Пересказ статьи Hugo Kornelis. Columnstore Index Scan
Введение
Columnstore Index Scan фактически не является оператором. Вы можете встретить его в графических планах выполнения SSMS (или других инструментов), но если вы посмотрите на лежащий в основе плана выполнения XML, то увидите, что это либо оператор Index Scan, либо Clustered Index Scan.
Продолжить чтение "Сканирование поколоночного индекса"
Пересказ статьи Hugo Kornelis. Clustered Index Seek
Введение
Оператор Clustered Index Seek использует структуру кластеризованного индекса для эффективного поиска как отдельных строк (singleton seek), так и конкретных подмножеств строк (range seek). Поскольку кластеризованный индекс всегда содержит все столбцы таблицы, Clustered Index Seek является одним из наиболее эффективных приемов, который применяет SQL Server для поиска отдельных строк и небольших диапазонов при условии наличия фильтра, который может быть эффективно использован.
Продолжить чтение "Поиск в кластеризованном индексе (Clustered Index Seek)"
Пересказ статьи Hugo Kornelis. Index Seek
Введение
Оператор Index Seek использует структуру некластеризованного индекса для эффективного поиска как отдельных строк (singleton seek), так и конкретных подмножеств строк (range seek). ( Когда SQL Server требуется прочитать отдельные строки или небольшие подмножества строк из кластеризованного индекса, он использует другой оператор: Clustered Index Seek).
Продолжить чтение "Поиск в индексе (Index Seek)"
Пересказ статьи Mike Byrd. TOP vs Max/Min: Is there a difference
Я всегда стараюсь больше узнать работе черного ящика оптимизатора, и недавно заинтересовался тем, как он решает следующие запросы:
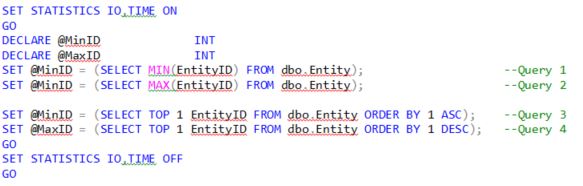 Продолжить чтение "TOP или Max/Min: есть ли разница?"
Продолжить чтение "TOP или Max/Min: есть ли разница?"
Пересказ статьи Brent Ozar. Can deleting rows make a table…bigger?
Michael J. Swart задал интересный вопрос: его таблица содержала 7,5 миллиардов строк и 5 индексов. При удалении 10 миллионов строк он обратил внимание, что индексы стали больше, а не меньше.
Продолжить чтение "Может ли удаление строк сделать таблицу...больше?"
Пересказ статьи Edwin Sanchez. How to Use SQL Server HierarchyID Through Easy Examples
Вы еще используете родительско-дочерний подход или хотели бы попробовать что-то новое типа hierarchyID? Да, это относительно новое, поскольку hierarchyID появился в SQL Server 2008. Конечно, новизна, сама по себе, не является аргументом. Однако заметьте, что Microsoft добавил эту функциональность для лучшего представления многоуровневых отношений один-ко-многим.
Продолжить чтение "Использование HierarchyID в SQL Server на простых примерах"
Пересказ статьи Arthur Daniels. Query memory grants part 2: Varchars and sorting
Какого черта мы сделали все наши столбцы varchar? Это гипотетический вопрос, извините.
И теперь мы должны заплатить за наши решения. Рассмотрим запрос, который должен выполнить некоторую сортировку. Давайте возьмем таблицу, которую нужно отсортировать.
Продолжить чтение "Query memory grants. Часть 2: Varchar и сортировка"
Пересказ статьи Arthur Daniels. Query memory grants part 1: Where does the memory go?
Давайте поговорим о том, как запросы используют память, а именно, в плане выполнения. Одним из операторов запроса, который использует память, является сортировка. Чтобы продемонстрировать это, я напишу запрос с предложением ORDER BY и покажу план выполнения.
Продолжить чтение "Query memory grants. Часть 1: куда девается память?"
