
PostgreSQL (auto) vacuum - уже не тайна
Пересказ статьи Henrietta Dombrovskaya. Uncovering the mysteries of PostgreSQL (auto) vacuum
В этой статье мы поговорим о конфигурационных параметрах PostgreSQL, которые управляют теневыми процессами (auto)vacuum и (auto)analyze.
Зачем нужно вакуумировать
Прежде чем говорить о параметрах, относящихся к vacuum и analyze, необходимо коснуться понятия вакуумирования в PostgreSQL. Это понятие является спецификой PostgreSQL, и у администраторов, приходящих из Oracle и SQL Server, может вызывать недоумение - вы не можете непосредственно связать ее со своим предшествующим опытом. (Замечание: Как Oracle, так и SQL Server имеют много больше общего в конфигурации. Например, оптимизированные для памяти таблицы SQL Server имеют подобный процесс, который называется сборкой мусора.)
Давайте начнем с того, как сохраняются данные в базе данных PostgreSQL. Общая структура блока показана на рис.1.
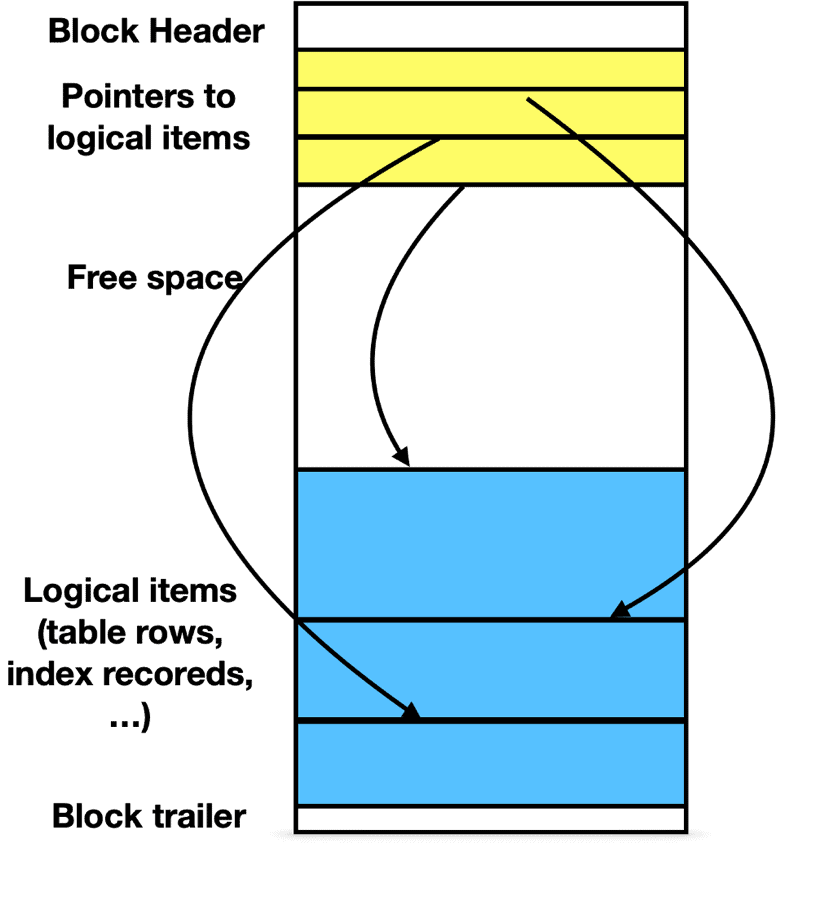
Рис.1. Общая структура блока
Строки таблицы хранятся в куче, и их порядок не гарантирован. На рис.1 можно увидеть свободное пространство в блоке, которое может быть заполнено новыми строками данных. Если ваш предшествующий опыт связан с движком РСУБД, использующим блокировки, вы можете подумать, что необходимо установить коэффициент заполнения каждой таблицы менее 100% с тем, чтобы оставалось некоторое пространство, главным образом, для поддержки обновления записей в том же самом блоке.
Приготовьтесь к сюрпризу! Хотя вы можете определить fillfactor <100%, эта опция редко используется в PostgreSQL. Причина состоит в том, что PostgreSQL никогда не обновляет строку по месту в силу его реализации управления параллелизмом!
Чтобы позволить множеству пользователей параллельно получать доступ к данным и избежать ожиданий при обновлении данных, PostgreSQL использует многоверсионное управление параллелизмом (MVCC). Это реализуется с использованием изоляции снимка (Snapshot Isolation - SI): каждый оператор SQL видит снимок данных (версию базы данных), каким он был, когда транзакция началась, вне зависимости от текущего состояния соответствующих данных. Этот подход дает несколько преимуществ:
Модифицированные кортежи сохраняются в новом месте, в том же блоке ли в другом, но если некоторые транзакции по-прежнему активно обращаются к старым версиям измененных кортежей, эти кортежи остаются «живыми».
Откуда PostgreSQL знает, какие версии следует оставлять живым, а какие могут быть утилизированы? Каждая таблица имеет несколько "скрытых" (системных) атрибутов, которые вам не видны, когда вы выполняете SELECT * FROM <таблица>. Двумя из этих скрытых атрибутов являются xmin, содержащий ID транзакции, которая создала строку, и xmax, хранящий ID транзакции, которая удалила строку (либо посредством обновления или удаления).
Теперь для любых процессов с ID транзакции, который находится в диапазоне >= xmin и <=xmax, эта строка является активной и должна быть видима в транзакции. PostgreSQL помечает кортеж "мертвым", если больше не существует активных транзакций, которые могли бы видеть эту строку. На рис.2 представлена схема блока с мертвым кортежем.
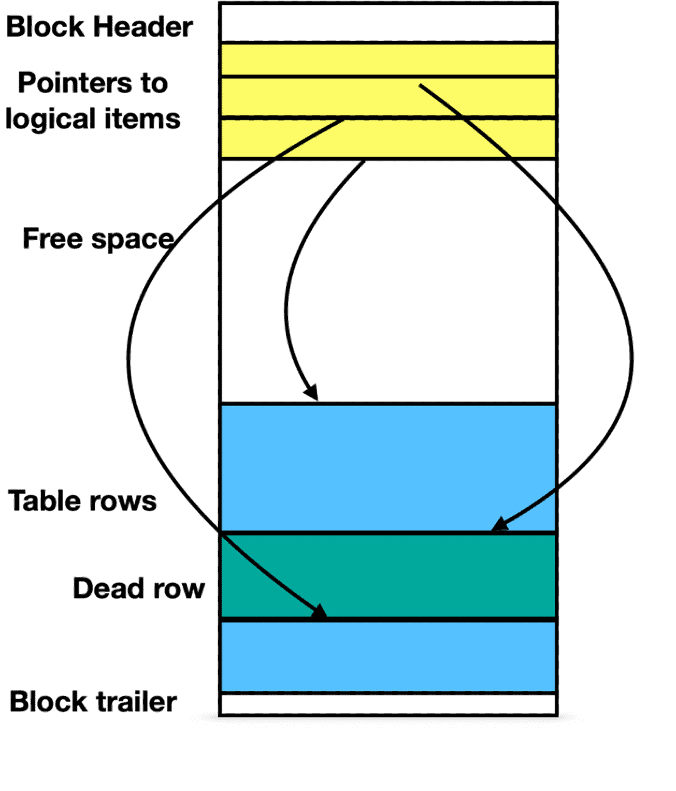
Рис.2. Схема блока с мертвым кортежем
Каково влияние MVCC на производительность базы данных? С одной стороны, отсутствие блокировок повышает производительность. С другой стороны, наличие множества версий и, следовательно, мертвых кортежей приводит к раздуванию таблицы и индекса.
VACUUM проверяет все блоки и помечает старые кортежи как "мертвые". Важно помнить, что VACUUM не переписывает блок и не "сжимает" данные. Он просто помечает пространство, занятое мертвыми кортежами, доступными для использования. Вы можете сжать данные и вернуть неиспользуемое пространство обратно операционной системе, выполнив VACUUM FULL.
К этому моменту можно почувствовать, что "информации слишком много", особенно, если вы впервые знакомитесь с понятием вакуумирования в PostgreSQL. Но прежде, чем продолжить, отметим, что работа VACUUM не ограничивается возвращением пространства. Помимо этого:
Если ваша работа заключается в управлении экземплярами PostgreSQL, возможно, вы захотите прочитать о вакуумировании то, что выходит за рамки настоящей статьи, которая является лишь введением. Просто помните, что существует еще много того, что делает вакуумирование.
Автовакуум - это демон, который периодически включает вакуумирование таблиц и индексов. Автовакуум не требует какого-либо расписания, напротив, его поведение определяется несколькими параметрами системы, которые будут описаны ниже в этой статье.
Поскольку концепция вакуумирования является необычной для других РСУБД и не вполне понятна новичкам в PostgreSQL (да и некоторым опытным людям тоже!), он является источником множества распространенных мифов.
В этом разделе я сделаю что могу для рассеивания этих мифов.
Реальность. VACUUM (и его расширение autovacuum) очевидно не обходятся бесплатно, но стоимость его значительно ниже, чем если бы он не выполнялся. Когда строки модифицируются, мертвые кортежи начинают накапливаться, и все может замедляться, если autovacuum не запускается регулярно.
Таблицы раздуваются (подробнее об этом ниже в статье), что замедляет последовательное сканирование. Карта видимости не обновляется, что мешает использованию сканирования только лишь индекса (PostgreSQL все еще требуется проверять кучу, чтобы убедиться, что индекс не указывает на мертвые кортежи).
Реальность. Процесс VACUUM прерывается, если он блокируется любой операцией записи. Время ожидания определяется параметром deadlock_timeout. Фактически для загруженной таблицы может быть выгодно часто выполнять процесс вакуумирования (в деле использовать autovacuum), поскольку в противном случае может не оказаться шанса завершить процесс днями и неделями по причине блокировки операциями записи.
Реальность. "Нагруженные системы" (в смысле модификации данных) могут быть загружены большую часть дня, а не только в определенное время дня, за небольшим исключением. Если вы выключаете autovacuum и выполняете vacuum по расписанию, например, во "время простоя", vacuum придется сделать больше работы (если система "нагружена" к этому времени может оказаться много мертвых кортежей!) Тогда вы можете столкнуться с блокировкой таблиц на более длительные периоды времени, поэтому вам потребуется убедиться, что в течение длительного периода времени не будут выполняться операции записи.
Кроме того, если поведение системы предсказуемо в целом, есть шанс массовых обновлений, и вы получите большее раздувание, чем ожидалось, с даже более серьезными последствиями.
Реальность. Напомню, что высвобождение пространства является лишь одной из нескольких функций, выполняемых VACUUM.Вы можете освободить пространство, но другие функции VACUUM не будут исполнены, и более важно, что старые записи не будут заморожены. Опять таки, если мы говорим о "нагруженных системах" риск оборачивания TXID становится выше.
Реальность. На таблице в небольшим числом операций записи autovacuum может выполняться раз в неделю ли даже реже. В следующем разделе описываются параметры, которые определяют, насколько часто будет выполняться вакуумирование на конкретной таблице.
Возможно посмотреть статистику обновлений для каждой таблицы и установить обслуживание на основе этой информации, но это фактически означало бы воспроизведение логики автоочистки (autovacuum). Более важно мониторить производительность системы и раздувание таблиц.
Существует много связанных с вакуумированием параметров, которые позволяют очень точно настроить этот процесс. Однако на практике зачастую достаточно правильно настроить лишь их малую часть. Большинство параметров управляют autovacuum, помогая настроить автоматическое выполнение процесса вакуумирования.
Вакуумирование жизненно важно для нормальной работы баз данных PostgreSQL, и autovacuum никогда не следует выключать, если не произошли действительно исключительные и необычные ситуации. В то же время autovacuum всегда следует настраивать на конкретные требования рабочей среды.
Настройка autovacuum не простая, поскольку необходимо принимать во внимание скорость очистки, уровень ввода/вывода и блокировки. Для начала, установки по умолчанию параметров, относящихся в вакуумированию должны работать адекватно. Спустя некоторое время проверьте раздувание системы, и, если оно окажется высоким, отрегулируйте настройки autovacuum. Что следует считать высоким раздуванием, зависит от многих факторов.
В среднем раздувание ниже 20% считается нормальным. Для больших таблиц 10% может считаться значительным раздуванием, в то время как для небольших таблиц даже 50% может быть приемлемо. Если раздувание не вызывает заметного падения производительности, нет острой необходимости заниматься этим.
Имеются примеры таких запросов, которые можно найти во многих блогах PostgreSQL и сайтах компаний. Многие решения требуют расширений. Если вы готовы установить дополнительные расширения для мониторинга раздувания, то можете использовать следующее:
Это одно из многих расширений, предоставляемых пакетом PostgreSQL contrib, поэтому вам не придется ничего загружать, просто выполните оператор CREATE. Имеющиеся функции документированы в PostgreSQL.
Если вы не хотите устанавливать расширения, следующие запросы дадут хорошие оценки:
table_bloat_check.sql
index_bloat_check.sql
Если ваша система хоть как-то активна, очень важно следить за раздуванием ваших объектов данных.
Хотя вы можете в pg_stat_all_tables выяснить время, когда последний раз выполнялись vacuum/autovacuum и analyze/autoanalyze, мы не рекомендуем отслеживать это значение. Как упоминалось в предыдущем разделе, если обновления не достигают порогового значения, нет необходимости выполнять autovacuum. Однако объект pg_stat_all_tables содержит множество ценной информации, которая может быть очень полезна при оценке состояния базы данных.
Для каждой таблицы pg_stat_all_tables содержит следующую информацию:
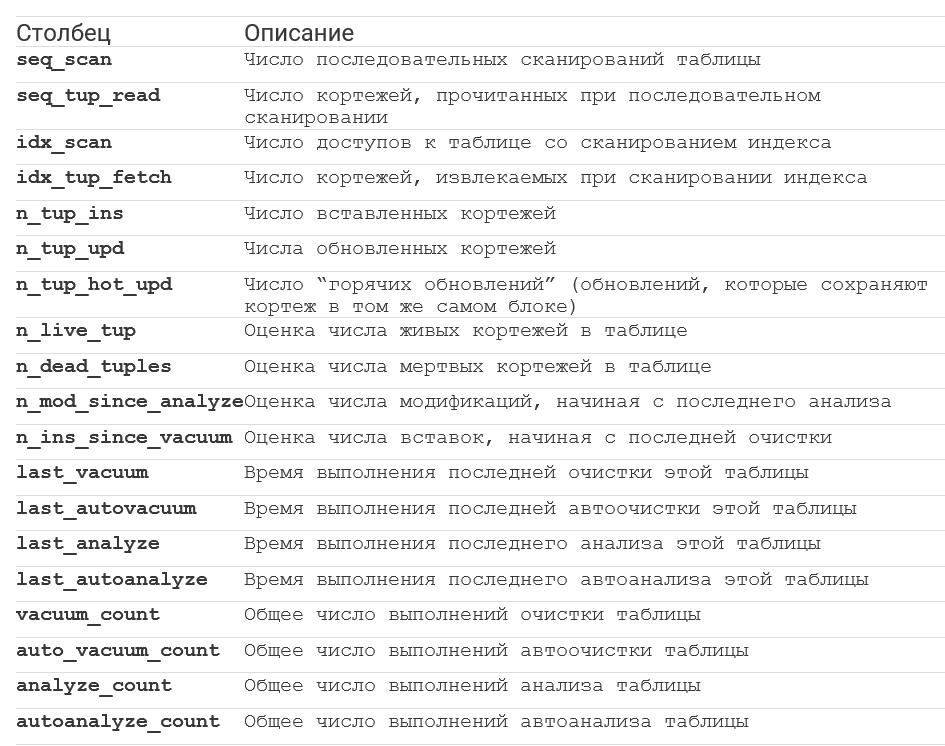
Можно увидеть, что эта таблица дает ценную информацию о динамике каждой таблицы. Однако единственный способ увидеть корректность настройки autovacuum - это выполнять запросы проверки раздувания на регулярной основе.
Не является необычным, что новые пользователи PostgreSQL и даже администраторы баз данных уделяют немного внимания настройке автоочистки и мониторингу раздувания таблиц и индексов. Это происходит потому, что эти понятия специфичны для PostgreSQL и не присутствуют в активном контрольном списке профессионалов, имеющих предшествующий опыт в других РСУБД.
Таким образом, важно изучить для себя, какую роль очистка и анализ играют для обеспечения нормальной работы PostgreSQL.
Ссылки по теме
Рис.1. Общая структура блока
Строки таблицы хранятся в куче, и их порядок не гарантирован. На рис.1 можно увидеть свободное пространство в блоке, которое может быть заполнено новыми строками данных. Если ваш предшествующий опыт связан с движком РСУБД, использующим блокировки, вы можете подумать, что необходимо установить коэффициент заполнения каждой таблицы менее 100% с тем, чтобы оставалось некоторое пространство, главным образом, для поддержки обновления записей в том же самом блоке.
Приготовьтесь к сюрпризу! Хотя вы можете определить fillfactor <100%, эта опция редко используется в PostgreSQL. Причина состоит в том, что PostgreSQL никогда не обновляет строку по месту в силу его реализации управления параллелизмом!
Многоверсионное управление параллелизмом
Чтобы позволить множеству пользователей параллельно получать доступ к данным и избежать ожиданий при обновлении данных, PostgreSQL использует многоверсионное управление параллелизмом (MVCC). Это реализуется с использованием изоляции снимка (Snapshot Isolation - SI): каждый оператор SQL видит снимок данных (версию базы данных), каким он был, когда транзакция началась, вне зависимости от текущего состояния соответствующих данных. Этот подход дает несколько преимуществ:
- Он предотвращает оператор от наблюдения несогласованных данных по причине модификации их другими транзакциями.
- Он обеспечивает изоляцию транзакции для каждой сессии.
Модифицированные кортежи сохраняются в новом месте, в том же блоке ли в другом, но если некоторые транзакции по-прежнему активно обращаются к старым версиям измененных кортежей, эти кортежи остаются «живыми».
Откуда PostgreSQL знает, какие версии следует оставлять живым, а какие могут быть утилизированы? Каждая таблица имеет несколько "скрытых" (системных) атрибутов, которые вам не видны, когда вы выполняете SELECT * FROM <таблица>. Двумя из этих скрытых атрибутов являются xmin, содержащий ID транзакции, которая создала строку, и xmax, хранящий ID транзакции, которая удалила строку (либо посредством обновления или удаления).
Теперь для любых процессов с ID транзакции, который находится в диапазоне >= xmin и <=xmax, эта строка является активной и должна быть видима в транзакции. PostgreSQL помечает кортеж "мертвым", если больше не существует активных транзакций, которые могли бы видеть эту строку. На рис.2 представлена схема блока с мертвым кортежем.
Рис.2. Схема блока с мертвым кортежем
Каково влияние MVCC на производительность базы данных? С одной стороны, отсутствие блокировок повышает производительность. С другой стороны, наличие множества версий и, следовательно, мертвых кортежей приводит к раздуванию таблицы и индекса.
Для чего используется VACUUM?
VACUUM проверяет все блоки и помечает старые кортежи как "мертвые". Важно помнить, что VACUUM не переписывает блок и не "сжимает" данные. Он просто помечает пространство, занятое мертвыми кортежами, доступными для использования. Вы можете сжать данные и вернуть неиспользуемое пространство обратно операционной системе, выполнив VACUUM FULL.
Что еще делает VACUUM?
К этому моменту можно почувствовать, что "информации слишком много", особенно, если вы впервые знакомитесь с понятием вакуумирования в PostgreSQL. Но прежде, чем продолжить, отметим, что работа VACUUM не ограничивается возвращением пространства. Помимо этого:
- Обновляется статистика данных, используемая планировщиком запросов PostgreSQL.
- Обновляется карта видимости, помечающая блоки, не содержащие мертвых кортежей.
- Защищает от потери очень старых данных из-за переноса идентификатора транзакции.
Если ваша работа заключается в управлении экземплярами PostgreSQL, возможно, вы захотите прочитать о вакуумировании то, что выходит за рамки настоящей статьи, которая является лишь введением. Просто помните, что существует еще много того, что делает вакуумирование.
Для чего служит автовакуум?
Автовакуум - это демон, который периодически включает вакуумирование таблиц и индексов. Автовакуум не требует какого-либо расписания, напротив, его поведение определяется несколькими параметрами системы, которые будут описаны ниже в этой статье.
Мифы о процессе вакуумирования
Поскольку концепция вакуумирования является необычной для других РСУБД и не вполне понятна новичкам в PostgreSQL (да и некоторым опытным людям тоже!), он является источником множества распространенных мифов.
В этом разделе я сделаю что могу для рассеивания этих мифов.
Миф №1. Процесс вакуумирования все замедляет
Реальность. VACUUM (и его расширение autovacuum) очевидно не обходятся бесплатно, но стоимость его значительно ниже, чем если бы он не выполнялся. Когда строки модифицируются, мертвые кортежи начинают накапливаться, и все может замедляться, если autovacuum не запускается регулярно.
Таблицы раздуваются (подробнее об этом ниже в статье), что замедляет последовательное сканирование. Карта видимости не обновляется, что мешает использованию сканирования только лишь индекса (PostgreSQL все еще требуется проверять кучу, чтобы убедиться, что индекс не указывает на мертвые кортежи).
Миф №2. Процесс вакуумирования блокирует другие операции
Реальность. Процесс VACUUM прерывается, если он блокируется любой операцией записи. Время ожидания определяется параметром deadlock_timeout. Фактически для загруженной таблицы может быть выгодно часто выполнять процесс вакуумирования (в деле использовать autovacuum), поскольку в противном случае может не оказаться шанса завершить процесс днями и неделями по причине блокировки операциями записи.
Миф №3. На загруженных критически важных базах данных хорошей идеей является выключение автоматического вакуумирования и выполнения заданий вакуумирования по расписанию во время простоя.
Реальность. "Нагруженные системы" (в смысле модификации данных) могут быть загружены большую часть дня, а не только в определенное время дня, за небольшим исключением. Если вы выключаете autovacuum и выполняете vacuum по расписанию, например, во "время простоя", vacuum придется сделать больше работы (если система "нагружена" к этому времени может оказаться много мертвых кортежей!) Тогда вы можете столкнуться с блокировкой таблиц на более длительные периоды времени, поэтому вам потребуется убедиться, что в течение длительного периода времени не будут выполняться операции записи.
Кроме того, если поведение системы предсказуемо в целом, есть шанс массовых обновлений, и вы получите большее раздувание, чем ожидалось, с даже более серьезными последствиями.
Миф №4. Если вы используете другие способы управления раздуванием, например, pg_squeeze, вам вообще не потребуется запускать вакуумирование
Реальность. Напомню, что высвобождение пространства является лишь одной из нескольких функций, выполняемых VACUUM.Вы можете освободить пространство, но другие функции VACUUM не будут исполнены, и более важно, что старые записи не будут заморожены. Опять таки, если мы говорим о "нагруженных системах" риск оборачивания TXID становится выше.
Миф №5. Вам нужно мониторить выполнение autovacuum и убедиться, что все таблицы вакуумируются, по крайней мере, ежедневно
Реальность. На таблице в небольшим числом операций записи autovacuum может выполняться раз в неделю ли даже реже. В следующем разделе описываются параметры, которые определяют, насколько часто будет выполняться вакуумирование на конкретной таблице.
Возможно посмотреть статистику обновлений для каждой таблицы и установить обслуживание на основе этой информации, но это фактически означало бы воспроизведение логики автоочистки (autovacuum). Более важно мониторить производительность системы и раздувание таблиц.
Наиболее важные параметры, которые управляют процессом вакуумирования
Существует много связанных с вакуумированием параметров, которые позволяют очень точно настроить этот процесс. Однако на практике зачастую достаточно правильно настроить лишь их малую часть. Большинство параметров управляют autovacuum, помогая настроить автоматическое выполнение процесса вакуумирования.
- autovacuum_vacuum_cost_delay: количество времени, которое процесс будет спать после превышения максимальной стоимости.
- Значением по умолчанию является 20 мс, которое является очень умеренным и может привести к тому, что вакуумирование не успеет почистить все изменения. Начните с уменьшения значения до 10 мс и, если потребуется, доведите его до 2 мс.
- Заметим, что этот параметр отличен от naptime (времени сна, смотрите ниже).
- autovacuum_max_workers: максимальное количество параллельных рабочих процессов (на сервере), которые вызываются при каждом вызове автоочистки.
- Наболее часто этот параметр устанавливается на половину общего числа параллельных рабочих процессов, определенных для экземпляра, однако часто преимущество дает еще большее увеличение этого числа.
- autovacuum_naptime: минимальная задержка между запусками автоочистки на любой заданной базе данных.
- Всякий раз, когда запускается демон autovacuum, он проверяет базу данных и при необходимости выполняет команды VACUUM и ANALYZE для таблиц в этой базе данных. Поскольку эта установка определяет время пробуждения на базу данных, рабочий процесс autovacuum будет начат с частотой autovacuum_naptime / число баз данных. Например, если autovacuum_naptime = 1 мин, и у нас имеется 5 баз данных, рабочий процесс autovacuum будет начинаться каждые двенадцать секунд
- Значением по умолчанию для этого параметра является 1 мин, однако для нагруженных баз данных с множеством операций записи будет полезно увеличить это значение, чтобы autovacuum не пробуждался слишком часто. Как и в случае многих других параметров, для этого параметра существует компромисс между «слишком часто» и «слишком много работы при каждом вызове».
- autovacuum_vacuum_scale_factor: процент изменений в таблице, после которого следует выполнять вакуумирование.
- Значение по умолчанию - 0.2; для больших таблиц следует уменьшить до 0.05 (и учтите это для всех таблиц, если так).
- autovacuum_analyze_scale_factor: процент изменений в таблице, после которого должен запускаться анализ (analyze).
- Значение по умолчанию - 0.1; для больших таблиц следует уменьшить до 0.05 (и учтите это также для всех таблиц) соответственно.
- Замечание: значением по умолчанию для autovacuum_vacuum_scale_factor является 0.2 (20%), а для autovacuum_analyze_scale_factor - 0.1 (10%). Хотя эти значения по умолчанию вполне применимы для таблиц умеренных размеров (в районе 500Мб), для больших таблиц эти значения обычно слишком велики.
- autovacuum_vacuum_cost_limit: Значение по умолчанию -1 для autovacuum_vacuum_cost_limit означает, что autovacuum_vacuum_cost_limit = vacuum_cost_limit. Однако это значение распределяется пропорционально между выполняющимися рабочими процессами autovacuum. Это делается для того, чтобы сумма пределов каждого рабочего процесса никогда не превышала предельного значения этой переменной. Следовательно, значение по умолчанию 200 для vacuum_cost_limit обычно слишком мало для высоконагруженного сервера баз данных с множеством процессов autovacuum. Должно быть установлено значение -1.
- vacuum_cost_limit: накопительная стоимость, после которой очистка должна останавливаться; следует установить в 200 х число рабочих процессов.
Как настраивать (auto)vacuum
Вакуумирование жизненно важно для нормальной работы баз данных PostgreSQL, и autovacuum никогда не следует выключать, если не произошли действительно исключительные и необычные ситуации. В то же время autovacuum всегда следует настраивать на конкретные требования рабочей среды.
Настройка autovacuum не простая, поскольку необходимо принимать во внимание скорость очистки, уровень ввода/вывода и блокировки. Для начала, установки по умолчанию параметров, относящихся в вакуумированию должны работать адекватно. Спустя некоторое время проверьте раздувание системы, и, если оно окажется высоким, отрегулируйте настройки autovacuum. Что следует считать высоким раздуванием, зависит от многих факторов.
В среднем раздувание ниже 20% считается нормальным. Для больших таблиц 10% может считаться значительным раздуванием, в то время как для небольших таблиц даже 50% может быть приемлемо. Если раздувание не вызывает заметного падения производительности, нет острой необходимости заниматься этим.
Как определить, раздуты ли ваши таблицы
Имеются примеры таких запросов, которые можно найти во многих блогах PostgreSQL и сайтах компаний. Многие решения требуют расширений. Если вы готовы установить дополнительные расширения для мониторинга раздувания, то можете использовать следующее:
CREATE EXTENSION pgstattuple;Это одно из многих расширений, предоставляемых пакетом PostgreSQL contrib, поэтому вам не придется ничего загружать, просто выполните оператор CREATE. Имеющиеся функции документированы в PostgreSQL.
Если вы не хотите устанавливать расширения, следующие запросы дадут хорошие оценки:
table_bloat_check.sql
index_bloat_check.sql
Если ваша система хоть как-то активна, очень важно следить за раздуванием ваших объектов данных.
Как следить
Хотя вы можете в pg_stat_all_tables выяснить время, когда последний раз выполнялись vacuum/autovacuum и analyze/autoanalyze, мы не рекомендуем отслеживать это значение. Как упоминалось в предыдущем разделе, если обновления не достигают порогового значения, нет необходимости выполнять autovacuum. Однако объект pg_stat_all_tables содержит множество ценной информации, которая может быть очень полезна при оценке состояния базы данных.
Для каждой таблицы pg_stat_all_tables содержит следующую информацию:
Можно увидеть, что эта таблица дает ценную информацию о динамике каждой таблицы. Однако единственный способ увидеть корректность настройки autovacuum - это выполнять запросы проверки раздувания на регулярной основе.
Заключение
Не является необычным, что новые пользователи PostgreSQL и даже администраторы баз данных уделяют немного внимания настройке автоочистки и мониторингу раздувания таблиц и индексов. Это происходит потому, что эти понятия специфичны для PostgreSQL и не присутствуют в активном контрольном списке профессионалов, имеющих предшествующий опыт в других РСУБД.
Таким образом, важно изучить для себя, какую роль очистка и анализ играют для обеспечения нормальной работы PostgreSQL.
Ссылки по теме
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой