
TOP или Max/Min: есть ли разница?
Пересказ статьи Mike Byrd. TOP vs Max/Min: Is there a difference
Я всегда стараюсь больше узнать работе черного ящика оптимизатора, и недавно заинтересовался тем, как он решает следующие запросы:
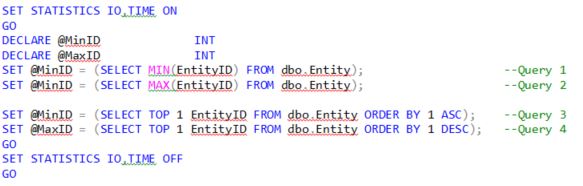
Таблица dbo.Entity содержит 31404767 строк. Все 4 запроса имеют одинаковые показатели ввода/вывода: число сканирований 1, логических чтений 4, физических чтений 0 и т.д., а планы этих запросов выглядят так:
Хм, интересно! Я думал, что оптимизатор мог прийти к одному и тому же плану выполнения для каждого запроса, однако запросы с TOP приводят к несколько более сложному плану. Давайте оценим 4 плана и посмотрим на отличия.
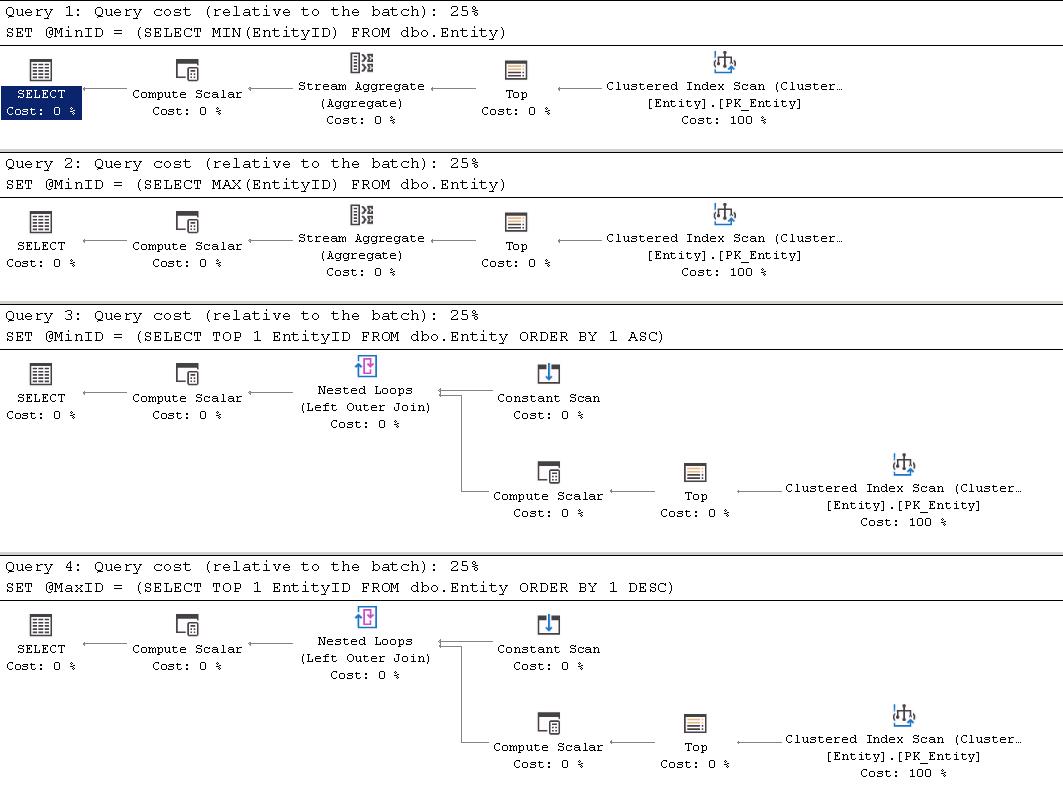
Похоже, что все 4 одинаковы по стоимости запроса (относительно пакета): 25%, но если посмотреть на фактические числа, то запросы 1 и 2 имеют стоимость поддерева
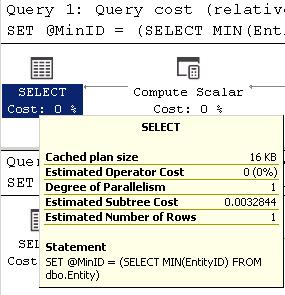
Это небольшая разница (0.0000043), но все же разница. Если внимательно посмотреть на различие в двух планах, то в запросах 1 и 2 мы имеем оператор Stream Aggregate, а в запросах 3 и 4 - дополнительные операторы Compute Scalar, Constant Scan и Nested Loop.
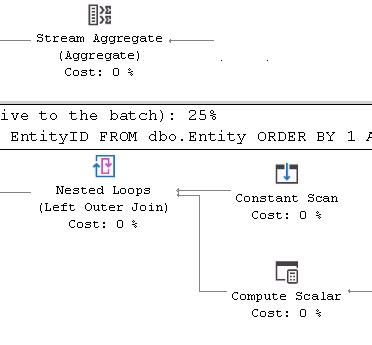
Я не собираюсь обсуждать относительные метрики этих операторов, а лишь один факт, не показанный здесь, который заключается в том, что все 4 запроса имеют время ЦП 0 секунд (на самом деле это менее 0,5 миллисекунды), но затраченное время для всех 4 запросов, неизменно показывало увеличение времени в 4-8 для запросов 3 и 4 по сравнению с запросами 1 и 2.
Запросы 1 и 3 завершаются сканированием вперед кластеризованного индекса (MIN), а запросы 2 и 4 - сканированием назад кластеризованного индекса (MAX), и каждый возвращает единственную строку, как показано на схеме ниже:
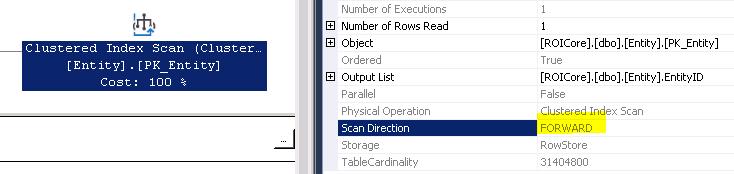
Именно этот результат (и ответ) я ожидал получить на всех 4 запросах, но действительно интересно, откуда все остальные операторы в плане запроса, ь.к. я полагал, что оптимизатор достаточно "умен" для того, чтобы распознать простые запросы и не требовать лишних операторов.
Наконец, я изначально совсем не ожидал увидеть здесь 4 логических чтения. После выполнения следующего запроса
частичные результаты имеют вид
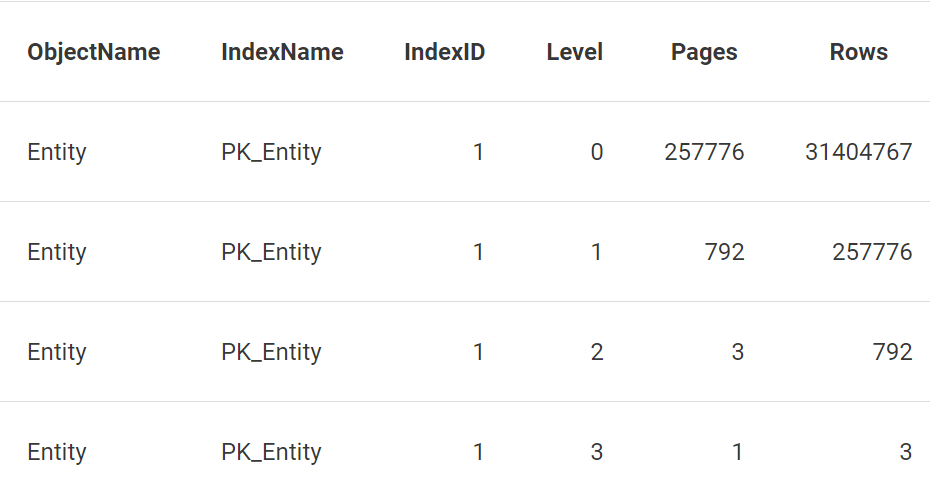
При 4 уровнях в B-Tree, несмотря на то, что возвращается только одна строка, запросам необходимо пройти 4 уровня (т.е. прочитать 4 страницы) для получения данных одной строки.
Итак, что мы узнали? Кажется, что агрегатные функции MAX, MIN и функция TOP все начинают со сканирования одного и того же индекса, однако то, как затем оптимизатор использует промежуточные результаты, слегка отличается. Есть ли большой выигрыш в использовании TOP? Я бы не сказал, но если бы эти операторы T-SQL вызывались тысячи раз в течение короткого периода времени, возможно, вы бы рассмотрели вариант использования MAX и MIN вместо функции TOP.
Хм, интересно! Я думал, что оптимизатор мог прийти к одному и тому же плану выполнения для каждого запроса, однако запросы с TOP приводят к несколько более сложному плану. Давайте оценим 4 плана и посмотрим на отличия.
Похоже, что все 4 одинаковы по стоимости запроса (относительно пакета): 25%, но если посмотреть на фактические числа, то запросы 1 и 2 имеют стоимость поддерева
Это небольшая разница (0.0000043), но все же разница. Если внимательно посмотреть на различие в двух планах, то в запросах 1 и 2 мы имеем оператор Stream Aggregate, а в запросах 3 и 4 - дополнительные операторы Compute Scalar, Constant Scan и Nested Loop.
Я не собираюсь обсуждать относительные метрики этих операторов, а лишь один факт, не показанный здесь, который заключается в том, что все 4 запроса имеют время ЦП 0 секунд (на самом деле это менее 0,5 миллисекунды), но затраченное время для всех 4 запросов, неизменно показывало увеличение времени в 4-8 для запросов 3 и 4 по сравнению с запросами 1 и 2.
Запросы 1 и 3 завершаются сканированием вперед кластеризованного индекса (MIN), а запросы 2 и 4 - сканированием назад кластеризованного индекса (MAX), и каждый возвращает единственную строку, как показано на схеме ниже:
Именно этот результат (и ответ) я ожидал получить на всех 4 запросах, но действительно интересно, откуда все остальные операторы в плане запроса, ь.к. я полагал, что оптимизатор достаточно "умен" для того, чтобы распознать простые запросы и не требовать лишних операторов.
Наконец, я изначально совсем не ожидал увидеть здесь 4 логических чтения. После выполнения следующего запроса
dbcc showcontig ('dbo.Entity')
with tableresults, all_indexes, all_levels;частичные результаты имеют вид
При 4 уровнях в B-Tree, несмотря на то, что возвращается только одна строка, запросам необходимо пройти 4 уровня (т.е. прочитать 4 страницы) для получения данных одной строки.
Итак, что мы узнали? Кажется, что агрегатные функции MAX, MIN и функция TOP все начинают со сканирования одного и того же индекса, однако то, как затем оптимизатор использует промежуточные результаты, слегка отличается. Есть ли большой выигрыш в использовании TOP? Я бы не сказал, но если бы эти операторы T-SQL вызывались тысячи раз в течение короткого периода времени, возможно, вы бы рассмотрели вариант использования MAX и MIN вместо функции TOP.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой