
Поиск в индексе (Index Seek)
Пересказ статьи Hugo Kornelis. Index Seek
Введение
Оператор Index Seek использует структуру некластеризованного индекса для эффективного поиска как отдельных строк (singleton seek), так и конкретных подмножеств строк (range seek). ( Когда SQL Server требуется прочитать отдельные строки или небольшие подмножества строк из кластеризованного индекса, он использует другой оператор: Clustered Index Seek).
Index Seek часто используется в сочетании с оператором Nested Loops в операторе Key Lookup или в операторе RID Lookup. В одном из таких сочетаний Index Seek используется для быстрого нахождения требуемых строк, а затем Lookup используется для извлечения дополнительных данных из столбцов, которые не входят в структуру индекса. Некластеризованный индекс называется покрывающим для запроса, если все необходимые запросу данные могут быть прочитаны непосредственно из самого индекса, избегая необходимости в Lookup.
Хотя общая логика оператора Index Seek всегда одна и та же, конкретное действие, а также доступные оптимизатору опции, меняются в зависимости от типа используемого индекса (что указывается в свойствах Storage и IndexKind). Большая часть логики выполняется на уровне движка хранилища. Поскольку это важно для правильного понимания производительности данного оператора, фактически выполняемые на уровне движка хранилища действия будут также описаны в этой статье.
SQL Server 2017 поддерживает четыре типа хранения индексов. Свойство Storage может иметь значения RowStore, ColumnStore и MemoryOptimized; для последнего типа последующее разделение показывается только в IndexKind, принимающего значения NonClustered или NonClusteredHash.
Оператор Index Seek не может использоваться с индексами поколоночного хранения (ColumnStore), поэтому здесь мы будем обсуждать только поведение Index Seek с (некластеризованными) индексами построчного хранения и с оптимизированными для памяти индексами (как обычными некластеризованными, так и некластеризованными хеш-индексами).
В зависимости от используемого инструментария, оператор Index Seek может на графическом плане выполнения выглядеть так:
SQL Server Management Studio (версия 17.4 и выше)

SQL Server Management Studio (до версии 17.3)

Azure Data Studio
Plan Explorer
Базовый алгоритм оператора Index Seek показан ниже.
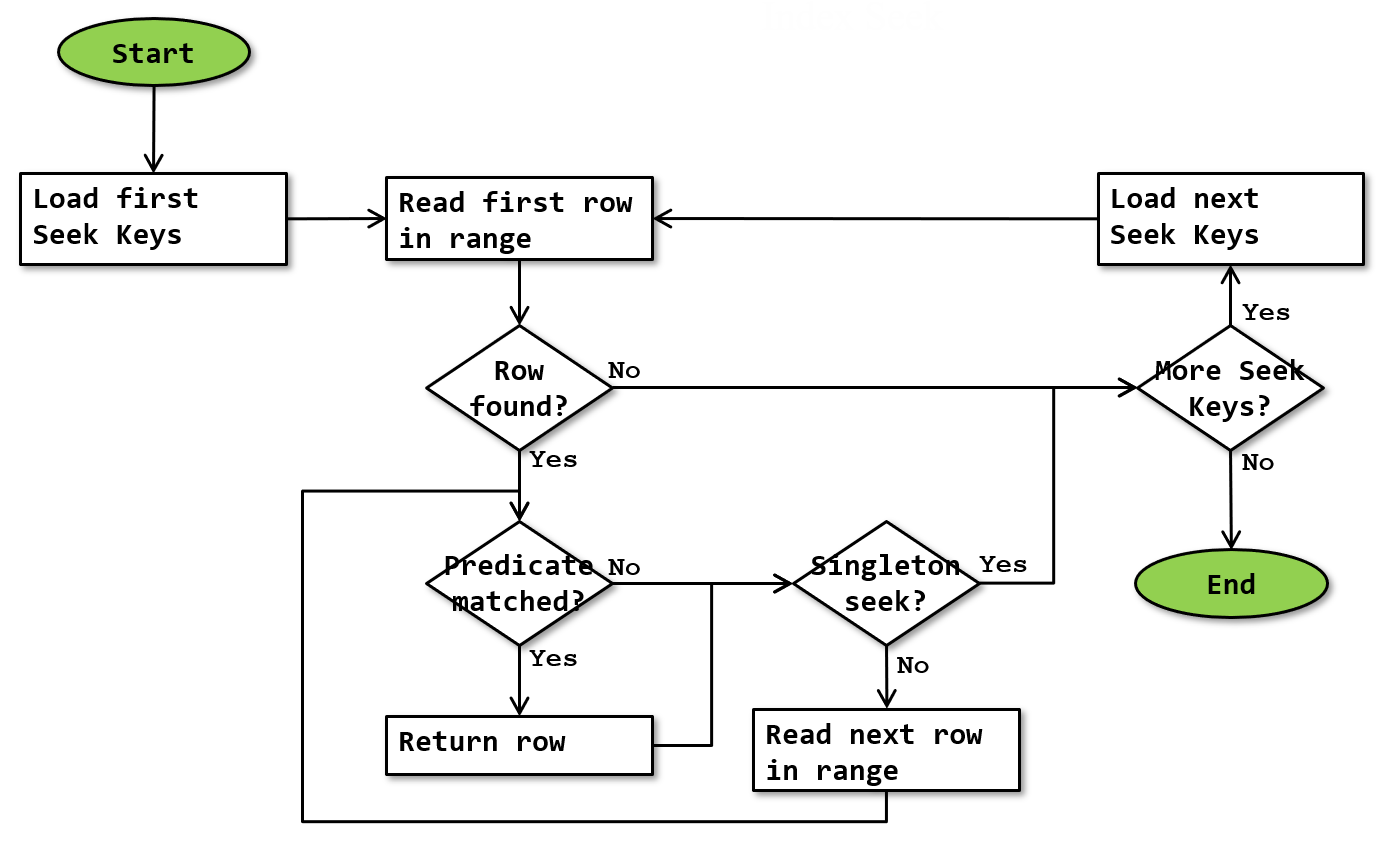
Заметим, что это упрощенная схема. Она не показывает, что выполнение останавливается при каждом возвращении строки и возобновляется с этого места при последующем вызове.
Отметим также, что в зависимости от уровня изоляции транзакций, который влияет на чтение индекса, могут накладываться и сниматься блокировки по мере доступа к строкам. Эта часть является стороной ответственности движка хранилища, и подробное изложение данной функциональности лежит за рамками данной статьи.
Каждый оператор Index Seek имеет свойство Seek Predicates (поисковые предикаты), которое содержит один или более элементов, называемых ключами поиска. Каждый ключ поиска может специфицировать префикс, диапазон, или и то, и другое. (Комбинация префикса и диапазона возможна только в том случае, если Index Seek используется в составном индексе).
Спецификация префикса элемента Seek Keys обеспечивает условие равенства одного или более крайних слева столбцов в индексе. Поэтому, например, если индекс построен на трех столбцах, то спецификация префикса может применяться только к самому крайнему слева столбцу, двум крайним слева столбцам или ко всем трем столбцам. Условие префикса обычно отображается в форме (SSMS) "Prefix: Столбцы = Выражения", где Столцы - список через точку с запятой столбцов, которые проиндексированы индексом, в котором ведется поиск, а Выражения - список через точку с запятой значений, по количеству равном количеству столбцов в Столбцы. Заметим, что выражения могут включать специальное значение “Scalar Operator (NULL)”, которое будет интерпретироваться как "IS NULL".
Index Seek будет возвращать только те строки, для которых значения в указанных столбцах равны значениям в соответствующих выражениях, дополнительно сокращаемым далее спецификацией диапазона.
Спецификация диапазона элемента Seek Keys используется для задания диапазона строк в пределах префикса или, в случае отсутствия префикса, задания диапазона строк в пределах всего индекса. Спецификация диапазона может применяться к столбцу, который в определении индекса следует сразу за последним столбцом спецификации префикса (подразумевая, что при отсутствии спецификации префикса спецификация диапазона может применяться только к крайнему левому столбцу в определении индекса). Обычно спецификация индекса состоит из условия начала и конца, хотя также можно увидеть спецификацию диапазона, которая имеет только условие начала или только конца. Здесь также имеется специальный случай: условие “IsNotNull”.
Условие начала спецификации диапазона отображается в SSMS в форме "Start: Столбец Оп Выражение", где Столбец задает используемый столбец (всегда первый стоблец в определении индекса после столбцов, используемых в спецификации префикса), Оп задает оператор (которым для большинства индексов является либо >, либо >=, но и < или <= для индексов, которые построены при сортировке по убыванию), и Выражение задает начальное значение.
Если диапазон указан без начального условия и не использует условие “IsNotNull”, он начинается с первой строки индекса, которая отвечает спецификации префикса, или самой первой строки в индексе, если
спецификация префикса отсутствует.
Условие конца спецификации диапазона отображается в SSMS в форме "End: Столбец Оп Выражение", где Столбец задает используемый столбец (всегда первый столбец в определении индекса после столбцов, используемых в спецификации префикса), Оп задает оператор (которым для большинства индексов является либо <, либо <=, но и > или >= для индексов, которые построены при сортировке по убыванию), и Выражение задает конечное значение.
Если диапазон указан без конечного условия и не использует условие “IsNotNull”, он заканчивается сразу после последней строки индекса, которая отвечает спецификации префикса, или самой последней строки в индексе, если спецификация префикса отсутствует.
Специальное условие “IsNotNull” некорректно отображается во всплывающей подсказке SSMS: она показывается пустой строкой в Seek Keys, если нет префиксного условия, а если есть префиксное условие, то отображается только это условие, а условие IsNotNull не отображается вообще. Хотя и полное окно свойств не показывает это условие корректно.
Условие IsNotNull перечисляет один столбец (всегда первый столбец в определении индекса после столбцов, используемых в спецификации префикса), и указывает, что все ненулевые значения в этом столбце являются частью диапазона. Поскольку значения NULL хранятся первыми в индексе, условие IsNotNull эквивалентно обычной спецификации диапазона, который начинается с первого не NULL значения и не имеет условия конца; или для индекса, построенного в убывающем порядке, спецификации диапазона, который не имеет начального условия и заканчивается на последнем не NULL значении.
Заметим, что условие IsNotNull не может сочетаться с условием Start или End.
Также отметим, что здесь не существует условия IsNULL. Если Index Seek используется для нахождения NULL-значений, он будет использовать спецификацию префикса. Даже если условие будет показано как "Столбец = Scalar Operator (NULL)" в исполнении плана выполнения SSMS, оператор будет фактически применять ожидаемую логику IS NULL.
Каждая спецификация Seek Keys может быть либо для "единичного поиска", либо для "поиска диапазона". Единичный поиск применяется, когда максимум одна строка может удовлетворять требованиям спецификации Seek Keys. Поиск диапазона означает, что (потенциально) более одной строки может быть квалифицировано.
Для единичного поиска, чтобы найти строку, которая отвечает заданному условию, используется структура индекса. Если строка существует, она возвращается , после чего оператор сразу переходит к следующей спецификации Seek Keys. Если нет, то ничего не возвращается и оператор переходит к следующей спецификации Seek Keys. Спецификация Seek Keys считает поиск единичным, если имеют место все перечисленные ниже условия:
Для поиска диапазона структура индекса используется для поиска первой строки, которая отвечает заданному условию. Если она существует, то возвращается, и затем оператор переключает поведение на то, которое подобно оператору Index Scan (сканирование индекса), для нахождения остальных строк, отвечающих условию. Как только обнаруживается строка, которая больше не квалифицируется (или если вообще не найдено квалификационных строк), он переходит к следующей спецификации Seek Keys. Спецификация Seek Keys считает поиск поиском диапазона, если он не отвечает требованиям единичного поиска.
Оператор Index Seek поддерживает необязательное свойство Predicate, которое может использоваться для продвижения логики дополнительного фильтра, которая не может использоваться для сокращения числа строк при доступе к индексу, но может использоваться для сокращения числа строк, возвращаемых оператором в его родительский оператор. Предполагается (но не документировано), что эта логика, где это возможно, переносится в движок хранилища.
Свойство Predicate, как правило, будет использоваться для фильтров на индексированных столбцах, для которых структура хранилища не дает преимуществ, фильтров на включенных столбцах или фильтров в составных индексах, например, на третьем столбце, когда нет условия равенства для первого и второго столбца вместе.
Схема выше показывает основные этапы обработки Index Seek. Как говорилось выше, некоторые действия могут варьироваться в зависимости от типа индекса, который используется в Index Seek. В параграфах ниже описывается различное поведение действий “Read first row in range” (прочитать первую строку в диапазоне) и “Read next row in range” (прочитать следующую строку в диапазоне) в зависимости от типа индекса.
Для построчного некластеризованного индекса (Storage = “RowStore” и IndexKind = “NonClustered”) оператор Index Seek использует структуру индекса B-Tree (сбалансированное дерево) для нахождения возвращаемых строк. B-Tree имеет единственную так называемую корневую страницу, которая содержит указатели либо на один, либо на большее число уровней промежуточных индексных страниц, или листовых страниц, на которых хранятся сами данные индекса. Более детальное обсуждение структуры B-Tree выходит за рамки настоящей статьи.
Описанное здесь применяется, когда свойство Scan Direction установлено в FORWARD. В случае BACKWARD роли условий Range Start и Range End меняются, и все страницы (корневая, промежуточные и листовая) обрабатываются в обратном логическом порядке.
Внутренние структуры данных (которае можно увидеть с помощью представления sys.sysindexes) используются для нахождения размещения корневой страницы. Она заносится в буферный пул и выполняется сравнение значений проиндексированных столбцов с каждой записью (в правильном логическом порядке на основе таблицы смещений строк на странице) с текущей спецификацией в Seek Keys. Как только обнаруживается запись, для которой значения в столбцах в условиях Prefix и Range Start равны или больше (меньше при индексированных столбцах по убыванию) указанных в спецификации значений, выполняется переход к одной записи назад (к последней записи, которая не удовлетворяет условиям) для нахождения страницы, для обработки на следующем более низком уровне. (Если самый первый вход уже отвечает условиям, тогда не существует предыдущего входа, и переход выполняется по первой записи).
Теперь страница на следующем более низком уровне перемещается для обработки в буферный пул и проверяется её заголовок. Если страница находится на промежуточном уровне индекса, она обрабатывается так же, как и корневая страница, для нахождения страницы на следующем нижнем уровне. Этот процесс повторяется до тех пор, пока не будет получена листовая страница.
Как только будет обнаружена листовая страница, значения индексированных столбцов в каждой строке еще раз сравниваются (в правильном логическом порядке на основе таблицы смещений строк на странице) со спецификациями в текущей спецификации Seek Keys, пока не будет найдена строка, для которой значения во всех столбцах в условиях Prefix и Range Start равны или больше (меньше для индексных столбцов по убыванию), чем указанные в спецификации значения. Тогда эта строка является первой строкой в диапазоне. В противном случае, указанный диапазон не содержит строк.
Для поиска диапазона следующий вызов Index Seek использует таблицу смещения строк на текущей странице для нахождения местоположения следующей строки. Если обработана последняя строка на текущей странице, проверяется указатель NextPage на текущей листовой странице для нахождения следующей в логическом порядке листовой страницы, эта страница переносится в буферный пул, а затем опять используется таблица смещения строк на этой странице для нахождения и возвращения первой строки.
Для каждой таким образом найденной строки значения столбцов сравниваются со значениями в условиях Prefix и Range End. Как только обнаруживается строка, которая не удовлетворяет этим условиям, или достигается последняя строка на листовой странице, и это строка имеет nil-указаталь в NextPage, то достигнут конец диапазона (или данных индекса), и никакие строки больше не возвращаются.
Для построчного некластеризованного индекса (Storage = “RowStore” и IndexKind = “NonClustered”) оператор Index Seek использует структуру индекса Bw-tree для запуска сканирования. Детальное обсуждение структуры Bw-tree выходит за рамки этой статьи, но, поскольку она очень похожа на структуру B-tree построчных индексов, процессы её чтения также похожи.
Сначала оператор использует внутреннюю структуру данных (выходящую за рамки статьи) для нахождения таблицы сопоставления страниц (PMT) индекса, затем использует её для нахождения местоположения в памяти текущей версии корневой страницы. На этой странице он читает значения индексированных столбцов в каждой записи (в правильном логическом порядке) и сравнивает их со спецификациями в оцениваемой спецификации Seek Keys. Как только он находит запись, для которой значения всех столбцов в условиях Prefix и Range Start равны или больше (меньше для сортировки индексных столбцов по убыванию), чем заданные значения, он возвращается назад на одну запись (последнюю запись, которая не соответствует этим условиям) для нахождения указателя на индексную страницу на следующем для обработки более низком уровне. (Если самая первая запись уже отвечает условиям, тогда не существует предыдущей записи, и переход выполняется по первой записи).
Выполняется переход (опять с помощью PMT) на нелистовую страницу. Данные на этой странице обрабатывается так же, как и корневая страница, для нахождения страницы на следующем нижнем уровне. Этот процесс повторяется до тех пор, пока не будет получена листовая страница.
Как только будет обнаружена листовая страница, значения индексированных столбцов в каждой строке еще раз сравниваются (в правильном логическом порядке) со спецификациями в текущей спецификации Seek Keys, пока не будет найдена строка, для которой значения во всех столбцах в условиях Prefix и Range Start равны или больше (меньше для индексных столбцов по убыванию), чем указанные в спецификации значения. Тогда, если также столбцы Prefix и Range End для этой строки равны или меньше (больше для убывающего порядка индексных столбцов), чем заданные значения, эта строка является первой строкой в диапазоне. Оператор использует указатель для нахождения первой строки для этого значения индекса и использует значения timestamp (временной метки) для проверки видимости строки для текущей транзакции. В противном случае, выполняется переход по указателю на следующую строку, и процесс повторяется. Если видимая строка найдена, то эта строка возвращается оператору.
При следующем вызове Index Seek выполняется переход по указателю в текущей строке на следующую строку и используется значение timestamp этой строки для определения видимости строки для текущей транзакции. Если строка видна, то она возвращается. В противном случае, проверяется следующая строка в цепочке указателей. Если достигается конец цепочки указателей, то сканирование возвращается к текущей листовой странице индекса, перемещается к следующему значению в индексе (переходя к логически следующей листовой странице, когда текущая страница исчерпана), и проверяются условия Prefix и Range End conditions. Если значение находится все еще в диапазоне, то оператор снова стартует со следующего указателя в цепочке.
Процесс завершается, как только обрабатывается индексная запись, которая не отвечает спецификации Prefix и Range End, или когда заканчивается последняя листовая страница (та, которая имеет nil указатель на следующую страницу).
Оптимизированный для памяти некластеризованный хеш-индекс (Storage=“MemoryOptimized” и IndexKind=“NonClusteredHash”) использует хеш-таблицу для хранения данных. Неравенство и сравнение диапазонов не работает на этой структуре, поэтому Index Seek на оптимизированном для памяти некластеризованном хеш-индексе будет использовать только условия префикса в спецификациях Seek Keys, и в случае составного индекса условие префикса должно включать все индексированные столбцы.
Оператор использует внутреннюю структуру данных (выходит за рамки статьи) для нахождения начала внутренней хеш-таблицы для индекса. Он вычисляет хеш целевых значений, указанных в условии префикса спецификации Seek Keys, вычисляет место в памяти соответствующего хеш-блока, и читает его.
Если хеш-блок имеет nil-указатель, то в заданном диапазоне нет строк. В противном случае оператор переходит по указателю и проверяет значения временной метки найденной строки на предмет видимости строки для текущей транзакции. Если строка не видна, то выполняется переход по указателю на следующую строку, и процесс повторяется. Если видимая строка обнаружена, то эта строка возвращается оператору.
Для получения следующей строки оператор перемещается по указателю в текущей строке на следующую строку и проверяет её значения временной метки на предмет видимости для текущей транзакции. Если она видна, строка возвращается. В противном случае, проверяется следующая строка в цепочке указателей. Если достигнут конец цепочки указателей, то достигнут и конец диапазона, и никаких больше строк не возвращается для текущей спецификации Seek Keys.
Нижеприведенные свойства специфичны для оператора Index Seek или же имеют специфичный для него смысл. Относительно всех других свойств обратитесь к "Общие свойства". Свойства, которые находятся на странице общих свойств, но также включены ниже по причине специфики их смысла для оператора Index Seek, отмечаются значком *.
В таблице ниже перечислено поведение неявных свойств для оператора Index Seek.
Хотя общая логика оператора Index Seek всегда одна и та же, конкретное действие, а также доступные оптимизатору опции, меняются в зависимости от типа используемого индекса (что указывается в свойствах Storage и IndexKind). Большая часть логики выполняется на уровне движка хранилища. Поскольку это важно для правильного понимания производительности данного оператора, фактически выполняемые на уровне движка хранилища действия будут также описаны в этой статье.
SQL Server 2017 поддерживает четыре типа хранения индексов. Свойство Storage может иметь значения RowStore, ColumnStore и MemoryOptimized; для последнего типа последующее разделение показывается только в IndexKind, принимающего значения NonClustered или NonClusteredHash.
Оператор Index Seek не может использоваться с индексами поколоночного хранения (ColumnStore), поэтому здесь мы будем обсуждать только поведение Index Seek с (некластеризованными) индексами построчного хранения и с оптимизированными для памяти индексами (как обычными некластеризованными, так и некластеризованными хеш-индексами).
Визуальное представление планов выполнения
В зависимости от используемого инструментария, оператор Index Seek может на графическом плане выполнения выглядеть так:
SQL Server Management Studio (версия 17.4 и выше)
SQL Server Management Studio (до версии 17.3)
Azure Data Studio
Plan Explorer
Алгоритм
Базовый алгоритм оператора Index Seek показан ниже.
Заметим, что это упрощенная схема. Она не показывает, что выполнение останавливается при каждом возвращении строки и возобновляется с этого места при последующем вызове.
Отметим также, что в зависимости от уровня изоляции транзакций, который влияет на чтение индекса, могут накладываться и сниматься блокировки по мере доступа к строкам. Эта часть является стороной ответственности движка хранилища, и подробное изложение данной функциональности лежит за рамками данной статьи.
Ключи поиска (Seek Keys)
Каждый оператор Index Seek имеет свойство Seek Predicates (поисковые предикаты), которое содержит один или более элементов, называемых ключами поиска. Каждый ключ поиска может специфицировать префикс, диапазон, или и то, и другое. (Комбинация префикса и диапазона возможна только в том случае, если Index Seek используется в составном индексе).
Спецификация префикса
Спецификация префикса элемента Seek Keys обеспечивает условие равенства одного или более крайних слева столбцов в индексе. Поэтому, например, если индекс построен на трех столбцах, то спецификация префикса может применяться только к самому крайнему слева столбцу, двум крайним слева столбцам или ко всем трем столбцам. Условие префикса обычно отображается в форме (SSMS) "Prefix: Столбцы = Выражения", где Столцы - список через точку с запятой столбцов, которые проиндексированы индексом, в котором ведется поиск, а Выражения - список через точку с запятой значений, по количеству равном количеству столбцов в Столбцы. Заметим, что выражения могут включать специальное значение “Scalar Operator (NULL)”, которое будет интерпретироваться как "IS NULL".
Index Seek будет возвращать только те строки, для которых значения в указанных столбцах равны значениям в соответствующих выражениях, дополнительно сокращаемым далее спецификацией диапазона.
Спецификация диапазона
Спецификация диапазона элемента Seek Keys используется для задания диапазона строк в пределах префикса или, в случае отсутствия префикса, задания диапазона строк в пределах всего индекса. Спецификация диапазона может применяться к столбцу, который в определении индекса следует сразу за последним столбцом спецификации префикса (подразумевая, что при отсутствии спецификации префикса спецификация диапазона может применяться только к крайнему левому столбцу в определении индекса). Обычно спецификация индекса состоит из условия начала и конца, хотя также можно увидеть спецификацию диапазона, которая имеет только условие начала или только конца. Здесь также имеется специальный случай: условие “IsNotNull”.
Начало диапазона
Условие начала спецификации диапазона отображается в SSMS в форме "Start: Столбец Оп Выражение", где Столбец задает используемый столбец (всегда первый стоблец в определении индекса после столбцов, используемых в спецификации префикса), Оп задает оператор (которым для большинства индексов является либо >, либо >=, но и < или <= для индексов, которые построены при сортировке по убыванию), и Выражение задает начальное значение.
Если диапазон указан без начального условия и не использует условие “IsNotNull”, он начинается с первой строки индекса, которая отвечает спецификации префикса, или самой первой строки в индексе, если
спецификация префикса отсутствует.
Конец диапазона
Условие конца спецификации диапазона отображается в SSMS в форме "End: Столбец Оп Выражение", где Столбец задает используемый столбец (всегда первый столбец в определении индекса после столбцов, используемых в спецификации префикса), Оп задает оператор (которым для большинства индексов является либо <, либо <=, но и > или >= для индексов, которые построены при сортировке по убыванию), и Выражение задает конечное значение.
Если диапазон указан без конечного условия и не использует условие “IsNotNull”, он заканчивается сразу после последней строки индекса, которая отвечает спецификации префикса, или самой последней строки в индексе, если спецификация префикса отсутствует.
IsNotNull
Специальное условие “IsNotNull” некорректно отображается во всплывающей подсказке SSMS: она показывается пустой строкой в Seek Keys, если нет префиксного условия, а если есть префиксное условие, то отображается только это условие, а условие IsNotNull не отображается вообще. Хотя и полное окно свойств не показывает это условие корректно.
Условие IsNotNull перечисляет один столбец (всегда первый столбец в определении индекса после столбцов, используемых в спецификации префикса), и указывает, что все ненулевые значения в этом столбце являются частью диапазона. Поскольку значения NULL хранятся первыми в индексе, условие IsNotNull эквивалентно обычной спецификации диапазона, который начинается с первого не NULL значения и не имеет условия конца; или для индекса, построенного в убывающем порядке, спецификации диапазона, который не имеет начального условия и заканчивается на последнем не NULL значении.
Заметим, что условие IsNotNull не может сочетаться с условием Start или End.
Также отметим, что здесь не существует условия IsNULL. Если Index Seek используется для нахождения NULL-значений, он будет использовать спецификацию префикса. Даже если условие будет показано как "Столбец = Scalar Operator (NULL)" в исполнении плана выполнения SSMS, оператор будет фактически применять ожидаемую логику IS NULL.
Единичный поиск против поиска диапазона
Каждая спецификация Seek Keys может быть либо для "единичного поиска", либо для "поиска диапазона". Единичный поиск применяется, когда максимум одна строка может удовлетворять требованиям спецификации Seek Keys. Поиск диапазона означает, что (потенциально) более одной строки может быть квалифицировано.
Для единичного поиска, чтобы найти строку, которая отвечает заданному условию, используется структура индекса. Если строка существует, она возвращается , после чего оператор сразу переходит к следующей спецификации Seek Keys. Если нет, то ничего не возвращается и оператор переходит к следующей спецификации Seek Keys. Спецификация Seek Keys считает поиск единичным, если имеют место все перечисленные ниже условия:
- Индекс, который использует Index Seek, должен быть объявлен как UNIQUE;
- Seek Keys не должен иметь спецификации диапазона (что подразумевает наличие спецификации префикса);
- Спецификация Prefix должна предоставить значения для всех столбцов в спецификации индекса, поэтому, если индекс имеет 3 столбца, все три должны включаться в спецификацию Prefix для Seek Keys.
Для поиска диапазона структура индекса используется для поиска первой строки, которая отвечает заданному условию. Если она существует, то возвращается, и затем оператор переключает поведение на то, которое подобно оператору Index Scan (сканирование индекса), для нахождения остальных строк, отвечающих условию. Как только обнаруживается строка, которая больше не квалифицируется (или если вообще не найдено квалификационных строк), он переходит к следующей спецификации Seek Keys. Спецификация Seek Keys считает поиск поиском диапазона, если он не отвечает требованиям единичного поиска.
Предикат
Оператор Index Seek поддерживает необязательное свойство Predicate, которое может использоваться для продвижения логики дополнительного фильтра, которая не может использоваться для сокращения числа строк при доступе к индексу, но может использоваться для сокращения числа строк, возвращаемых оператором в его родительский оператор. Предполагается (но не документировано), что эта логика, где это возможно, переносится в движок хранилища.
Свойство Predicate, как правило, будет использоваться для фильтров на индексированных столбцах, для которых структура хранилища не дает преимуществ, фильтров на включенных столбцах или фильтров в составных индексах, например, на третьем столбце, когда нет условия равенства для первого и второго столбца вместе.
Изменения в зависимости от типа индекса
Схема выше показывает основные этапы обработки Index Seek. Как говорилось выше, некоторые действия могут варьироваться в зависимости от типа индекса, который используется в Index Seek. В параграфах ниже описывается различное поведение действий “Read first row in range” (прочитать первую строку в диапазоне) и “Read next row in range” (прочитать следующую строку в диапазоне) в зависимости от типа индекса.
Построчное хранение
Для построчного некластеризованного индекса (Storage = “RowStore” и IndexKind = “NonClustered”) оператор Index Seek использует структуру индекса B-Tree (сбалансированное дерево) для нахождения возвращаемых строк. B-Tree имеет единственную так называемую корневую страницу, которая содержит указатели либо на один, либо на большее число уровней промежуточных индексных страниц, или листовых страниц, на которых хранятся сами данные индекса. Более детальное обсуждение структуры B-Tree выходит за рамки настоящей статьи.
Описанное здесь применяется, когда свойство Scan Direction установлено в FORWARD. В случае BACKWARD роли условий Range Start и Range End меняются, и все страницы (корневая, промежуточные и листовая) обрабатываются в обратном логическом порядке.
Чтение первой строки в диапазоне
Внутренние структуры данных (которае можно увидеть с помощью представления sys.sysindexes) используются для нахождения размещения корневой страницы. Она заносится в буферный пул и выполняется сравнение значений проиндексированных столбцов с каждой записью (в правильном логическом порядке на основе таблицы смещений строк на странице) с текущей спецификацией в Seek Keys. Как только обнаруживается запись, для которой значения в столбцах в условиях Prefix и Range Start равны или больше (меньше при индексированных столбцах по убыванию) указанных в спецификации значений, выполняется переход к одной записи назад (к последней записи, которая не удовлетворяет условиям) для нахождения страницы, для обработки на следующем более низком уровне. (Если самый первый вход уже отвечает условиям, тогда не существует предыдущего входа, и переход выполняется по первой записи).
Теперь страница на следующем более низком уровне перемещается для обработки в буферный пул и проверяется её заголовок. Если страница находится на промежуточном уровне индекса, она обрабатывается так же, как и корневая страница, для нахождения страницы на следующем нижнем уровне. Этот процесс повторяется до тех пор, пока не будет получена листовая страница.
Как только будет обнаружена листовая страница, значения индексированных столбцов в каждой строке еще раз сравниваются (в правильном логическом порядке на основе таблицы смещений строк на странице) со спецификациями в текущей спецификации Seek Keys, пока не будет найдена строка, для которой значения во всех столбцах в условиях Prefix и Range Start равны или больше (меньше для индексных столбцов по убыванию), чем указанные в спецификации значения. Тогда эта строка является первой строкой в диапазоне. В противном случае, указанный диапазон не содержит строк.
Чтение следующей строки в диапазоне
Для поиска диапазона следующий вызов Index Seek использует таблицу смещения строк на текущей странице для нахождения местоположения следующей строки. Если обработана последняя строка на текущей странице, проверяется указатель NextPage на текущей листовой странице для нахождения следующей в логическом порядке листовой страницы, эта страница переносится в буферный пул, а затем опять используется таблица смещения строк на этой странице для нахождения и возвращения первой строки.
Для каждой таким образом найденной строки значения столбцов сравниваются со значениями в условиях Prefix и Range End. Как только обнаруживается строка, которая не удовлетворяет этим условиям, или достигается последняя строка на листовой странице, и это строка имеет nil-указаталь в NextPage, то достигнут конец диапазона (или данных индекса), и никакие строки больше не возвращаются.
Оптимизированный для памяти (некластеризованный)
Для построчного некластеризованного индекса (Storage = “RowStore” и IndexKind = “NonClustered”) оператор Index Seek использует структуру индекса Bw-tree для запуска сканирования. Детальное обсуждение структуры Bw-tree выходит за рамки этой статьи, но, поскольку она очень похожа на структуру B-tree построчных индексов, процессы её чтения также похожи.
Чтение первой строки в диапазоне
Сначала оператор использует внутреннюю структуру данных (выходящую за рамки статьи) для нахождения таблицы сопоставления страниц (PMT) индекса, затем использует её для нахождения местоположения в памяти текущей версии корневой страницы. На этой странице он читает значения индексированных столбцов в каждой записи (в правильном логическом порядке) и сравнивает их со спецификациями в оцениваемой спецификации Seek Keys. Как только он находит запись, для которой значения всех столбцов в условиях Prefix и Range Start равны или больше (меньше для сортировки индексных столбцов по убыванию), чем заданные значения, он возвращается назад на одну запись (последнюю запись, которая не соответствует этим условиям) для нахождения указателя на индексную страницу на следующем для обработки более низком уровне. (Если самая первая запись уже отвечает условиям, тогда не существует предыдущей записи, и переход выполняется по первой записи).
Выполняется переход (опять с помощью PMT) на нелистовую страницу. Данные на этой странице обрабатывается так же, как и корневая страница, для нахождения страницы на следующем нижнем уровне. Этот процесс повторяется до тех пор, пока не будет получена листовая страница.
Как только будет обнаружена листовая страница, значения индексированных столбцов в каждой строке еще раз сравниваются (в правильном логическом порядке) со спецификациями в текущей спецификации Seek Keys, пока не будет найдена строка, для которой значения во всех столбцах в условиях Prefix и Range Start равны или больше (меньше для индексных столбцов по убыванию), чем указанные в спецификации значения. Тогда, если также столбцы Prefix и Range End для этой строки равны или меньше (больше для убывающего порядка индексных столбцов), чем заданные значения, эта строка является первой строкой в диапазоне. Оператор использует указатель для нахождения первой строки для этого значения индекса и использует значения timestamp (временной метки) для проверки видимости строки для текущей транзакции. В противном случае, выполняется переход по указателю на следующую строку, и процесс повторяется. Если видимая строка найдена, то эта строка возвращается оператору.
Чтение следующей строки в диапазоне
При следующем вызове Index Seek выполняется переход по указателю в текущей строке на следующую строку и используется значение timestamp этой строки для определения видимости строки для текущей транзакции. Если строка видна, то она возвращается. В противном случае, проверяется следующая строка в цепочке указателей. Если достигается конец цепочки указателей, то сканирование возвращается к текущей листовой странице индекса, перемещается к следующему значению в индексе (переходя к логически следующей листовой странице, когда текущая страница исчерпана), и проверяются условия Prefix и Range End conditions. Если значение находится все еще в диапазоне, то оператор снова стартует со следующего указателя в цепочке.
Процесс завершается, как только обрабатывается индексная запись, которая не отвечает спецификации Prefix и Range End, или когда заканчивается последняя листовая страница (та, которая имеет nil указатель на следующую страницу).
Оптимизированный для памяти (NonClusteredHash)
Оптимизированный для памяти некластеризованный хеш-индекс (Storage=“MemoryOptimized” и IndexKind=“NonClusteredHash”) использует хеш-таблицу для хранения данных. Неравенство и сравнение диапазонов не работает на этой структуре, поэтому Index Seek на оптимизированном для памяти некластеризованном хеш-индексе будет использовать только условия префикса в спецификациях Seek Keys, и в случае составного индекса условие префикса должно включать все индексированные столбцы.
Чтение первой строки в диапазоне
Оператор использует внутреннюю структуру данных (выходит за рамки статьи) для нахождения начала внутренней хеш-таблицы для индекса. Он вычисляет хеш целевых значений, указанных в условии префикса спецификации Seek Keys, вычисляет место в памяти соответствующего хеш-блока, и читает его.
Если хеш-блок имеет nil-указатель, то в заданном диапазоне нет строк. В противном случае оператор переходит по указателю и проверяет значения временной метки найденной строки на предмет видимости строки для текущей транзакции. Если строка не видна, то выполняется переход по указателю на следующую строку, и процесс повторяется. Если видимая строка обнаружена, то эта строка возвращается оператору.
Чтение следующей строки в диапазоне
Для получения следующей строки оператор перемещается по указателю в текущей строке на следующую строку и проверяет её значения временной метки на предмет видимости для текущей транзакции. Если она видна, строка возвращается. В противном случае, проверяется следующая строка в цепочке указателей. Если достигнут конец цепочки указателей, то достигнут и конец диапазона, и никаких больше строк не возвращается для текущей спецификации Seek Keys.
Свойства оператора
Нижеприведенные свойства специфичны для оператора Index Seek или же имеют специфичный для него смысл. Относительно всех других свойств обратитесь к "Общие свойства". Свойства, которые находятся на странице общих свойств, но также включены ниже по причине специфики их смысла для оператора Index Seek, отмечаются значком *.
| Описание | |
|---|---|
| Defined Values (определенные значения) * | Для Index Seek это свойство перечисляет столбцы, прочитанные из индекса и возвращаемые в вызывающий оператор. Т.е. это то же самое, что и свойство Output List. |
| Estimated Number of Rows to be Read (оценка числа считываемых строк) | Это оценка числа строк, которое будет прочитано оператором при навигации по индексу. Чем выше разница между этим числом и Table Cardinality, тем более эффективным оценивается использование этого оператора (по сравнению с Index Scan). Разница между этим свойством и свойством Estimated Number of Rows представляет число строк, которые по оценке должны быть прочитаны, но не будут возвращены в силу свойства Predicate. |
| Forced Index (навязанный индекс) | Это свойство устанавливается в true, если использование этого индекса было навязано хинтом запроса. |
| ForceScan (навязанное сканирование) | Это свойство устанавливается в true, если запрос использовал хинт FORCESCAN для принудительного использования оператора сканирования, даже если оптимизатор предпочел бы использовать оператор поиска. Следовательно, в операторе Clustered Index Seek он всегда ложен. |
| ForceSeek (навязанный поиск) | Это свойство устанавливается в true, если запрос использовал хинт FORCESEEK для принудительного использования оператора поиска, даже если оптимизатор предпочел бы использовать оператор сканирования. |
| IndexKind (вид индекса) | Представляет тип сканируемого некластеризованного индекса; оно может быть либо NonClustered, либо NonClusteredHash. Замечу, что это свойство не отображается в списке SSMS, хотя тип индекса показывается в скобках под оператором. К свойству можно получить доступ в плане выполнения XML. |
| NoExpandHint | Это свойство устанавливается в true, если в запросе был использован хинт NOEXPAND для принуждения оптимизатора к использованию индексов на индексированном представлении. |
| Number of Rows Read (число чтений строк) | Это число строк, которые были прочитаны оператором при навигации по индексу. В параллельном плане выполнения это свойство показывает разбивку строк по каждому отдельному процессу. Разница между этим свойством и свойством Actual Number of Rows представляет число строк, которые были прочитаны, но не возвращены в силу свойства Predicate. Доступно только в плане выполнения плюс статистика времени выполнения. Когда число чтений строк равно нулю, это свойство опускается. |
| Object | Это свойство перечисляет индекс, по которому перемещается оператор Index Seek, используя именование из 4 частей (база, схема, таблица, индекс), и может иметь последующий алиас. |
| Ordered | Это свойство всегда равно True для Index Seek. |
| Predicate (предикат) | Если присутствует, это свойство определяет логическое выражение, которое должно применяться ко всем строкам, прочитанных оператором Index Seek. Возвращаются только те строки, для которых предикат оценивается как True. При возможности оператор Index Seek будет проталкивать этот предикат в движок хранилища, чтобы избежать лишних переходов между оператором и движком. Заметим, что Predicate для Index Seek не уменьшает числа строк, на которые воздействует оператор. Разница между Actual Number of Rows свойством Number of Rows Read (или их предварительными аналогами) показывает как много прочитанных строк не было возвращено. Это можно использовать для оценки полезности индекса относительно поддержки поисковых предикатов. |
| Scan Direction (направление сканирования) | Для поиска в диапазоне это свойство определяет, в каком порядке будут возвращаться данные - в обычном порядке индекса (“FORWARD”) или в обратном порядке (“BACKWARD”). Опция BACKWARD недоступна для индексов, оптимизированных для памяти. |
| Seek Predicates (поисковые предикаты) | Набор одного или более ключей поиска, которые используются для навигации по индексу и нахождения необходимых для чтения строк. |
| Storage (хранилище) | Это свойство определяет тип индекса, по которому выполняется навигация. (Отметим, что это также может быть определено с помощью DMV на основе свойства Object). Возможными значениями для Index Seek являются RowStore и MemoryOptimized. |
| Table Cardinality (кардинальное число таблицы) | Это свойство показывает число строк в проиндексированной таблице на момент компиляции плана. |
Неявные свойства
В таблице ниже перечислено поведение неявных свойств для оператора Index Seek.
| Название свойства | Описание |
|---|---|
| Batch Mode enabled (пакетный режим разрешен) | Оператор Index Seek поддерживает только построчный режим выполнения. |
| Blocking (блокировка) | Оператор Index Seek является неблокирующим. |
| Memory requirement (потребность в памяти) | Оператор Index Seek не предъявляет каких-либо особых требований к памяти. |
| Order-preserving (сохранение порядка) | Оператор Index Seek навязывает порядок, что определяется свойством Scan Direction. Если свойство Seek Predicates задает более одной спецификации Seek Keys, оптимизатор всегда гарантирует их соответствие правильному порядку. |
| Поддержка параллелизма | Когда оператор Index Seek используется для сканирования диапазонов в параллельной части плана выполнения, он использует “Parallel Page Supplier”. Смотрите детали для Index Scan. |
| Segment aware (поддержка сегментов) | Оператор Index Seek не поддерживает сегменты. |
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой