
Понимание CRUD-операций на таблицах с индексами B-Tree, разбиение страниц и фрагментация
Пересказ статьи Mohsin Khan. Understanding CRUD Operations on Tables with B-tree Indexes, Page-splits, and Fragmentation
Введение
Каждая транзакция DML читает данные, прежде чем сделать какие-либо изменения. Не только при операторе SELECT, но и когда выполняется любой оператор DML, вставка, обновление или удаление, SQL Server сначала считывает набор страниц в буферный пул, размещая желаемые строки и изменяя их, выполняя синхронную запись в файл журнала транзакций.
В то время как индексы на таблице улучшают производительность чтения, они добавляют накладные расходы при модификации данных. Каждая вставка, обновление или удаление, которые воздействуют на столбцы в базовой таблице - куче или кластеризованном индексе - также оказывают воздействие на любые некластеризованные индексы, которые включают этот столбец.
Замечание: Это третья статья в серии. Однако эти статьи самодостаточны, поэтому их можно читать в любом порядке. Вот они:
Давайте сначала разберемся с базовой структурой B-tree.
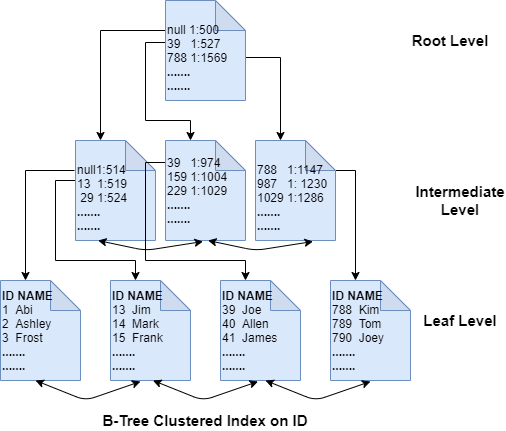
В структуре B-tree SQL Server сортирует страницы данных в порядке ключевых столбцов индекса. Страницы связываются двусвязным списком, что позволяет сканировать страницы последовательно как в прямом, так и в обратном направлениях. Заголовок каждой страницы индекса содержит адреса предыдущей и следующей страницы. Индекс b-tree имеет уровни трех типов: корневой (root), промежуточный (intermediate) и листовой (leaf).
Корневая страница находится на верхнем уровне и содержит указатели строк на страницы уровня ниже. Следующий уровень ниже корня является промежуточным уровнем, состоящим из индексных страниц с указателями строк на каждую страницу следующего уровня ниже. Если таблица большая, промежуточных уровней может быть несколько. Последний промежуточный уровень указывает на листовой уровень, содержащий листовые страницы, которыми могут быть страницы данных, если b-tree представляет собой кластеризованный индекс, или страницы индекса, если это некластеризованный индекс. Если листовые страницы являются страницами индекса, они содержат указатели на базовую таблицу, которая может быть кучей или кластеризованным индексом.
При вставке новой строки SQL Server читает страницу данных, на которую она должна быть вставлена, в буферный пул, если страницы там еще нет. В этом случае SQL Server размещает новый экстент. Затем он вставляет строку на страницу, синхронно записывает соответствующую запись в журнал транзакций и асинхронно сбрасывает грязную страницу в файл данных на диске либо посредством контрольной точки, либо ленивой записи.
SQL Server знает, на какую страницу должна быть записана строка в таблицу с кластеризованным индексом. Например, пусть имеется страница с значениями в столбце ключа кластеризации от 1 до 10. При вставке новой строки с значением ключевого столбца 11 SQL Server пытается разместить её на той же странице, если на ней достаточно места. Если нет, SQL Server выделяет новую страницу и связывает её с предыдущей страницей для поддержания порядка. Предположим, что требуется вставить строку на страницу, на которой нет места, скажем, строку с значением ключевого столбца 5 в нашем примере. В этом случае SQL Server разделяет страницу, т.е. он выделает новую страницу и перемещает на неё около 50% строк из предыдущей страницы и выполняет вставку либо на старую, либо на новую страницу, в зависимости от значения ключа индекса.
Хотя процесс разделения страницы поддерживает логический порядок следования строк на основе ключа кластеризации, он является затратным. SQL Server должен убрать ссылку со старой страницы, создать новую ссылку на новую выделенную страницу, и переместить туда строки. Кроме того, добавляется запись для новой страницы на родительскую страницу уровнем выше. Операция полностью журнализируется, что увеличивает накладные расходы на ведение журнала транзакций, которые могут иметь тяжелые последствия, если база данных является частью функционала, который опирается на журнал транзакций, например, группы доступности (Availability Groups) .
Кроме того, разделение страниц вызывает логическую (или внешнюю) фрагментацию. Если новая страница не является физически смежной со страницей, которая разделяется, что почти всегда имеет место, это влияет на производительность. Особенно в процессе опережающего чтения, когда в целях оптимизации производительности SQL Server в паузах считывает в память блоки лишних страниц до того, как они могут потребоваться, посылая большие запросы на ввод-вывод. Не имея физически смежных соседних страниц из-за разбиения страниц, SQL Server при чтении должен выполнять перемещения туда и обратно. Логический порядок строк не следует физическому порядку, что вызывает логическую фрагментацию, которая ухудшает производительность. Разделение страницы может произойти для корневой страницы индекса, промежуточных индексных страниц, листовых страниц данных кластеризованного индекса или листовых индексных страниц некластеризованного индекса.
Страница может претерпеть несколько разделений, если новая строка не может поместиться после единственного разделения. Кроме того, разделение страницы выполняется как внутренняя транзакция, означая, что если вы выполняли транзакцию вставки, и она привела к разделению страницы и её отмене, хотя SQL Server откатывает вставку, он не отменяет разделение. Также SQL Server эксклюзивно блокирует разделяемую страницу в процессе ее разделения на две, что означает недоступность строк страницы в других сеансах.
Фрагментация в кластеризованных индексах часто происходит, когда ключ кластеризации не увеличивается, в том смысле, что если значения ключевого столбца генерируются случайным образом, то нет гарантии, что новые значения попадут до или после существующих значений. Предположим, например, что кластеризованный индекс использует тип данных uniqueidentifier с генерацией случайных значений при помощи функции NEWID(). Хотя значения будут уникальны, они не попадают до или после существующих значений, приводя к разделению страниц и фрагментации. То же самое справедливо для некластеризованных индексов.
Разделение корневой страницы не является обычным делом, поскольку индексы, как правило, имеют несколько уровней, и чтобы произошло разделение корневой страницы, должна быть огромная массовая вставка данных. Если корневая страница индекса должна разделиться для размещения новой строки индекса, SQL Server выделяет две новых индексных страницы. Он перемещает строки с корневой страницы на двух новых страницах с последующей вставкой новой строки на одну из двух новых страниц в соответствии с ее логическим порядком. SQL Server не удаляет корневой страницы. Исходные строки на корневой странице теперь находятся на двух новых страницах индекса. Такое разделение корневой страницы вводит новый промежуточный уровень в индекс, т.е. две новых индексных страницы.
Предположим, что страница промежуточного уровня индекса должна быть разделена для размещения новой индексной строки. В этом случае SQL Server выделяет новую индексную страницу, размещает половину до средней из индексных строк на разделяемой странице и перемещает последние 50% строк на новую страницу с последующей вставкой новой строки либо на странице с первыми 50% строк, либо на новой странице с последними 50% строк, в зависимости от её логического порядка, и включает новую страницу в цепочку указателей. Соответствующая родительская страница уровнем выше получает новую индексную строку, вставленную с физическим адресом и минимальным значением ключевого столбца на вновь выделенной странице.
Безусловно, наиболее общим случаем является разделение страницы на листовом уровне либо кластеризованного, либо некластеризованного индекса. Как и в случае разделения на промежуточном уровне, SQL Server создает новую пустую страницу и перемещает 50% строк со старой страницы на новую страницу, и вставляет новую строку на одну из двух страниц. Хотя это не влияет на некластеризованные индексы в таблице, поскольку значения ключа кластеризованного индекса не меняются в разделяемой странице, это влияет на производительность поиска ключа, т.к. SQL должен выполнить разбросанные чтения, если листовые страницы кластеризованного индекса физически не расположены рядом.
Будем использовать ту же базу, которую мы создали в статье о кучах, чтобы посмотреть, каким образом вставки могут вызвать фрагментацию. Следующий код создает новую таблицу с именем Insert_frag со столбцом типа uniqueidentifier, использующим функцию NEWID() в качестве ключа кластеризации, и наполняет её набором строк. Затем мы вставим еще записи, чтобы вызвать случайные вставки, которые приведут к разделению страниц и фрагментации.
Верхняя выдача выполнена до случайных вставок. Обратите внимание, что фрагментация была почти нулевой при высокой плотности страницы, выводимой в столбце avg_page_space_used_in_percent. После случайной вставки, результаты которой показаны ниже, видна множественная фрагментация и низкая плотность (заполнение страницы) из-за разбиения страниц. Кроме того, отметьте увеличение числа страниц после второй вставки.
SQL Server эффективно выполняет удаления. Как и в любых операциях DML, SQL Server считывает страницы данных в память, где и выполняет удаление строк данных. SQL Server не убирает строки из слотов страницы физически. Напротив, он просто помечает флажком удаленные строки как записи-призраки, меняя биты состояния в заголовке строки на обрабатываемых страницах. Это делает легким откат, т.к. это просто сводится к обращению битов состояния на этих страницах, не производя физических изменений.
SQL Server фактически удаляет записи-призраки в фоновом режиме в фоновом потоке, который называется чисткой призраков (ghost-cleanup). Этот поток удаляет записи-призраки пока активные незафиксированные транзакции не требуют их. Поток также освобождает целые страницы, если на них удалены все записи; однако таблицы кучи должны быть перестроены, чтобы освободились пустые страницы. При удалении строки из таблицы SQL Server удаляет соответствующую строку из любых некластеризованных индексов, поскольку они содержат указатель на удаленную строку.
Удаления приводят к появлению пропусков в прежде физически соседних страницах. Например, пусть страница 1 имеет строки с значениями от 1 до 10, страница 2 - от 11 до 20, а страница 3 - от 21 до 30. Если мы удаляем все строки со страницы 2, эта страница становится пустой и создает зазор между страницами 1 и 3. Страница 2 может быть использована либо последующими вставками, обновлениями или освобождена в процессе очистки призраков. Поэтому, хотя удаления не вызывают непосредственно разделения страниц, они создают зазоры, которые могут использовать другие индексы в будущем, что потенциально может привести к фрагментации. Но это не настолько серьезно, как в случаях, вызываемых вставками и обновлениями.
Следующий код создает новую таблицу с именем Delete_frag со столбцом identity кластеризованного индекса, и наполняет её набором строк. Затем мы удаляем несколько случайно выбранных записей, чтобы создать зазоры, приводящие к небольшой фрагментации.

Если страница, содержащая строку для обновления, еще не находится в буферном пуле, SQL Server физически считывает страницу с диска, вызывая физическую операцию ввода-вывода. Затем он обновляет строку на странице и генерирует новую запись в журнал транзакций, которая содержит достаточно информации для отмены обновления, если потребуется восстановление. Затем синхронно выполняется запись в файл журнал транзакций на диске. Измененная или "грязная" страница в какой-то момент сбрасывается в файл данных на диске.
Пока изменения не затрагивают столбцов ключа кластеризации, это не оказывает влияния на некластеризованные индексы. Однако, если в результате команды Update изменяется ключ кластеризации, соответствующая строка некластеризованного индекса обновляется, чтобы отразить новое значение ключа. Если обновление вызывает перемещение строки в другое физическое местоположение, а значение ключа кластеризации остается неизменным, не происходит никаких изменений в некластеризованном индексе.
Одновление приводит к резделению страницы и фрагментации индекса, когда столбец обновлятся большим значением, которое не может ни заменить старое значение в том же самом месте, ни переместить в другое место на той же странице, оставляя разделение страницы как единственную возможность. Фрагментация также может иметь место, когда изменяется значение ключа индекса. Новое местоположение значения приходится на другую страницу, на которой недостаточно места для размещения новой строки, что приводит к разделению страницы.
Следующий код создает новую таблицу с именем Update_frag со столбцом identity как кластеризованным индексом, и наполняет её набором строк. Затем несколько записей обновляется бОльшими значениями, вызывая фрагментацию.
Верхняя выдача - это до обновления. Заметим, что фрагментация была нулевой с высокой плотностью страницы. Нижний результат, полученный после обновления, показывает фрагментацию и низкий уровень плотности страниц, поскольку произошло разделение.

Разделение страниц приводит к обновлению множества страниц, которое полностью журнализируется в журнале транзакций. Следующий очевидный вопрос такой: "Как избежать разделения страниц?" Один из способов - это использовать подходящий ключ кластеризации, который не допускает вставки данных на случайные страницы, а добавляет их в конец таблицы, тем самым избегая вставки на предыдущие страницы, что может вызвать их разделение.
Рекомендуемые характеристики ключа кластеризации - это уникальный, статичный, узкий и монотонно возрастающий. GUID вызывает разделение страниц в силу своей случайной природы, поэтому это не лучший выбор для ключа кластеризации. Вместо этого вы можете использовать монотонно возрастающий столбец IDENTITY или DATETIME. Однако при монотонно возрастающем ключе последняя страница может стать горячей точкой, выражающейся в конкуренции за вставку на последнюю страницу. Это означает, что могут иметь место множество одновременных вставок на последнюю страницу в памяти, вызывая высокие значения ожиданий PAGELATCH_xx для потоков. В SQL Server 2019 введена опция индекса, называемая OPTIMIZE_FOR_SEQUENTIAL_KEY, для улучшения пропускной способности для высококонкурентных вставок в индекс, тем самым понижая конкуренцию вставки на последнюю страницу.
Во-вторых, используйте подходящее значение коэффициента заполнения (Fill Factor) при создании или перестройке индекса. Fill Factor определяет, скольк свободного пространства резервируется на потенциальные будущие вставки на листовые страницы индекса. Правильное значение для Fill Factor диктуется типом рабочей нагрузки, которая выполняется на экземпляре. Предположим, что на страницах имеется много свободного пространства. В этом случае страницы имеют низкую плотность (так называемая внутренняя фрагментация), и память расходуется неэкономно, т.к. SQL Server считывает страницы в память целиком, независимо от того, полностью они заполнены или частично. Так же, если вы выберите заполнение страниц до их емкости, то высока вероятность разделения страниц и фрагментации. Итак, нужно тщательно оценивать рабочую нагрузку.
Значение Fill Factor 0 означает то же самое, что и 100, это заполнение страниц до их емкости. 0 является значением по умолчанию коэффициента заполнения при создании индекса, и может быть изменено для соответствия рабочей нагрузке. Единственный повод начать со 100, это мониторить уровни фрагментации, и постепенно настраивать значение, уменьшая его до оптимального значения.
Минимизирует фрагментацию также исключение типов данных переменной длины. Данные таких типов как VARCHAR и NVARCHAR могут изменяться со временем и потенциально вызвать разделение страниц. Версионность строк также может вызвать фрагментацию. При включении версионности строк SQL Server сохраняет старую версию записей в хранилище версий в tempdb и добавляет 14-байтовый тег версии к строкам в базе данных, чтобы связать их со строками в хранилище версий. Это на 14 байтов увеличивает каждую строку, что может спровоцировать перемещение строк и, соответственно, разделение страниц.
Сжатие базы данных тоже вызывает фрагментацию, которую можно исправить перестройкой индекса. Сжатие перемещает страницы с конца файла данных вперед и освобождает свободное пространство в конце. SQL Server перемещает страницы вперед, не следуя принципу физической близости, создавая фрагментацию. Следовательно, нужно по возможности избегать сжатия.
Мы должны следовать надлежащей стратегии реорганизации и перестройки индексов. Microsoft рекомендует перестраивать индекс, если фрагментация превышает 30% и выполнять реорганизацию при 5-30 процентов. В то время как перестройка индекса выполняется в рамках транзакции, которая при остановке полностью откатывается, реорганизация индекса может прерываться без потери работы, выполненной до точки останова. В SQL Server 2017 была введена функция возобновляемой онлайн перестройки индекса, которая позволяет прерывать перестройку индекса либо вручную, либо по причине сбоя после его устранения.
Индексы должны обслуживаться регулярно для удаления внутренней и внешней фрагментации. Следует внимательно оценивать Fill Factor, т.к. для него нет универсального значения. Выбирайте уникальный, статичный, узкий и монотонно возрастающий столбец для кластеризованного индекса, чтобы минимизировать разделение страниц и фрагментацию. Некластеризованные индексы должны быть узкими, чтобы увеличить плотность, ведущую к более быстрому обслуживанию индекса, эффективному использованию буферного пула, уменьшению операций ввода-вывода, более быстрым операциям создания резервных копий и DBCC CHECKDB. Вставки, обновления и удаления все могут привести к фрагментации. Однако удаления технически вызывают зазоры между страницами, которые могут, в конце концов, приводить к фрагментации, но это не так существенно, как фрагментация, вызываемая вставками и обновлениями.
Замечание: Это третья статья в серии. Однако эти статьи самодостаточны, поэтому их можно читать в любом порядке. Вот они:
- Основы внутреннего устройства страниц данных
- Понимание CRUD операций, адресованных к куче, и указатели пересылки
- Эта статья
Давайте сначала разберемся с базовой структурой B-tree.
В структуре B-tree SQL Server сортирует страницы данных в порядке ключевых столбцов индекса. Страницы связываются двусвязным списком, что позволяет сканировать страницы последовательно как в прямом, так и в обратном направлениях. Заголовок каждой страницы индекса содержит адреса предыдущей и следующей страницы. Индекс b-tree имеет уровни трех типов: корневой (root), промежуточный (intermediate) и листовой (leaf).
Корневая страница находится на верхнем уровне и содержит указатели строк на страницы уровня ниже. Следующий уровень ниже корня является промежуточным уровнем, состоящим из индексных страниц с указателями строк на каждую страницу следующего уровня ниже. Если таблица большая, промежуточных уровней может быть несколько. Последний промежуточный уровень указывает на листовой уровень, содержащий листовые страницы, которыми могут быть страницы данных, если b-tree представляет собой кластеризованный индекс, или страницы индекса, если это некластеризованный индекс. Если листовые страницы являются страницами индекса, они содержат указатели на базовую таблицу, которая может быть кучей или кластеризованным индексом.
Вставка
При вставке новой строки SQL Server читает страницу данных, на которую она должна быть вставлена, в буферный пул, если страницы там еще нет. В этом случае SQL Server размещает новый экстент. Затем он вставляет строку на страницу, синхронно записывает соответствующую запись в журнал транзакций и асинхронно сбрасывает грязную страницу в файл данных на диске либо посредством контрольной точки, либо ленивой записи.
SQL Server знает, на какую страницу должна быть записана строка в таблицу с кластеризованным индексом. Например, пусть имеется страница с значениями в столбце ключа кластеризации от 1 до 10. При вставке новой строки с значением ключевого столбца 11 SQL Server пытается разместить её на той же странице, если на ней достаточно места. Если нет, SQL Server выделяет новую страницу и связывает её с предыдущей страницей для поддержания порядка. Предположим, что требуется вставить строку на страницу, на которой нет места, скажем, строку с значением ключевого столбца 5 в нашем примере. В этом случае SQL Server разделяет страницу, т.е. он выделает новую страницу и перемещает на неё около 50% строк из предыдущей страницы и выполняет вставку либо на старую, либо на новую страницу, в зависимости от значения ключа индекса.
Хотя процесс разделения страницы поддерживает логический порядок следования строк на основе ключа кластеризации, он является затратным. SQL Server должен убрать ссылку со старой страницы, создать новую ссылку на новую выделенную страницу, и переместить туда строки. Кроме того, добавляется запись для новой страницы на родительскую страницу уровнем выше. Операция полностью журнализируется, что увеличивает накладные расходы на ведение журнала транзакций, которые могут иметь тяжелые последствия, если база данных является частью функционала, который опирается на журнал транзакций, например, группы доступности (Availability Groups) .
Кроме того, разделение страниц вызывает логическую (или внешнюю) фрагментацию. Если новая страница не является физически смежной со страницей, которая разделяется, что почти всегда имеет место, это влияет на производительность. Особенно в процессе опережающего чтения, когда в целях оптимизации производительности SQL Server в паузах считывает в память блоки лишних страниц до того, как они могут потребоваться, посылая большие запросы на ввод-вывод. Не имея физически смежных соседних страниц из-за разбиения страниц, SQL Server при чтении должен выполнять перемещения туда и обратно. Логический порядок строк не следует физическому порядку, что вызывает логическую фрагментацию, которая ухудшает производительность. Разделение страницы может произойти для корневой страницы индекса, промежуточных индексных страниц, листовых страниц данных кластеризованного индекса или листовых индексных страниц некластеризованного индекса.
Страница может претерпеть несколько разделений, если новая строка не может поместиться после единственного разделения. Кроме того, разделение страницы выполняется как внутренняя транзакция, означая, что если вы выполняли транзакцию вставки, и она привела к разделению страницы и её отмене, хотя SQL Server откатывает вставку, он не отменяет разделение. Также SQL Server эксклюзивно блокирует разделяемую страницу в процессе ее разделения на две, что означает недоступность строк страницы в других сеансах.
Фрагментация в кластеризованных индексах часто происходит, когда ключ кластеризации не увеличивается, в том смысле, что если значения ключевого столбца генерируются случайным образом, то нет гарантии, что новые значения попадут до или после существующих значений. Предположим, например, что кластеризованный индекс использует тип данных uniqueidentifier с генерацией случайных значений при помощи функции NEWID(). Хотя значения будут уникальны, они не попадают до или после существующих значений, приводя к разделению страниц и фрагментации. То же самое справедливо для некластеризованных индексов.
Разделение корневой страницы индекса
Разделение корневой страницы не является обычным делом, поскольку индексы, как правило, имеют несколько уровней, и чтобы произошло разделение корневой страницы, должна быть огромная массовая вставка данных. Если корневая страница индекса должна разделиться для размещения новой строки индекса, SQL Server выделяет две новых индексных страницы. Он перемещает строки с корневой страницы на двух новых страницах с последующей вставкой новой строки на одну из двух новых страниц в соответствии с ее логическим порядком. SQL Server не удаляет корневой страницы. Исходные строки на корневой странице теперь находятся на двух новых страницах индекса. Такое разделение корневой страницы вводит новый промежуточный уровень в индекс, т.е. две новых индексных страницы.
Разделение страницы промежуточного уровня индекса
Предположим, что страница промежуточного уровня индекса должна быть разделена для размещения новой индексной строки. В этом случае SQL Server выделяет новую индексную страницу, размещает половину до средней из индексных строк на разделяемой странице и перемещает последние 50% строк на новую страницу с последующей вставкой новой строки либо на странице с первыми 50% строк, либо на новой странице с последними 50% строк, в зависимости от её логического порядка, и включает новую страницу в цепочку указателей. Соответствующая родительская страница уровнем выше получает новую индексную строку, вставленную с физическим адресом и минимальным значением ключевого столбца на вновь выделенной странице.
Разделение листовой страницы
Безусловно, наиболее общим случаем является разделение страницы на листовом уровне либо кластеризованного, либо некластеризованного индекса. Как и в случае разделения на промежуточном уровне, SQL Server создает новую пустую страницу и перемещает 50% строк со старой страницы на новую страницу, и вставляет новую строку на одну из двух страниц. Хотя это не влияет на некластеризованные индексы в таблице, поскольку значения ключа кластеризованного индекса не меняются в разделяемой странице, это влияет на производительность поиска ключа, т.к. SQL должен выполнить разбросанные чтения, если листовые страницы кластеризованного индекса физически не расположены рядом.
Демонстрация вставки
Будем использовать ту же базу, которую мы создали в статье о кучах, чтобы посмотреть, каким образом вставки могут вызвать фрагментацию. Следующий код создает новую таблицу с именем Insert_frag со столбцом типа uniqueidentifier, использующим функцию NEWID() в качестве ключа кластеризации, и наполняет её набором строк. Затем мы вставим еще записи, чтобы вызвать случайные вставки, которые приведут к разделению страниц и фрагментации.
--Фрагментация из-за вставки
USE DML_DB
GO
IF NOT EXISTS (
SELECT *
FROM sysobjects
WHERE name = 'Insert_frag'
AND xtype = 'U'
)
BEGIN
CREATE TABLE dbo.Insert_frag (
ID UNIQUEIDENTIFIER CONSTRAINT DF_GUID DEFAULT NEWID()
,Name VARCHAR(7800)
);
END
--Вставка набора строк
INSERT INTO Insert_frag (Name)
SELECT TEXT
FROM sys.messages
CREATE CLUSTERED INDEX CIX_Insert_frag ON dbo.Insert_frag (ID);
--Проверка фрагментации
USE DML_DB
GO
SELECT index_type_desc
,page_count
,CAST(avg_fragmentation_in_percent AS DECIMAL(6, 2)) AS avg_frag_in_percent
,fragment_count AS frag_count
,avg_fragment_size_in_pages AS avg_frag_size_in_pages
,CAST(avg_page_space_used_in_percent AS DECIMAL(6, 2)) AS avg_page_space_used_in_percent
,forwarded_record_count
FROM sys.dm_db_index_physical_stats(DB_ID('DML_DB'), OBJECT_ID('dbo.Insert_frag'), NULL, NULL, 'DETAILED')
--Случайные вставки, приводящие к фрагментации
INSERT INTO Insert_frag (Name)
SELECT name
FROM sys.system_columns
--Проверка фрагментации
SELECT index_type_desc
,page_count
,CAST(avg_fragmentation_in_percent AS DECIMAL(6, 2)) AS avg_frag_in_percent
,fragment_count AS frag_count
,avg_fragment_size_in_pages AS avg_frag_size_in_pages
,CAST(avg_page_space_used_in_percent AS DECIMAL(6, 2)) AS avg_page_space_used_in_percent
,forwarded_record_count
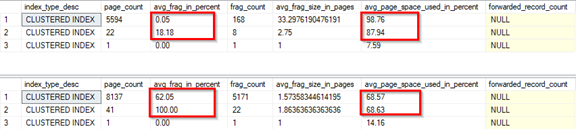
FROM sys.dm_db_index_physical_stats(DB_ID('DML_DB'), OBJECT_ID('dbo.Insert_frag'), NULL, NULL, 'DETAILED')Верхняя выдача выполнена до случайных вставок. Обратите внимание, что фрагментация была почти нулевой при высокой плотности страницы, выводимой в столбце avg_page_space_used_in_percent. После случайной вставки, результаты которой показаны ниже, видна множественная фрагментация и низкая плотность (заполнение страницы) из-за разбиения страниц. Кроме того, отметьте увеличение числа страниц после второй вставки.
Операции удаления
SQL Server эффективно выполняет удаления. Как и в любых операциях DML, SQL Server считывает страницы данных в память, где и выполняет удаление строк данных. SQL Server не убирает строки из слотов страницы физически. Напротив, он просто помечает флажком удаленные строки как записи-призраки, меняя биты состояния в заголовке строки на обрабатываемых страницах. Это делает легким откат, т.к. это просто сводится к обращению битов состояния на этих страницах, не производя физических изменений.
SQL Server фактически удаляет записи-призраки в фоновом режиме в фоновом потоке, который называется чисткой призраков (ghost-cleanup). Этот поток удаляет записи-призраки пока активные незафиксированные транзакции не требуют их. Поток также освобождает целые страницы, если на них удалены все записи; однако таблицы кучи должны быть перестроены, чтобы освободились пустые страницы. При удалении строки из таблицы SQL Server удаляет соответствующую строку из любых некластеризованных индексов, поскольку они содержат указатель на удаленную строку.
Удаления приводят к появлению пропусков в прежде физически соседних страницах. Например, пусть страница 1 имеет строки с значениями от 1 до 10, страница 2 - от 11 до 20, а страница 3 - от 21 до 30. Если мы удаляем все строки со страницы 2, эта страница становится пустой и создает зазор между страницами 1 и 3. Страница 2 может быть использована либо последующими вставками, обновлениями или освобождена в процессе очистки призраков. Поэтому, хотя удаления не вызывают непосредственно разделения страниц, они создают зазоры, которые могут использовать другие индексы в будущем, что потенциально может привести к фрагментации. Но это не настолько серьезно, как в случаях, вызываемых вставками и обновлениями.
Демонстрация удаления
Следующий код создает новую таблицу с именем Delete_frag со столбцом identity кластеризованного индекса, и наполняет её набором строк. Затем мы удаляем несколько случайно выбранных записей, чтобы создать зазоры, приводящие к небольшой фрагментации.
--Фрагментация из-за удаления
USE DML_DB
GO
IF NOT EXISTS (
SELECT *
FROM sysobjects
WHERE name = 'Delete_frag'
AND xtype = 'U'
)
BEGIN
CREATE TABLE dbo.Delete_frag (
ID INT IDENTITY(1, 1)
,Name VARCHAR(3000)
);
END
--вставка набора строк
INSERT INTO dbo.Delete_frag (Name)
SELECT name + replicate('a', 2500)
FROM sys.all_views
CREATE CLUSTERED INDEX CIX_Delete_frag ON dbo.Delete_frag (ID);
SELECT index_type_desc
,page_count
,CAST(avg_fragmentation_in_percent AS DECIMAL(6, 2)) AS avg_frag_in_percent
,fragment_count AS frag_count
,avg_fragment_size_in_pages AS avg_frag_size_in_pages
,CAST(avg_page_space_used_in_percent AS DECIMAL(6, 2)) AS avg_page_space_used_in_percent
,forwarded_record_count
FROM sys.dm_db_index_physical_stats(DB_ID('DML_DB'), OBJECT_ID('dbo.Delete_frag'), NULL, NULL, 'DETAILED')
USE DML_DB
GO
--удаление нескольких случайных строк для создания зазоров
--удаления приводят к образованию зазоров между страницами, поэтому фрагментация обычно минимальна
DELETE
FROM dbo.Delete_frag
WHERE ID BETWEEN 25
AND 75
DELETE
FROM dbo.Delete_frag
WHERE ID BETWEEN 85
AND 135
DELETE
FROM dbo.Delete_frag
WHERE ID BETWEEN 135
AND 235
waitfor delay '00:00:05'
SELECT index_type_desc
,page_count
,CAST(avg_fragmentation_in_percent AS DECIMAL(6, 2)) AS avg_frag_in_percent
,fragment_count AS frag_count
,avg_fragment_size_in_pages AS avg_frag_size_in_pages
,CAST(avg_page_space_used_in_percent AS DECIMAL(6, 2)) AS avg_page_space_used_in_percent
,forwarded_record_count
FROM sys.dm_db_index_physical_stats(DB_ID('DML_DB'), OBJECT_ID('dbo.Delete_frag'), NULL, NULL, 'DETAILED')Операции обновления
Если страница, содержащая строку для обновления, еще не находится в буферном пуле, SQL Server физически считывает страницу с диска, вызывая физическую операцию ввода-вывода. Затем он обновляет строку на странице и генерирует новую запись в журнал транзакций, которая содержит достаточно информации для отмены обновления, если потребуется восстановление. Затем синхронно выполняется запись в файл журнал транзакций на диске. Измененная или "грязная" страница в какой-то момент сбрасывается в файл данных на диске.
Пока изменения не затрагивают столбцов ключа кластеризации, это не оказывает влияния на некластеризованные индексы. Однако, если в результате команды Update изменяется ключ кластеризации, соответствующая строка некластеризованного индекса обновляется, чтобы отразить новое значение ключа. Если обновление вызывает перемещение строки в другое физическое местоположение, а значение ключа кластеризации остается неизменным, не происходит никаких изменений в некластеризованном индексе.
Одновление приводит к резделению страницы и фрагментации индекса, когда столбец обновлятся большим значением, которое не может ни заменить старое значение в том же самом месте, ни переместить в другое место на той же странице, оставляя разделение страницы как единственную возможность. Фрагментация также может иметь место, когда изменяется значение ключа индекса. Новое местоположение значения приходится на другую страницу, на которой недостаточно места для размещения новой строки, что приводит к разделению страницы.
Демонстрация обновления
Следующий код создает новую таблицу с именем Update_frag со столбцом identity как кластеризованным индексом, и наполняет её набором строк. Затем несколько записей обновляется бОльшими значениями, вызывая фрагментацию.
--Фрагментация из-за обновления
USE DML_DB
GO
IF NOT EXISTS (
SELECT *
FROM sysobjects
WHERE name = 'Update_frag'
AND xtype = 'U'
)
BEGIN
CREATE TABLE dbo.Update_frag (
ID INT IDENTITY(1, 1)
,Name VARCHAR(3000)
);
END
--вставка набора строк
INSERT INTO dbo.Update_frag (Name)
SELECT name + replicate('a', 2500)
FROM sys.all_views
CREATE CLUSTERED INDEX CIX_Update_frag ON dbo.Update_frag (ID);
USE DML_DB
GO
SELECT index_type_desc
,page_count
,CAST(avg_fragmentation_in_percent AS DECIMAL(6, 2)) AS avg_frag_in_percent
,fragment_count AS frag_count
,avg_fragment_size_in_pages AS avg_frag_size_in_pages
,CAST(avg_page_space_used_in_percent AS DECIMAL(6, 2)) AS avg_page_space_used_in_percent
,forwarded_record_count
FROM sys.dm_db_index_physical_stats(DB_ID('DML_DB'), OBJECT_ID('dbo.Update_frag'), NULL, NULL, 'DETAILED')
USE DML_DB
GO
-- обновление нескольких строк большими значениями, чтобы вызвать разделение страницы
UPDATE dbo.Update_frag
SET name = REPLICATE('b', 3000)
WHERE ID > 120
--обратите внимание на отсутствие указателей пересылки,
--поскольку это кластеризованный индекс (не куча)
SELECT index_type_desc
,page_count
,CAST(avg_fragmentation_in_percent AS DECIMAL(6, 2)) AS avg_frag_in_percent
,fragment_count AS frag_count
,avg_fragment_size_in_pages AS avg_frag_size_in_pages
,CAST(avg_page_space_used_in_percent AS DECIMAL(6, 2)) AS avg_page_space_used_in_percent
,forwarded_record_count
FROM sys.dm_db_index_physical_stats(DB_ID('DML_DB'), OBJECT_ID('dbo.Update_frag'), NULL, NULL, 'DETAILED') Верхняя выдача - это до обновления. Заметим, что фрагментация была нулевой с высокой плотностью страницы. Нижний результат, полученный после обновления, показывает фрагментацию и низкий уровень плотности страниц, поскольку произошло разделение.
Управление разделением страниц и фрагментацией
Разделение страниц приводит к обновлению множества страниц, которое полностью журнализируется в журнале транзакций. Следующий очевидный вопрос такой: "Как избежать разделения страниц?" Один из способов - это использовать подходящий ключ кластеризации, который не допускает вставки данных на случайные страницы, а добавляет их в конец таблицы, тем самым избегая вставки на предыдущие страницы, что может вызвать их разделение.
Рекомендуемые характеристики ключа кластеризации - это уникальный, статичный, узкий и монотонно возрастающий. GUID вызывает разделение страниц в силу своей случайной природы, поэтому это не лучший выбор для ключа кластеризации. Вместо этого вы можете использовать монотонно возрастающий столбец IDENTITY или DATETIME. Однако при монотонно возрастающем ключе последняя страница может стать горячей точкой, выражающейся в конкуренции за вставку на последнюю страницу. Это означает, что могут иметь место множество одновременных вставок на последнюю страницу в памяти, вызывая высокие значения ожиданий PAGELATCH_xx для потоков. В SQL Server 2019 введена опция индекса, называемая OPTIMIZE_FOR_SEQUENTIAL_KEY, для улучшения пропускной способности для высококонкурентных вставок в индекс, тем самым понижая конкуренцию вставки на последнюю страницу.
Во-вторых, используйте подходящее значение коэффициента заполнения (Fill Factor) при создании или перестройке индекса. Fill Factor определяет, скольк свободного пространства резервируется на потенциальные будущие вставки на листовые страницы индекса. Правильное значение для Fill Factor диктуется типом рабочей нагрузки, которая выполняется на экземпляре. Предположим, что на страницах имеется много свободного пространства. В этом случае страницы имеют низкую плотность (так называемая внутренняя фрагментация), и память расходуется неэкономно, т.к. SQL Server считывает страницы в память целиком, независимо от того, полностью они заполнены или частично. Так же, если вы выберите заполнение страниц до их емкости, то высока вероятность разделения страниц и фрагментации. Итак, нужно тщательно оценивать рабочую нагрузку.
Значение Fill Factor 0 означает то же самое, что и 100, это заполнение страниц до их емкости. 0 является значением по умолчанию коэффициента заполнения при создании индекса, и может быть изменено для соответствия рабочей нагрузке. Единственный повод начать со 100, это мониторить уровни фрагментации, и постепенно настраивать значение, уменьшая его до оптимального значения.
Минимизирует фрагментацию также исключение типов данных переменной длины. Данные таких типов как VARCHAR и NVARCHAR могут изменяться со временем и потенциально вызвать разделение страниц. Версионность строк также может вызвать фрагментацию. При включении версионности строк SQL Server сохраняет старую версию записей в хранилище версий в tempdb и добавляет 14-байтовый тег версии к строкам в базе данных, чтобы связать их со строками в хранилище версий. Это на 14 байтов увеличивает каждую строку, что может спровоцировать перемещение строк и, соответственно, разделение страниц.
Сжатие базы данных тоже вызывает фрагментацию, которую можно исправить перестройкой индекса. Сжатие перемещает страницы с конца файла данных вперед и освобождает свободное пространство в конце. SQL Server перемещает страницы вперед, не следуя принципу физической близости, создавая фрагментацию. Следовательно, нужно по возможности избегать сжатия.
Мы должны следовать надлежащей стратегии реорганизации и перестройки индексов. Microsoft рекомендует перестраивать индекс, если фрагментация превышает 30% и выполнять реорганизацию при 5-30 процентов. В то время как перестройка индекса выполняется в рамках транзакции, которая при остановке полностью откатывается, реорганизация индекса может прерываться без потери работы, выполненной до точки останова. В SQL Server 2017 была введена функция возобновляемой онлайн перестройки индекса, которая позволяет прерывать перестройку индекса либо вручную, либо по причине сбоя после его устранения.
Заключение
Индексы должны обслуживаться регулярно для удаления внутренней и внешней фрагментации. Следует внимательно оценивать Fill Factor, т.к. для него нет универсального значения. Выбирайте уникальный, статичный, узкий и монотонно возрастающий столбец для кластеризованного индекса, чтобы минимизировать разделение страниц и фрагментацию. Некластеризованные индексы должны быть узкими, чтобы увеличить плотность, ведущую к более быстрому обслуживанию индекса, эффективному использованию буферного пула, уменьшению операций ввода-вывода, более быстрым операциям создания резервных копий и DBCC CHECKDB. Вставки, обновления и удаления все могут привести к фрагментации. Однако удаления технически вызывают зазоры между страницами, которые могут, в конце концов, приводить к фрагментации, но это не так существенно, как фрагментация, вызываемая вставками и обновлениями.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой