Пересказ статьи Anjuman Bhattacharyya. Statement Timeout in PostgreSQL
Необходимо предохранять вашу базу данных от долгоиграющих запросов, т.к. они могут подвесить ее. Для защиты вашей базы данных PostgreSQL имеется один конфигурационный параметр, устанавливающий максимально дозволенную длительность любого исполняющегося запроса. Это параметр statement_timeout.
Конфигурационный параметр: statement_timeout
Описание: Устанавливает максимально допустимую продолжительность любого оператора.
Значение по умолчанию: 0 (0 означает, что параметр выключен; обычно измеряется в мс; в основном указывается в мс или сек).
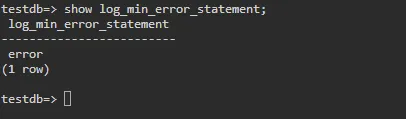
PostgreSQL также записывает в журнал запрос, время ожидания которого истекло, если другой параметр
log_min_error_statement установлен в ERROR. Вы можете проверить это, выполнив следующую команду в вашей базе данных.
 Продолжить чтение "Тайм-аут оператора в PostgreSQL"
Продолжить чтение "Тайм-аут оператора в PostgreSQL"
Пересказ статьи Semab Tariq. Performance impact of using ORDER BY with LIMIT in PostgreSQL
При запросах к большим наборам данных в PostgreSQL сочетание предложений ORDER BY и LIMIT может существенно влиять на производительность. ORDER BY сортирует данные, а LIMIT ограничивает число возвращаемых строк, но вместе они создают узкое место в производительности. Понимание взаимодействия этих операций и оптимизация их использования представляется весьма важным для поддержания эффективной производительности базы данных и гарантии быстрого выполнения запросов.
В этой статье мы рассмотрим, как они могут повлиять на производительность запроса.
Ниже приведена структура простой таблицы с именем person, которая будет использоваться в наших тестах.
Продолжить чтение "Влияние на производительность использования ORDER BY с LIMIT в PostgreSQL"
Пересказ статьи Tarik Favero. PostgreSQL Execution plan algorithms
В этой статье описываются наиболее общие алгоритмы, которые PostgreSQL может использовать в плане выполнения данного запроса. Примите к сведению, что это не полный список; позднее могут быть добавлены другие алгоритмы.
Алгоритмы пути доступа
Все планы выполнения описывают способ доступа к данным для обеспечения вывода результатов запроса. Поэтому мы обнаружим список операторов, которые выполнялись или будут выполняться для получения результатов.
Мы увидим такие алгоритмы доступа к данным, как Seq Scan, Index Scan, Index-only scan, Bitmap index scan, Bitmap heap scan и их параллельные реализации. В зависимости от условий соединения в JOIN мы увидим алгоритмы комбинации таблиц, такие как Nested loop, Hash-join и Merge. Кроме того, будет представлена информация относительно агрегации, сортировки и буферизации.
Каждый алгоритм имеет свои собственные особенности, которые в зависимости от множества факторов могут оказаться более или менее производительными. Давайте более подробно рассмотрим каждый алгоритм доступа.
Продолжить чтение "Алгоритмы плана выполнения в PostgreSQL"
Пересказ статьи Jared Westover. Replace SQL Cursors with Set Based Operations – OUTPUT and MERGE
Курсоры имеют плохую репутацию в SQL Server, и вполне залуженную. Они находят свое применение в таких областях, как выполнение задач по обслуживанию баз данных. Я избегаю их, когда дело касается стандартного кода T-SQL. Проблемы производительности становятся заметными при работе с таблицами сколь-нибудь заметного размера. Если вы имеете за спиной более процедурный язык, бывает трудно думать не в терминах курсора. Но не беспокойтесь, есть надежда.
В этой статье я хочу сделать обзор типичного паттерна, который мы все видели. Он включает использование курсора или цикл WHILE для вставки или обновления данных. Начнем с того, чтобы разобраться, почему разработчик может по умолчанию начинать с курсора. Далее я построю типичный курсор для решения этой задачи. Затем мы разберемся, как можно быстрей достичь того же вывода с помощью операции на основе множеств.
Продолжить чтение "Замена курсоров SQL операциями на основе множеств - OUTPUT и MERGE"
Пересказ статьи Cláudio Silva. What happens when we drop a column on a SQL Server table? Where's my space
Короткий ответ: столбец отмечается как "удаленный" и перестанет быть видимым/используемым. Но, что наиболее важно - размер записи/таблицы останется неизменным.
Операция с метаданными
Удаление столбца является логической операцией с метаданными, а не физической. Это означает, что данные не удаляются/перезаписываются при этом действии. Если говорить об удалении данных (записей), то как упоминает
здесь Пол Рэндал:
«стоимость этого будет отложена для вставляющих, а не для удаляющих».
Продолжить чтение "Что происходит при удалении столбца в таблице SQL Server? Где мое пространство?"
Пересказ статьи Hagen Hübel. Understanding the Performance Difference in Adding Columns in PostgreSQL
Оптимизация производительности базы данных крайне важна, особенно, когда речь идет о больших таблицах. Многие администраторы баз данных и разработчики знакомы с типичным сценарием добавления новых столбцов в существующие таблицы . Недавно я столкнулся с интересной ситуацией в PostgreSQL, которая позволила увидеть то, как база данных обрабатывает добавление и обновление столбцов. Вот что я обнаружил, и почему это важно.
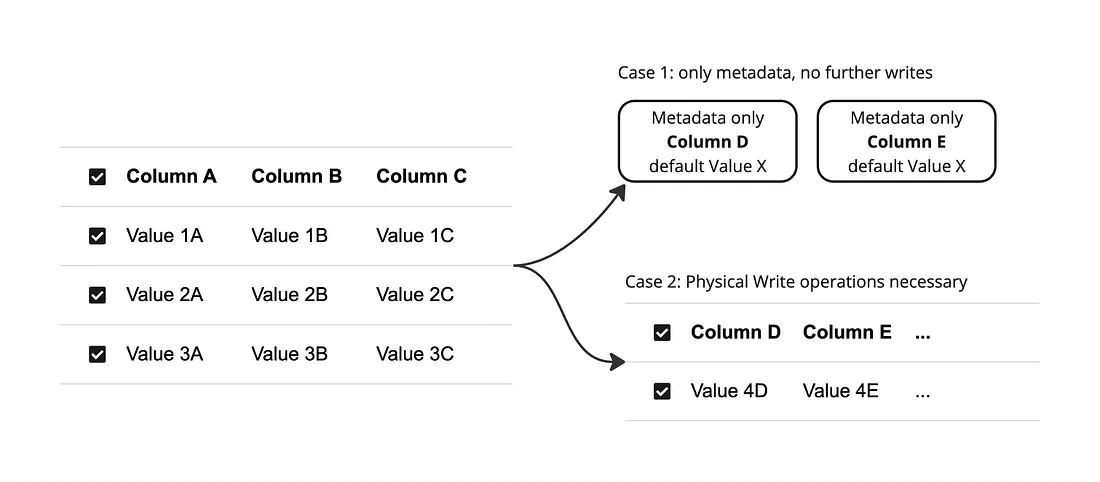
Вопрос
Представьте, что у вас есть большая таблица, содержащая десятки тысяч записей. Вы хотите добавить новый допускающий NULL-значения столбец без значения по умолчанию, а затем выполнить оператор UPDATE, чтобы установить для этого нового столбца заданное значение. Этот процесс занимает значительное время. Однако, если вы вместо этого добавляете новый столбец со значением по умолчанию, это не занимает так много времени. Почему имеет место такая разница в производительности?
Продолжить чтение "Понимание разницы в производительности при добавлении столбцов в PostgreSQL"
Пересказ статьи Hugo Kornelis. Plansplaining part 30 – Static cursors
В части 30 серии
plansplaining мы продолжим обсуждение обработки курсоров. Я рекомендую вам сначала прочитать
предыдущую статью, где я излагаю основы.
Тестовый запрос
В этой серии я буду придерживаться использования одного и того же тестового запроса, который выводит данные по продажам и товарам, которые были проданы в количестве более 10 единиц в пределах заданного диапазона заказов.
Продолжить чтение "Статические курсоры"
Пересказ статьи Lukas Vileikis. Optimizing MySQL: Deleting Data
Удаление данных - основы
Спросите любого администратора баз данных, как удалить данные, и вы услышите об одном или двух следующих методов:
- Выполните запрос DELETE - запросы DELETE довольно самоочевидны, и они удаляют строки в таблицах базы данных.
- Выполните запрос TRUNCATE - TRUNCATE - это брат DELETE с тем главным отличием, что DELETE удаляет подмножество строк, а TRUNCATE удаляет все строки таблицы. TRUNCATE имеет еще одно отличие - он значительно быстрей, чем DELETE при удалении всех строк таблицы, поскольку он имеет меньше накладных расходов. Но давайте начнем с начала.
Для начала рассмотрим обычный запрос DELETE, который в MySQL выглядит следующим образом:
DELETE FROM имя_таблицы WHERE [логическое_выражение]
По частям:
Продолжить чтение "Оптимизация MySQL: удаление данных"
Пересказ статьи Eitan Blumin. SQL Server Index Mastery: Choosing the Right Column Order
Введение
Оптимизация производительности SQL Server - непростая тема, и проектирование индексов играет в ней жизненно важную роль, способствуя эффективности выполнения запросов к базе данных.
Одним из ключевых аспектов, которые часто влияют на производительность, является порядок столбцов в индексе.
В этом руководстве я буду использовать мой реальный опыт работы консультантом для исследования мыслительного процесса, стоящего за выбором лучшей последовательности столбцов в индексе, логики принятия решений и предложения некоторых практических решений для достижения оптимальной производительности базы данных.
Продолжить чтение "Мастерство работы с индексами в SQL Server: выбор правильного порядка столбцов"
Пересказ статьи Simon Liew. SQL Server Filtered Index Essentials Guide
Фильтрованные индексы могут значительно повысить производительность запроса, но простые ошибки могут помешать их использованию. Мы поможем вам понять, как использовать фильтрованные индексы SQL Server и выявить запросы, которые могут получить от этого преимущество, которого они не имели.
Фильтрованные индексы - это обычные некластеризованные индексы, которые содержат только подмножество данных (фильтрованные данные). Фильтрованные индексы особенно полезны для узкого покрытия запроса, который требует быстрого извлечения и высокой доступности.
Ключом для правильного использования оптимизатором SQL Server фильтрованных индексов является:
- Убедиться, то предикат (предикаты) запроса эквивалентны выражению фильтрованного индекса. Иногда предикат не должен точно совпадать с выражением, и оптимизатор SQL Server может определить это. Однако чем проще, тем лучше.
- Предикат ((предикаты) запроса на столбце (столбцах) фильтрованного индекса не параметризуются или не используют присвоение переменной.
Продолжить чтение "Фильтрованные индекс в SQL Server: основы"
Пересказ статьи Yash Marathe. Generalized Inverted Index in PostgreSQL
Исследование достоинств и недостатков GIN-индексов в PostgreSQL
Содержание
- Мотивация
- Введение
- GIN-индексирование изнутри
- Практический пример
- Уроки индекса GIN Trigram GitLab
- Заключение
- Ссылки
Продолжить чтение "Обобщенный инвертированный индекс в PostgreSQL"
Пересказ статьи Erik Darling. The How To Write SQL Server Queries Correctly Cheat Sheet Conditional Join and Where Clauses
Так или иначе
Оператор OR вполне легитимно может использоваться в операторах SQL. Если вы используете предложение IN, велика вероятность, что оптимизатор преобразует его в последовательность операторов OR.
Например, IN(1, 2, 3) может в результате стать = 1 OR = 2 OR = 3 без вашего участия. Оптимизаторы так забавляются. Забавные маленькие кролики.
Проблема обычно возникает не тогда, когда вы пишете в запросе IN или OR для одного столбца со списком литеральных значений, а когда вы:
- Используете OR по множеству столбцов в предложении WHERE.
- Используете OR в предложении JOIN любого сорта.
- Используете OR для обработки параметров или переменных NULL.
Добавьте немного сложности, объединив две таблицы и попросив что-то вроде:
Продолжить чтение "Шпаргалка по правильному написанию запросов к SQL Server: условное соединение и предложение WHERE"
Пересказ статьи Lorenzo Uriel. The SQL Week: Data Modeling
Наличие хорошей документации и четко определенного процесса сделают вас более способными что-то создавать и внедрять.
Одним из наиболее любимых мной процессов является моделирование данных.
Итак, из чего состоит процесс моделирования?
Можно упомянуть:
1. Анализ требований
2. Концептуальная модель (ERD - ERM)
3. Логическая модель (таблицы и связи)
4. Физическая модель (создание таблиц в базе данных)
Это будут пункты этой части, в результате которой я хочу построить с вами реальный пример с нуля.
Продолжить чтение "Неделя SQL: моделирование данных"
Пересказ статьи Andy Brownsword. Solving Parameter Sniffing with Multiple Execution Plans
Динамический SQL имеет много вариантов использования, и один из них может помочь нам разрешить проблемы прослушивания параметра (Parameter Sniffing). Здесь мы рассмотрим как он может использоваться для генерации
нескольких планов выполнения для одного и того же запроса.
Прослушивание параметра является общеизвестной проблемой. Даже для простых запросов мы можем столкнуться с получением неоптимального плана. Имеется несколько способов с применением динамического SQL, которые мы можем использовать для решения этой проблемы. Тут мы продемонстрируем один из них: инъекция комментария.
Давайте начнем с процедуры и индекса в базе данных StackOverflow:
CREATE OR ALTER PROCEDURE dbo.GetPopularUsers (
@MinimumViews INT
) AS
BEGIN
SELECT Id, DisplayName
FROM dbo.Users
WHERE [Views] >= @MinimumViews;
END
GO
CREATE INDEX [Views]
ON dbo.Users ([Views]);
Продолжить чтение "Решение проблемы прослушивания параметра при помощи нескольких планов выполнения"
Пересказ статьи Erik Darling. The How To Write SQL Server Queries Correctly Cheat Sheet: Cross Apply And Outer Apply
Ситуации
В конечном счете я преобразую множество производных соединений, особенно тех, которые используют оконные функции, к использованию синтаксиса APPLY. Иногда для этого существуют хорошие индексы, в других случаях необходимо их создавать, чтобы избежать
"Жадного спула индексов".
Одним из наиболее частых вопросов, которые я получаю от разработчиков, является вопрос о том, когда следует использовать apply, а не другой синтаксис соединения.
Короткий ответ заключается в том, что я начинаю мысленно представлять себе, как синтаксис apply может быть полезен, когда:
- Имеется небольшая внешняя таблица (FROM) и большая внутренняя таблица (APPLY).
- Мне требуется выполнить значительный объем работы на внутренней стороне соединения.
- Целью запроса является получение top N на группу или что-то подобное.
- Я пытаюсь получить параллельные вложенные циклы вместо выбора некоторого альтернативного плана.
- Чтобы заменить скалярную UDF в списке select на встроенную (inline) UDF.
- Чтобы использовать конструкцию VALUES необычным способом.
Большинство этого ситуативно и требует немного опыта и знакомства, чтобы быстро это заметить.
Продолжить чтение "Шпаргалка по правильному написанию запросов к SQL Server: Cross Apply и Outer Apply"
