
Получение TOP(N) строк с помощью APPLY или ROW_NUMBER() в SQL Server
Пересказ статьи Jared Westover. Return TOP (N) Rows using APPLY or ROW_NUMBER() in SQL Server
По большей части, существует много способов сделать одну и ту же вещь. Например, если вам нужно вернуть заданное число строк из табличнозначной функции или табличного выражения. Обычно для выполнения этой задачи разработчики применяют метод, основанный на операторе APPLY. Но является ли APPLY лучшим методом для получения результатов? Как узнать, какой метод выбрать? И что делает один метод лучше другого?
Здесь мы сравним два метода для достижения одних и тех же результатов. Сначала я детально рассмотрю оператор APPLY в случаях, когда он обычно используется. Вы знаете, что он существует в двух вариантах? Затем мы сравним APPLY с ROW_NUMBER() для получения TOP(n) строк из табличного выражения. Я расскажу о критериях, используемых для измерения производительности. Как вы думаете, кто из них победит при сравнении? К концу статьи вы будете знать, какой метод выбрать для вашего следующего проекта.
Применение APPLY
Microsoft ввела оператор APPLY в SQL Server 2005. В статье Arshad Ali APPLY описывается как предложение соединения: "Оно позволяет соединить два табличных выражения, т.е. соединить левое/внешнее табличное выражение с правым/внутренним табличным выражением." Поскольку обе таблицы могут технически быть выражениями, далее в статье, чтобы избежать путаницы, я буду называть первую/левую таблицу таблицей, а вторую табличным выражением.
Другим полезным применением APPLY является сочетание с функцией OPENJSON. Вы можете преобразовать данные JSON в реляционный формат. Andrew Villazon написал исчерпывающую статью на эту тему.
Оператор APPLY имеет две формы. Первой является CROSS APPLY, которую не следует путать с соединением, выполняющим декартово произведение. Вторая называется OUTER APPLY.
CROSS APPLY
Полезно думать о CROSS APPLY как о INNER JOIN — оно возвращает только те строк из первой таблицы, которые существуют во втором табличном выражении. Вы можете иногда относиться к этому как к фильтрующему или ограничивающему типу, поскольку вы фильтруете строки из первой таблицы на основе того, что возвращается из второй.
SELECT ft.ColumnName,
st.Amount
FROM dbo.FirstTable ft
CROSS APPLY
(
SELECT st.Amount
FROM dbo.SecondTable st
WHERE st.FirstTableId = ft.Id
) st;OUTER APPLY
С другой стороны, OUTER APPLY подобен OUTER JOIN. Он возвращает все строк из первой таблицы и совпадающие строки из второй. Вы слышали, что это называется производством NULL. Если строка не существует в табличном выражении, она будет заполнена NULL.
SELECT ft.ColumnName,
st.Amount
FROM dbo.FirstTable ft
OUTER APPLY
(
SELECT st.Amount
FROM dbo.SecondTable st
WHERE st.FirstTableId = ft.Id
) st;Возвращение TOP(n) строк
Типичный запрос, когда используется APPLY, это возвращение TOP(n) строк из второго результирующего набора. Теперь здесь может быть либо CROSS or OUTER. Это зависит от того, что вам нужно. Синтаксис для решения этой задачи может выглядеть следующим образом:
SELECT ft.ColumnName,
st.Amount
FROM dbo.FirstTable ft
CROSS APPLY
(
SELECT TOP(2) st.Amount
FROM dbo.SecondTable st
WHERE st.FirstTableId = ft.Id
ORDER BY st.Amount DESC
) st;Предложение ORDER BY указывает порядок, в котором ранжируются строки. В примере выше, если вы захотите включить две строки с максимальными значениями, то можете использовать ключевое слово DESC/DESCENDING.
Второй метод для получения TOP(n) строк - это использование ROW_NUMBER(). Синтаксис на примере, как это должно работать, показан ниже.
;WITH cte_HighestSales
AS (
SELECT ROW_NUMBER() OVER (PARTITION BY FirstTableId ORDER BY Amount DESC) AS RowNumber,
Amount,
FirstTableId
FROM dbo.SecondTable
)
SELECT ft.ColumnName,
st.Amount
FROM dbo.FirstTable ft
INNER JOIN cte_HighestSales st
ON st.FirstTableId = ft.Id
AND st.RowNumber < 3;Какой из способов использовать на практике? Чтобы ответить на этот вопрос, нам нужно построить набор данных и сравнить производительность этих двух методов.
Построение тестового набора данных
Код ниже создает две таблицы. Первая таблица меньше и действует, скорее, как измерение. Вторая таблица содержит большую часть строк.
USE [master];
GO
IF DATABASEPROPERTYEX( 'PizzaTracker',
'Version'
) IS NOT NULL
BEGIN
ALTER DATABASE PizzaTracker SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE PizzaTracker;
END;
GO
CREATE DATABASE PizzaTracker;
GO
ALTER DATABASE PizzaTracker SET RECOVERY SIMPLE;
GO
USE PizzaTracker;
GO
CREATE TABLE dbo.MutantFighters
(
Id INT PRIMARY KEY,
[Name] VARCHAR(50) NOT NULL,
Species VARCHAR(50) NOT NULL
);
INSERT INTO dbo.MutantFighters
(
Id,
Name,
Species
)
VALUES
(1, 'Leonardo', 'Turtle'),
(2, 'Michelangelo', 'Turtle'),
(3, 'Donatello', 'Turtle'),
(4, 'Raphael', 'Turtle'),
(5, 'Splinter', 'Rat'),
(6, 'Bebop', 'Warthog'),
(7, 'Rocksteady', 'Rhino');
CREATE TABLE dbo.PizzaLog
(
Id INT IDENTITY(1, 1) NOT NULL,
MutantId INT NOT NULL,
Slices INT NOT NULL,
DateEaten DATE NOT NULL
);
-- Генерация данных за февраль.
DECLARE @StartDate DATE = '2023-02-01';
DECLARE @EndDate DATE = '2023-02-28';
WITH Dates
AS (
SELECT @StartDate AS Date
UNION ALL
SELECT DATEADD( DAY,
1,
Date
) AS Date
FROM Dates
WHERE Date < @EndDate
)
INSERT INTO dbo.PizzaLog
(
MutantId,
Slices,
DateEaten
)
SELECT mf.Id,
CASE
WHEN mf.Id = 2 THEN
ABS(CHECKSUM(NEWID()) % 15) + 3 -- Майки ест больше всего пиццы
ELSE
ABS(CHECKSUM(NEWID()) % 10) + 1
END AS Slices,
d.Date
FROM dbo.MutantFighters mf
CROSS JOIN Dates d
WHERE mf.id <> 5;
GOРезультаты сравнения
В запросе ниже я хочу получить три дня за которые каждый персонаж съел больше всего кусочков пиццы. Я начну с CROSS APPLY и INNER JOIN для ROW_NUMBER(). Я также включу фактический план выполнения и STATISTICS IO. Мы будем сравнивать число логических чтений и стоимость плана. Стоимость плана не является точной наукой, но он дает некоторое приближение.
SET STATISTICS IO ON;
SELECT mf.[Name],
pl.DateEaten,
pl.Slices
FROM dbo.MutantFighters mf
CROSS APPLY
(
SELECT TOP (3)
DateEaten,
Slices
FROM dbo.PizzaLog pl
WHERE pl.MutantId = mf.Id
ORDER BY Slices DESC, DateEaten ASC
) pl;
SET STATISTICS IO OFF;
SET STATISTICS IO ON;
;WITH cte_pl AS (
SELECT ROW_NUMBER() OVER(PARTITION BY MutantId ORDER BY Slices DESC, DateEaten ASC) AS RowNumber,
MutantId,
Slices,
DateEaten
FROM dbo.PizzaLog
)
SELECT mf.[Name],
cte_pl.DateEaten,
cte_pl.Slices
FROM dbo.MutantFighters mf
INNER JOIN cte_pl ON cte_pl.MutantId = mf.Id
WHERE cte_pl.RowNumber < 4
SET STATISTICS IO OFF;

Результаты показывают, что CROSS APPLY выполнял 7 логических чтений, в то время как ROW_NUMBER() только 3. Когда запросы выполняются в одном пакете, доля CROSS APPLY составляет 78% стоимости.
Давайте применим OUTER APPLY и LEFT JOIN для второго теста. Здесь меня также интересуют лица, которые вообще не ели пиццы.
SET STATISTICS IO ON;
SELECT mf.[Name],
pl.DateEaten,
pl.Slices
FROM dbo.MutantFighters mf
OUTER APPLY
(
SELECT TOP (3)
DateEaten,
Slices
FROM dbo.PizzaLog pl
WHERE pl.MutantId = mf.Id
ORDER BY Slices DESC, DateEaten ASC
) pl;
SET STATISTICS IO OFF;
SET STATISTICS IO ON;
;WITH cte_pl AS (
SELECT ROW_NUMBER() OVER(PARTITION BY MutantId ORDER BY Slices DESC, DateEaten ASC) AS RowNumber,
MutantId,
Slices,
DateEaten
FROM dbo.PizzaLog
)
SELECT mf.[Name],
cte_pl.DateEaten,
cte_pl.Slices
FROM dbo.MutantFighters mf
LEFT JOIN cte_pl ON cte_pl.MutantId = mf.Id AND cte_pl.RowNumber < 4
SET STATISTICS IO OFF;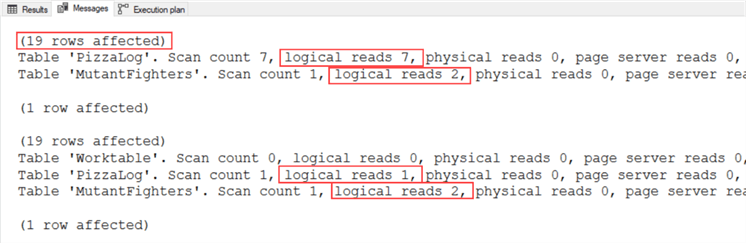
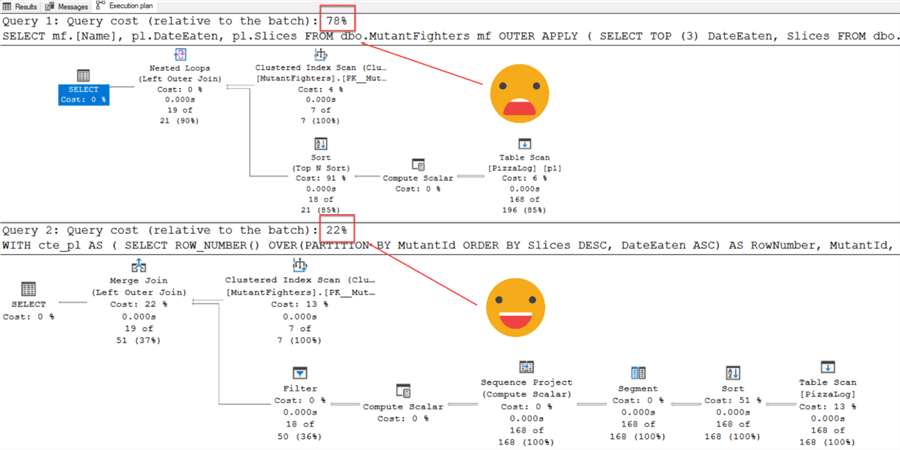
Как можно увидеть на скриншотах, результаты почти идентичны. Замечу, что я получил лишнюю строку для учета Сплинтера. Если сравнивать логические чтения и стоимость пакета, легко побеждает ROW_NUMBER(). С меньшим результирующим набором я бы не стал мучиться с выбором, какой метод использовать. Однако, если вы используете большие таблицы, возможно, стоит пересмотреть ваш подход.
Основные выводы
- Вы можете использовать оконную функцию ROW_NUMBER() и оператор APPLY для получения заданного числа строк из табличного выражения.
- APPLY имеет две формы - CROSS и OUTER. CROSS можно понимать как INNER JOIN, OUTER - как LEFT JOIN.
- Это во многом будет зависеть от ваших предпочтений, но мои симпатии находятся на стороне ROW_NUMBER().
- При больших наборах данных, т.е. миллионы строк, я считаю, что ROW_NUMBER() может дать заметный выигрыш в производительности.
Ссылки по теме
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой