
Решение проблем производительности при использовании UDF в SQL Server
Пересказ статьи Eric Blinn. Performance Problems and Solutions when using User Defined Functions in SQL Server
Может ли определяемая пользователем функция (UDF) являться причиной проблем с производительностью в SQL Server? Как это выяснить? Если это может быть частью проблемы, то что тут можно сделать?
UDF могут быть очень привлекательны для новых разработчиков T-SQL, особенно для тех, кто пришел с опытом в более традиционных процедурных языках программирования. Эти функции позволяют обеспечить более высокую степень повторного использования кода и могут упростить его читабельность. К сожалению, SQL Server использует теоретико-множественную парадигму программирования и зачастую не так хорош при выполнении UDF. Что хуже, многие традиционные методы настройки производительности не точно оценивают влияние UDF на запросы. Здесь мы будем изучать эту проблему и способы ее обхода.
Все демонстрационные примеры будут выполняться с использованием SQL Server Management Studio (SSMS) на экземпляре SQL Server 2019. Целевой базой данных является WideWorldImporters, доступная для скачивания на GitHub.
Для начала нужно установить базовый уровень ожидаемой производительности. Затем мы привлечем UDF, чтобы посмотреть на реакцию SQL Server. Рассмотрим простой запрос:
Воспользуемся традиционными методами настройки производительности, включающими статистику ввода-вывода, времени выполнения и фактический план выполнения, возвращающий эту статистику. Если это внове для вас, обратитесь к статьям: Погружение в SET STATISTICS IO ON для SQL Server, Введение в план выполнения SQL Server и Планы выполнения, на что следует обращать внимание?.
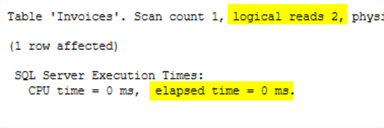

Запросу потребовалось прочитать только две страницы при одной операции поиска в индексе. Он выполнился быстрей 1 миллисекунды. Такой результат может получиться при настройке запроса.
Теперь рассмотрим такой запрос:
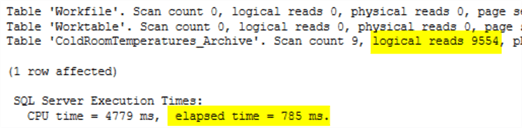
Этот запрос выполняется на много большей таблице и сообщает о необходимости более 9000 чтений. Он занимает около 750 мс.
План выполнения значительно более сложный, чем план предыдущего запроса.

Наконец, плохой запрос будет обернут в UDF. Тип данных для сенсора (sensor) был выбран неверно, чтобы сделать UDF как можно хуже.
Пришло время объединить первый демонстрационный запрос, который выполняется менее 1 мс, с UDF второго запроса, который занимает 750 мс.
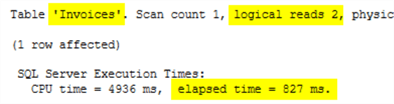
Этот запрос будет считывать данные из обеих таблиц, Invoices и ColdRoomTemperatures_Archive, но почему-то статистика по вводу-выводу (io) упоминает только таблицу Invoices. Время выполнения выглядит более точным.
План выполнения никак не помогает. Он показывает только поиск, связанный с таблицей Invoices.
Как настраивать запрос, который выполняет только два чтения в рамках единственной операции поиска в индексе, но выполняется почти за 1 секунду? Мы знаем, что другая таблица участвует в этом примере, но это не всегда будет известно при просмотре существующего кода в реальном сценарии. Представьте себе сценарий, в котором запрос содержит сотни строк кода. План длинный и сложный. Если проблема действительно заключается в вызовах одной из нескольких UDF, будет невероятно сложно диагностировать ключевую проблему производительности, без визуализации выполнения этих UDF.
Первое, куда нужно заглянуть за информацией о выполнении UDF, это предварительный (estimated) план выполнения. Ранее в демонстрационном примере был использован фактический (actual) план выполнения. Эта функция активируется другой кнопкой или комбинацией клавиш. На этом скриншоте показана кнопка и комбинация клавиш, требуемая для получения предварительного плана.
В отличие от фактического плана выполнения, этот план появляется почти мгновенно. Это потому, что сначала выполняется не запрос, а потом план; просто генерируется и отображается план. Запрос не выполняется при этой операции. Это также полезно в тех сценариях, когда нужно получить план, но запрос не может быть выполнен. Это может быть связано с настройкой операторов insert, update или delete, или когда ожидается слишком долгое выполнение запроса, и разработчик не хочет ждать, когда запрос выполнится, чтобы посмотреть его план.
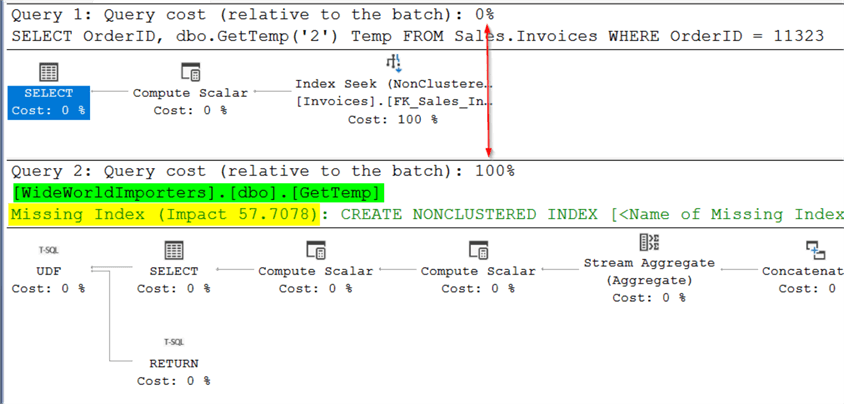
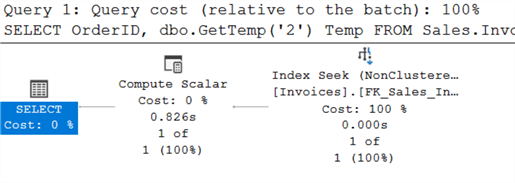
В то время как фактический план выполнения выбрасывает информацию, относящуюся к UDF, предварительный план ее включает! Сама UDF упомянута по имени (выделено зеленым на плане). Сразу становится очевидным, что проблемы производительности связаны с UDF. Процентное соотношение на концах красной линии делает это очевидным. Выводится даже предложение по улучшению производительности UDF, которое выделено желтым цветом.
Другой способ получить подробную информацию о производительности, связанную с UDF в запросе SQL, - это использовать Live Query Statistics. Как и в случае с кнопкой фактического плана выполнения, для просмотра этой информации функция должна быть включена в окне запроса до выполнения самого запроса. Кнопка включения Live Query Statistics показана на скриншоте ниже.
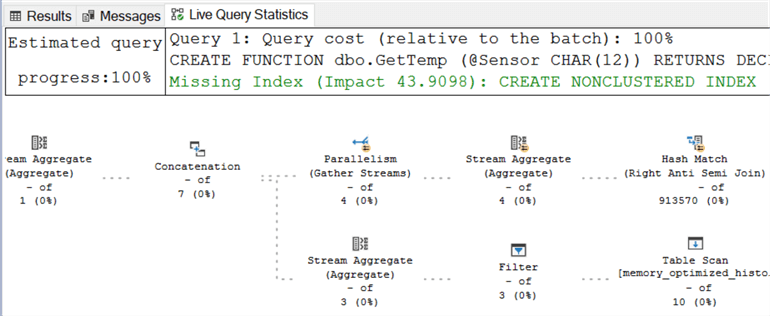
И опять выполнение запроса с включенной этой функцией открывает новую вкладку в SSMS, на которой показан план выполнения запроса. Этот запрос завершился быстрее 1 секунды, но если выполнение запроса занимает длительное время, данные можно наблюдать в движении в реальном времени. Как и в случае запуска предварительного плана выполнения, вывод включает информацию о UDF.
SQL Server зачастую работает лучше, если UDF не является частью запросов. Удерживайтесь от соблазна добавить их в базу данных. Вместо них по мере возможности используйте общие табличные выражения, подзапросы или представления. Хотя и с меньшим повторным использованием кода, операции на базе множеств почти всегда будут работать лучше, чем их аналоги UDF.
Если нет способа обойти использование UDF, вы хотя бы знаете, как найти медленные функции, а значит их можно настроить.
Ссылки по теме
1. Изучение плана запроса в SQL
2. Поиск в индексе (Index Seek)
3. Встраивание скалярных UDF (SQL Server 2019)
Создаем базовый уровень для сравнения
Для начала нужно установить базовый уровень ожидаемой производительности. Затем мы привлечем UDF, чтобы посмотреть на реакцию SQL Server. Рассмотрим простой запрос:
SELECT OrderID FROM Sales.Invoices WHERE OrderID = 11323;Воспользуемся традиционными методами настройки производительности, включающими статистику ввода-вывода, времени выполнения и фактический план выполнения, возвращающий эту статистику. Если это внове для вас, обратитесь к статьям: Погружение в SET STATISTICS IO ON для SQL Server, Введение в план выполнения SQL Server и Планы выполнения, на что следует обращать внимание?.
Запросу потребовалось прочитать только две страницы при одной операции поиска в индексе. Он выполнился быстрей 1 миллисекунды. Такой результат может получиться при настройке запроса.
Теперь рассмотрим такой запрос:
SELECT MSSQLTIPS = AVG(Temperature)
FROM Warehouse.ColdRoomTemperatures_Archive
WHERE ColdRoomSensorNumber = 2;Этот запрос выполняется на много большей таблице и сообщает о необходимости более 9000 чтений. Он занимает около 750 мс.
План выполнения значительно более сложный, чем план предыдущего запроса.
Наконец, плохой запрос будет обернут в UDF. Тип данных для сенсора (sensor) был выбран неверно, чтобы сделать UDF как можно хуже.
CREATE FUNCTION dbo.GetTemp (@Sensor CHAR(12)) RETURNS DECIMAL(10,2)
AS
BEGIN
DECLARE @MSSQLTIPS DECIMAL(10,2);
SELECT @MSSQLTIPS = AVG(Temperature)
FROM Warehouse.ColdRoomTemperatures_Archive
WHERE ColdRoomSensorNumber = @Sensor;
RETURN @MSSQLTIPS;
END; Отсутствующая информация в плане запроса не помогает в его настройке
Пришло время объединить первый демонстрационный запрос, который выполняется менее 1 мс, с UDF второго запроса, который занимает 750 мс.
SELECT OrderID, dbo.GetTemp('2') Temp FROM Sales.Invoices WHERE OrderID = 11323;Этот запрос будет считывать данные из обеих таблиц, Invoices и ColdRoomTemperatures_Archive, но почему-то статистика по вводу-выводу (io) упоминает только таблицу Invoices. Время выполнения выглядит более точным.
План выполнения никак не помогает. Он показывает только поиск, связанный с таблицей Invoices.
Как настраивать запрос, который выполняет только два чтения в рамках единственной операции поиска в индексе, но выполняется почти за 1 секунду? Мы знаем, что другая таблица участвует в этом примере, но это не всегда будет известно при просмотре существующего кода в реальном сценарии. Представьте себе сценарий, в котором запрос содержит сотни строк кода. План длинный и сложный. Если проблема действительно заключается в вызовах одной из нескольких UDF, будет невероятно сложно диагностировать ключевую проблему производительности, без визуализации выполнения этих UDF.
Обнаружение скрытой стоимости запроса в плане запроса, использующего UDF
Первое, куда нужно заглянуть за информацией о выполнении UDF, это предварительный (estimated) план выполнения. Ранее в демонстрационном примере был использован фактический (actual) план выполнения. Эта функция активируется другой кнопкой или комбинацией клавиш. На этом скриншоте показана кнопка и комбинация клавиш, требуемая для получения предварительного плана.
В отличие от фактического плана выполнения, этот план появляется почти мгновенно. Это потому, что сначала выполняется не запрос, а потом план; просто генерируется и отображается план. Запрос не выполняется при этой операции. Это также полезно в тех сценариях, когда нужно получить план, но запрос не может быть выполнен. Это может быть связано с настройкой операторов insert, update или delete, или когда ожидается слишком долгое выполнение запроса, и разработчик не хочет ждать, когда запрос выполнится, чтобы посмотреть его план.
В то время как фактический план выполнения выбрасывает информацию, относящуюся к UDF, предварительный план ее включает! Сама UDF упомянута по имени (выделено зеленым на плане). Сразу становится очевидным, что проблемы производительности связаны с UDF. Процентное соотношение на концах красной линии делает это очевидным. Выводится даже предложение по улучшению производительности UDF, которое выделено желтым цветом.
Нахождение скрытой стоимости запроса UDF с помощью статистики запросов в реальном времени (Live Query Statistics)
Другой способ получить подробную информацию о производительности, связанную с UDF в запросе SQL, - это использовать Live Query Statistics. Как и в случае с кнопкой фактического плана выполнения, для просмотра этой информации функция должна быть включена в окне запроса до выполнения самого запроса. Кнопка включения Live Query Statistics показана на скриншоте ниже.
И опять выполнение запроса с включенной этой функцией открывает новую вкладку в SSMS, на которой показан план выполнения запроса. Этот запрос завершился быстрее 1 секунды, но если выполнение запроса занимает длительное время, данные можно наблюдать в движении в реальном времени. Как и в случае запуска предварительного плана выполнения, вывод включает информацию о UDF.
Финальные мысли
SQL Server зачастую работает лучше, если UDF не является частью запросов. Удерживайтесь от соблазна добавить их в базу данных. Вместо них по мере возможности используйте общие табличные выражения, подзапросы или представления. Хотя и с меньшим повторным использованием кода, операции на базе множеств почти всегда будут работать лучше, чем их аналоги UDF.
Если нет способа обойти использование UDF, вы хотя бы знаете, как найти медленные функции, а значит их можно настроить.
Ссылки по теме
1. Изучение плана запроса в SQL
2. Поиск в индексе (Index Seek)
3. Встраивание скалярных UDF (SQL Server 2019)
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой