
Введение в B-Tree и хэш-индексы в PostgreSQL
Пересказ статьи Paul S. Randal. An Introduction to B-Tree and Hash Indexes in PostgreSQL
В этой статье изучаются реализация B-Tree (B означает сбалансированное) и структуры данных хэш-индекса в PostgreSQL. По мере роста популярности PostgreSQL в качестве системы баз данных с открытыми кодами для разработчиков и как цель для переноса рабочей нагрузки Oracle, понимание работы индексов в PostgreSQL исключительно важно для разработчиков и администраторов баз данных. PostgreSQL имеет несколько других типов индексов, таких как индексы GIN, индексы GiST и индексы BRIN. В этой статье я не буду их рассматривать, поскольку они специфичны для поиска в тексте, географических и других сложных типов данных. И, хотя использование индекса B-Tree покрывает примерно 90% случаев использования, хэш-индексы и их концепция также важны для понимания.
Таблицы PostgreSQL
В PostgreSQL все таблицы представляют собой кучу, т.к. не существует порядка в таблице, который обслуживался бы реляционным движком. Не существует возможности определить кластеризованный индекс для поддержания физической упорядоченности данных в таблице по ключу. Поскольку данные в таблице неупорядочены, это может сделать некоторые типы операций сканирования менее эффективными. Однако в PostgreSQL имеется понятие команды CLUSTER для таблицы. При выполнении команды CLUSTER для таблицы данные в таблице упорядочиваются физически на основе ключа вторичного индекса (подробнее об этом чуть позже), который вы при этом указываете. Однако движок не поддерживает физическое упорядочивание после того, как команда CLUSTER была выполнена - новые строки добавляются в первое попавшееся место в таблице, где имеется достаточно свободного места. Вам может потребоваться периодически выполнять команду CLUSTER для реорганизации таблицы, если окажется, что можно получить выгоду от такого упорядочивания при сканировании на определенных шаблонах доступа для вашей рабочей нагрузки.
Страницы данных и индексов
Каждая таблица и индекс в PostgreSQL состоит из массива страниц. Страница является структурой данных, которая предназначена для хранения записей таблицы или указателей индекса. Страница базы данных в PostgreSQL обычно имеет размер 8Кб, но его можно изменить при компиляции сервера. Поскольку таблица не имеет порядка в PostgreSQL, при вставке строки в таблицу она попадает на первую страницу, на которую может поместиться. Для этого PostgreSQL отслеживает заполнение каждой страницы посредством структуры данных, известной как карта свободного пространства (Free Space Map - FSM). Структура FSM содержит по одному байту на страницу, и этот байт показывает, насколько заполнена страница. Если ни на одной странице в таблице нет достаточно места для сохранения записи данных, в таблицу добавляется новая страница, на которую и помещается запись.
Вторичные индексы
Каждый индекс в PostgreSQL является вторичным индексом - структурой данных, хранящейся отдельно от табличной структуры кучи и содержащей указатель некоторого типа на таблицу кучи. Два типа индексов, на которых я остановлюсь сегодня - это индекс B-Tree и хэш-индекс. Индекс B-Tree является наиболее общей используемой индексной структурой, которая позволяет выполнять быстрый поиск и сортировку данных при минимальных затратах на хранение индекса. Хэш-индексы являются одностолбцовыми индексами, хранящими 4-байтовые результаты применения алгоритма хэширования к ключу индекса. Хэш-значение сопоставляется с сегментом, в котором хранится указатель на строку в таблице кучи. Я объясню преимущества и недостатки хэш-индекса несколько позже.
Давайте создадим тестовую таблицу для демонстрационных примеров. В качестве GUI я буду использовать DBeaver Community Edition - блестящий интерфейс для разработки и администрирования мириадов экземпляров различных баз данных. Для базы данных PostgreSQL я буду использовать Azure Database for PostgreSQL Flexible Server. Azure упрощает раскрутку сервера баз данных PostgreSQL, поэтому я могу запускать свои демонстрации, а затем быстро демонтировать экземпляр с минимальными затратами.
Первый шаг - это создание тестовой базы данных:
create database sqlskills; Затем воспользуемся навыкам SQL и создадим таблицу с именем numbers:
create table numbers (numbercol int, charcol varchar (100));Я буду использовать функцию PostgreSQL generate_series для быстрой генерации списка из 5000 чисел и случайных строковых значений для вставки в таблицу numbers. Заметьте, что я генерирую случайное число в предложении ORDER BY для вставки данных в таблицу в случайном порядке.
insert into numbers (numbercol, charcol)
select generate_series, left(md5 (random ()::text),100)
from generate_series (1,5000)
order by random (); Теперь, когда я выполню запрос SELECT к этой таблице, данные возвращаются в случайном порядке:
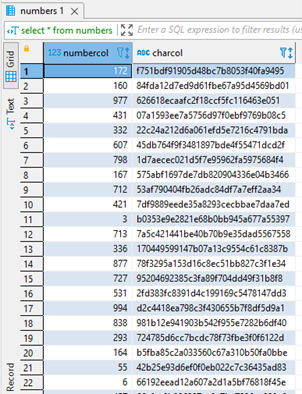
Чтобы показать команду CLUSTER в действии, я должен сначала создать индекс B-Tree на таблице с помощью команды CREATE INDEX. Индекс может быть указан как ASC или DESC, при этом ASC принимается по умолчанию. Этот индекс B-Tree упорядочен по столбцу numbercol таблицы numbers:
create index idx_numbers_numbercol on numbers (numbercol);И теперь выполнение команды CLUSTER, в которую передается имя используемого индекса, физически упорядочивает содержимое таблицы:
cluster numbers using idx_numbers_numbercol;Теперь выполнение простого SELECT без ORDER BY выводит данные из таблицы в том же порядке, который использован в только что созданном индексе:

Индексы B-Tree
Индекс в предыдущем примере является индексом B-Tree (B означает сбалансированное). Индексы B-Tree являются наиболее общими и предпочтительными структурами среди реляционных систем управления базами данных (RDBMS - РСУБД). Индекс B-Tree преследует 2 цели. Первая и основная цель - обеспечить быстрый и эффективный поиск записей вместо выполнения последовательного сканирования таблицы. Вторая вспомогательная цель - сделать возможной быструю сортировку данных. Для достижения обеих этих целей индекс B-Tree сохраняет данных, которые он содержит, в отсортированном порядке и имеет дерево поиска.
На картинке ниже показан высокоуровневый обзор индекса B-Tree. В наших целях давайте предположим, что это дерево B-Tree хранит данные индекса idx_numbers_numbercol на таблице numbers, который был создан в предыдущем примере.
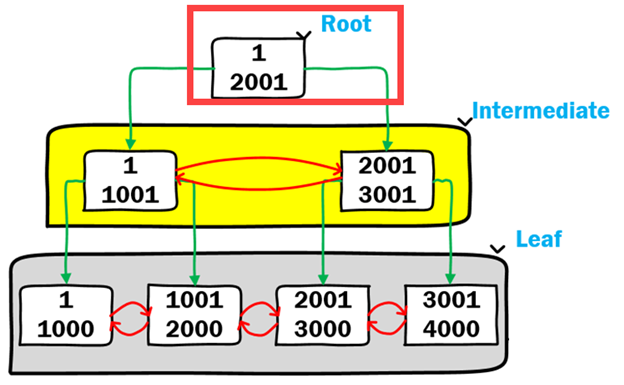
На верхнем уровне индекса находится "корневая" страница. Это фиксированная страница метаданных, содержащая указатели на другие страницы на основе хранимых метаданных. Рассмотрим следующий запрос:
select numbercol
from numbers n
where numbercol = 2500;При перемещении по этому индексу B-Tree для нахождения значения 2500 первой опрашивается корневая страница. Корневая страница содержит первую подсказку на карте для поиска требуемого значения. Значение 2500 больше, чем значение 2001, поэтому корневая страница направляет поиск на правую страницу нелистового (промежуточного) уровня в структуре B-Tree, как показано ниже.
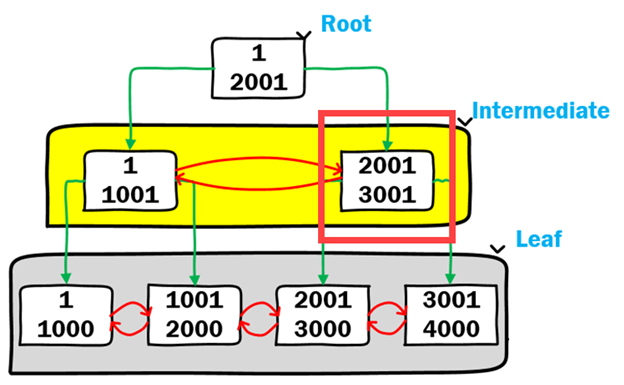
На нелистовых уровнях индекса B-Tree находятся "индексные страницы", содержащие указатели либо на следующий нелистовой уровень индекса в дереве, либо на листовой уровень индекса. На нелистовых уровнях индексные страницы представляют двусвязные списки, которые поддерживают логический порядок в индексе. Для нашего поиска значение 2500 находится между 2001 и 3001, поэтому следующей страницей для перехода является листовая страница, содержащая 2001 - 3000, как показано ниже.
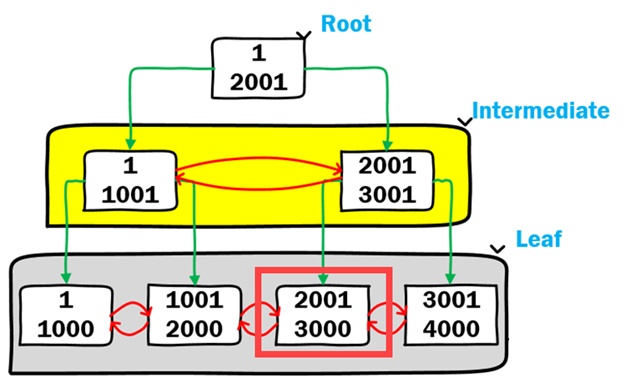
Теперь поиск достиг листового уровня индекса. Для вторичных индексов листовой уровень содержит ключ (ключи) индекса, любые неключевые включенные столбцы, определенные в индексе, и указатель на запись в таблице кучи. Также следует отметить, что страницы на листовом уровне связаны двусвязным списком, поддерживая переход к предыдущей и следующей странице, а также двунаправленную сортировку.
Для вышеприведенного запроса ядру PostgreSQL необходимо проверить только три страницы, чтобы вернуть затребованные данные. Мы можем это легко проверить с помощью команды EXPLAIN. В PostgreSQL команда EXPLAIN используется для вывода плана выполнения оператора SQL. Погружение в детали, относящиеся к команде EXPLAIN, выходят за рамки настоящей статьи; однако я покажу вам, как получить план выполнения для оператора и использовать опцию BUFFERS, чтобы увидеть, как много общих буферов (страниц данных в памяти) было задействовано для данного оператора.
Для просмотра плана выполнения я напечатаю ключевое слово EXPLAIN перед оператором, план которого я хочу получить, как показано ниже:
explain (analyze, buffers)
select numbercol
from numbers n
where numbercol = 2500;После EXPLAIN ключевое слово ANALYZE говорит PostgreSQL выполнить оператор и включить число общих буферов, задействованных для возврата данных. PostgreSQL имеет большую область выделенной памяти, чтобы сохранять данные и индексные страницы для запросов. Страницы данных должны извлекаться из диска в этот пул разделяемой памяти, прежде чем данные возвращаются конечному пользователю. Как правило, чем меньше общих буферов задействовано для возвращения данных пользователю, тем быстрей запрос.
Рассматривая план запроса ниже, можно заметить, что индекс idx_numbers_numbercol был использован для возвращения одной строки, а для возвращения наших данных было задействовано три общих буфера. Эти три общих буфера соответствуют чтению корневой страницы, нелистовой страницы и листовой страницы для возвращения данных. Круто.

Хэш-индексы
Хэш-индекс реализует вариацию структуры данных хэш-таблицы, при которой функция хэширования использует значение ключа индекса, создавая 4-байтовое знаковое целое значение (32 бита), представляющее значение ключа, и сохраняет хэшированное значение в так называемом ведре (bucket), наряду с указателем на то место, где находится запись в таблице кучи (по существу набор кортежей). До PostgreSQL версии 10 хэш-индексы не очень хорошо работали при высоко конкурентной нагрузке и не поддерживали протокол журнализации WAL, это означает, что они часто будут повреждены в случае восстановления после сбоя. Однако, поскольку были осуществлены улучшения хэш-индексов, они являются безопасными для использования, и в ряде случаев имеют преимущество по сравнению с индексами B-Tree.
Прежде чем я покажу некий демонстрационный код для создания хэш-индекса, давайте сначала рассмотрим логику применения хэш-индекса (это не фактическая реализация — просто логический взгляд). Для этого предположим, что имеется поле FirstName, в котором хранятся текстовые значения. В PostgreSQL есть функция hashtext, которая принимает строковое значение и возвращает детерминистическое целое значение для этой строки. В данном случае мое имя отображается в значение 403,565,329. Применительно к работе хэш-индексирования мыслите hashtext как первую часть алгоритма хэширования.
select hashtext ('Paul') as hashvalue;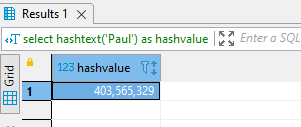
Второй частью алгоритма хэширования является отображение вывода хэш-функции на бакет. Структура бакета отображает значения хэш-кода на фактические строки таблицы. Бакеты реализованы как страницы данных в PostgreSQL и, в зависимости от размера таблицы, они могут отображать несколько различных хэш-значений на один и тот же бакет - обычный сценарий, известный как коллизия. Если коллизии заполняют страницу бакета полностью, то выделяется страница переполнения для хранения дополнительных хэш-значений и местоположения в таблице для хэшированного значения строки. В данном примере я использую функцию PostgreSQL mod для вывода по модулю 10 (значения остатка от 0 до 9) хэш-значения моего имени:
select mod (hashtext ('Paul'), 10) as bucketpointer;Это хэш-значение отображается на бакет 9.

Давайте взглянем на создание хэш-индекса. Я буду снова использовать схему таблицы, которую я создавал для индексов B-Tree.
drop table numbers;
create table numbers (numbercol int, charcol varchar(100));
insert into numbers (numbercol, charcol)
select generate_series, left (md5 (random()::text),100)
from generate_series (1,5000)
order by random ();Чтобы создать хэш-индекс, я должен использовать предложение "using" в операторе CREATE INDEX для указания, что индекс является хэш-индексом, а затем указать в скобках ключевой столбец. Мне не требовалось ранее включать предложение using при создании индексов B-Tree, т.к. индекс B-Tree является индексом по умолчанию для синтаксиса CREATE INDEX.
create index idxhash_numbers_numbercol on numbers using hash (numbercol);Затем я напишу запрос к таблице numbers для поиска значения ключа 2500. При выполнении этого запроса к значению 2500 применяется хэш-алгоритм, чтобы определить бакет в хэш-индексе, указывающего на строку в таблице.
explain (analyze)
select *
from numbers n
where numbercol = 2500;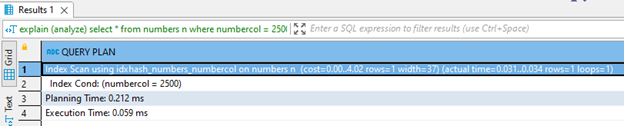
Ограничения хэш-индексов
В предыдущем примере было показано, как создать хэш-индекс для нахождения единственной записи в таблице, используя сравнение с уникальным значением в предложении WHERE запроса. Мне пришлось использовать простой пример из-за ограниченности хэш-индексов в вариантах их использования. Хэш-индексы поддерживают только сравнение на равенство при выполнении поиска. Это обусловлено применяемой структурой данных - алгоритм хэширования работает с ключом индекса, производя и сохраняя единственное 4-байтовое целое значение. Всякий раз, когда выполняется поиск, тот же самый алгоритм хэширования должен снова применяться к разыскиваемому значению для получения указателя на строку из бакета в этой структуре данных. По этой причине структура данных не имеет порядка. Единственным способом нахождения диапазона значений является чтение всей таблицы для обнаружения этих значений, при этом хэш-индекс не будет использоваться вообще. Хэш-индексы в PostgreSQL поддерживаются только для ключа из единственного столбца, поэтому наличие многостолбцового индекса в качестве хэш-индекса - не вариант. Кроме того, хэш-индексы не имеют возможности накладывать ограничение уникальности.
Преимущества хэш-индекса по сравнению с индексами B-Tree
Хотя имеется немало ограничений на хэш-индексы, они имеют некоторое преимущество по сравнению с индексами B-Tree. Первое преимущество заключается в том, что хэш-индекс может размещать поисковые значения ключа без необходимости какого-либо перемещения по древовидной структуре данных. Это может стать преимуществом для больших таблиц из-за уменьшения операций ввода вывода при поиске необходимых записей.
Другим преимуществом хэш-индексов над индексами B-Tree является размер ключа. Поскольку индексы B-Tree хранят фактические значения ключа а структуре индекса, индекс может сильно разрастись. Индексы B-Tree также имеют ограничения на длину ключа, который они хранят. Хэш-индексы, в свою очередь, не хранят фактические значения ключа, а только 4-байтовые хэшированные значения ключа со знаком.
И последним преимуществом хэш-индексов над индексами B-Tree состоит в том, что на размер хэш-индекса не влияет, насколько селективным является значение ключа индекса.
Использование B-tree и хэш-индексов
B-Tree индексы обычно выбираются в большинстве реализаций PostgreSQL, поскольку он позволяют выполнять быстрый поиск и сортировку данных, имеют небольшие накладные расходы и хороши при поиске на неравенство. Хэш-индексы представляют собой структуры данных, разработанные для возвращения единственной записи при поиске на равенство. В силу многих ограничений и того факта, что они лишь недавно стали поддерживать транзакции, хэш-индексы не так широко применяются в большинстве промышленных баз данных PostgreSQL. Однако, поскольку они оптимизируют поиск единственной записи, то могут быть великолепны в производственных средах, в которых в значительной степени требуется быстрый поиск отдельной записи.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой