
Удалить сразу все избыточные индексы в каждой базе данных
Пересказ статьи Eitan Blumin. Drop All Redundant Indexes In Every Database All At Once
Избыточные индексы в SQL Server - это явление значительно более общее, чем мне бы хотелось. Я встречал это довольно часто. Это означает, что данное сообщение в блоге все еще будет иметь значительную целевую аудиторию!

Статья Brent Ozar дает исчерпывающую информацию об избыточных/дублирующих индексах, что они означают, почему это плохо, и что нужно с этим делать.
Несколько лет назад Guy Glantser также опубликовал статью об удалении избыточных индексов. Она весьма полезна для нахождения всех избыточных индексов во всех таблицах в заданной базе данных.
Но вот чего не хватает в этих статьях, так это возможности легко генерировать команды Drop/Disable для этих избыточных индексов.
Кроме того, что если имеются "похожие" индексы, которые только "частично" избыточны, и, следовательно, недостаточно просто удалить один из них? Иначе это может негативно сказаться на производительности некоторых запросов.
Есть ли способ учесть все эти проблемы?
Каждый из них? Повсюду? Сразу?
Здесь я собираюсь показать вам, как обнаружить, получить подробную информацию и иметь возможность удалить КАЖДЫЙ избыточных индекс ЛЮБОЙ формы и размера:
Ссылка на скачивание скрипта приведена в конце статьи.
ВАЖНОЕ ЗАМЕЧАНИЕ:
Важно отметить, что вам следует удалять только действительно избыточные индексы. Перед удалением индекса следует убедиться, что он явно не используется какими-либо запросами или хранимыми процедурами в вашей базе данных посредством табличного хинта или хинта запроса.
Есть несколько разных случаев использования, когда будут иметь место избыточные индексы.
Эти случаи использования будут отличаться друг от друга на основании различий или подобия нескольких свойств индекса:
В разрезе этой статьи я буду предполагать следующее:
С этим покончено, давайте начнем!
Полностью дублируемым индексом считается такой, у которого идентичны все ключевые и все включенные столбцы.
Пример:
Пусть у нас имеется таблица с именем Products и следующими столбцами:
И пусть мы создали два индекса на этой таблице:
Индекс 1:
Индекс 2:
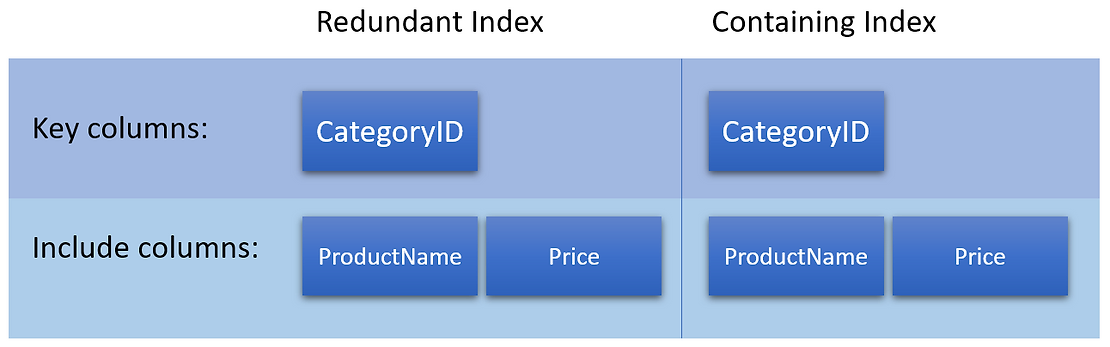
Оба индекса имеют один и тот же ключевой столбец CategoryID и одинаковые включенные столбцы - ProductName и Price. Следовательно индекс 2 является полным дубликатом индекса 1.
Исправление:
В данном случае мы можем удалить индекс 2, поскольку он дублирует индекс 1 и не дает никаких дополнительных преимуществ. Удаление избыточного индекса может помочь улучшить производительность запросов и уменьшить использование места в хранилище.
Полностью покрывающий индекс будет избыточным, если все его ключевые столбцы являются также первыми ключевыми столбцам другого индекса. Другой (содержащий) индекс может потенциально иметь дополнительные ключевые столбцы и/или может иметь больше включенных столбцов, помимо столбцов в избыточном индексе.
Важно, что содержащий индекс имеет все, что есть в избыточном индексе, и, возможно, что-то дополнительно.
Пример:
Пусть у нас имеется таблица Orders со следующими столбцами:
И пусть мы создали два следующих индекса на этой таблице:
Индекс 1:
Индекс 2:
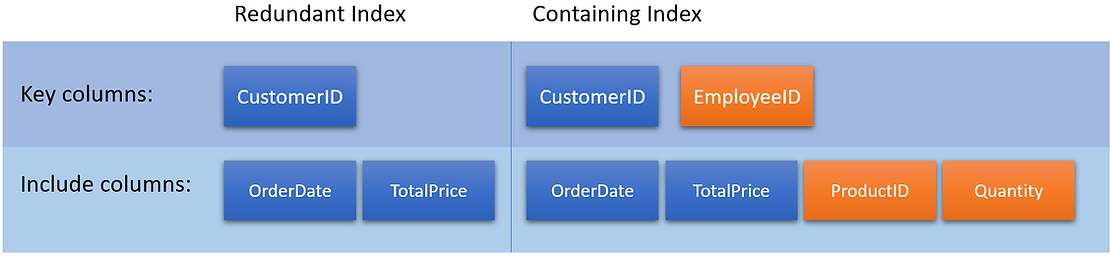
В этом случае индекс 2 включает все столбцы в индексе 1 и содержит дополнительный ключевой столбец EmployeeID. Кроме того, индекс 2 содержит дополнительные включенные столбцы ProductID и Quantity. Следовательно, индекс 2 является более объемлющим, чем индекс 1, и покрывает все запросы, которые покрывает индекс 1, плюс дополнительные запросы. Индекс 1 является избыточным в данном сценарии, поскольку он не дает дополнительного преимущества.
Исправление:
Мы можем удалить индекс 1 без влияния на производительность любых запросов.
Частично избыточный индекс - это индекс, у которого ключевые столбцы являются также первыми ключевыми столбцами другого индекса. Но включенные столбцы могут полностью различаться. Это означает, что содержащий индекс способен выполнять ту же операцию поиска (seek), что и избыточный индекс, но может потребоваться добавить в него несколько включенных столбцов, чтобы полностью обеспечить аналогичную функциональность. В противном случае, индекс либо не будет использоваться, либо потребуется дополнительная операция поиска ключа (key lookup).
Пример:
Пусть у нас есть таблица Customers со следующим столбцами:
И пусть мы создали следующую пару индексов на этой таблице:
Индекс 1:
Индекс 2:
В этом случае индекс 2 содержит ключевой столбец City, который также является первым ключевым столбцом в индексе 1. Однако индекс 2 имеет дополнительные включенные столбцы Email и Phone, которые не включены в индекс 1.
Хотя индекс 2 покрывает некоторые дополнительные запросы, которые не покрывает индекс 1, он является частично избыточным, поскольку ключевой столбец City уже покрывается индексом 1. Это означает, что индекс 1 уже может выполнять те же операции поиска, что и индекс 2, при условии, что запросы выполняют фильтрацию только по столбцу City.

Исправления:
Чтобы полностью обеспечить функциональность индекса 2, мы должны дополнительно добавить в индекс 1 включенные столбцы Email и Phone. Это устранит необходимость в избыточном индексе 2 и будет гарантировать оптимальное использование индекса для запросов, которые выполняют фильтрацию по столбцу City.
Обновленный синтаксис для индекса 1:
Удаляя избыточный индекс и обновляя содержащий индекс дополнительными включенными столбцами, мы можем уменьшить использование пространства хранилища и сделать базу данных более эффективной.
ПРЕДУПРЕЖДЕНИЕ:
Иногда при попытке создать "все покрывающий" индекс для замены всех его избыточных/частично-избыточных индексов вы рискуете создать "широкие" индексы, которые имеют очень длинный ключ или списки включенных столбцов.
Хотя это все еще "выгодно" с точки зрения использования пространства хранилища сравнительно с присутствием избыточных индексов, имеется риск падения производительности. Это обусловлено тем, что чем больше столбцов находится в индексе, тем больше данных требуется сканировать, читать и парсить во время операций поиска или сканирования индекса.
Поэтому будьте осторожны, чтобы не получить огромные списки столбцов в ваших индексах, иначе вы можете ухудшить производительность некоторых запросов.
Вы правы, работы много. Но, к счастью, возможно "автоматизировать" ее большую часть, написав скрипт T-SQL!
Используйте этот скрипт из нашего Madeira Toolbox:
Redundant Indexes Detailed - All Databases.sql
По умолчанию этот скрипт возвращает два различных результирующих набора.
Первый - это "подробный" результирующий набор, показывающий все избыточные индексы и индексы, которые их "содержат". Он имеет множество полезных деталей, но, возможно, будет включать дублирующуюся информацию (если тот же самый индекс "содержится" более чем в одном индексе).
Второй результирующий набор является "сводным", он показывает только избыточные индексы, и каждый избыточный индекс показан только один раз. Информация не дублируется, но некоторые детали опущены (которые можно найти в первом результирующем наборе). Вы можете использовать этот второй набор как единственный источник информации об избыточных индексах, которые должны быть удалены/отключены.
Обратите внимание на столбцы "*_index_seeks", "*_index_scans" и "*_index_updates", чтобы получить представление о "популярности" избыточных индексов по сравнению с их содержащими конкурентами.
Также примите к сведению, что столбец "redundant_index_pages" указывает на текущий размер индекса. Поделите это числа на 128, чтобы получить эквивалентный размер в Мб (деление числа страниц на 128 эквивалентно умножению на 8 для получения значения в Кб, а затем деления на 1024, чтобы получить значение в Мб). Замечание. Во втором (суммарном) результирующем наборе redundant_index_mb уже вычислен для вас.
Столбец "DisableCmd" может использоваться для быстрого получения соответствующих команд ALTER INDEX .. DISABLE для выключения избыточных индексов. Вы можете также использовать столбец "DisableIfActiveCmd" для "идемпотентной" альтернативы (отключает индекс, только если он существует включен).
Столбец "DropCmd" может использоваться для быстрого получения соответствующих команд DROP INDEX для удаления избыточных индексов. Есть также идемпотентная альтернатива (удаляет индекс, только если он существует).
При желании можно изменить значение переменной @CompareIncludeColumnsToo в верхней части на 0, чтобы несколько изменить поведение скрипта:
ВАЖНОЕ ЗАМЕЧАНИЕ:
Прежде чем удалить или отключить индекс, вам следует убедиться, что на него не ссылается ХИНТ таблицы или запроса. В противном случае, при недоступности индекса такие запросы перестанут работать.
С этой целью вы можете использовать следующий скрипт:
Find index hints for a specific index.sql
Кроме того, независимо от того, используется ли индекс в силу явного хинта, или просто потому, что оптимизатор SQL выбрал его, все равно полезно знать, что имеются запросы, которые используют определенный индекс, прежде чем вы решите удалить его.
Используйте запрос ниже, чтобы обнаружить использование индекса в кэше планов SQL:
Аналогично запрос ниже может использоваться для обнаружения использования индекса в хранилище запросов (Query Store):
Заметим, что при ссылках в плане запроса XML имена таблиц и индексов должны быть заключены в квадратные скобки.
Отключение индексов перед их удалением может стать полезным способом избежать влияния запроса на прозводительность (как будто он больше не существует), сохраняя при этом его определение с возможностью легкого восстановления (включения).
Для повторного включения отключенного индекса вам нужно просто перестроть его (команда REBUILD).
После отключения индексов, когда вы готовы выполнить следующее действие, то можете использовать скрипт ниже для простой генерации команд DROP либо REBUILD для всех отключенных индексов:
Drop or rebuild all Disabled Indexes.sql
Удаление избыточных индексов в SQL Server может значительно улучшить производительность и эффективность вашей базы данных. Избыточные индексы могут занимать ценное пространство в хранилище, замедлять ваши запросы и команды модификации данных, а также увеличивать использование процессора. Обнаружив и удалив избыточные индексы, вы можете освободить пространство, уменьшить накладные расходы при выполнении запросов и гарантировать, что для каждого запроса используется оптимальный индекс. Помните, что не все избыточные индексы очевидны, поэтому важно регулярно следить за использованием ваших индексов и удалять те из них, которые больше не нужны. Выполняя эту работу, вы сможете гарантировать, что ваша база SQL Server функционирует на максимуме производительности и эффективности.
Ссылки по теме
1. Индексы: обнаружение неиспользуемых индексов
2. Фильтрованные индексы
3. Что такое "включенные столбцы" в некластеризованных индексах?
4. Типы индексов в SQL Server
5. Поиск в индексе (Index Seek)
6. Как думать подобно SQL Server: что означает поиск ключа?
Но вот чего не хватает в этих статьях, так это возможности легко генерировать команды Drop/Disable для этих избыточных индексов.
Кроме того, что если имеются "похожие" индексы, которые только "частично" избыточны, и, следовательно, недостаточно просто удалить один из них? Иначе это может негативно сказаться на производительности некоторых запросов.
Есть ли способ учесть все эти проблемы?
Каждый из них? Повсюду? Сразу?
Здесь я собираюсь показать вам, как обнаружить, получить подробную информацию и иметь возможность удалить КАЖДЫЙ избыточных индекс ЛЮБОЙ формы и размера:
- Полностью дублируемые индексы
- Избыточные индексы на основе ключевых столбцов + включенных столбцов
- Частично избыточные индексы только на основе ключевых столбцов
- Все таблицы
- Все таблицы с минимальным числом строк
- В конкретной базе данных
- Во всех доступных базах данных
Ссылка на скачивание скрипта приведена в конце статьи.
ВАЖНОЕ ЗАМЕЧАНИЕ:
Важно отметить, что вам следует удалять только действительно избыточные индексы. Перед удалением индекса следует убедиться, что он явно не используется какими-либо запросами или хранимыми процедурами в вашей базе данных посредством табличного хинта или хинта запроса.
Давайте поговорим о случаях использования
Есть несколько разных случаев использования, когда будут иметь место избыточные индексы.
Эти случаи использования будут отличаться друг от друга на основании различий или подобия нескольких свойств индекса:
- Ключевые столбцы
- Включенные столбцы
- Определение фильтрации
- Другие свойства (сжатие данных, опции блокировки индекса, коэффициент заполнения, файловая группа)
В разрезе этой статьи я буду предполагать следующее:
- Если два индекса имеют различные определения фильтра, они НЕ являются дубликатами или в чем-то избыточными относительно друг друга.
- Кластеризованные индексы никогда не считаются избыточными, даже если их ключевые столбцы "содержатся" внутри другого индекса.
- Первичные и уникальные ключи никогда не считаются избыточными, даже если их ключевые столбцы "содержатся" внутри другого индекса.
- Некоторые разнообразные свойства индекса игнорируются при этой проверке (сжатие данных, опции блокировки индекса, коэффициент заполнения, файловая группа).
С этим покончено, давайте начнем!
Полностью дублируемый индекс
Полностью дублируемым индексом считается такой, у которого идентичны все ключевые и все включенные столбцы.
Пример:
Пусть у нас имеется таблица с именем Products и следующими столбцами:
- ProductID (int, Primary Key)
- ProductName (nvarchar(50))
- CategoryID (int)
- Price (money)
И пусть мы создали два индекса на этой таблице:
Индекс 1:
CREATE NONCLUSTERED INDEX IX_Products_CategoryID
ON Products(CategoryID)
INCLUDE(ProductName, Price);Индекс 2:
CREATE NONCLUSTERED INDEX IX_Products_CategoryID_2
ON Products(CategoryID)
INCLUDE(ProductName, Price);Оба индекса имеют один и тот же ключевой столбец CategoryID и одинаковые включенные столбцы - ProductName и Price. Следовательно индекс 2 является полным дубликатом индекса 1.
Исправление:
В данном случае мы можем удалить индекс 2, поскольку он дублирует индекс 1 и не дает никаких дополнительных преимуществ. Удаление избыточного индекса может помочь улучшить производительность запросов и уменьшить использование места в хранилище.
Полностью покрывающий избыточный индекс
Полностью покрывающий индекс будет избыточным, если все его ключевые столбцы являются также первыми ключевыми столбцам другого индекса. Другой (содержащий) индекс может потенциально иметь дополнительные ключевые столбцы и/или может иметь больше включенных столбцов, помимо столбцов в избыточном индексе.
Важно, что содержащий индекс имеет все, что есть в избыточном индексе, и, возможно, что-то дополнительно.
Пример:
Пусть у нас имеется таблица Orders со следующими столбцами:
- OrderID (int, Primary Key)
- OrderDate (datetime)
- CustomerID (int)
- EmployeeID (int)
- ProductID (int)
- Quantity (int)
- TotalPrice (money)
И пусть мы создали два следующих индекса на этой таблице:
Индекс 1:
CREATE NONCLUSTERED INDEX IX_Orders_CustomerID
ON Orders(CustomerID)
INCLUDE(OrderDate, TotalPrice);Индекс 2:
CREATE NONCLUSTERED INDEX IX_Orders_CustomerID_EmployeeID
ON Orders(CustomerID, EmployeeID)
INCLUDE(OrderDate, ProductID, Quantity, TotalPrice);В этом случае индекс 2 включает все столбцы в индексе 1 и содержит дополнительный ключевой столбец EmployeeID. Кроме того, индекс 2 содержит дополнительные включенные столбцы ProductID и Quantity. Следовательно, индекс 2 является более объемлющим, чем индекс 1, и покрывает все запросы, которые покрывает индекс 1, плюс дополнительные запросы. Индекс 1 является избыточным в данном сценарии, поскольку он не дает дополнительного преимущества.
Исправление:
Мы можем удалить индекс 1 без влияния на производительность любых запросов.
Частично избыточные индексы
Частично избыточный индекс - это индекс, у которого ключевые столбцы являются также первыми ключевыми столбцами другого индекса. Но включенные столбцы могут полностью различаться. Это означает, что содержащий индекс способен выполнять ту же операцию поиска (seek), что и избыточный индекс, но может потребоваться добавить в него несколько включенных столбцов, чтобы полностью обеспечить аналогичную функциональность. В противном случае, индекс либо не будет использоваться, либо потребуется дополнительная операция поиска ключа (key lookup).
Пример:
Пусть у нас есть таблица Customers со следующим столбцами:
- CustomerID (int, Primary Key)
- FirstName (nvarchar(50))
- LastName (nvarchar(50))
- City (nvarchar(50))
- State (nvarchar(50))
- ZipCode (nvarchar(10))
- Email (nvarchar(100))
- Phone (nvarchar(20))
И пусть мы создали следующую пару индексов на этой таблице:
Индекс 1:
CREATE NONCLUSTERED INDEX IX_Customers_City_State_ZipCode
ON Customers(City, State, ZipCode)
INCLUDE(FirstName, LastName);Индекс 2:
CREATE NONCLUSTERED INDEX IX_Customers_City
ON Customers(City)
INCLUDE(FirstName, LastName, Email, Phone);В этом случае индекс 2 содержит ключевой столбец City, который также является первым ключевым столбцом в индексе 1. Однако индекс 2 имеет дополнительные включенные столбцы Email и Phone, которые не включены в индекс 1.
Хотя индекс 2 покрывает некоторые дополнительные запросы, которые не покрывает индекс 1, он является частично избыточным, поскольку ключевой столбец City уже покрывается индексом 1. Это означает, что индекс 1 уже может выполнять те же операции поиска, что и индекс 2, при условии, что запросы выполняют фильтрацию только по столбцу City.
Исправления:
Чтобы полностью обеспечить функциональность индекса 2, мы должны дополнительно добавить в индекс 1 включенные столбцы Email и Phone. Это устранит необходимость в избыточном индексе 2 и будет гарантировать оптимальное использование индекса для запросов, которые выполняют фильтрацию по столбцу City.
Обновленный синтаксис для индекса 1:
CREATE NONCLUSTERED INDEX IX_Customers_City_State_ZipCode
ON Customers(City, State, ZipCode)
INCLUDE(FirstName, LastName, Email, Phone);Удаляя избыточный индекс и обновляя содержащий индекс дополнительными включенными столбцами, мы можем уменьшить использование пространства хранилища и сделать базу данных более эффективной.
ПРЕДУПРЕЖДЕНИЕ:
Иногда при попытке создать "все покрывающий" индекс для замены всех его избыточных/частично-избыточных индексов вы рискуете создать "широкие" индексы, которые имеют очень длинный ключ или списки включенных столбцов.
Хотя это все еще "выгодно" с точки зрения использования пространства хранилища сравнительно с присутствием избыточных индексов, имеется риск падения производительности. Это обусловлено тем, что чем больше столбцов находится в индексе, тем больше данных требуется сканировать, читать и парсить во время операций поиска или сканирования индекса.
Поэтому будьте осторожны, чтобы не получить огромные списки столбцов в ваших индексах, иначе вы можете ухудшить производительность некоторых запросов.
Похоже, что тут много работы
Вы правы, работы много. Но, к счастью, возможно "автоматизировать" ее большую часть, написав скрипт T-SQL!
Используйте этот скрипт из нашего Madeira Toolbox:
Redundant Indexes Detailed - All Databases.sql
По умолчанию этот скрипт возвращает два различных результирующих набора.
Первый - это "подробный" результирующий набор, показывающий все избыточные индексы и индексы, которые их "содержат". Он имеет множество полезных деталей, но, возможно, будет включать дублирующуюся информацию (если тот же самый индекс "содержится" более чем в одном индексе).
Второй результирующий набор является "сводным", он показывает только избыточные индексы, и каждый избыточный индекс показан только один раз. Информация не дублируется, но некоторые детали опущены (которые можно найти в первом результирующем наборе). Вы можете использовать этот второй набор как единственный источник информации об избыточных индексах, которые должны быть удалены/отключены.
Обратите внимание на столбцы "*_index_seeks", "*_index_scans" и "*_index_updates", чтобы получить представление о "популярности" избыточных индексов по сравнению с их содержащими конкурентами.
Также примите к сведению, что столбец "redundant_index_pages" указывает на текущий размер индекса. Поделите это числа на 128, чтобы получить эквивалентный размер в Мб (деление числа страниц на 128 эквивалентно умножению на 8 для получения значения в Кб, а затем деления на 1024, чтобы получить значение в Мб). Замечание. Во втором (суммарном) результирующем наборе redundant_index_mb уже вычислен для вас.
Столбец "DisableCmd" может использоваться для быстрого получения соответствующих команд ALTER INDEX .. DISABLE для выключения избыточных индексов. Вы можете также использовать столбец "DisableIfActiveCmd" для "идемпотентной" альтернативы (отключает индекс, только если он существует включен).
Столбец "DropCmd" может использоваться для быстрого получения соответствующих команд DROP INDEX для удаления избыточных индексов. Есть также идемпотентная альтернатива (удаляет индекс, только если он существует).
При желании можно изменить значение переменной @CompareIncludeColumnsToo в верхней части на 0, чтобы несколько изменить поведение скрипта:
- Вместо обнаружения избыточных индексов путем сравнения как ключевых столбцов, так и включенных, скрипт будет сравнивать только ключевые столбцы. Вероятно, это вернет даже больше "избыточных" индексов, но вам следует быть осторожным, т.к. эти индексы не обязательно "полностью" избыточные.
- Будет выводиться 3-й результирующий набор именно для этой цели.
- Он содержит столбец "ExpandIndexCommand", который будет содержать команды CREATE INDEX для "полностью покрывающих индексов", чтобы заместить все избыточные индексы на базе ключевых столбцов. Другими словами, это предполагает индекс с большинством ключевых столбцов, и добавлением в него всех включенных столбцов из всех избыточных конкурентов.
- Этот 3-й результирующий набор также содержит два дополнительных столбца "DisableRedundantIndexes" и "DropRedundantIndexes", которые могут использоваться, чтобы легче было избавиться от всех избыточных индексов, которые могут быть заменены новым покрывающим индексом.
ВАЖНОЕ ЗАМЕЧАНИЕ:
Прежде чем удалить или отключить индекс, вам следует убедиться, что на него не ссылается ХИНТ таблицы или запроса. В противном случае, при недоступности индекса такие запросы перестанут работать.
С этой целью вы можете использовать следующий скрипт:
Find index hints for a specific index.sql
Кроме того, независимо от того, используется ли индекс в силу явного хинта, или просто потому, что оптимизатор SQL выбрал его, все равно полезно знать, что имеются запросы, которые используют определенный индекс, прежде чем вы решите удалить его.
Используйте запрос ниже, чтобы обнаружить использование индекса в кэше планов SQL:
DECLARE
@IndexName sysname = 'UQ_CountryCodes'
,@TableName sysname = 'CountryCodes'
DECLARE
@IndexNameWithBrackets sysname = QUOTENAME(@IndexName)
,@TableNameWithBrackets sysname = QUOTENAME(@TableName)
;WITH XMLNAMESPACES (DEFAULT N'http://schemas.microsoft.com/sqlserver/2004/07/showplan', N'http://schemas.microsoft.com/sqlserver/2004/07/showplan' AS p)
SELECT
cp.objtype,
cp.usecounts,
st.text,
qp.query_plan
FROM sys.dm_exec_cached_plans cp
CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) AS st
CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) AS qp
WHERE st.text LIKE '%' + @TableName + '%'
AND qp.query_plan.exist('//Object[@Index=sql:variable("@IndexNameWithBrackets") and @Table=sql:variable("@TableNameWithBrackets")]') = 1Аналогично запрос ниже может использоваться для обнаружения использования индекса в хранилище запросов (Query Store):
DECLARE
@IndexName sysname = 'UQ_CountryCodes'
,@TableName sysname = 'CountryCodes'
DECLARE
@IndexNameWithBrackets sysname = QUOTENAME(@IndexName)
,@TableNameWithBrackets sysname = QUOTENAME(@TableName)
;WITH XMLNAMESPACES (DEFAULT N'http://schemas.microsoft.com/sqlserver/2004/07/showplan', N'http://schemas.microsoft.com/sqlserver/2004/07/showplan' AS p)
SELECT
q.query_id,
q.query_text_id,
qt.query_sql_text,
qp.query_plan_xml
FROM sys.query_store_query AS q
INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id
INNER JOIN sys.query_store_query_text AS qt ON q.query_text_id = qt.query_text_id
OUTER APPLY (SELECT CAST(p.query_plan AS XML) AS query_plan_xml) AS qp
WHERE qt.query_sql_text LIKE '%' + @TableName + '%'
AND qp.query_plan_xml.exist('//Object[@Index=sql:variable("@IndexNameWithBrackets") and @Table=sql:variable("@TableNameWithBrackets")]') = 1Заметим, что при ссылках в плане запроса XML имена таблиц и индексов должны быть заключены в квадратные скобки.
Дополнительное предупреждение
Отключение индексов перед их удалением может стать полезным способом избежать влияния запроса на прозводительность (как будто он больше не существует), сохраняя при этом его определение с возможностью легкого восстановления (включения).
Для повторного включения отключенного индекса вам нужно просто перестроть его (команда REBUILD).
После отключения индексов, когда вы готовы выполнить следующее действие, то можете использовать скрипт ниже для простой генерации команд DROP либо REBUILD для всех отключенных индексов:
Drop or rebuild all Disabled Indexes.sql
Заключение
Удаление избыточных индексов в SQL Server может значительно улучшить производительность и эффективность вашей базы данных. Избыточные индексы могут занимать ценное пространство в хранилище, замедлять ваши запросы и команды модификации данных, а также увеличивать использование процессора. Обнаружив и удалив избыточные индексы, вы можете освободить пространство, уменьшить накладные расходы при выполнении запросов и гарантировать, что для каждого запроса используется оптимальный индекс. Помните, что не все избыточные индексы очевидны, поэтому важно регулярно следить за использованием ваших индексов и удалять те из них, которые больше не нужны. Выполняя эту работу, вы сможете гарантировать, что ваша база SQL Server функционирует на максимуме производительности и эффективности.
Ссылки по теме
1. Индексы: обнаружение неиспользуемых индексов
2. Фильтрованные индексы
3. Что такое "включенные столбцы" в некластеризованных индексах?
4. Типы индексов в SQL Server
5. Поиск в индексе (Index Seek)
6. Как думать подобно SQL Server: что означает поиск ключа?
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой