
Об использовании индексов
Индекс создается командой create index и непосредственно недоступен пользователю. Индексы используются оптимизатором запросов для доступа к данным в базовых таблицах и представлениях.
Индексы бывают двух видов - кластеризованные и некластеризованные. Некластеризованный индекс - это вспомогательная таблица, которая содержит данные столбца/столбцов (ключ индекса), по которым индексируется базовая таблица и указатель (RID) на данные в таблице, соответствующие этому ключу.
Кластеризованный индекс - это индекс, у которого на листовом уровне находятся сами табличные данные. Поскольку индекс содержит физически упорядоченные данные, то становится ясно, почему для каждой отдельной таблицы можно создать только один кластеризованный индекс.
Именно в силу упорядоченности данных индекс предоставляет более эффективный доступ по сравнению со сканированием таблицы к требуемым данным.
Поскольку речь идет о поиске по ключу, а кластеризованный индекс у нас только один (и, соответственно, только один ключ), то мы можем создать дополнительно некластеризованные индексы. Хорошей новостью является то, что таких индексов мы можем создать сколько угодно. Реально, конечно, их количество ограничено, но возможность создать несколько сотен индексов на одну таблицу может удовлетворить любым потребностям.
Индексы, как правило, имеют структуру B-Tree - древовидная иерарархическая структура - которая позволяет, наряду со сканированием индекса (index scan), использовать прямой доступ к данным - поиск по индексу (index seek). Эта структура используется как для кластеризованных, так и некластеризованных индексов. Различием между ними, повторю, является то, что на листовом уровне дерева у кластеризованного индекса находятся сами табличные данные, а у некластеризованного - указатели на данные в таблице.
Если сказанное выше вам не вполне понятно, могу порекомендовать хорошую статью Гейла Шоу (Gail Shaw. Introduction to Indexes).
Кластерный индекс создается автоматически на первичном ключе (который и является ключом индекса), если вы не укажите обратного.
Возьмем для примера таблицу utV (база данных «Окраска»), содержащую всего три столбца - v_id (идентификатор баллончика - первичный ключ), v_name (название баллончика) и v_color (цвет краски в баллончике). Как уже говорилось, на первичном ключе автоматически создается кластеризованный индекс, есть он и у нашей таблицы.
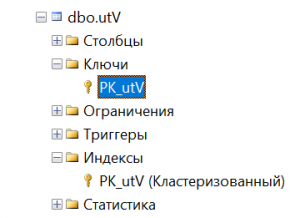
Рис.1 Кластеризованный индекс
Выполним три следующих запроса и посмотрим на планы их выполнения.
select v_id from utv;
select * from utv;
select v_name from utv;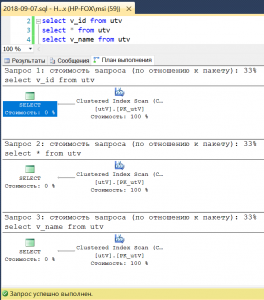
Рис.2 Сканирование кластеризованного индекса
Как вы можете убедиться, все эти запросы имеют одинаковый план выполнения, а именно – сканирование кластеризованного индекса, вне зависимости от того, данные всех столбцов нам нужны, или нет. Тут нет ничего удивительного, т.к. кроме кластеризованного индекса у нас ничего нет, а данные нужны из всех строк.
Давайте теперь заменим кластеризованный индекс некластеризованным, удалив сначала кластеризованный первичный ключ, и создав затем некластеризованный. Предварительно нам потребуется удалить внешний ключ из таблицы utB, который ссылается на первичный ключ таблицы utV:
alter table utB
drop constraint FK_utB_utV; --удаляем внешний ключ
alter table utV
drop constraint PK_utV; -- удаляем первичный ключ (кластеризованный индекс)
go
alter table utV
add constraint PK_utVn primary key nonclustered (v_id asc);Выполним теперь те же запросы, чтобы увидеть разницу:

Рис.3 Использование некластеризованного индекса
В двух последних случаях сканирование индекса изменилось на сканирование таблицы. И только в первом случае используется сканирование индекса. Это объясняется тем, что затребованные данные находятся в индексе (ключ индекса), и нет необходимости обращаться к самой таблице. Оптимизатор выбирает эту стратегию доступа, поскольку индекс имеет меньший размер, чем индексируемая таблица, и будет просматриваться быстрей, даже в нашем случае, когда нужны все его строки.
Рассмотрим теперь запросы на получение конкретной строки:
select v_id from utv where v_id = 15;
select v_name from utv where v_id = 15;Для выполнения первого запроса оптимизатором теперь выбирается поиск по индексу (index seek) – наиболее эффективная операция, поскольку это прямой доступ к данным с использованием структуры B-Tree. План для второго запроса помимо поиска по индексу содержит еще две операции. Это связано с тем, что мы в запросе хотим получить имя баллончика, а не его ИД, а в индексе содержится только v_id. Поэтому после нахождения строки с v_id = 15 выполняется обращение к таблице по RID-указателю, содержащемуся в индексе. Это прямая операция, которая называется поиском закладки (lookup). Последняя операция выполняет соединение полученных результатов. Тут следует заметить, что план читается справа налево.

Рис. 4 Поиск по индексу
Можно избежать лишней операции – поиска закладки, если включить в индекс требуемые запросом данные. Для этого мы удалим индекс PK_utVn и создадим вместо него новый.
alter table utV
drop constraint PK_utVn; -- удаляем индекс
/* создаем уникальный индекс (не первичный ключ) с включенным столбцом */
create unique nonclustered index IX_utVi on utV(v_id asc) include(v_name); Посмотрим план выполнения второго запроса.
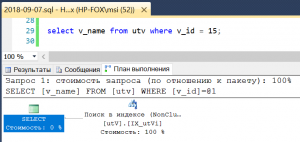
Рис. 5 Поиск по индексу с включенным столбцом
Как видим, теперь план не отличается от плана выполнения первого запроса.
Следует отметить, что последний индекс не является составным, т.е. индексом, построенным по двум столбцам – {v_id, v_name}. Составной индекс для данного запроса использовался бы аналогичным образом, но есть одно важное отличие. При изменении данных, в частности, значений v_name составной индекс пришлось бы перестраивать, а индекс с включенным столбцом – нет, поскольку по включенному столбцу не выполняется физическое упорядочивание. Таким образом, накладные расходы на поддержку индексов в случае индекса с включенными столбцами будут ниже. Преимущества же составного индекса мы рассмотрим позже.
Рассмотрим, наконец, самый плохой вариант – отсутствие индексов.
drop index IX_utVi on utV; -- удаляем индекс
go
select v_id from utv where v_id = 15;
select v_name from utv where v_id = 15;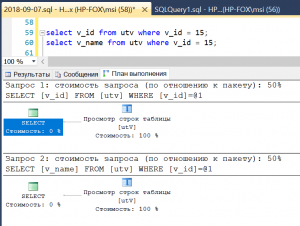
Рис.6 Сканирование таблицы при отсутствии индексов
Как и ожидалось, оба запроса выполняются сканированием таблицы, хотя должна быть получена максимум одна строка. Причем поиск будет продолжен даже после нахождения искомой строки, поскольку система не имеет информации о том, что значение v_id уникально.
Для сравнения планов выполнения давайте вернем индекс по столбцу v_id
alter table utV
add constraint PK_utVn primary key nonclustered (v_id asc);и выполним следующие запросы:
select v_id from utv where v_id = 15;
select v_id from utv where v_name= 'Balloon # 15';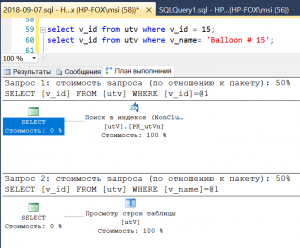
Рис.7 Выборка по столбцу без индекса
Эти запросы возвращают одно и то же, но в первом из них поисковым аргументом является столбец, имеющий индекс, а во втором – нет. Как и следовало ожидать, для первого запроса используется план с поиском по индексу, а для второго – сканирования таблицы. Не обращайте внимания на то, что стоимости планов выполнения запроса (cost) оцениваются оптимизатором одинаково. Причина в незначительном количестве данных, которые что в одном, что в другом случае, целиком будут находиться в оперативной памяти, и количество дисковых операций, которые оптимизируются сервером, будет эквивалентно. Это хороший пример того, что при оптимизации запросов нужно полагаться не на оценку стоимости, а читать план. В данном случае потенциальной потери производительности можно избежать, создав индекс на столбце v_name.
Давайте так и поступим, и выполним предыдущие запросы.
create index IX_utVname on utV(v_name);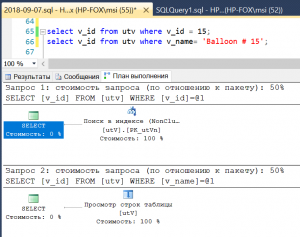
Рис. 8 Игнорирование неуникального индекса
Неожиданно? Мы ожидали, что будет использован поиск по индексу, а затем поиск закладки для нахождения значения v_id. Однако оптимизатор не использовал индекс на столбце v_name. Почему?
Причина, как я думаю, заключается в том, что индекс на столбце v_name не является уникальным. Т.е. оптимизатор полагает, что значений, отвечающих предикату v_name= 'Balloon # 15' может быть несколько. Тогда для каждого такого значения потребуется поиск закладки. Поскольку данных в таблице немного, оптимизатор решает не оценивать план с использованием индекса на основе имеющейся статистики о распределении значений в столбце v_name, а пойти по простому пути, сэкономив на оценке плана. Давайте проверим это предположение, создав уникальный индекс, полагая, что одинаковых названий нет и быть не должно.
drop index IX_utVname on utV;
create unique index IX_utVname on utV(v_name);
Рис.9 Использование уникального индекса
Теперь результат согласуется с нашими ожиданиями.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой