
Изучение плана запроса в SQL
Пересказ статьи Dennes Torres. Exploring Query Plans in SQL
SQL Server сохраняет наиболее часто используемые планы выполнения в кэше, поэтому их не требуется перекомпилировать при каждом выполнении запроса. Как мы можем воспользоваться этим, чтобы найти потенциальные проблемы производительности в планах выполнения? Давайте попытаемся отыскать некоторые возможности для оптимизации, используя информацию, содержащуюся в кэше планов SQL Server.
Динамическое административное представление (DMV) sys.dm_db_index_usage_stats создает отчет об использовании индексов, и мы можем использовать это DMV для обнаружения индексов, которые могут вызывать проблемы. DMV могут предоставить итоги по некоторым видам использования индексов, например, число сканирований, поисков и переходов по закладкам, на основании чего мы можем выявить не только индексы, но также базы данных, которые требуют внимания.
Вот, в частности, та важная информация, которую мы можем извлечь с помощью DMV:
Я упрощаю методы оптимизации, но в этой статье внимание сфокусировано только на том, где искать возможности для оптимизации.
DMV sys.dm_db_index_usage_stats включает информацию о действиях пользователей и системы, т.е. user_scans и system_scans, но мы можем игнорировать системную информацию.
Первым шагом является обнаружение базы данных, которая в наибольшей мере подвержена этим проблемам. Нам нужен запрос для проблем каждого типа, будь-то сканирование или поиск закладки (поиск - seek - не является проблемой, однако отношение поиска к сканированию является той информацией, которая поможет нам идентифицировать проблемы, вызванные сканированием).
Вот запрос для поиска баз данных, которые испытывают наибольшие проблемы сканирования:
Суммирование user_scans для различных индексов большого смысла не имеет, поэтому мы вычисляем максимум и среднее значение пользовательского сканирования, чтобы найти базы данных, требующих нашего внимания.
Вот результат выполнения запроса на моем SQL Server:
Видим, что больше всего операций сканирования происходит в базе данных adventureworks2012.
Только после выбора конкретной базы данных мы может продолжить и получить имена индексов, которые могут вызывать проблемы. Чтобы это сделать, требуется соединить эту информацию из DMV с информацией из sys.indexes и получить имя индекса.
Следующий запрос необходимо запустить на выбранной базе данных (естественно, вы измените имя базы в запросе):
Эти примеры были созданы с использованием базы данных Adventureworks2012 , которую вы можете загрузить с https://msftdbprodsamples.codeplex.com/releases/view/55330. При этом таблицы ‘bigproduct’ and ‘bigtransactionhistory’ были созданы Адамом Мачаником, и вы можете найти их скрипт на http://sqlblog.com/blogs/adam_machanic/archive/2011/10/17/thinking-big-adventure.aspx. Активность сканирования генерировалась при помощи инструмента SQL Query Stress, также разработанного Адамом, и вы можете взять его отсюда: http://dataeducation.com/sqlquerystress-the-source-code/.
Замечу, что я также использовал index_id для идентификации индекса как кластеризованного или некластеризованного. Я также включил информацию о поиске, чтобы мы могли сравнить отношение числа сканирований к поискам и решить, какой индекс требует пристального внимания.
В результате мы можем выяснить, что таблица bigproduct и её кластеризованный индекс имеют множество сканирований, поэтому мы должны сосредоточиться на них.
Оба запроса, которые я использовал до сих пор, были созданы для того, чтобы изучать проблемы сканирования, однако вы можете использовать эти же запросы и для проблем поиска закладок: вам просто нужно изменить поле user_scans на поле user_looups.
При помощи рассмотренных запросов мы находим, какие базы данных и индексы требуют внимания, но как обнаружить те планы запросов, с помощью которых мы найдем сами запросы, вызывающие эти проблемы?
На втором шаге мы можем использовать SQL для обнаружения проблемных планов запросов в кэше с последующим переходом к запросам, требующим оптимизации.
Используя DMV sys.dm_exec_query_stats, мы можем выбрать все запросы в кэше и идентифицировать проблемные планы.
Это DMV имеет дескриптор, который мы можем использовать для получения плана запроса, и дескриптор, который мы можем использовать для получения текста запроса. Для их получения мы будем использовать динамические административные функции (DMF) sys.dm_exec_query_plan и sys.dm_exec_sql_text соответственно. Нам потребуется CROSS APPLY.
Запрос
Поле query_plan представлен в виде XML, однако, если вы наблюдаете результат в сетке (result to grid), окно запроса в SSMS распознает схему и показывает графический план при щелчке по ссылке. Это удобно для изучения отдельных планов, но не для систематического поиска по множеству планов, отвечающих конктерному критерию. Если мы не сможем фильтровать результаты на основе XML, нам придется просматривать их по одному. Поэтому лучшим вариантом является использование Xquery.
Если щелкнуть по полю query_plan, мы увидим графический план запроса
Для того, чтобы использовать XQuery не вслепую для поиска в XML, нам потребуется информация об используемой XML-схеме.
Схема этого документа XML опубликована на http://schemas.microsoft.com/sqlserver/2004/07/showplan
Существует множество возможностей для обнаружения проблем выполнения с помощью этого метода, но я смогу показать лишь несколько. А для выполнения различных исследований, вам потребуется изучить схему.
Просматривая схему, мы обнаружим, что имеется элемент RelOp с атрибутом LogicalOp, который мы можем использовать для нахождения всех планов, которые включают сканирование индекса или сканирование таблицы. Давайте рассмотрим запрос:
XML плана запроса является типизированным, поэтому нам нужно определить пространство имен для того, чтобы использовать Xquery. Схема несколько сложна, и вам нужно быть внимательными при написании собственных запросов. Например, возможны ошибки при запросе элемента IndexScan, поскольку элемент IndexScan используется во всех операциях с индексами, включая поиск и поиск закладок.
Следующий шаг - фильтрация результатов по указанному индексу. Мы уже обнаружили индексы с наибольшим числом сканирований, теперь мы можем выяснить, какие планы их порождают. Следуя схеме, имя индекса является атрибутом элемента Object внутри элемента IndexScan, который находится внутри элемента RelOp.
Поэтому запрос будет таким:
Если запрос выдает слишком много планов, мы можем использовать другие поля в sys.dm_exec_query_Stats, чтобы найти планы, требующие оптимизации. Например, мы можем использовать поле total_worker_time, чтобы упорядочить результаты по времени CPU, например:
В моей ситуации результатом является только один план запроса. Мы имеем текст соответствующего запроса и можем посмотреть графический план в SSMS. SSMS моказывает даже информацию о "недостающих индексах", позволяя легко решить проблему, создав их.

Мы нашли тот самый запрос, который порождает проблему и...

...мы можем увидеть графический план и предположение об отсутствующем индексе.
Другим примером использования DMV является поиск планов с поиском закладок в индексе. Если изменить первый запрос на вычисление количества закладок, мы обнаружим множество закладок в adventureworks2012:
Попробуем найти индекс, который их порождает, для дальнейшего исследования:
Наконец, чтобы найти планы запросов с закладками, нам нужно выполнить фильтрацию по атрибуту lookup в элементе IndexScan. Новый запрос:
В этом примере мы обнаружим, что если удалить два поля - quantity и actualcost из запроса, то lookup пропадет. Конечно, это невозможно, и в данном случае нам пришлось бы искать другое решение, но это тема не данной статьи.
Замечательно, что мы можем находить планы запросов в кэше для поиска проблем, однако непрактично использовать подобные запросы в процессе ежедневной оптимизации. Как сделать это более практичным? Просто: мы создаем функцию, и нам больше не нужно беспокоиться о сложном синтаксисе запросов. Итак, мы можем создать запросы для каждой из главных проблем в плане запросов, а затем создать одну функцию для каждого запроса.
Метод XQuery exists() принимает только константы в качестве параметров. Поэтому для доступа к переменной внутри выражения xquery мы можем только лишь преобразовав имя индекса в переменную при помощи выражения sql:variable.
Ниже приведена полученная таким образом функция:
Обратите внимание, что я включил функцию fn:lower-case, в противном случае функция стала бы чувствительна к регистру, как и XML.
Теперь для поиска планов в кэше, которые используют сканирование конкретного индекса, достаточно написать простой запрос:
Аналогично для проблем с закладками:
И последний штрих: поскольку мы создаем повторно исполняемые функции, будет полезно выводить больше полей из sys.dm_exec_query_stats, чтобы функции стали более гибкими.
Вот окончательный вид функций:
Мы можем начать с построения множества запросов, которые применяют мощь XQuery для поиска планов выполнения, хранящихся в кэше, чтобы наметить пути оптимизации запросов и устранения потенциальных проблем. Затем можно обернуть эти запросы в функции для их повторного использования. При создании новых функций весьма полезно изучить схему плана выполнения и испытать их на предмет производительности, прежде чем использовать на рабочем сервере. Хотя они весьма удобны при отслеживании проблем производительности, сами запросы не являются быстрыми.
Вот, в частности, та важная информация, которую мы можем извлечь с помощью DMV:
- Scans: Сканирование обычно худший вариант с точки зрения производительности, поскольку в поисках нужной информации просматривается весь индекс. Вероятно, вам потребуется оптимизировать те запросы, которые приводят к интенсивному сканированию, перерабатывая сами запросы или индекс.
- Seeks: Поиск в отличие от сканирования - лучший вариант использования индекса, поэтому мы можем сравнить отношение поиска к сканированию, чтобы обнаружить те индексы, которые чаще сканируются, чем используется поиск, что может являться потенциальным источником проблем.
- Lookups: Поиск закладки происходит тогда, когда операции, выполняемой на некластеризованном индексе, требуются дополнительные столбцы для запроса, обычно использующего кластеризованный индекс. Это дорогая операция, поэтому оптимизатор запросов в отдельных случаях может принять решение о сканировании кластеризованного индекса вместо поиска закладок. В последнем случае, конечно, это даст количество сканирований, а не поиска закладок. Поэтому число поиска закладок включается только тогда, когда сканирование становится слишком дорогим, что также плохо для производительности.
Я упрощаю методы оптимизации, но в этой статье внимание сфокусировано только на том, где искать возможности для оптимизации.
DMV sys.dm_db_index_usage_stats включает информацию о действиях пользователей и системы, т.е. user_scans и system_scans, но мы можем игнорировать системную информацию.
Первым шагом является обнаружение базы данных, которая в наибольшей мере подвержена этим проблемам. Нам нужен запрос для проблем каждого типа, будь-то сканирование или поиск закладки (поиск - seek - не является проблемой, однако отношение поиска к сканированию является той информацией, которая поможет нам идентифицировать проблемы, вызванные сканированием).
Идентификация проблем сканирования
Вот запрос для поиска баз данных, которые испытывают наибольшие проблемы сканирования:
select db_name(database_id),max(user_scans) bigger,
avg(user_scans) average
from sys.dm_db_index_usage_stats
group by db_name(database_id)
order by average desc
Суммирование user_scans для различных индексов большого смысла не имеет, поэтому мы вычисляем максимум и среднее значение пользовательского сканирования, чтобы найти базы данных, требующих нашего внимания.
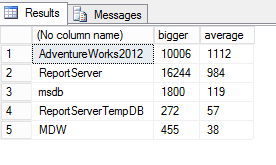
Вот результат выполнения запроса на моем SQL Server:
Видим, что больше всего операций сканирования происходит в базе данных adventureworks2012.
Только после выбора конкретной базы данных мы может продолжить и получить имена индексов, которые могут вызывать проблемы. Чтобы это сделать, требуется соединить эту информацию из DMV с информацией из sys.indexes и получить имя индекса.
Следующий запрос необходимо запустить на выбранной базе данных (естественно, вы измените имя базы в запросе):
Use adventureworks2012 /* <<<<------- тут вы должны подставить имя своей базы данных */
select object_name(c.object_id) as [table],
c.name as [index],user_scans,user_seeks,
case a.index_id
when 1 then 'CLUSTERED'
else 'NONCLUSTERED'
end as type
from sys.dm_db_index_usage_stats a
inner join sys.indexes c
on c.object_id=a.object_id and c.index_id=a.index_id
and database_id=DB_ID('AdventureWorks2012') /* <<<<-- измените имя базы данных */
order by user_scans desc
Эти примеры были созданы с использованием базы данных Adventureworks2012 , которую вы можете загрузить с https://msftdbprodsamples.codeplex.com/releases/view/55330. При этом таблицы ‘bigproduct’ and ‘bigtransactionhistory’ были созданы Адамом Мачаником, и вы можете найти их скрипт на http://sqlblog.com/blogs/adam_machanic/archive/2011/10/17/thinking-big-adventure.aspx. Активность сканирования генерировалась при помощи инструмента SQL Query Stress, также разработанного Адамом, и вы можете взять его отсюда: http://dataeducation.com/sqlquerystress-the-source-code/.
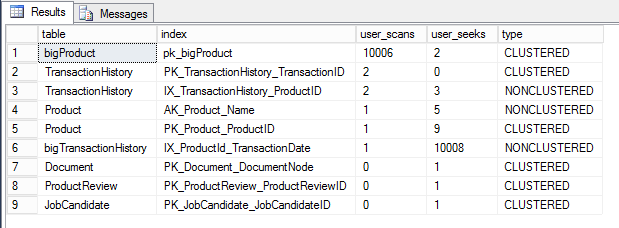
Замечу, что я также использовал index_id для идентификации индекса как кластеризованного или некластеризованного. Я также включил информацию о поиске, чтобы мы могли сравнить отношение числа сканирований к поискам и решить, какой индекс требует пристального внимания.
В результате мы можем выяснить, что таблица bigproduct и её кластеризованный индекс имеют множество сканирований, поэтому мы должны сосредоточиться на них.
Оба запроса, которые я использовал до сих пор, были созданы для того, чтобы изучать проблемы сканирования, однако вы можете использовать эти же запросы и для проблем поиска закладок: вам просто нужно изменить поле user_scans на поле user_looups.
Поиск планов запросов, вызывающих сканирование
При помощи рассмотренных запросов мы находим, какие базы данных и индексы требуют внимания, но как обнаружить те планы запросов, с помощью которых мы найдем сами запросы, вызывающие эти проблемы?
На втором шаге мы можем использовать SQL для обнаружения проблемных планов запросов в кэше с последующим переходом к запросам, требующим оптимизации.
Используя DMV sys.dm_exec_query_stats, мы можем выбрать все запросы в кэше и идентифицировать проблемные планы.
Это DMV имеет дескриптор, который мы можем использовать для получения плана запроса, и дескриптор, который мы можем использовать для получения текста запроса. Для их получения мы будем использовать динамические административные функции (DMF) sys.dm_exec_query_plan и sys.dm_exec_sql_text соответственно. Нам потребуется CROSS APPLY.
Запрос
select qp.query_plan,qt.text from sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle) qt
CROSS APPLY sys.dm_exec_query_plan(plan_handle) qp
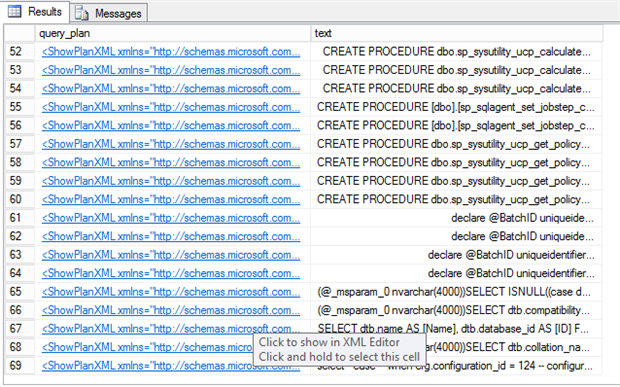
Поле query_plan представлен в виде XML, однако, если вы наблюдаете результат в сетке (result to grid), окно запроса в SSMS распознает схему и показывает графический план при щелчке по ссылке. Это удобно для изучения отдельных планов, но не для систематического поиска по множеству планов, отвечающих конктерному критерию. Если мы не сможем фильтровать результаты на основе XML, нам придется просматривать их по одному. Поэтому лучшим вариантом является использование Xquery.
Если щелкнуть по полю query_plan, мы увидим графический план запроса
Для того, чтобы использовать XQuery не вслепую для поиска в XML, нам потребуется информация об используемой XML-схеме.
Схема этого документа XML опубликована на http://schemas.microsoft.com/sqlserver/2004/07/showplan
Существует множество возможностей для обнаружения проблем выполнения с помощью этого метода, но я смогу показать лишь несколько. А для выполнения различных исследований, вам потребуется изучить схему.
Просматривая схему, мы обнаружим, что имеется элемент RelOp с атрибутом LogicalOp, который мы можем использовать для нахождения всех планов, которые включают сканирование индекса или сканирование таблицы. Давайте рассмотрим запрос:
select qp.query_plan,qt.text from sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle) qt
CROSS APPLY sys.dm_exec_query_plan(plan_handle) qp
where qp.query_plan.exist('declare namespace
qplan="http://schemas.microsoft.com/sqlserver/2004/07/showplan";
//qplan:RelOp[@LogicalOp="Index Scan"
or @LogicalOp="Clustered Index Scan"
or @LogicalOp="Table Scan"]')=1
XML плана запроса является типизированным, поэтому нам нужно определить пространство имен для того, чтобы использовать Xquery. Схема несколько сложна, и вам нужно быть внимательными при написании собственных запросов. Например, возможны ошибки при запросе элемента IndexScan, поскольку элемент IndexScan используется во всех операциях с индексами, включая поиск и поиск закладок.
Следующий шаг - фильтрация результатов по указанному индексу. Мы уже обнаружили индексы с наибольшим числом сканирований, теперь мы можем выяснить, какие планы их порождают. Следуя схеме, имя индекса является атрибутом элемента Object внутри элемента IndexScan, который находится внутри элемента RelOp.
Поэтому запрос будет таким:
select qp.query_plan,qt.text from sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle) qt
CROSS APPLY sys.dm_exec_query_plan(plan_handle) qp
where qp.query_plan.exist('declare namespace
qplan="http://schemas.microsoft.com/sqlserver/2004/07/showplan";
//qplan:RelOp/qplan:IndexScan/qplan:Object[@Index="[pk_bigProduct]"]')=1
Если запрос выдает слишком много планов, мы можем использовать другие поля в sys.dm_exec_query_Stats, чтобы найти планы, требующие оптимизации. Например, мы можем использовать поле total_worker_time, чтобы упорядочить результаты по времени CPU, например:
select qp.query_plan,qt.text,total_worker_time from sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle) qt
CROSS APPLY sys.dm_exec_query_plan(plan_handle) qp
where qp.query_plan.exist('declare namespace
qplan="http://schemas.microsoft.com/sqlserver/2004/07/showplan";
//qplan:RelOp[@LogicalOp="Index Scan"
or @LogicalOp="Clustered Index Scan"
or @LogicalOp="Table Scan"]/qplan:IndexScan/qplan:Object[@Index="[pk_bigProduct]"]')=1
order by total_worker_time desc
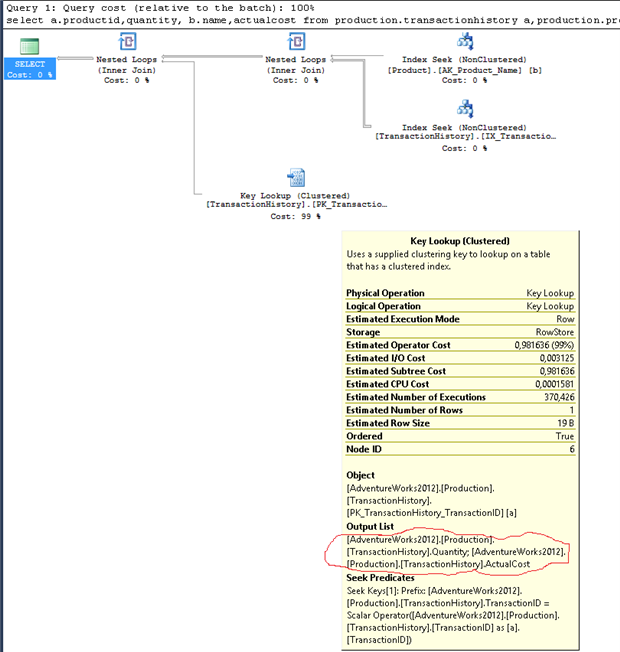
В моей ситуации результатом является только один план запроса. Мы имеем текст соответствующего запроса и можем посмотреть графический план в SSMS. SSMS моказывает даже информацию о "недостающих индексах", позволяя легко решить проблему, создав их.
Мы нашли тот самый запрос, который порождает проблему и...
...мы можем увидеть графический план и предположение об отсутствующем индексе.
Идентификация проблем поиска закладок
Другим примером использования DMV является поиск планов с поиском закладок в индексе. Если изменить первый запрос на вычисление количества закладок, мы обнаружим множество закладок в adventureworks2012:
select db_name(database_id),max(user_lookups) bigger,
avg(user_lookups) average
from sys.dm_db_index_usage_stats
group by db_name(database_id)
order by average desc
Попробуем найти индекс, который их порождает, для дальнейшего исследования:
use adventureworks2012 /* <<<<<------- вам нужно изменить имя базы данных */
select object_name(c.object_id) as [table],
c.name as [index],user_lookups,
case a.index_id
when 1 then 'CLUSTERED'
else 'NONCLUSTERED'
end as type
from sys.dm_db_index_usage_stats a
inner join sys.indexes c
on c.object_id=a.object_id and c.index_id=a.index_id
and database_id=DB_ID('AdventureWorks2012') /* <<<<<--измените имя базы данных */
order by user_lookups desc
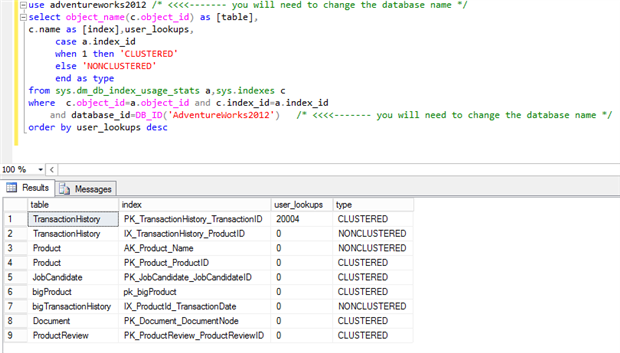 Adventureworks2012 также имеет проблемы с закладками
Adventureworks2012 также имеет проблемы с закладками
Наконец, чтобы найти планы запросов с закладками, нам нужно выполнить фильтрацию по атрибуту lookup в элементе IndexScan. Новый запрос:
select qp.query_plan,qt.text, plan_handle,query_plan_hash from
sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle) qt
CROSS APPLY sys.dm_exec_query_plan(plan_handle) qp
where qp.query_plan.exist('declare namespace
AWMI="http://schemas.microsoft.com/sqlserver/2004/07/showplan";
//AWMI:IndexScan[@Lookup]/AWMI:Object[@Index="[PK_TransactionHistory_TransactionID]"]')=1
В этом примере мы обнаружим, что если удалить два поля - quantity и actualcost из запроса, то lookup пропадет. Конечно, это невозможно, и в данном случае нам пришлось бы искать другое решение, но это тема не данной статьи.
Мы видим причину закладки
Настройка исследовательских запросов на практические цели
Замечательно, что мы можем находить планы запросов в кэше для поиска проблем, однако непрактично использовать подобные запросы в процессе ежедневной оптимизации. Как сделать это более практичным? Просто: мы создаем функцию, и нам больше не нужно беспокоиться о сложном синтаксисе запросов. Итак, мы можем создать запросы для каждой из главных проблем в плане запросов, а затем создать одну функцию для каждого запроса.
Метод XQuery exists() принимает только константы в качестве параметров. Поэтому для доступа к переменной внутри выражения xquery мы можем только лишь преобразовав имя индекса в переменную при помощи выражения sql:variable.
Ниже приведена полученная таким образом функция:
Create FUNCTION [dbo].[FindScans]
(
-- Добавьте параметры функции
@Index varchar(50)
)
RETURNS TABLE
AS
RETURN
(
select qp.query_plan,qt.text,total_worker_time from sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle) qt
CROSS APPLY sys.dm_exec_query_plan(plan_handle) qp
where qp.query_plan.exist('declare namespace
qplan="http://schemas.microsoft.com/sqlserver/2004/07/showplan";
//qplan:RelOp[@LogicalOp="Index Scan"
or @LogicalOp="Clustered Index Scan"
or @LogicalOp="Table Scan"]/qplan:IndexScan/qplan:Object[fn:lower-case(@Index)=fn:lower-
case(sql:variable("@Index"))]')=1
)
GO
Обратите внимание, что я включил функцию fn:lower-case, в противном случае функция стала бы чувствительна к регистру, как и XML.
Теперь для поиска планов в кэше, которые используют сканирование конкретного индекса, достаточно написать простой запрос:
select * from dbo.FindScans('[pk_bigProduct]')Аналогично для проблем с закладками:
CREATE FUNCTION FindLookups
(
-- Добавьте параметры функции
@Index varchar(50)
)
RETURNS TABLE
AS
RETURN
(
select qp.query_plan,qt.text from sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle) qt
CROSS APPLY sys.dm_exec_query_plan(plan_handle) qp
where qp.query_plan.exist('declare namespace
AWMI="http://schemas.microsoft.com/sqlserver/2004/07/showplan";
//AWMI:IndexScan[@Lookup]/AWMI:Object[fn:lower-case(@Index)=fn:lower-
case(sql:variable("@Index"))]')=1
)
GO
select * from dbo.FindLookups('[PK_TransactionHistory_TransactionID]')
И последний штрих: поскольку мы создаем повторно исполняемые функции, будет полезно выводить больше полей из sys.dm_exec_query_stats, чтобы функции стали более гибкими.
Вот окончательный вид функций:
Create FUNCTION [dbo].[FindScans]
(
-- Добавьте параметры функции
@Index varchar(50)
)
RETURNS TABLE
AS
RETURN
(
select qp.query_plan,qt.text,
statement_start_offset, statement_end_offset,
creation_time, last_execution_time,
execution_count, total_worker_time,
last_worker_time, min_worker_time,
max_worker_time, total_physical_reads,
last_physical_reads, min_physical_reads,
max_physical_reads, total_logical_writes,
last_logical_writes, min_logical_writes,
max_logical_writes, total_logical_reads,
last_logical_reads, min_logical_reads,
max_logical_reads, total_elapsed_time,
last_elapsed_time, min_elapsed_time,
max_elapsed_time, total_rows,
last_rows, min_rows,
max_rows from sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle) qt
CROSS APPLY sys.dm_exec_query_plan(plan_handle) qp
where qp.query_plan.exist('declare namespace
qplan="http://schemas.microsoft.com/sqlserver/2004/07/showplan";
//qplan:RelOp[@LogicalOp="Index Scan"
or @LogicalOp="Clustered Index Scan"
or @LogicalOp="Table Scan"]/qplan:IndexScan/qplan:Object[fn:lower-
case(@Index)=fn:lower-case(sql:variable("@Index"))]')=1
)
GO
Create FUNCTION FindLookups
(
-- Добавьте параметры функции
@Index varchar(50)
)
RETURNS TABLE
AS
RETURN
(
select qp.query_plan,qt.text,
statement_start_offset, statement_end_offset,
creation_time, last_execution_time,
execution_count, total_worker_time,
last_worker_time, min_worker_time,
max_worker_time, total_physical_reads,
last_physical_reads, min_physical_reads,
max_physical_reads, total_logical_writes,
last_logical_writes, min_logical_writes,
max_logical_writes, total_logical_reads,
last_logical_reads, min_logical_reads,
max_logical_reads, total_elapsed_time,
last_elapsed_time, min_elapsed_time,
max_elapsed_time, total_rows,
last_rows, min_rows,
max_rows from sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle) qt
CROSS APPLY sys.dm_exec_query_plan(plan_handle) qp
where qp.query_plan.exist('declare namespace
AWMI="http://schemas.microsoft.com/sqlserver/2004/07/showplan";
//AWMI:IndexScan[@Lookup]/AWMI:Object[fn:lower-case(@Index)=fn:lower-
case(sql:variable("@Index"))]')=1
)
GO
Заключение
Мы можем начать с построения множества запросов, которые применяют мощь XQuery для поиска планов выполнения, хранящихся в кэше, чтобы наметить пути оптимизации запросов и устранения потенциальных проблем. Затем можно обернуть эти запросы в функции для их повторного использования. При создании новых функций весьма полезно изучить схему плана выполнения и испытать их на предмет производительности, прежде чем использовать на рабочем сервере. Хотя они весьма удобны при отслеживании проблем производительности, сами запросы не являются быстрыми.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой