Пересказ статьи Ryan Booz. Six Things to Monitor with PostgreSQL
В этой статье описываются шесть метрик производительности, которые должны быть на первом месте вашей стратегии мониторинга PostgreSQL. Используя инструмент, подобный SQL Monitor, для отслеживания этих метрик во времени и устанавливая для них базовые линии, вы сможете сразу выявлять нехватку ресурсов или проблемы с производительностью, быстро диагностируя причину и предотвращая возникновение проблем для пользователей.
Продолжить чтение "Шесть вещей для мониторинга в PostgreSQL"
Пересказ статьи MATTHEW MCGIFFEN. Introduction to SQL Server Query Store
Появление в SQL 2016 Query Store (хранилище запросов) явилось, без сомнения, наиболее привлекательной и обсуждаемой новой функциональностью. В этой статье мы просто бросим краткий взгляд на нее, что это такое, как запустить и как это можно использовать. Это будет довольно краткий обзор - потребуется целая книга, чтобы описать все подробно - но, надеюсь, что он даст вам понятие о том, насколько это будет полезно и как начать использовать.
Продолжить чтение "Введение в хранилище запросов SQL Server"
Пересказ статьи Henrietta Dombrovskaya. Uncovering the mysteries of PostgreSQL (auto) vacuum
В этой статье мы поговорим о конфигурационных параметрах PostgreSQL, которые управляют теневыми процессами (auto)vacuum и (auto)analyze.
Зачем нужно вакуумировать
Прежде чем говорить о параметрах, относящихся к vacuum и analyze, необходимо коснуться понятия вакуумирования в PostgreSQL. Это понятие является спецификой PostgreSQL, и у администраторов, приходящих из Oracle и SQL Server, может вызывать недоумение - вы не можете непосредственно связать ее со своим предшествующим опытом. (Замечание: Как Oracle, так и SQL Server имеют много больше общего в конфигурации. Например,
оптимизированные для памяти таблицы SQL Server имеют подобный процесс, который называется
сборкой мусора.)
Продолжить чтение "PostgreSQL (auto) vacuum - уже не тайна"
Пересказ статьи Eric Blinn. Cheat Sheet for SQL Server DBAs - Monitoring Current Activity, Blocking and Performance
Видимо, каждый администратор баз данных имеет флэшку или общий диск со скриптами, подходящими почти для любой ситуации. Как построить такую библиотеку файлов T-SQL?
Это вторая статья в данной серии, в которой содержится несколько скриптов, которые я обычно использую, когда SQL Server имеет проблемы с производительностью. Каждый скрипт сопровождается кратким объяснением его использования. Эти скрипты предоставляются как-есть без каких-либо гарантий.
Продолжить чтение "Шпаргалка для администратора БД - мониторинг активности, блокировок и производительности"
Пересказ статьи Gaurav Rajapurkar. SQL Performance Tuning
Настройка производительности SQL - это процесс оптимизации запросов SQL, гарантирующий их быстрое выполнение, насколько это возможно. Имеется множество факторов, которые влияют на производительность SQL-запросов, таких как число участвующих в запросе таблиц, размер и число столбцов в таблицах, индексы на таблицах.
Настройка производительности SQL является важным элементом, который сказывается на масштабируемости и скорости запросов. Здесь обсуждаются некоторые способы настройки SQL.
Продолжить чтение "Настройка производительности SQL"
Пересказ статьи Steve Stedman.SQL Server DBCC Commands: DBCC FREEPROCCACHE
DBCC FREEPROCCACHE является командой DBCC в Microsoft SQL Server, которая может использоваться для очистки процедурного кэша - области памяти, в которой хранятся планы выполнения для хранимых процедур, триггеров и ad hoc пакетов Transact-SQL. Очистка процедурного кэша может быть полезна для устранения проблем с производительностью или тестирования влияния изменений схемы базы данных на производительность запросов.
Продолжить чтение "Команды DBCC в SQL Server: DBCC FREEPROCCACHE"
Пересказ статьи Joe Billingham. Should I use a Table Variable or a Temporary Table?
При работе с SQL Server нет ничего необычного в необходимости сохранять данные во временной таблице или табличной переменной. Хотя оба варианта могут использоваться для достижения одной и той же цели, они по-разному могут влиять на производительность и возможность написания эффективного кода. Давайте исследуем различия между табличными переменными и временными таблицами, и когда предпочтительно использовать ту или иную.
Продолжить чтение "Что использовать - табличную переменную или временную таблицу?"
Пересказ статьи Brent Ozar. What Does Setting the SQL Server Compatibility Level Do?
Если щелкнуть правой кнопкой по базе данных в SQL Server Management Studio, вы получаете возможность установить уровень совместимости (Compatibility Level) на уровне базы данных:
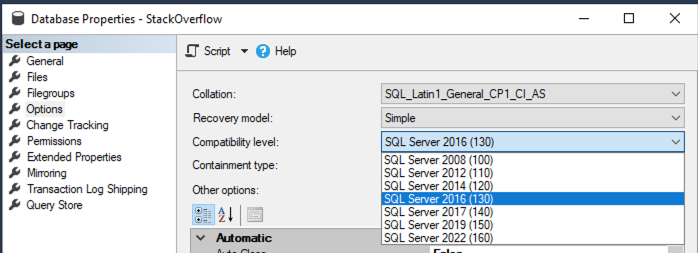 Продолжить чтение "Что делает установка уровня совместимости в SQL Server?"
Продолжить чтение "Что делает установка уровня совместимости в SQL Server?"
Пересказ статьи Jared Westover. Return TOP (N) Rows using APPLY or ROW_NUMBER() in SQL Server
По большей части, существует много способов сделать одну и ту же вещь. Например, если вам нужно вернуть заданное число строк из табличнозначной функции или табличного выражения. Обычно для выполнения этой задачи разработчики применяют метод, основанный на операторе APPLY. Но является ли APPLY лучшим методом для получения результатов? Как узнать, какой метод выбрать? И что делает один метод лучше другого?
Здесь мы сравним два метода для достижения одних и тех же результатов. Сначала я детально рассмотрю оператор APPLY в случаях, когда он обычно используется. Вы знаете, что он существует
в двух вариантах? Затем мы сравним APPLY с ROW_NUMBER() для получения TOP(n) строк из табличного выражения. Я расскажу о критериях, используемых для измерения производительности. Как вы думаете, кто из них победит при сравнении? К концу статьи вы будете знать, какой метод выбрать для вашего следующего проекта.
Продолжить чтение "Получение TOP(N) строк с помощью APPLY или ROW_NUMBER() в SQL Server"
Пересказ статьи Chad Callihan. Save Time Counting, Use IF EXISTS
При проверке существования значения или значений в таблице обычно не обязательно читать всю таблицу. Цель состоит в том, чтобы получить больше верных или ложных ответов, независимо от того, соблюдаются критерии или нет. Если критерии выполняются на первых нескольких записях, то нет необходимости продолжать чтение. Тем не менее, вы можете встретить скрипты, написанные с необязательным извлечением полного числа значений в таблице. Давайте сравним разницу в производительности между использованием COUNT(*) и “IF EXISTS” при проверке наличия значений.
Продолжить чтение "Экономьте время на подсчете, используйте IF EXISTS"
Пересказ статьи Eitan Blumin. Drop All Redundant Indexes In Every Database All At Once
Избыточные индексы в SQL Server - это явление значительно более общее, чем мне бы хотелось. Я встречал это довольно часто. Это означает, что данное сообщение в блоге все еще будет иметь значительную целевую аудиторию!
 Статья Brent Ozar
Статья Brent Ozar дает исчерпывающую информацию об избыточных/дублирующих индексах, что они означают, почему это плохо, и что нужно с этим делать.
Продолжить чтение "Удалить сразу все избыточные индексы в каждой базе данных"
Пересказ статьи Eric Blinn. Performance Problems and Solutions when using User Defined Functions in SQL Server
Может ли определяемая пользователем функция (UDF) являться причиной проблем с производительностью в SQL Server? Как это выяснить? Если это может быть частью проблемы, то что тут можно сделать?
UDF могут быть очень привлекательны для новых разработчиков T-SQL, особенно для тех, кто пришел с опытом в более традиционных процедурных языках программирования. Эти функции позволяют обеспечить более высокую степень повторного использования кода и могут упростить его читабельность. К сожалению, SQL Server использует теоретико-множественную парадигму программирования и зачастую не так хорош при выполнении UDF. Что хуже, многие традиционные методы настройки производительности не точно оценивают влияние UDF на запросы. Здесь мы будем изучать эту проблему и способы ее обхода.
Продолжить чтение "Решение проблем производительности при использовании UDF в SQL Server"
Пересказ статьи Lukas Vileikis. Optimizing Queries in MySQL: Optimizing Reads
Оптимизация операций чтения является одной из наиболее частых проблем, с которой сталкивается любой администратор баз данных. Не важно, какая система управления базами данных используется - MySQL, ее клоны Percona Server или MariaDB, MongoDB, TimescaleDB, SQL Server, или какие-либо другие, запросы на чтение касаются их всех. В первую очередь, можно привести примеры запросов SELECT, но многое также относится к UPDATE и DELETE, поскольку эти операторы тоже должны извлекать строки для работы с ними.
В этом блоге мы расскажем, как решить проблемы, связанные с этим вопросом. В конце статьи приводятся некоторые операторы DDL для загрузки тестовых данных.
Продолжить чтение "Оптимизация запросов в MySQL: оптимизация чтений"
Пересказ статьи rohind. Nullable vs Non-Nullable Columns and Adding Not Null Without Downtime in PostgreSQL
В этой статье мы поговорим о столбцах, которые допускают и не допускают NULL-значения применительно к базам данных PostgreSQL. Хотя на первый взгляд причины использовать те или иные столбцы кажутся очевидными, имеются неожиданности, связанные с каждым решением, которые сказываются либо на скорости разработки, либо на производительности приложения, либо вызывают ожидание.
Начнем с определений. Термины Nullable и non-nullable для столбцов используются для описания возможности для столбца таблицы базы данных допускать или не допускать значения NULL. NULL означает неизвестные или отсутствующие данные. Это не то же самое, что пустая строка или число нуль. Например, вам требуется вставить адрес электронной почты контакта в таблицу. Если вы не знаете, имеет ли контакт электронную почту, вы можете вставить NULL в столбец электронного адреса. В этом случае NULL означает, что электронный адрес неизвестен. NULL ничему не равен, даже самому себе. Выражение 'NULL == NULL' возвращает 'NULL', поскольку два неизвестных значения не должны быть равными. Для проверки наличия значения 'NULL' вы используете логический оператор 'IS NULL'. Оператор ниже вернет true для значения NULL или false в противном случае.
Продолжить чтение "Столбцы, допускающие и не допускающие значения NULL, и добавление Not Null без ступора в PostgreSQL"
Пересказ статьи Jared Westover. SQL Server Indexes with Key and Non-Key Columns as Covering Indexes to improve Performance
Когда я начинал создавать индексы в SQL Server, я добавлял столбцы только в ключ. Даже если зеленая полезная подсказка предлагала обратное. Это было так давно, что я уже не помню, где я впервые прочитал о размещении столбцов во включенной или неключевой части. Однако как-то я приспособился. Почему вы должны размещать столбцы в ключе, а не в ключевой области при создании индекса? Имеет ли это значение? Вот несколько вопросов, которые мы исследуем вместе с вами.
В этом руководстве я начну с определения понятия покрывающего индекса в SQL Server. Затем мы рассмотрим, как SQL Server хранит неключевые столбцы в структуре индекса. Мы узнаем о двух главных преимуществах добавления столбцов во включенную часть индекса. Это не все преимущества, но с этими двумя имеют дело наиболее часто. К концу руководства вы сможете уже сейчас начать создавать лучшие индексы.
Продолжить чтение "Покрывающие индексы SQL Server с ключевыми и неключевыми столбцами для повышения производительности"
