
Типы индексов в PostgreSQL: изучаем PostgreSQL вместе с Grant Fritchey
Пересказ статьи Grant Fritchey. Index Types in PostgreSQL: Learning PostgreSQL with Grant
Как и любая другая реляционная система управления базами данных (РСУБД), PostgreSQL использует индексы как механизм улучшения доступа к данным. PostgreSQL имеет большое число различных типов индексов, поддерживающих различное поведение и различные типы данных. Помимо этого, подобно другим РСУБД, эти индексы характеризуются различными свойствами и поведением.
В этой статье я собираюсь пройтись по индексам различных типов и поведению некоторых индексов. Мы узнаем, что такое индексы, как они работают и как наилучшим образом применять их в ваших базах данных. Я надеюсь, что вы разовьете понимание того, какие индексы будут работать лучше в той или иной ситуации.
Однако я не буду обсуждать индексы подробно. Более того, я не собираюсь глубоко вникать в то, как индексы влияют на производительность. Я еще не настолько хорошо продвинулся в настройке производительности с PostgreSQL. Эта статья довольно далека от этого. Когда вы узнаете, какой индекс и где использовать, вы сможете углубиться, чтобы лучше понять этот индекс и как лучше всего оценить его влияние на производительность.
Важно помнить, что как типы ваших данных, так и фактические запросы, определяют те индексы, которые лучше всего подходят для ваших баз данных. Это особенно справедливо для PostgreSQL, т.к. некоторые типы индексов сильно ориентированы на конкретные шаблоны запросов.
Имеется шесть типов индексов:
Давайте поговорим о каждом из них в отдельности.
Хотя, прежде чем приступить, я сохраню все скрипты, которые я создал для этой статьи в публичном доступе на GitHub. Начать следует с CreateDatabase.sql. Вы можете использовать скрипт в SampleData.sql для загрузки некоторых данных.
Название индекса B-Tree в PostgreSQL является сокращением для многостороннего сбалансированного древовидного индекса. В основном он подобен индексу в SQL Server, когда значения индекса сохраняются на страницах в виде двусвязного списка. Страницы составляют дерево, у которого страницы на листовом уровне хранят данные ключевого столбца. Вы определяете ключевой столбец, или столбцы, в определении индекса:
Поведение по умолчанию позволяет игнорировать некоторые элементы синтаксиса, который вам стоит начать использовать сейчас, так как все остальные индексы, которые вы создаете, не будут работать таким образом:
Предложение USING BTREE сообщает PostgreSQL какой вид индекса вы хотите построить. Вы увидите другие команды для других типов индексов далее в статье.
Это, в частности, связано с тем, что имена в пределах заданной базы данных PostgreSQL являются уникальными. Это несколько необычно для старого пользователя SQL Server, который обычно использует дубликаты имен индексов, поскольку они привязаны к индексируемой таблице.
Вы можете сделать составной ключ, просто добавив еще столбцы:
Индексы B-Tree являются единственным типом индексов в PostgreSQL, который поддерживает определение UNIQUE (уникальность):
Этот индекс гарантирует, что дублирующиеся значения не смогут вводиться в ключевой столбец или столбцы индекса.
Другим уникальным поведением индекса B-Tree является его способность хранить данные в заданном порядке. Это может помочь с получением данных в правильном порядке. Конечно, вообще говоря, это прерогатива предложений ORDER BY, однако есть и другие условия и обстоятельства, в которых это может помочь. Подобно SQL Server, вы можете сделать выбор, в каком порядке упорядочивать значения ключа, по возрастанию или по убыванию. Вы также можете решить, где хранить NULL-значения - в начале или в конце индекса. Например, индекс будет сортировать значения столбца radioname по убыванию, но размещать NULL-значения в начале:
Одно отличие от SQL Server состоит в том, что существует только один тип индекса B-Tree. Все таблицы в PostgreSQL хранятся в виде кучи. Не существует кластерзованных индексов, определяющих способ хранения данных. Все индексы B-Tree являются вторичным хранилищем, означающим, что столбцы, определенные в индексе, хранятся в самом индексе. Без глубокого погружения в настройку производительности (которую, напомню, я еще не готов преподавать) это может привести к большим проблемам с производительностью, поскольку доступ в куче может быть случайным. Итак, вы можете использовать команду INCLUDE для создания покрывающего индекса - индекса, который удовлетворяет потребностям в столбцах для запроса, избегая при этом лишних чтений в куче:
PostgreSQL также поддерживает то, что называется Частичными Индексами, которые в SQL Server называют фильтрованными индексами:
В данном случае только те значения в столбце radioname, которые не являются NULL, будут добавлены в индекс. Вы можете использовать частичный индекс даже с определением UNIQUE, что открывает некоторые интересные возможности для индексирования.
Наконец, вы можете создавать такие индексы:
Я потому не демонстрировал это в начале, поскольку считаю это плохой практикой. PostgreSQL будет именовать индекс вместо вас, что замечательно. Но вы могли выполнить этот скрипт более одного раза, получив дубликаты индексов. Тут PostgreSQL присвоит вашему индексу имя, и в итоге вы получите что-то вроде этого:
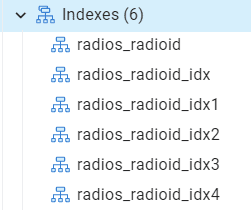
Это один и тот же индекс в пяти экземплярах. Это означает пятикратное увеличение хранилища, пятикратное обслуживание и пятикратные накладные расходы. Не говоря уже о совершенно запутанной базе данных. Я бы не рекомендовал строить ваши индексы в такой манере.
Еще пример, когда бы вы делали что-то подобное на одном сервере:
А затем так на другом:
В итоге вы получите разные индексы с совпадающими именами, что вызовет головную боль при тестировании и разработке. Поэтому я начал именовать свои индексы сам. Избегайте головной боли, следуя простой и понятной практике написания кода.
Имеется еще много деталей в поведении индексов B-Tree в PostgreSQL, но здесь обсуждаются основы.
PostgreSQL поддерживает хэш-индексы на данных любых типов. Хэш является просто результатом вычислений, выполняемых над данными в столбце и которые всегда дают в результате одинаковое значение для одинакового входа. Хэш хранится как 4-байтовое значение вне зависимости от размера индексируемого столбца. Это делает хэш хорошим выбором для больших объемов данных. Подумайте о длинных строках, например, веб-адресах. Создание хэш-индекса почти такое же, как и создание B-Tree:
Однако существует значительно больше ограничений в использовании хэш-индексов по сравнению с B-Tree. Во-первых, хэш-индекс может быть создан только на единственном столбце. Конечно, на любых данных вообще, но никаких составных ключей или INCLUDE для покрытия хэш-индекса.
Самая большая проблема, связанная с хэш-индексами, это коллизии, когда два не совсем одинаковых значения получают одно и то же хэш-значение. Это происходит довольно редко, но может случиться. Именно поэтому настоятельно рекомендуется, чтобы хэш-индексы строились на уникальных, или почти уникальных, данных. Сам по себе хэш-индекс не поддерживает оператор UNIQUE, но в значительной степени он функционирует так, как если бы имел дело с уникальными значениями. В зависимости от размера данных и самих данных, вы можете никогда не столкнуться с коллизии при хэшировании. Но когда это происходит, то может привести к серьезным проблемам с производительностью.
Значения хэш-индекса сохраняются в так называемых хэш-ведрах. Ведро имеет метаданные, которые связаны с наибольшим и наименьшим значениями, хранящимся в ведре. Это помогает сделать быстрым поиск хэш-значения. Когда имеется несколько копий хэш-значения, выполняется дополнительный поиск для идентификации соответствующего значения, что замедляет поиск. Это основная причина, по которой предлагается выполнять хэш-индексацию уникальных или почти уникальных данных. Указатель на таблицу кучи хранится вместе с самим хэш-значением.
Хэш-индексы могут быть частичными, поэтому для приведения их к уникальности вы можете добавить предложение WHERE при создании индекса:
Здесь предполагается, что значения, превосходящие ‘1/1/2020', будут более уникальными, что делает индекс более эффективным.
Другое отличие от B-Tree состоит в том, что хэш-индекс не поддерживает сканирование только по индексу. Однако это хорошо, поскольку вы не захотели бы видеть сканирование хэша, особенно при возможном наличии коллизий, из-за возникающих при этом накладных расходах. Кроме того, вывод из хэш-индекса не сортирован, это означает, что данные возвращаются в том порядке, в котором они извлекаются, и предложения ORDER BY отсутствуют. Невозможность сканирования индекса является главной причиной того, что поддерживается только оператор эквивалентности (=).
Если вы выполните поиск в интернет по хэш-индексам в PostgreSQL, то можете найти информацию о том, что их не следует использовать, поскольку они не записываются в журнал WAL (Write Ahead Log). Однако эта информация уже устарела после выхода версии PostgreSQL 9. Это больше не актуально и, если этот тип индекса может помочь, смело используйте его.
Индекс обобщенного дерева поиска (GiST) фактически не является индексом как таковым. Он является методом доступа, который позволяет вам определить различные виды индексов для поддержки различных типов данных и операций поиска для этих типов данных. Индексы GiST используются для типов данных, которые не имеют дела с диапазонами или равенством, подобных индексам B-Tree или хэш-индексам, а связаны с геометрическими данными, документами или даже изображениями. Кроме того, индексы GiST являются расширяемыми. Фактически документация по самому индексу GiST гораздо больше ориентирована на расширяемость индексов в рамках методов доступа GiST. Документация о поведении GiST фактически крутится вокруг различных типов данных, которые им поддерживаются, что несколько затрудняет понимание, как фактически работают индексы GiST. Советую тем, кто только начал процесс изучения GiST, не беспокоиться об этом, пока вы не уйдете от базовых типов данных как-то VARCHAR, DATE и т.д.
Данные в пределах индекса GiST хранятся в сбалансированном дереве, но интересно что там хранится. Вместо того, чтобы начать со значений ключа или хэш-значений, как в ранее обсуждаемых индексах, хранилище в индексах GiST начинается с предиката. Затем последовательности строк дочерних поддеревьев, которые удовлетворяют этому предикату, сохраняются в ветке предиката.
Уже существует большое число расширений индексов GiST в PostgreSQL. Так, например, если у вас географическое местоположение хранится в виде точек, вы могли бы добавить индекс, который поможет найти информацию на геометрической плоскости:
Синтаксис в целом тот же. Вопрос в том, имеется ли уже функциональность в рамках индексов PostgreSQL для используемого типа данных. Если нет, вам придется обеспечить поведение, а также определить индекс. Это выходит далеко за рамки данной статьи, поэтому мы отложим это на потом.
Пространственно секционированный GIST (Space Partitioned GiST или SP-GIST) во многом подобен индексу GIST в том, что он строится для поддержки полностью настраиваемого набора данных. В этом случае функция полностью подобна индексу GIST, но хранилище секционируется с тем, чтобы данные, которые поддаются группировке посредством секционирования, больше выиграли от индекса SP-GIST. Типы данных, поддерживаемые из коробки довольно похожи на GIST, включая геометрические данные типа моего примера выше. Так что в этом случае я, вероятно, снова выбрал бы этот пример синтаксиса:
Наиболее интересным моментом как для GIST, так и SP-GIST, является расширяемость. Я не буду это обсуждать здесь. Я все еще изучаю, как в запросах использовать эти вещи. Тем не менее, еще один интересный аспект заключается в том, что GiST в первую очередь ориентирован на операции, в то время как SP-GIST, безусловно, тоже ориентирован на операции, но именно секционирование данных будет определяющим фактором для того, чтобы это был лучший вариант при выборе индексов.
Обобщенный инвертированный индекс (GIN) эффективно индексирует массивы. PostgreSQL имеет много различных типов массивов данных. Мы можем долго дискутировать на тему, является ли массив подходящим способом хранения данных, но по факту массивы в PostgreSQL работают достаточно хорошо и весьма функциональны. Плюс все хранят данные в JSON или YAML. Поэтому вы собираетесь увидеть типы массивов данных в действии. Почему бы не найти способ сделать ваш массив более быстрым?
Индекс GIN почти так же эффективен, как индекс B-Tree, за несколькими исключениями. Самое интересное находится на уровне страниц. Вместо хранения значений ключа и идентификатора кортежа (TID), расположение в куче, где хранятся данные, вы получаете с помощью так называемого списка публикации. Это список всех значений, которые удовлетворяют ключу, и указатель на TID. Хотя это может оказаться немного сложнее, т.к. по мере того, как вы получаете больше и больше дублирующихся значений, вы можете получить то, что называется деревом публикации. По сути, это способ расширить страницу до набора страниц, каждая из которых имеет значение TID, своего рода B-Tree внутри B-Tree.
В то время как массивы, особенно JSON, вероятно, являются основным назначением индекса GIN, вы можете также использовать его для полнотекстового поиска. Те же концепции применимы, если вы выполняли поиск в массиве. Помимо прочего, большой текстовый документ можно мыслить просто как большой массив текста.
В моей тестовой базе сейчас нет полнотекстового столбца, поэтому мы просто проиндексируем один из массивов:
Вы не можете использовать столбцы INCLUDE, поскольку ничего не сохраняется на уровне страниц за исключением PID или списка публикации. Хотя вы можете построить многостолбцовый индекс GIN, что сделает индекс значительно более селективным на уровне ключа, несколько увеличивая его на листовом уровне. На самом деле, одна большая слабость индексов GIN, которая признается всеми, заключается в том, что они работают медленно, когда дело доходит до операторов UPDATE. Имеется несколько обходных путей, которые я еще не готов понять, не говоря уже о том, чтобы объяснить, которые могут помочь смягчить эту проблему. Больше информации по этому вопросу можно найти здесь.
Индекс диапазона блоков (Block Range Index) предназначен для хранения упорядоченных значений диапазона данных (представьте себе даты). Поэтому, когда у вас есть естественным путем сгруппированные данные, которые, скорее всего, будут возвращены в виде набора (на ум приходят почтовые индексы), у вас есть индекс, который может тут помочь. Более того, когда вы пытаетесь исключить наборы, скажем, выдать даты, которые меньше определенного значения, опять таки тут может помочь индекс BRIN. Просто помните, что речь идет о диапазонах данных, а не о поиске значений отдельных точек, где лучше подходит индекс B-Tree.
Итак, если вы имеете запросы с поиском по диапазону, BRIN - ваш друг. Я знаю, что их может поддерживать также B-Tree, но для ограниченных типов запросов (думайте опять таки об упорядоченных наборах), BRIN не только превосходит B-Tree, но обычно занимает около 1% места. Вы прочли это правильно, экономия 99% пространства. Приблизительно. Все тесты, которые я видел с большими наборам данных, говорят об этом.
Синтаксис вас не удивит:
Поскольку журналы, по большей части, следуют по порядку и упорядочены по возрастанию даты, это оказывается полезным индексом.
Мой редактор, Louis Davidson, справедливо заметил, что до некоторой степени индекс BRIN сортируется как кластеризованный индекс B-Tree в SQL Server. Сходства очевидны, порядок данных и, следовательно, где вы начинаете поиск или сканирование, определяется индексом. Ключевым отличием все же служит тот факт, что этот индекс не определяет хранилище данных. Данные все так же находятся в куче.
Чтобы увидеть реальные преимущества индексов, вам бы хотелось посмотреть примеры. Однако я пока все еще поверхностно изучил PostgreSQL. Я пока еще не готов сказать вам, что происходит в плане EXPLAIN. Однако простое обсуждение типов данных и поддерживаемых запросов даст вам некоторые указания, как индекс может улучшить поведение в PostgreSQL. Как и в других системах баз данных, вы можете добавить более одного индекса, чтобы повысить производительность таблицы. Просто знайте, что, как и везде, это может привести к дополнительным накладным расходам относительно хранилища и обработки, т.к. данные меняются со временем.
Ссылки по теме
Важно помнить, что как типы ваших данных, так и фактические запросы, определяют те индексы, которые лучше всего подходят для ваших баз данных. Это особенно справедливо для PostgreSQL, т.к. некоторые типы индексов сильно ориентированы на конкретные шаблоны запросов.
Имеется шесть типов индексов:
- B-Tree
- Hash
- GIST
- SP-GIST
- GIN
- RIN
Давайте поговорим о каждом из них в отдельности.
Хотя, прежде чем приступить, я сохраню все скрипты, которые я создал для этой статьи в публичном доступе на GitHub. Начать следует с CreateDatabase.sql. Вы можете использовать скрипт в SampleData.sql для загрузки некоторых данных.
B-Tree
Название индекса B-Tree в PostgreSQL является сокращением для многостороннего сбалансированного древовидного индекса. В основном он подобен индексу в SQL Server, когда значения индекса сохраняются на страницах в виде двусвязного списка. Страницы составляют дерево, у которого страницы на листовом уровне хранят данные ключевого столбца. Вы определяете ключевой столбец, или столбцы, в определении индекса:
CREATE INDEX radios_radioname ON radio.radios(radio_name);Поведение по умолчанию позволяет игнорировать некоторые элементы синтаксиса, который вам стоит начать использовать сейчас, так как все остальные индексы, которые вы создаете, не будут работать таким образом:
CREATE INDEX radios_radioname ON radio.radios USING BTREE(radio_name);Предложение USING BTREE сообщает PostgreSQL какой вид индекса вы хотите построить. Вы увидите другие команды для других типов индексов далее в статье.
Это, в частности, связано с тем, что имена в пределах заданной базы данных PostgreSQL являются уникальными. Это несколько необычно для старого пользователя SQL Server, который обычно использует дубликаты имен индексов, поскольку они привязаны к индексируемой таблице.
Вы можете сделать составной ключ, просто добавив еще столбцы:
CREATE INDEX radios_radioname_radioid ON radios.radios
USING BTREE(radio_name, radio_id);Индексы B-Tree являются единственным типом индексов в PostgreSQL, который поддерживает определение UNIQUE (уникальность):
CREATE UNIQUE INDEX radios_radioid_unique ON radio.radios
USING BTREE(radio_id);Этот индекс гарантирует, что дублирующиеся значения не смогут вводиться в ключевой столбец или столбцы индекса.
Другим уникальным поведением индекса B-Tree является его способность хранить данные в заданном порядке. Это может помочь с получением данных в правильном порядке. Конечно, вообще говоря, это прерогатива предложений ORDER BY, однако есть и другие условия и обстоятельства, в которых это может помочь. Подобно SQL Server, вы можете сделать выбор, в каком порядке упорядочивать значения ключа, по возрастанию или по убыванию. Вы также можете решить, где хранить NULL-значения - в начале или в конце индекса. Например, индекс будет сортировать значения столбца radioname по убыванию, но размещать NULL-значения в начале:
CREATE INDEX radios_radioname ON radio.radios
USING BTREE(radio_name DESC NULLS FIRST);Одно отличие от SQL Server состоит в том, что существует только один тип индекса B-Tree. Все таблицы в PostgreSQL хранятся в виде кучи. Не существует кластерзованных индексов, определяющих способ хранения данных. Все индексы B-Tree являются вторичным хранилищем, означающим, что столбцы, определенные в индексе, хранятся в самом индексе. Без глубокого погружения в настройку производительности (которую, напомню, я еще не готов преподавать) это может привести к большим проблемам с производительностью, поскольку доступ в куче может быть случайным. Итак, вы можете использовать команду INCLUDE для создания покрывающего индекса - индекса, который удовлетворяет потребностям в столбцах для запроса, избегая при этом лишних чтений в куче:
CREATE INDEX radios_radioid ON radio.radios
USING BTREE(radio_id) INCLUDE(radio_name);PostgreSQL также поддерживает то, что называется Частичными Индексами, которые в SQL Server называют фильтрованными индексами:
CREATE INDEX radios_radioname ON radio.radios USING BTREE(radio_name)
WHERE radio_name IS NOT NULL;В данном случае только те значения в столбце radioname, которые не являются NULL, будут добавлены в индекс. Вы можете использовать частичный индекс даже с определением UNIQUE, что открывает некоторые интересные возможности для индексирования.
Наконец, вы можете создавать такие индексы:
CREATE INDEX ON radios (adioed);Я потому не демонстрировал это в начале, поскольку считаю это плохой практикой. PostgreSQL будет именовать индекс вместо вас, что замечательно. Но вы могли выполнить этот скрипт более одного раза, получив дубликаты индексов. Тут PostgreSQL присвоит вашему индексу имя, и в итоге вы получите что-то вроде этого:
Это один и тот же индекс в пяти экземплярах. Это означает пятикратное увеличение хранилища, пятикратное обслуживание и пятикратные накладные расходы. Не говоря уже о совершенно запутанной базе данных. Я бы не рекомендовал строить ваши индексы в такой манере.
Еще пример, когда бы вы делали что-то подобное на одном сервере:
CREATE INDEX ON radios (radioid);
CREATE INDEX ON radios (radio_name);А затем так на другом:
CREATE INDEX ON radios (radio_name);
CREATE INDEX ON radios (radioid);В итоге вы получите разные индексы с совпадающими именами, что вызовет головную боль при тестировании и разработке. Поэтому я начал именовать свои индексы сам. Избегайте головной боли, следуя простой и понятной практике написания кода.
Имеется еще много деталей в поведении индексов B-Tree в PostgreSQL, но здесь обсуждаются основы.
Хеш-индексы
PostgreSQL поддерживает хэш-индексы на данных любых типов. Хэш является просто результатом вычислений, выполняемых над данными в столбце и которые всегда дают в результате одинаковое значение для одинакового входа. Хэш хранится как 4-байтовое значение вне зависимости от размера индексируемого столбца. Это делает хэш хорошим выбором для больших объемов данных. Подумайте о длинных строках, например, веб-адресах. Создание хэш-индекса почти такое же, как и создание B-Tree:
CREATE INDEX bands_band_name ON radio.bands USING HASH(band_name);Однако существует значительно больше ограничений в использовании хэш-индексов по сравнению с B-Tree. Во-первых, хэш-индекс может быть создан только на единственном столбце. Конечно, на любых данных вообще, но никаких составных ключей или INCLUDE для покрытия хэш-индекса.
Самая большая проблема, связанная с хэш-индексами, это коллизии, когда два не совсем одинаковых значения получают одно и то же хэш-значение. Это происходит довольно редко, но может случиться. Именно поэтому настоятельно рекомендуется, чтобы хэш-индексы строились на уникальных, или почти уникальных, данных. Сам по себе хэш-индекс не поддерживает оператор UNIQUE, но в значительной степени он функционирует так, как если бы имел дело с уникальными значениями. В зависимости от размера данных и самих данных, вы можете никогда не столкнуться с коллизии при хэшировании. Но когда это происходит, то может привести к серьезным проблемам с производительностью.
Значения хэш-индекса сохраняются в так называемых хэш-ведрах. Ведро имеет метаданные, которые связаны с наибольшим и наименьшим значениями, хранящимся в ведре. Это помогает сделать быстрым поиск хэш-значения. Когда имеется несколько копий хэш-значения, выполняется дополнительный поиск для идентификации соответствующего значения, что замедляет поиск. Это основная причина, по которой предлагается выполнять хэш-индексацию уникальных или почти уникальных данных. Указатель на таблицу кучи хранится вместе с самим хэш-значением.
Хэш-индексы могут быть частичными, поэтому для приведения их к уникальности вы можете добавить предложение WHERE при создании индекса:
CREATE INDEX logs_log_date ON logging.logs USING HASH(log_date)
WHERE log_date > '1/1/2020';Здесь предполагается, что значения, превосходящие ‘1/1/2020', будут более уникальными, что делает индекс более эффективным.
Другое отличие от B-Tree состоит в том, что хэш-индекс не поддерживает сканирование только по индексу. Однако это хорошо, поскольку вы не захотели бы видеть сканирование хэша, особенно при возможном наличии коллизий, из-за возникающих при этом накладных расходах. Кроме того, вывод из хэш-индекса не сортирован, это означает, что данные возвращаются в том порядке, в котором они извлекаются, и предложения ORDER BY отсутствуют. Невозможность сканирования индекса является главной причиной того, что поддерживается только оператор эквивалентности (=).
Если вы выполните поиск в интернет по хэш-индексам в PostgreSQL, то можете найти информацию о том, что их не следует использовать, поскольку они не записываются в журнал WAL (Write Ahead Log). Однако эта информация уже устарела после выхода версии PostgreSQL 9. Это больше не актуально и, если этот тип индекса может помочь, смело используйте его.
GiST
Индекс обобщенного дерева поиска (GiST) фактически не является индексом как таковым. Он является методом доступа, который позволяет вам определить различные виды индексов для поддержки различных типов данных и операций поиска для этих типов данных. Индексы GiST используются для типов данных, которые не имеют дела с диапазонами или равенством, подобных индексам B-Tree или хэш-индексам, а связаны с геометрическими данными, документами или даже изображениями. Кроме того, индексы GiST являются расширяемыми. Фактически документация по самому индексу GiST гораздо больше ориентирована на расширяемость индексов в рамках методов доступа GiST. Документация о поведении GiST фактически крутится вокруг различных типов данных, которые им поддерживаются, что несколько затрудняет понимание, как фактически работают индексы GiST. Советую тем, кто только начал процесс изучения GiST, не беспокоиться об этом, пока вы не уйдете от базовых типов данных как-то VARCHAR, DATE и т.д.
Данные в пределах индекса GiST хранятся в сбалансированном дереве, но интересно что там хранится. Вместо того, чтобы начать со значений ключа или хэш-значений, как в ранее обсуждаемых индексах, хранилище в индексах GiST начинается с предиката. Затем последовательности строк дочерних поддеревьев, которые удовлетворяют этому предикату, сохраняются в ветке предиката.
Уже существует большое число расширений индексов GiST в PostgreSQL. Так, например, если у вас географическое местоположение хранится в виде точек, вы могли бы добавить индекс, который поможет найти информацию на геометрической плоскости:
create index logs_location on logging.logs using gist(log_location); Синтаксис в целом тот же. Вопрос в том, имеется ли уже функциональность в рамках индексов PostgreSQL для используемого типа данных. Если нет, вам придется обеспечить поведение, а также определить индекс. Это выходит далеко за рамки данной статьи, поэтому мы отложим это на потом.
SP-GIST
Пространственно секционированный GIST (Space Partitioned GiST или SP-GIST) во многом подобен индексу GIST в том, что он строится для поддержки полностью настраиваемого набора данных. В этом случае функция полностью подобна индексу GIST, но хранилище секционируется с тем, чтобы данные, которые поддаются группировке посредством секционирования, больше выиграли от индекса SP-GIST. Типы данных, поддерживаемые из коробки довольно похожи на GIST, включая геометрические данные типа моего примера выше. Так что в этом случае я, вероятно, снова выбрал бы этот пример синтаксиса:
create index logs_location on logging.logs using spgist(log_location);Наиболее интересным моментом как для GIST, так и SP-GIST, является расширяемость. Я не буду это обсуждать здесь. Я все еще изучаю, как в запросах использовать эти вещи. Тем не менее, еще один интересный аспект заключается в том, что GiST в первую очередь ориентирован на операции, в то время как SP-GIST, безусловно, тоже ориентирован на операции, но именно секционирование данных будет определяющим фактором для того, чтобы это был лучший вариант при выборе индексов.
GIN
Обобщенный инвертированный индекс (GIN) эффективно индексирует массивы. PostgreSQL имеет много различных типов массивов данных. Мы можем долго дискутировать на тему, является ли массив подходящим способом хранения данных, но по факту массивы в PostgreSQL работают достаточно хорошо и весьма функциональны. Плюс все хранят данные в JSON или YAML. Поэтому вы собираетесь увидеть типы массивов данных в действии. Почему бы не найти способ сделать ваш массив более быстрым?
Индекс GIN почти так же эффективен, как индекс B-Tree, за несколькими исключениями. Самое интересное находится на уровне страниц. Вместо хранения значений ключа и идентификатора кортежа (TID), расположение в куче, где хранятся данные, вы получаете с помощью так называемого списка публикации. Это список всех значений, которые удовлетворяют ключу, и указатель на TID. Хотя это может оказаться немного сложнее, т.к. по мере того, как вы получаете больше и больше дублирующихся значений, вы можете получить то, что называется деревом публикации. По сути, это способ расширить страницу до набора страниц, каждая из которых имеет значение TID, своего рода B-Tree внутри B-Tree.
В то время как массивы, особенно JSON, вероятно, являются основным назначением индекса GIN, вы можете также использовать его для полнотекстового поиска. Те же концепции применимы, если вы выполняли поиск в массиве. Помимо прочего, большой текстовый документ можно мыслить просто как большой массив текста.
В моей тестовой базе сейчас нет полнотекстового столбца, поэтому мы просто проиндексируем один из массивов:
create index parksontheair_contacts on logging.parksontheair
using GIN(contacts);Вы не можете использовать столбцы INCLUDE, поскольку ничего не сохраняется на уровне страниц за исключением PID или списка публикации. Хотя вы можете построить многостолбцовый индекс GIN, что сделает индекс значительно более селективным на уровне ключа, несколько увеличивая его на листовом уровне. На самом деле, одна большая слабость индексов GIN, которая признается всеми, заключается в том, что они работают медленно, когда дело доходит до операторов UPDATE. Имеется несколько обходных путей, которые я еще не готов понять, не говоря уже о том, чтобы объяснить, которые могут помочь смягчить эту проблему. Больше информации по этому вопросу можно найти здесь.
BRIN
Индекс диапазона блоков (Block Range Index) предназначен для хранения упорядоченных значений диапазона данных (представьте себе даты). Поэтому, когда у вас есть естественным путем сгруппированные данные, которые, скорее всего, будут возвращены в виде набора (на ум приходят почтовые индексы), у вас есть индекс, который может тут помочь. Более того, когда вы пытаетесь исключить наборы, скажем, выдать даты, которые меньше определенного значения, опять таки тут может помочь индекс BRIN. Просто помните, что речь идет о диапазонах данных, а не о поиске значений отдельных точек, где лучше подходит индекс B-Tree.
Итак, если вы имеете запросы с поиском по диапазону, BRIN - ваш друг. Я знаю, что их может поддерживать также B-Tree, но для ограниченных типов запросов (думайте опять таки об упорядоченных наборах), BRIN не только превосходит B-Tree, но обычно занимает около 1% места. Вы прочли это правильно, экономия 99% пространства. Приблизительно. Все тесты, которые я видел с большими наборам данных, говорят об этом.
Синтаксис вас не удивит:
create index logs_log_date on logging.logs using BRIN(logs_log_date);Поскольку журналы, по большей части, следуют по порядку и упорядочены по возрастанию даты, это оказывается полезным индексом.
Мой редактор, Louis Davidson, справедливо заметил, что до некоторой степени индекс BRIN сортируется как кластеризованный индекс B-Tree в SQL Server. Сходства очевидны, порядок данных и, следовательно, где вы начинаете поиск или сканирование, определяется индексом. Ключевым отличием все же служит тот факт, что этот индекс не определяет хранилище данных. Данные все так же находятся в куче.
Заключение
Чтобы увидеть реальные преимущества индексов, вам бы хотелось посмотреть примеры. Однако я пока все еще поверхностно изучил PostgreSQL. Я пока еще не готов сказать вам, что происходит в плане EXPLAIN. Однако простое обсуждение типов данных и поддерживаемых запросов даст вам некоторые указания, как индекс может улучшить поведение в PostgreSQL. Как и в других системах баз данных, вы можете добавить более одного индекса, чтобы повысить производительность таблицы. Просто знайте, что, как и везде, это может привести к дополнительным накладным расходам относительно хранилища и обработки, т.к. данные меняются со временем.
Ссылки по теме
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой