
Кучи в SQL Server: часть 1 - основы
Пересказ статьи Uwe Ricken. Heaps in SQL Server: Part 1 The Basics
Большинство советов, которые вы видите в сети, рекомендуют избегать куч (heap). В настоящей статье дается понятие кучи, и вы сами сможете определить, когда кучи являются лучшим выбором.
Пока эта серия состоит из:
- Кучи в SQL Server: часть 1 - основы (эта статья)
- Кучи в SQL Server: часть 2 - оптимизация чтений
- Кучи в SQL Server: часть 3 - некластеризованные индексы
Эта статья начальная в серии о кучах в Microsoft SQL Server. Кучи отвергаются многими разработчиками баз данных, использующих SQL Server. Недоверие к ним поддерживается самой Microsoft, обычно рекомендуя использовать кластеризованные индексы для каждой таблицы. Широко известные эксперты в SQL Server также обычно советуют, чтобы таблицы в Microsoft SQL Server снабжались кластеризованным индексом.
Снова и снова я пытаюсь убедить разработчиков, что куча может даже иметь преимущества. Я обсуждал много "за" и "против" с этими людьми, и хотел бы теперь поломать копья "ЗА КУЧУ". Эта статья посвящена основам. Важные объекты системы, которые играют значимую роль в кучах, здесь представлены лишь поверхностно, и подробно обсуждаются в последующих статьях.
В Microsoft SQL Server кучи избегаются так же, как дьявол избегает святой воды. Причина такого отказа заключается в том, что в статьях многих известных блогеров указывается, что таблица должна использовать кластеризованный индекс. В настоящей серии статей упор делается на максимально широком спектре положительного и отрицательного применения кучи. В результате вы должны решить для себя, имеет ли и когда имеет преимущество куча по сравнению с кластеризованным индексом. Чтобы принять решение, вы должны понимать метод работы и внутренние структуры.
Кучи - это таблицы без кластеризованного индекса. Без индекса никакая сортировка данных не гарантируется. Данные сохраняются на любом свободном месте без предопределенного порядка. Если таблица пустая, записи данных вносятся в таблицу в порядке, определяемом командами INSERT.
Скрипт создает новую таблицу для хранения данных клиентов и вставляет одну строку. Поскольку нет ни индекса, ни использования первичного ключа с опцией CLUSTERED, данные записываются "несортированными" в эту таблицу.
Если таблица не имеет кластеризованного индекса, кучу можно найти в системном представлении [sys].[Indexes], которая всегда имеет [Index_Id] = 0.

Рис.1: [index_id] = 0 и [index_id] = 1 зарезервировано для кучи и кластеризованного индекса соответственно
Поскольку кучи являются примитивным хранением данных, никакие сложные структуры не требуются для управления кучами. Кучи имеют одну строку в sys.partitions с [index_id] = 0 для каждой секции, используемой кучей. Когда куча разбита на множество секций, каждая секция имеет структуру кучи, которая содержит данные этой конкретной секции.
В зависимости от типов данных в куче, каждая структура кучи будет иметь одну или более единиц распределения для хранения и управления данными конкретной секции. По минимуму каждая куча будет иметь одну единицу распределения IN_ROW_DATA на секцию.
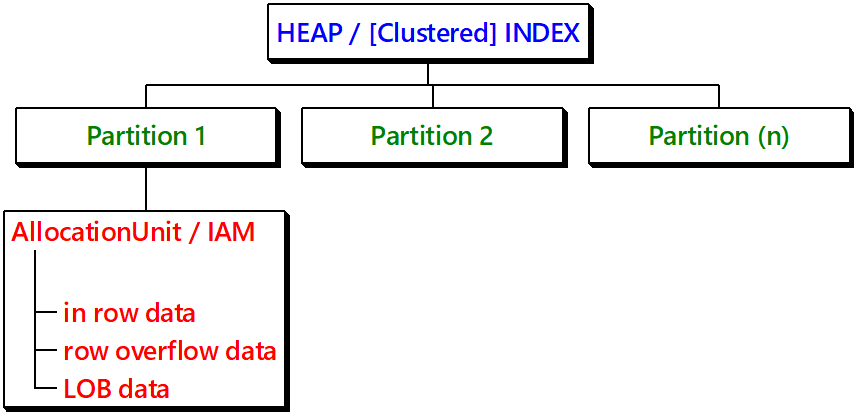
Рис.2: Концепция хранения куч / Кластеризованные индексы / Некластеризованные индексы
Каждая таблица и индекс используют IAM-структуры для управления страницами данных. IAM-страница содержит информацию о блоках (экстентах), которые используются таблицей или индексом для каждой единицы распределения.
Страницы данных кучи не хранят ссылок на следующую или предыдущую страницы данных. Для кучи нет в этом необходимости, поскольку куча не требует, чтобы данные были отсортированы в соответствии с определенным критерием.
Столбец [first_iam_page] в системном представлении [sys].[system_internals_allocation_units] указывает на первую IAM-страницу в цепочке IAM-страниц, которая управляет выделенными страницами данных кучи в конкретной секции. Не пугайтесь мистического шестнадцатеричного кода; он легко расшифровывается с помощью функции sys.fn_PhysLocFormatter!

Рис.3: Информация о распределении страниц и первой IAM-страницы
Приведенный выше запрос возвращает информацию о типе хранилища, числе страниц и размещении первой IAM-страницы, которая управляет страницами данных кучи. Microsoft SQL Server требуется только первая IAM-страница, поскольку она содержит ссылку на следующую IAM-страницу и т.д.
Чтобы узнать тайны IAM-страницы, вы можете использовать еоманду DBCC PAGE, но следует быть осторожным при использовании недокументированных функций в рабочей системе.
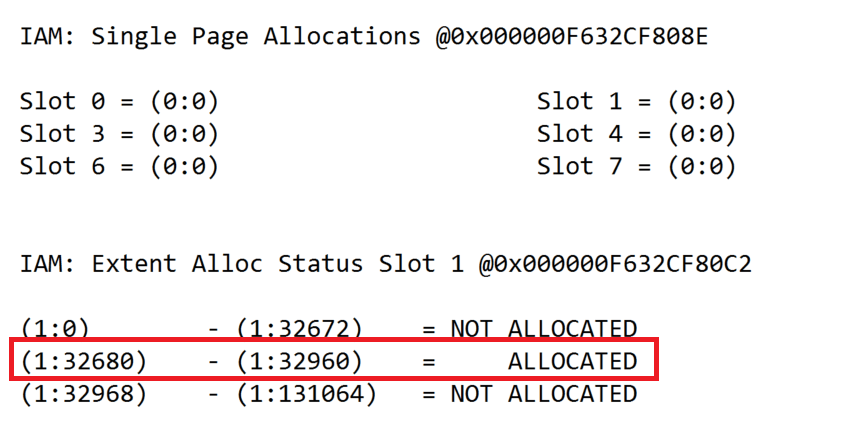
Рис.4: Заглянем в содержимое IAM-страницы
Выше показана информация, записанная на IAM-странице нашей кучи. Она говорит о том, что страницы 32,680 – 32,967 заняты таблицей [dbo].[Customers]. Поэтому теперь Microsoft SQL Server знает, какие данные содержатся на страницах при выполнении оператора SELECT на куче.
Уровень заполнения страницы данных можно указать только для страниц данных кучи. В отличие от кластеризованного индекса, строки данных не сортируются и не должны вводиться в отсортированном виде. Это дело Microsoft SQL Server решать, на какой странице сохранить запись данных.
Однако для доступа к месту записи страницы Microsoft SQL Server требуется знать, где имеется достаточно пространства на страницах данных для завершения транзакции. Такая информация может быть получена на основе записанного уровня заполнения страницы данных. Эта информация содержится на странице PFS.
Проблема в том, что эта степень заполнения не сохраняется "точно". Напротив, Microsoft SQL Server использует лишь "грубое" процентное отношение для степени заполнения.

Следующий более высокий уровень обновляется, как только состояние превышено. Например, страница данных ВСЕГДА имеет 50% заполнения, как только вводится первая запись данных.
Текущий уровень заполнения страниц данных кучи можно определить с помощью (недокументированной) системной функции [sys]. [dm_db_database_page_allocations].
Следующий пример показывает как изменяется уровень заполнения при превышении состояния (байты). Для этого создается куча, которая хранит записи по 2004 байта.
После создания таблицы, добавьте одну запись в таблицу. Хотя страница данных заполнена только на 25%, Microsoft SQL Server записывает статус заполнения страницы 50%.

Рис.5: page_free_space_percent
Когда вы вставляете вторую запись, уровень заполнения не изменится, поскольку 2*2011 = 4022 байтов не достигает 50%. Уровень заполнения будет обновлен только для третьей записи!
Замечание: Каждая запись данных имеет заголовок, в котором записана структура записи данных. Структура записывается в 7 байтах. Поэтому физическая длина тестовой записи данных составляет не 2004, а 2011 байтов. Более подробно об анатомии записи вы можете прочитать в статье Paul Randal.
Здесь описана специфика кучи, но вас пока еще интересует, имеются ли какие-либо преимущества их использования. Вот выжимка преимуществ и недостатков, о которых я напишу в следующих статьях:
Использование кучи может быть более эффективным, чем таблица с кластеризованным индексом. В целом, имеется несколько случаев использования куч, подобно загрузки временных таблиц или записи данных протокола в кучу, поскольку тут нет нужды уделять внимание сортировке при сохранении данных. Записи сохраняются на следующей доступной странице данных, на которой достаточно свободного места. Кроме того, процесс INSERT не требует перемещения вниз по индексной структуре B-Tree до страниц данных для сохранения записи!
Кучи могут обладать несколькими недостатками:
Некоторые из упомянутых "недостатков" могут быть устранены или обойдены, если вы знаете, как устроена куча внутри. Я надеюсь, что смогу убедить кого-нибудь, что кластеризованный индекс не всегда является лучшим выбором. Как оптимизировать обслуживание куч будет обсуждаться в следующих статьях.
Снова и снова я пытаюсь убедить разработчиков, что куча может даже иметь преимущества. Я обсуждал много "за" и "против" с этими людьми, и хотел бы теперь поломать копья "ЗА КУЧУ". Эта статья посвящена основам. Важные объекты системы, которые играют значимую роль в кучах, здесь представлены лишь поверхностно, и подробно обсуждаются в последующих статьях.
Основы куч
В Microsoft SQL Server кучи избегаются так же, как дьявол избегает святой воды. Причина такого отказа заключается в том, что в статьях многих известных блогеров указывается, что таблица должна использовать кластеризованный индекс. В настоящей серии статей упор делается на максимально широком спектре положительного и отрицательного применения кучи. В результате вы должны решить для себя, имеет ли и когда имеет преимущество куча по сравнению с кластеризованным индексом. Чтобы принять решение, вы должны понимать метод работы и внутренние структуры.
Что такое куча
Кучи - это таблицы без кластеризованного индекса. Без индекса никакая сортировка данных не гарантируется. Данные сохраняются на любом свободном месте без предопределенного порядка. Если таблица пустая, записи данных вносятся в таблицу в порядке, определяемом командами INSERT.
CREATE TABLE dbo.Customers
(
Id INT NOT NULL,
Name VARCHAR (200) NOT NULL,
Street VARCHAR (200) NOT NULL,
Code CHAR (3) NOT NULL,
ZIP VARCHAR (5) NOT NULL,
City VARCHAR (200) NOT NULL,
State VARCHAR (200) NOT NULL
)
GO
INSERT INTO dbo.Customers(Id, Name, Street, Code, Zip, City, State)
VALUES(1,'John Smith','Times Square','123','10001',
'New York','New York');Скрипт создает новую таблицу для хранения данных клиентов и вставляет одну строку. Поскольку нет ни индекса, ни использования первичного ключа с опцией CLUSTERED, данные записываются "несортированными" в эту таблицу.
Если таблица не имеет кластеризованного индекса, кучу можно найти в системном представлении [sys].[Indexes], которая всегда имеет [Index_Id] = 0.
-- куча всегда имеет index_id = 0
SELECT object_id,
name,
index_id,
type_desc
FROM sys.indexes
WHERE object_id = OBJECT_ID (N'dbo.Customers', N'U');
GO Рис.1: [index_id] = 0 и [index_id] = 1 зарезервировано для кучи и кластеризованного индекса соответственно
Структура кучи
Поскольку кучи являются примитивным хранением данных, никакие сложные структуры не требуются для управления кучами. Кучи имеют одну строку в sys.partitions с [index_id] = 0 для каждой секции, используемой кучей. Когда куча разбита на множество секций, каждая секция имеет структуру кучи, которая содержит данные этой конкретной секции.
В зависимости от типов данных в куче, каждая структура кучи будет иметь одну или более единиц распределения для хранения и управления данными конкретной секции. По минимуму каждая куча будет иметь одну единицу распределения IN_ROW_DATA на секцию.
Рис.2: Концепция хранения куч / Кластеризованные индексы / Некластеризованные индексы
Карта распределения индекса (IAM)
Каждая таблица и индекс используют IAM-структуры для управления страницами данных. IAM-страница содержит информацию о блоках (экстентах), которые используются таблицей или индексом для каждой единицы распределения.
Страницы данных кучи не хранят ссылок на следующую или предыдущую страницы данных. Для кучи нет в этом необходимости, поскольку куча не требует, чтобы данные были отсортированы в соответствии с определенным критерием.
SELECT SIAU.type_desc,
SIAU.total_pages,
SIAU.used_pages,
SIAU.data_pages,
SIAU.first_iam_page,
sys.fn_PhysLocFormatter(SIAU.first_iam_page) AS iam_page
FROM sys.system_internals_allocation_units AS SIAU
INNER JOIN sys.partitions AS P
ON
SIAU.container_id =
CASE WHEN SIAU.type IN (1, 3)
THEN P.hobt_id
ELSE P.partition_id
END
WHERE P.object_id = OBJECT_ID (N'dbo.Customers', N'U');
GOСтолбец [first_iam_page] в системном представлении [sys].[system_internals_allocation_units] указывает на первую IAM-страницу в цепочке IAM-страниц, которая управляет выделенными страницами данных кучи в конкретной секции. Не пугайтесь мистического шестнадцатеричного кода; он легко расшифровывается с помощью функции sys.fn_PhysLocFormatter!
Рис.3: Информация о распределении страниц и первой IAM-страницы
Приведенный выше запрос возвращает информацию о типе хранилища, числе страниц и размещении первой IAM-страницы, которая управляет страницами данных кучи. Microsoft SQL Server требуется только первая IAM-страница, поскольку она содержит ссылку на следующую IAM-страницу и т.д.
Чтобы узнать тайны IAM-страницы, вы можете использовать еоманду DBCC PAGE, но следует быть осторожным при использовании недокументированных функций в рабочей системе.
-- передача вывода DBCC PAGE клиенту
DBCC TRACEON (3604);
-- Показать содержимое страницы данных
DBCC PAGE (0, 1, 188, 3);Рис.4: Заглянем в содержимое IAM-страницы
Выше показана информация, записанная на IAM-странице нашей кучи. Она говорит о том, что страницы 32,680 – 32,967 заняты таблицей [dbo].[Customers]. Поэтому теперь Microsoft SQL Server знает, какие данные содержатся на страницах при выполнении оператора SELECT на куче.
Страничное свободное пространство (PFS)
Уровень заполнения страницы данных можно указать только для страниц данных кучи. В отличие от кластеризованного индекса, строки данных не сортируются и не должны вводиться в отсортированном виде. Это дело Microsoft SQL Server решать, на какой странице сохранить запись данных.
Однако для доступа к месту записи страницы Microsoft SQL Server требуется знать, где имеется достаточно пространства на страницах данных для завершения транзакции. Такая информация может быть получена на основе записанного уровня заполнения страницы данных. Эта информация содержится на странице PFS.
Проблема в том, что эта степень заполнения не сохраняется "точно". Напротив, Microsoft SQL Server использует лишь "грубое" процентное отношение для степени заполнения.
Следующий более высокий уровень обновляется, как только состояние превышено. Например, страница данных ВСЕГДА имеет 50% заполнения, как только вводится первая запись данных.
Текущий уровень заполнения страниц данных кучи можно определить с помощью (недокументированной) системной функции [sys]. [dm_db_database_page_allocations].
Следующий пример показывает как изменяется уровень заполнения при превышении состояния (байты). Для этого создается куча, которая хранит записи по 2004 байта.
DROP TABLE IF EXISTS dbo.demo_table;
GO
CREATE TABLE dbo.demo_table
(
C1 INT NOT NULL IDENTITY (1, 1),
C2 CHAR(2000) NOT NULL DEFAULT ('Test')
);
GO
INSERT INTO dbo.demo_table DEFAULT VALUES;
GOПосле создания таблицы, добавьте одну запись в таблицу. Хотя страница данных заполнена только на 25%, Microsoft SQL Server записывает статус заполнения страницы 50%.
-- Какие страницы выделены?
SELECT allocated_page_page_id,
previous_page_page_id,
next_page_page_id,
page_type_desc,
page_free_space_percent
FROM sys.dm_db_database_page_allocations
(
DB_ID(),
OBJECT_ID(N'dbo.demo_table', N'U'),
0,
NULL,
N'DETAILED'
);
GOРис.5: page_free_space_percent
Когда вы вставляете вторую запись, уровень заполнения не изменится, поскольку 2*2011 = 4022 байтов не достигает 50%. Уровень заполнения будет обновлен только для третьей записи!
-- Вставка второй записи в демо-таблицу
INSERT INTO dbo.demo_table DEFAULT VALUES;
GOЗаключение
Здесь описана специфика кучи, но вас пока еще интересует, имеются ли какие-либо преимущества их использования. Вот выжимка преимуществ и недостатков, о которых я напишу в следующих статьях:
Преимущества куч
Использование кучи может быть более эффективным, чем таблица с кластеризованным индексом. В целом, имеется несколько случаев использования куч, подобно загрузки временных таблиц или записи данных протокола в кучу, поскольку тут нет нужды уделять внимание сортировке при сохранении данных. Записи сохраняются на следующей доступной странице данных, на которой достаточно свободного места. Кроме того, процесс INSERT не требует перемещения вниз по индексной структуре B-Tree до страниц данных для сохранения записи!
Недостатки куч
Кучи могут обладать несколькими недостатками:
- Куча не может масштабироваться, если база данных имеет неудачный проект из-за конкуренции PFS (будет подробно рассмотрено в следующих статьях).
- Поиск данных не может быть эффективным в куче.
- Время поиска данных в куче растет линейно с ростом объема данных.
- Куча не подходит для частого обновления данных из-за риска пересылки записей (будет подробно рассмотрено в следующих статьях).
- Куча - это ужас для каждого администратора баз данных, когда ему приходится их обслуживать, поскольку куча требует обновления некластеризованных индексов при перестройке кучи.
Некоторые из упомянутых "недостатков" могут быть устранены или обойдены, если вы знаете, как устроена куча внутри. Я надеюсь, что смогу убедить кого-нибудь, что кластеризованный индекс не всегда является лучшим выбором. Как оптимизировать обслуживание куч будет обсуждаться в следующих статьях.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой