
Покрывающие индексы SQL Server с ключевыми и неключевыми столбцами для повышения производительности
Пересказ статьи Jared Westover. SQL Server Indexes with Key and Non-Key Columns as Covering Indexes to improve Performance
Когда я начинал создавать индексы в SQL Server, я добавлял столбцы только в ключ. Даже если зеленая полезная подсказка предлагала обратное. Это было так давно, что я уже не помню, где я впервые прочитал о размещении столбцов во включенной или неключевой части. Однако как-то я приспособился. Почему вы должны размещать столбцы в ключе, а не в ключевой области при создании индекса? Имеет ли это значение? Вот несколько вопросов, которые мы исследуем вместе с вами.
В этом руководстве я начну с определения понятия покрывающего индекса в SQL Server. Затем мы рассмотрим, как SQL Server хранит неключевые столбцы в структуре индекса. Мы узнаем о двух главных преимуществах добавления столбцов во включенную часть индекса. Это не все преимущества, но с этими двумя имеют дело наиболее часто. К концу руководства вы сможете уже сейчас начать создавать лучшие индексы.
Покрывающий индекс в SQL Server
Начнем с ответа на вопрос - что такое покрывающий индекс? Говоря просто, это индекс, который включает каждый столбец конкретного запроса. Иногда можно услышать о покрытии запроса. Например, возьмем такой простой запрос:
SELECT Column1, Column2
FROM Table1
WHERE Column1 = 'Some value';Если вы хотите покрыть запрос, ниже один из индексов, который это выполняет.
CREATE NONCLUSTERED INDEX [IX_Column1_Column2]
ON Table1 (
Column1,
Column2
);Индекс может также покрывать и другие запросы, но мы этого не знаем. Это говорит о другой концепции настройки базы данных или сервера, где вы не рассматриваете один изолированный запрос; однако это выходит за рамки данной статьи. Сейчас мы фокусируемся на единственном запросе.
Что может случиться, если в примере выше мы исключим Column2 из области ключа индекса? Вероятно, SQL должен будет выполнить поиски ключа или RID, чтобы вытащить его из базовой таблицы. Выигрыш при избегании поиска является одной из главных причин для покрытия запроса. Я не говорю о том, что вы никогда не захотите видеть поиск (lookups) в плане вашего запроса. Чтобы полностью этого избежать, вам пришлось бы создать не одну дюжину индексов на одну таблицу в нагруженной производственной среде. Поскольку индексы занимают место и требуют обслуживания, создание индекса для каждого столбца не очень хорошая идея.
Структура индекса в SQL Server
Ниже показана иллюстрация структуры индекса. Вы, вероятно, видели нечто подобное неоднократно. Для простоты я предполагаю наличие только трех уровней. Корневой узел, где SQL хранит ключ индекса. Промежуточный уровень содержит указатели на следующий уровень. Наконец, листовой уровень или страницы фактических данных находятся на нижнем уровне дерева.
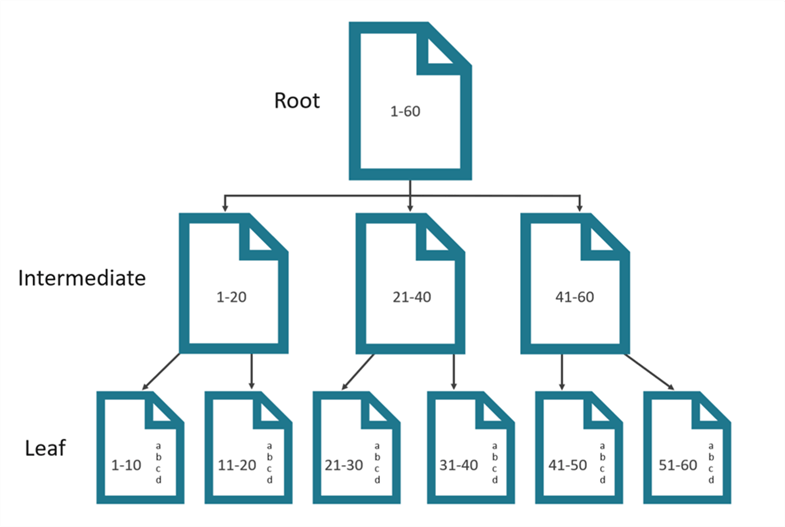
Этого достаточно для базового понимания структуры индекса, чтобы двигаться дальше.
Столбцы ключа индекса
Что следует помещать в ключ индекса? Для большей ясности я буду рассматривать некластеризованные индексы. Я рекомендую столбцы, используемые в предложениях JOIN и WHERE. Если ваш запрос имеет предложения ORDER BY или GROUP BY, они также могут служить кандидатами. Упомянутые столбцы также рекомендует Microsoft. Другой способ для определения столбцов в ключе зависит от того, планируем мы поиск или сортировку.
Неключевые столбцы индекса
Как насчет неключевой части? Какие столбцы следует туда добавить? Практически ни один из тех, что я упомянул в ключе, но все остальное, что удовлетворяет требованиям запроса. Другой способ решить - это те столбцы, о которых SQL Server не беспокоится при принятии решения о поиске или сортировке.
Когда вы создаете индекс и размещаете все столбцы в ключе, SQL сохраняет их в корневом узле. Имейте в виду, что ключ некластеризованного индекса имеет максимальный размер 1700 байтов, начиная с SQL Server 2016. До этого он был равен 900 байтов. Насколько я понимаю, этот размер управляет числом уровней в дереве.
Теперь давайте рассмотрим две главных причины добавления столбцов в неключевую часть.
Сокращение размера ключа
Первой причиной использования неключевых столбцов является сокращение размера ключа индекса. Когда вы помещаете столбцы в часть "Include", SQL сохраняет их только на листовом уровне. Я слышал разговоры о том, что это не оказывает заметного эффекта на число создаваемых страниц. В основном я согласен с этим мнением. Однако если вы знаете, что никогда не будете использовать столбец в предложении WHERE или ORDER BY, вы раздуваете число страниц как в корневом узле, так и на промежуточном уровне. Если вы имеете дело с небольшим набором данных, это не имеет значения. Однако таблицы, как сорняки, всегда растут со временем.
Давайте создадим набор данных для визуализации разницы. Скрипт ниже создает единственную таблицу с пятью столбцами. Вы можете видеть, что я сделал кластеризованный индекс на Column1. Затем мы вставляем 100 тысяч строк в эту новую таблицу.
DROP TABLE IF EXISTS dbo.IndexKeySize;
CREATE TABLE dbo.IndexKeySize
(
Column1 INT IDENTITY(1, 1),
Column2 INT NOT NULL,
Column3 CHAR(250) NOT NULL,
Column4 CHAR(250) NOT NULL,
Column5 NVARCHAR(MAX) NULL,
CONSTRAINT PK_IndexKeySize_Column1
PRIMARY KEY CLUSTERED (Column1)
);
GO
INSERT INTO dbo.IndexKeySize
(
Column2,
Column3,
Column4,
Column5
)
SELECT TOP (100000)
ABS(CHECKSUM(NEWID()) % 100) + 1 AS Column2,
SUBSTRING('ABCDEFGHIJKLMNOPQRSTUVWXYZ',
(ABS(CHECKSUM(NEWID())) % 26)+1, 10) AS Column3,
SUBSTRING('ABCDEFGHIJKLMNOPQRSTUVWXYZ',
(ABS(CHECKSUM(NEWID())) % 26)+1, 20) AS Column4,
SUBSTRING('ABCDEFGHIJKLMNOPQRSTUVWXYZ',
(ABS(CHECKSUM(NEWID())) % 26)+1, 20) AS Column5
FROM sys.all_columns AS n1
CROSS JOIN sys.all_columns AS n2;
GOПредположим теперь, что запрос ниже выполняется сотни раз на дню.
SELECT Column3,
Column4
FROM dbo.IndexKeySize
WHERE Column2 = 2;Для улучшения производительности создадим индекс. Если не использовать неключевые столбцы, DDL для индекса будет выглядеть подобно коду ниже.
CREATE NONCLUSTERED INDEX [IX_Column2_Column3_Column4]
ON dbo.IndexKeySize (
Column2,
Column3,
Column4
);
GOУдачи, наш новый блестящий индекс ждет своего часа. Давайте проверим, сколько уровней и страниц у нас имеется. Я собираюсь выполнить системную функцию sys.dm_db_index_physical_stats.
SELECT i.[name],
ips.index_type_desc,
ips.alloc_unit_type_desc,
ips.index_depth,
ips.index_level,
ips.page_count
FROM sys.dm_db_index_physical_stats(DB_ID(), OBJECT_ID('dbo.IndexKeySize'), NULL, NULL, 'DETAILED') ips
INNER JOIN sys.indexes i ON i.index_id = ips.index_id
AND [ips].[object_id] = [i].[object_id];
GO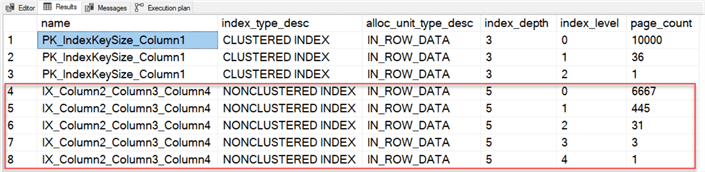
Вы можете увидеть на скриншоте выше, что наш индекс состоит из пяти уровней и содержит 7147 страниц. Как насчет создания другого индекса с определением столбцов Column3 и Column4 в качестве неключевых?
CREATE NONCLUSTERED INDEX [IX_Column2+Column3+Column4]
ON dbo.IndexKeySize (Column2)
INCLUDE (
Column3,
Column4
);
GOДавайте теперь снова выполним sys.dm_db_index_physical_stats.
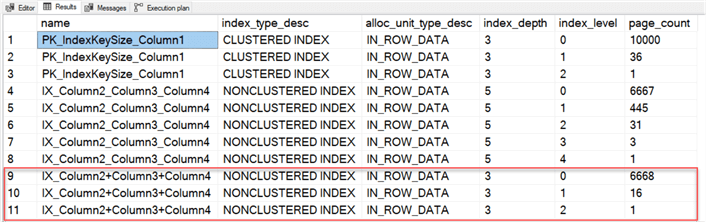
Обратите внимание, что наш новый индекс с неключевыми столбцами имеет всего три уровня в глубину для 6685 страниц. Как вы думаете, какой индекс будет использовать SQL Server, если мы еще раз выполним запрос выше?
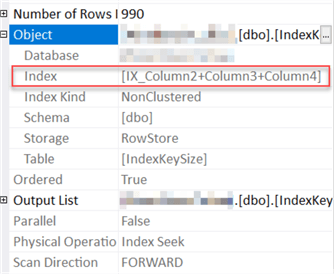
Вы угадали! Меньший индекс с меньшим числом страниц.
Типы данных, не поддерживаемые в ключе
Вторая причина использования неключевых столбцов состоит в том, что вы не можете поместить их в ключ. Вы обратили внимание, что Column5 имеет тип NVARCHAR(MAX)? Что если у нас есть следующий запрос, который выполняется в производственной среде сотни раз в день?
SELECT Column5
FROM dbo.IndexKeySize
WHERE Column2 = 2;Можете вы угадать, что произойдет, если я попытаюсь добавить Column5 в ключ индекса?
CREATE NONCLUSTERED INDEX [IX_Column2_Column5]
ON dbo.IndexKeySize (Column2,Column5);
GO
SQL возвращает сообщение об ошибке, которое просит вас этого не делать. Способ обойти это ограничение - разместить столбец в неключевой части индекса.
CREATE NONCLUSTERED INDEX [IX_Column2+Column5]
ON dbo.IndexKeySize (Column2)
INCLUDE (Column5);
GO
Я не пытался добавлять каждый тип данных в неключевую область, но Microsoft подтверждает, что вы можете использовать все типы данных за исключением text, ntext и image.
Заключение
Исходный вопрос состоял в том, имеет ли значение где размещать столбцы - в ключе или в неключевой части индекса? Судя по изложенному, да, это имеет значение. Вы не хотите, чтобы ключ индекса сильно разрастался, поскольку это приводит к увеличению размера корня и страниц промежуточных уровней. Кроме того, мы встретили ограничения при размещении определенных типов данных в ключе индекса. В этих случаях у вас есть вариант использовать включенные столбцы.
Ссылки по теме
- Что такое "включенные столбцы" в некластеризованных индексах?
- Столбцы, включенные в уникальный некластеризованный индекс, не являются частью ограничения UNIQUE
- Как думать подобно SQL Server: что лучше - ключевые столбцы или включенные в индекс?
- Как думать подобно SQL Server: включенные столбцы не дешевы
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой