
Использование HierarchyID в SQL Server на простых примерах
Пересказ статьи Edwin Sanchez. How to Use SQL Server HierarchyID Through Easy Examples
Вы еще используете родительско-дочерний подход или хотели бы попробовать что-то новое типа hierarchyID? Да, это относительно новое, поскольку hierarchyID появился в SQL Server 2008. Конечно, новизна, сама по себе, не является аргументом. Однако заметьте, что Microsoft добавил эту функциональность для лучшего представления многоуровневых отношений один-ко-многим.
Вам может быть интересно, чем это отличается от обычных отношений родитель/ребенок, и какие преимущества дает использование hierarchyID. Если вы никогда не рассматривали этот вопрос, результат может оказаться для вас неожиданным.
Признаюсь, что и я не изучал эту возможность, когда она появилась. Однако, когда я впоследствии сделал это, то оценил новинку. Она дает лучше выглядящий код, но далеко не только это. В данной статье у нас будет возможность выяснить все эти великолепные возможности.
Но прежде чем мы углубимся в особенности использования hierarchyID, давайте проясним его смысл и область применения.
HierarchyID - это встроенный тип данных в SQL Server, предназначенный для представления деревьев, которые являются наиболее распространенным типом иерархических данных. Каждый элемент дерева называется узлом. В табличном формате это строка со столбцом типа данных hierarchyID.
Обычно мы проектируем иерархии с помощью таблиц. Столбец ID представляет узел, а другой столбец указывает на родителя. Используя HierarchyID нам потребуется только один столбец типа данных hierarchyID.
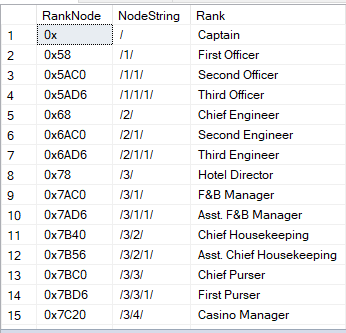
Если выполнить запрос к таблице со столбцом hierarchyID, вы увидите шестнадцатеричные числа. Это одно из визуальных представлений узла. Другим представлением является строка:
'/' - указывает на корневой узел;
‘/1/’, ‘/2/’, ‘/3/’ or ‘/n/’ - представляет потомков - прямые потомки от 1 до n;
‘/1/1/’ or ‘/1/2/’ - это потомки потомков или "внуки". Строка типа '/1/2/' означает, что первый потомок от корня имеет двух детей, которые, в свою очередь, являются двумя внуками корня.
Вот пример того, как это выглядит:
В отличие от других типов данных, столбец hierarchyID обладает тем преимуществом, что может иметь встроенные методы. Например, если у вас есть столбец в именем RankNode, вы можете использовать следующий синтаксис:
Одним из имеющихся методов является IsDescendantOf. Он возвращает 1, если текущий узел является потомком значения hierarchyID.
Вы можете написать подобный код с использованием этого метода:
Другими методами, используемыми с hierarchyID являются:
Чтобы гарантировать максимально быстрое выполнение запросов к таблицам, использующим hierarchyID, вам потребуется проиндексировать столбец. Имеется две стратегии индексирования:
В индексе depth-first строки поддерева находятся рядом друг с другом. Это подходит таким запросам, как поиск отделов, их подразделений и сотрудников. Другой пример - управляющий и его подчиненные, которые сохраняются рядом.
В таблице вы можете реализовать индекс depth-first путем создания кластеризованного индекса на узлах. Теперь мы выполняем один из наших примеров именно так.
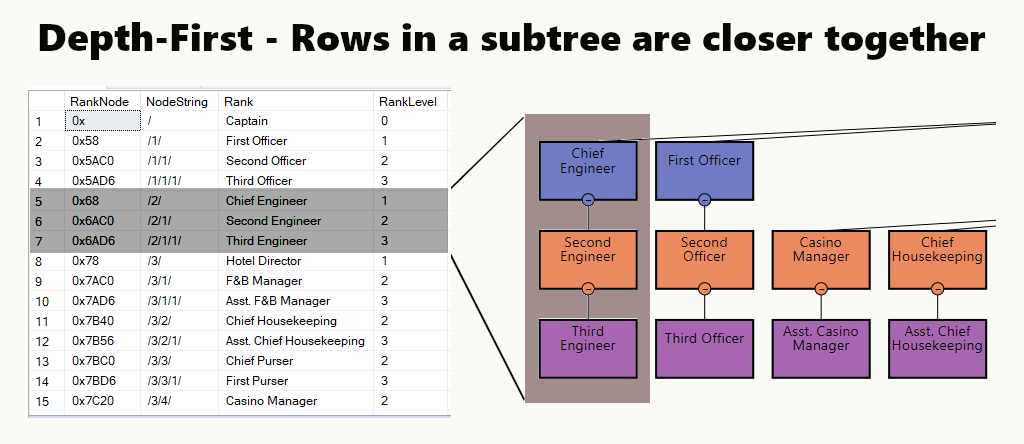
Рис.2. Стратегия индексирования в глубину. На схеме организации выделено поддерево Chief Engineer и результирующий набор. Список отсортирован для каждого поддерева.
В индексе breadth-first строки одного уровня находятся рядом. Это подходит запросам типа найти всех сотрудников, непосредственно подчиняющиеся руководителю. Если большинство запросов подобно этому, создайте кластеризованный индекс на основе (1) уровня и (2) узла.
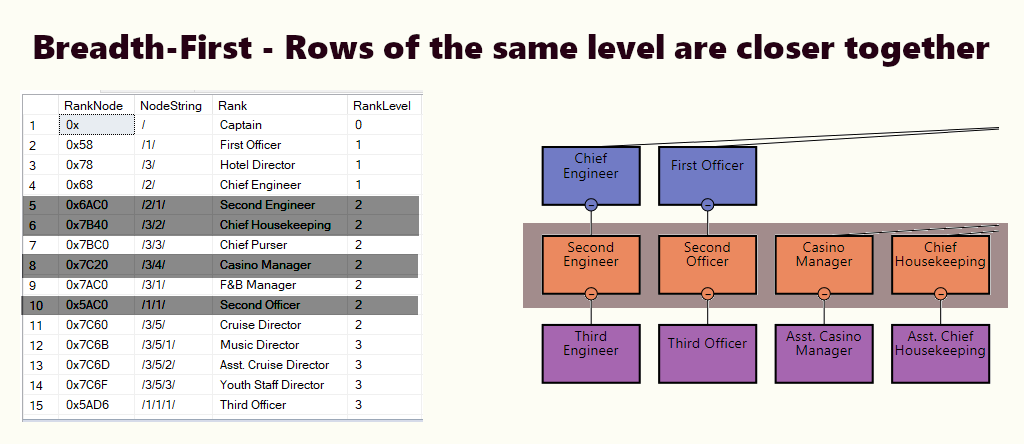
Рис.3: Стратегия индексирования в ширину. На схеме организации выделена часть уровня второго ранга и результирующий набор. Список отсортирован по масштабу.
Нужен ли вам индекс depth-first, breadth-first или же оба, зависит от конкретных требований. Требуется найти баланс между важностью типа запросов и операторов DML, которые вы адресуете к таблице.
К сожалению, использование hierarchyID не поможет решить все проблемы:
Прежде, чем мы продолжим, рассмотрим еще один вопрос. Посмотрите на результирующий набор со строками узлов; легко ли вам визуализировать иерархию?
Что касается меня, то с трудом.
Поэтому мы будем использовать Power BI и Hierarchy Chart от Akvelon, наряду с нашими таблицами базы данных. Они помогут отобразить иерархию в организационной структуре. Я надеюсь, что это упростит работу.
Теперь перейдем к работе.
Вы можете использовать HierarchyID в следующих бизнес-сценариях:
Даже если ваш бизнес-сценарий подобен представленным выше, и вы редко выполняете запросы к разделам иерархии, вам не нужен hierarchyID.
Например, ваша организация формирует платежные ведомости для сотрудников. Нужен ли вам доступ к поддереву для формирования чьей-то ведомости. Определенно нет. Однако если вы начисляете комиссионные людям в многоуровневой маркетинговой системе, это может потребоваться.
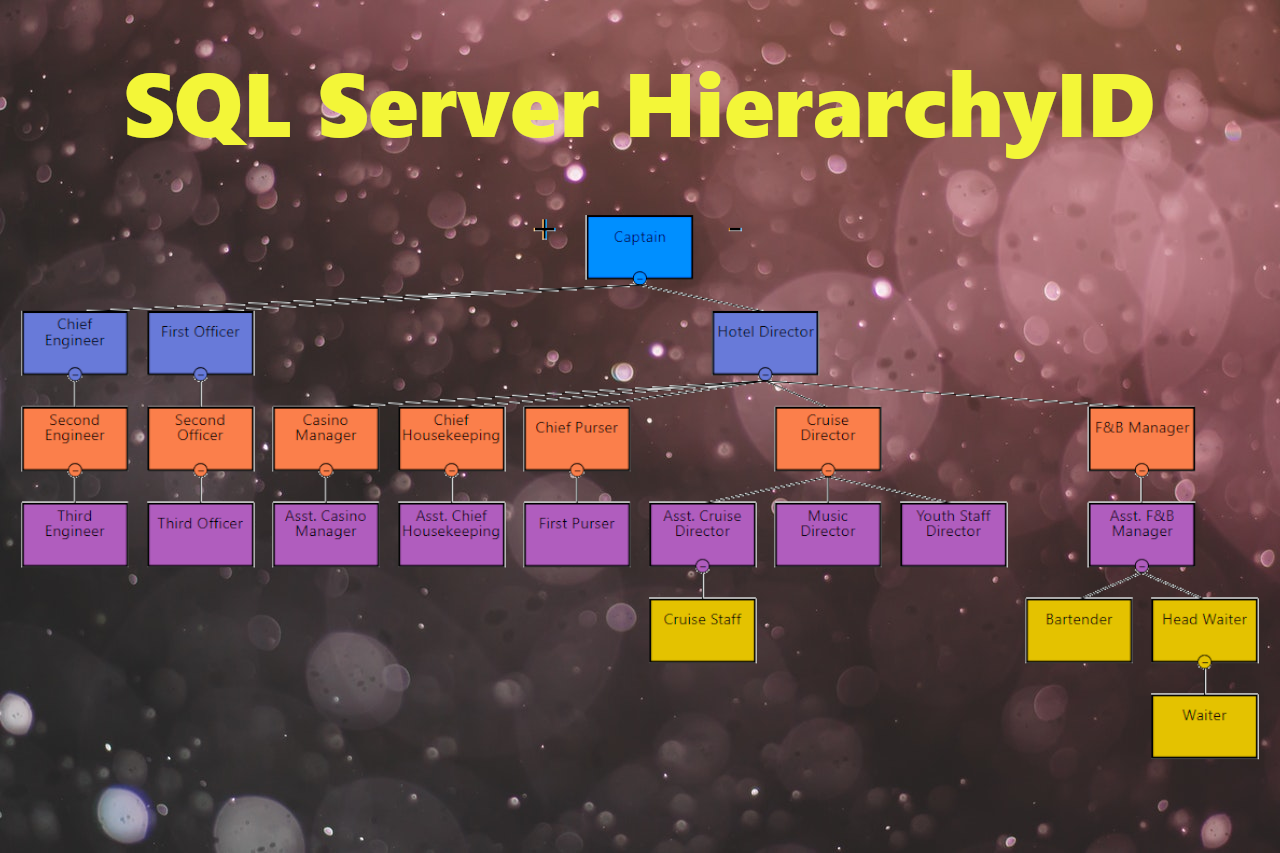
В этой статье мы используем часть структуры организации и цепочку командования на круизном лайнере. Структура была адаптирована из следующей организационной схемы. Посмотрите на рисунок 4 ниже:
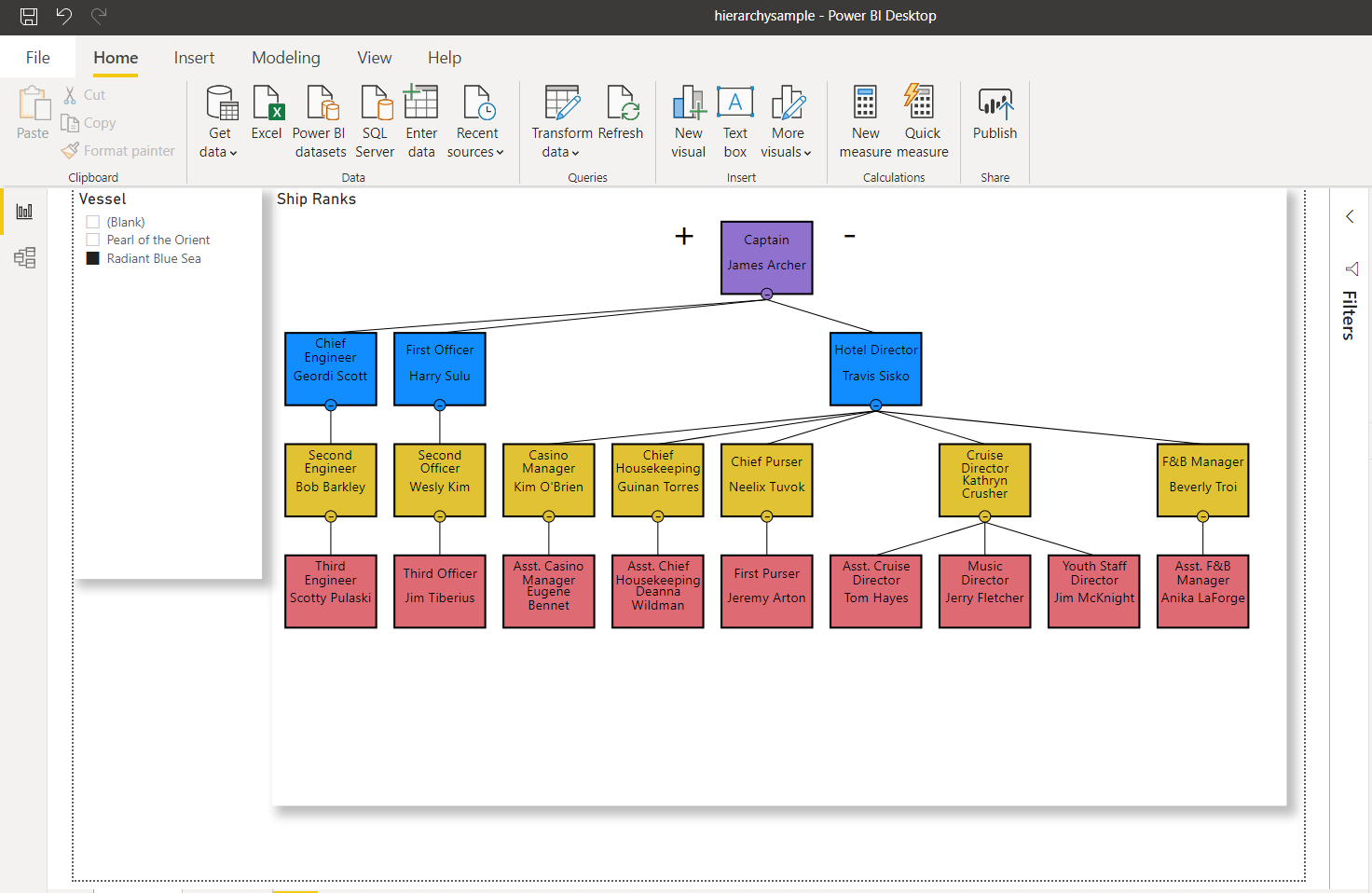
Рис.4: Структура организации типичного круизного лайнера, представленная с помощью Power BI, Hierarchy Chart от Akvelon и SQL Server. Имена вымышлены и не имеют отношения к конкретным людям и судам.
Теперь вы можете визуализировать указанную иерархию. Мы используем здесь повсюду следующие таблицы:
Таблицы имеют следующую структуру:
Первая задача в использовании hierarchyID - это добавление записей в таблицу со столбцом hierarchyID. Это можно сделать двумя способами.
Наиболее быстро вставить данные с hierarchyID можно с использованием строк. Чтобы увидеть это в действии, давайте добавим несколько записей в таблицу Ranks.
Этот код добавляет 20 записей в таблицу Ranks.
Как видно, структура дерева определяется в операторе INSERT. Это довольно легко, когда мы используем строки. Кроме того, SQL Server преобразует их в соответствующие шестнадцатеричные значения.
Использование строк подходит для задачи пополнения исходными данными. В долгосрочной перспективе вам потребуется код для обработки вставки без предоставления строк.
Чтобы это сделать, получим последний узел, используемый родителем или предком. Мы выполним это при помощи функций Max() и GetAncestor(). Вот как это выглядит:
Пояснения к коду:
После добавления записей в вашу таблицу, самое время запросить их. Для это есть 2 способа.
Когда мы ищем сотрудников, непосредственно подчиняющихся управляющему, нам необходимо знать две вещи:
Для первой задачи мы можем использовать нижеприведенный код. На выходе - список сотрудников, подчиняющихся директору гостиницы.
Результат выполнения запроса показан на рисунке 5:
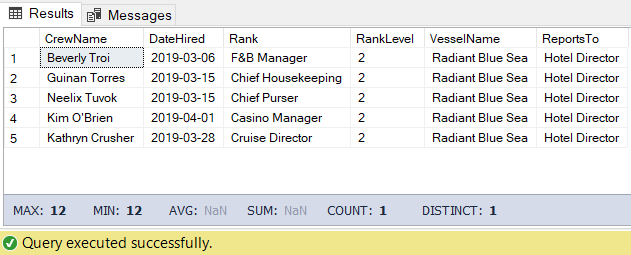
Рис.5: Результирующий набор, полученный для людей, непосредственно подчиняющихся директору отеля
Иногда также требуется получить список потомков и потомков потомков до самого нижнего уровня. Чтобы сделать это, нам необходимо иметь hierarchyID родителя.
Запрос будет похож на предыдущий, но без необходимости получения уровня. Вот пример кода:
Результат ниже.
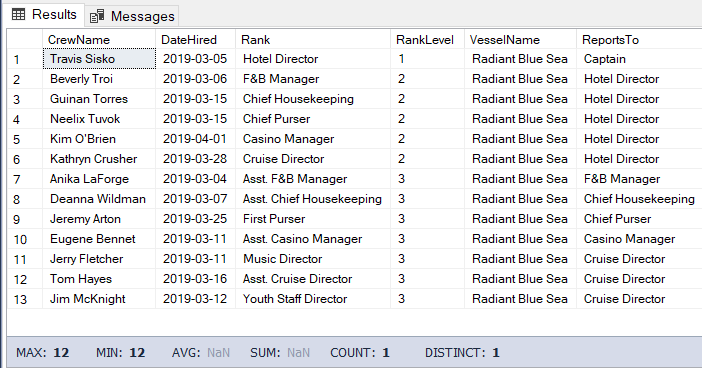
Рис.6: Директор отеля и все подчиненные до последнего уровня
Другой стандартной операцией с иерархическими данными является перемещение потомка или всего поддерева к другому родителю. Однако прежде давайте отметим одну потенциальную проблему:
Вы можете справиться с этой проблемой на уровне схемы базы данных.
Давайте рассмотрим используемую здесь схему.
Вместо определения иерархии в таблице Crew, мы определили её в таблице Ranks. Такой подход отличается от таблицы Employee в учебной базе данных AdventureWorks, и это отличие дает следующие преимущества:
Перейдем теперь к цели этого параграфа. Добавим дочерние узлы к неправильным родителям. Чтобы наглядно представить себе происходящее, обратимся к нижеприведенной иерархии. Обратите внимание на желтые узлы.
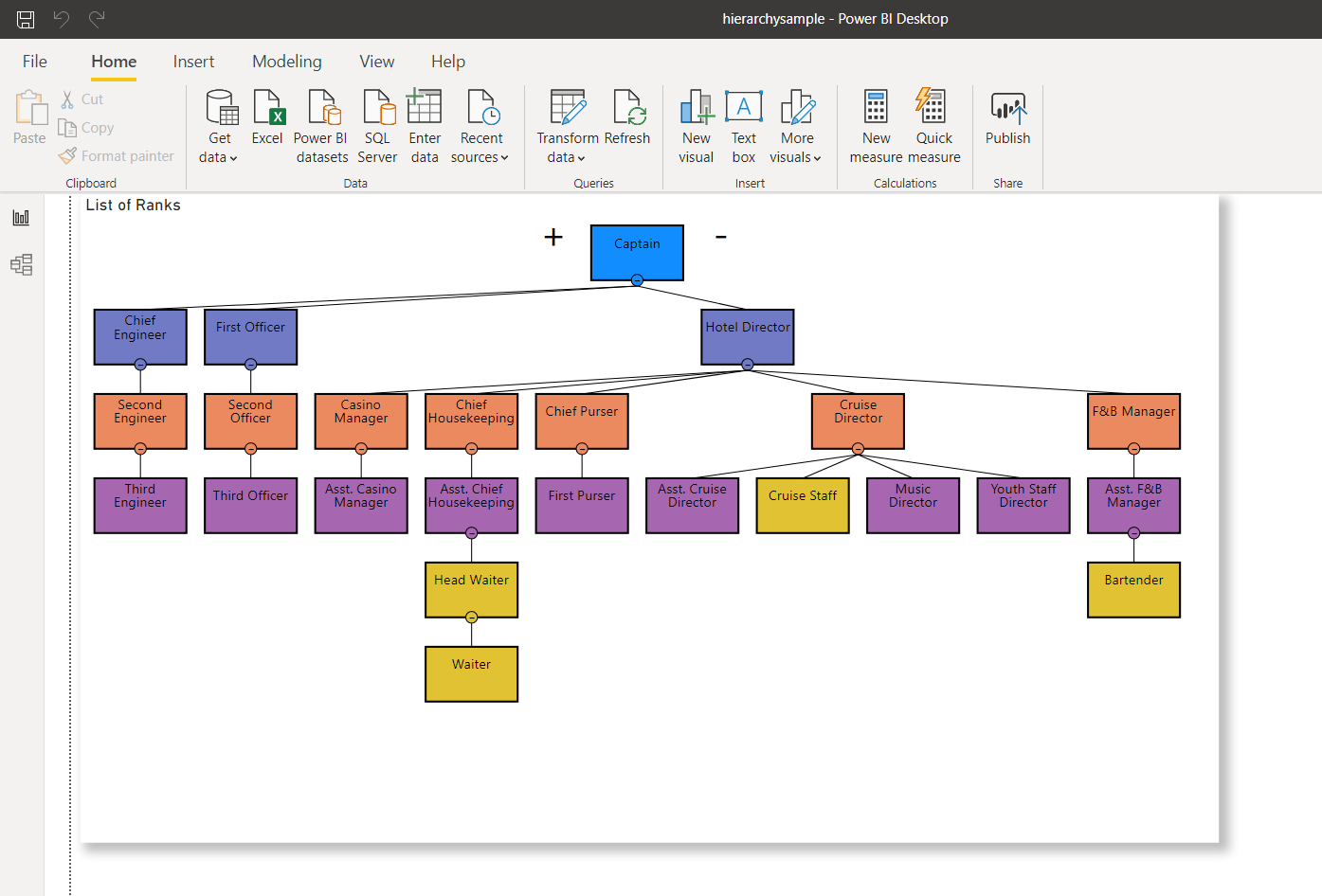
Рис.7: Три желтых узла размещены неправильно в иерархии - Cruise Staff, Head Waiter и Waiter.
Для перемещения дочернего узла требуется:
Начнем с перемещения узла, не имеющего потомков. В примере ниже мы перемещаем Cruise Staff от Cruise Director к Asst. Cruise Director.
Как только узел обновился, для узла будет использоваться новое шестнадцатеричное значение. После обновления моего подключения Power BI к SQL Server схема иерархии изменится следующим образом:
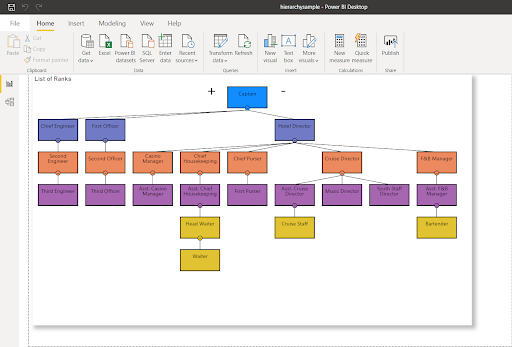
Рис.8: Узел Cruise Staff исправлен и перемещен к надлежащему родителю.
На рисунке 8 Cruise Staff больше не подчиняется Cruise Director - подчитение перешло к Assistant Cruise Director. Сравните с рисунком 7 выше.
Теперь давайте перейдем к следующей стадии и переместим Head Waiter к Assistant F&B Manager.
Тут есть вызов.
Дело в том, что предыдущий код не будет работать с узлом, имеющим даже одного потомка. Мы помним, что перемещение узла требует обновления одного или более дочерних узлов.
Более того, на этом дело не заканчивается. Если новый родитель имеет существующего потомка, мы можем столкнуться с дубликатами значений узлов.
В этом примере мы должны получить такую проблему: Asst. F&B Manager имеет дочерний узел Bartender.
Готовы? Вот код:
В этом примере итерация начинается с необходимости передать узел дочернему элементу на последнем уровне.
После выполнения кода таблица Ranks обновится. И опять, если вы хотите увидеть изменения, обновите отчет в Power BI. Вы увидите следующие изменения:
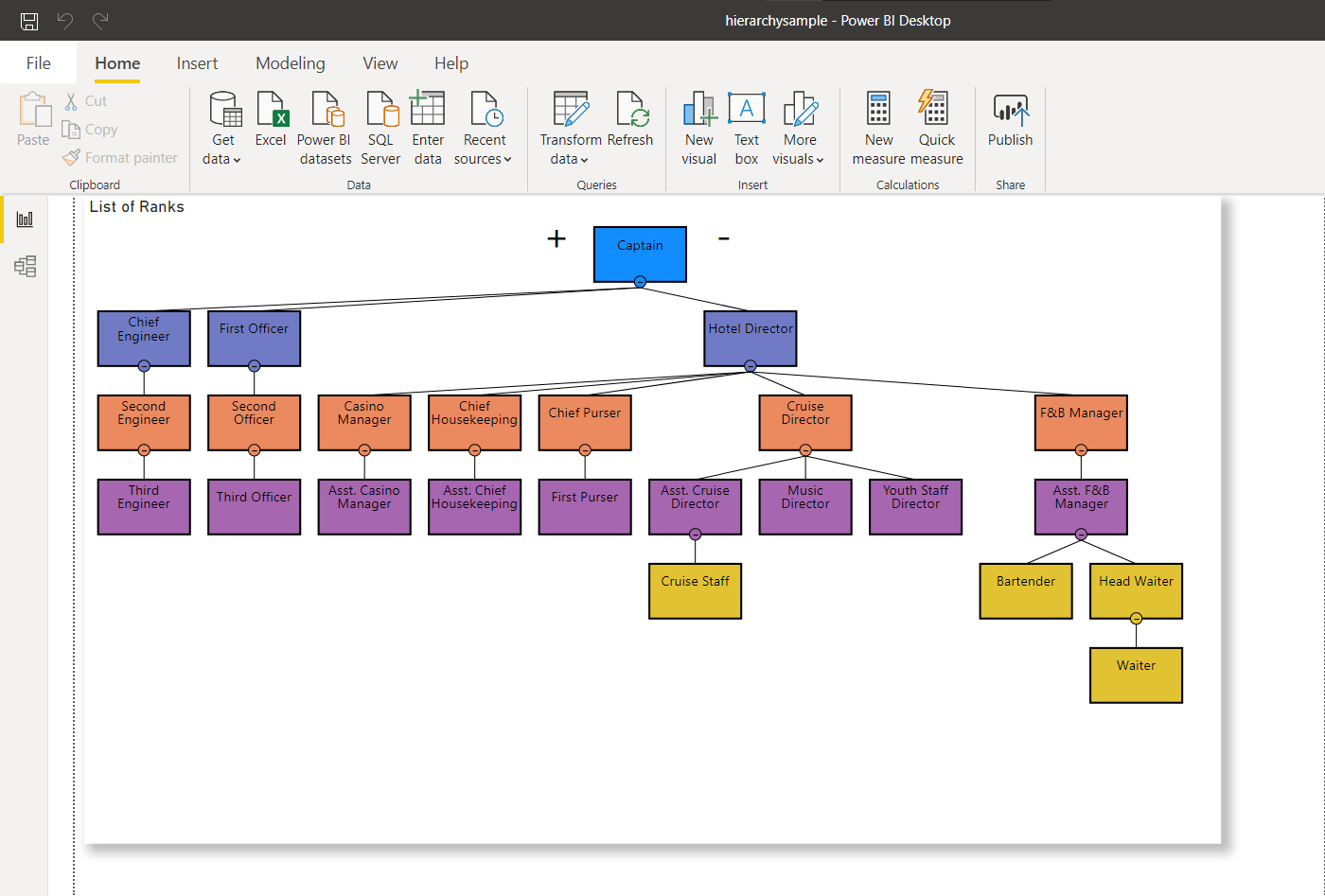
Рис.9: Все дочерние узлы Asst. F&B Manager исправлены
Чтобы убедить кого-нибудь что-нибудь использовать, нужно осознавать выгоды.
Поэтому в этой части мы сравним операторы, использующие те же самые таблицы, приведенные в начале. Один будет использовать hierarchyID, а другой - подход родитель/ребенок. Результирующие наборы будут одинаковы для обоих подходов. Мы ожидаем такие, как на рисунке 6.
Теперь, когда требования уточнены, давайте детально рассмотрим преимущества.
Посмотрите код ниже:
Этот образец требует только значения hierarchyID. Вы можете при желании изменить значение, не меняя запрос.
Теперь сравните оператор для модели родитель/ребенок, дающий тот же самый результат:
Что вы думаете? Пример почти тот же за исключением одного момента.
Предложение WHERE во втором запросе не получится гибко адаптировать, если потребуется другое поддерево.
Сделайте второй запрос достаточно общим, и размер вашего кода увеличится.
Согласно Microsoft, "запросы поддеревьев существенно быстрей с использованием hierarchyID" по сравнению со схемой родитель/потомок. Давайте это проверим.
Мы используем те же самые запросы. Одной из значимых метрик производительности является число логических чтений, которую можно получить с помощью установки SET STATISTICS IO. Она скажет, сколько 8Кб страниц потребуется прочитать SQL Server, чтобы получить нужный нам результат. Чем выше значение, тем к большему числу страниц SQL Server должен получить доступ и прочитать, и тем медленнее выполняется запрос. Выполните SET STATISTICS IO ON, а затем повторно запустите два вышеприведенных запроса. Запрос с меньшим числом логических чтений победит.
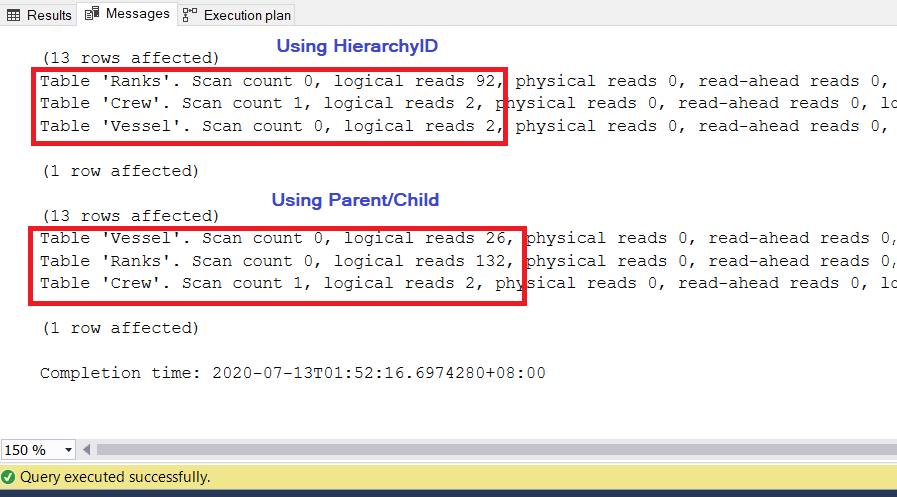
Рис.10: Запрос, использующий hierarchyID выполняется лучше с меньшим числом логических чтений
Как видно на рисунке 10, статистика ввода/вывода для запроса с hierarchyID имеет меньше логических чтений, чем его конкурент родитель/потомок. Обратите внимание на следующие моменты результата:
Килобайты страниц, возможно, сейчас невелики, но мы имеем лишь несколько записей. Тем не менее, это дает нам представление о том, насколько обременительным будет наш запрос на любом сервере. Для улучшения производительности вы можете сделать одно или несколько следующих действий:
Если вы это сделали, и число логических чтений уменьшилось при том же количестве записей, производительность должна улучшиться. Если вы сделаете число логических чтений ниже, чем при использовании hierarchyID, это будет хорошей новостью.
Но зачем обращаться к логическим чтениям, а не к затраченному времени?
Проверка затраченного времени (elapsed time) для обоих запросов с помощью SET STATISTICS TIME ON обнаруживает незначительное расхождение в миллисекундах для нашего небольшого набора данных. Кроме того, ваш сервер разработки может иметь отличную аппаратную конфигурацию, настройки SQL Server и рабочую нагрузку. Затраченное время менее миллисекунды может ввести вас в заблуждение относительно того, быстро выполняется ваш запрос или нет.
SET STATISTICS IO ON не открывает вам вещи, которые происходят "под капотом". В этом параграфе мы выясним, почему SQL Server приходит к этим числам, изучая план выполнения.
Давайте начнем с плана выполнения первого запроса.
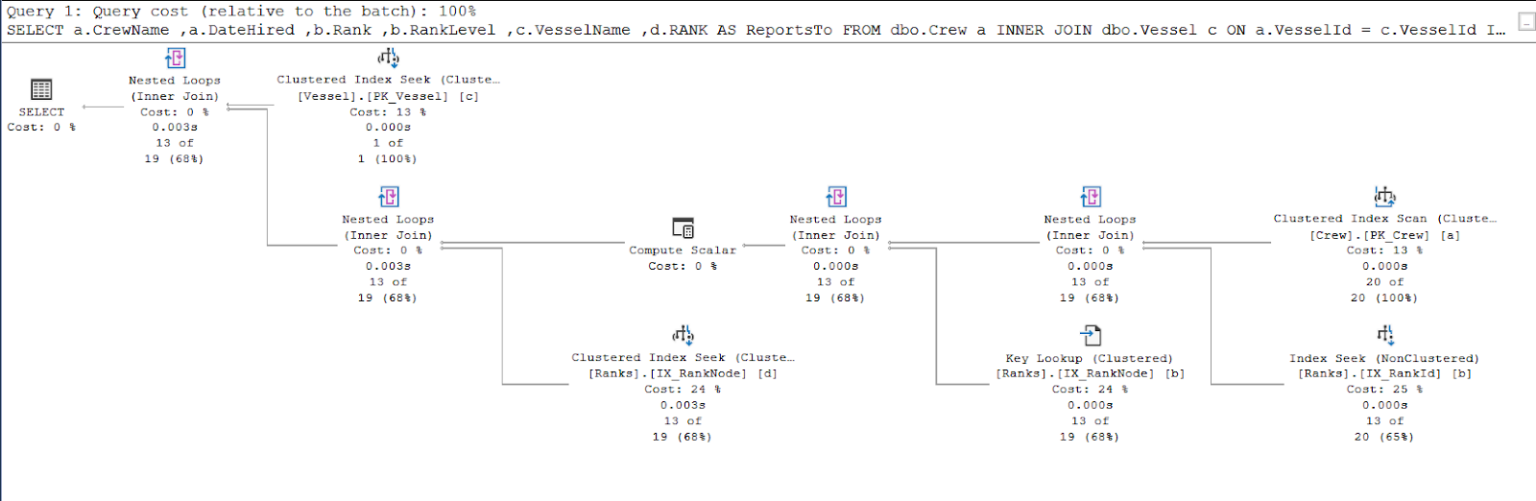
Рис.11: План выполнения первого запроса с hierarchyID
Теперь посмотрите план выполнения второго запроса.
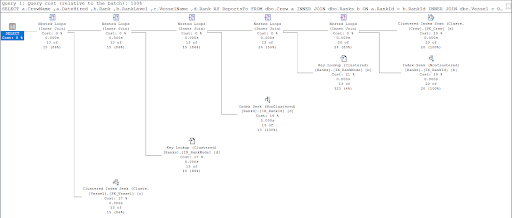
Рис.12: План выполнения второго запроса, использующего модель родитель/ребенок
Сравнивая рисунки 11 и 12, мы видим, что SQL Server требуются дополнительные усилия для получения результата, если вы используете подход родитель/ребенок. За это усложнение отвечает предложение WHERE.
Однако виной всему может быть и структура таблицы. Мы использовали одну и ту же таблицу для обоих подходов: таблица Ranks. Итак, я попытался продублировать таблицу Ranks, но использовать разные кластеризованные индексы, соответствующие каждой процедуре.
В результате использование hierarchyID все еще имеет меньше логических чтений по сравнению с конкурентом родитель/ребенок. Итак, мы доказали, что Microsoft была права, заявляя об этом.
Вот ключевые моменты, относящиеся к hierarchyID:
Схема родитель/ребенок в целом не плоха, и эта статья не для того, чтобы дискредитировать его. Однако расширение кругозора и усвоение новых идей всегда полезно для разработчика.
Признаюсь, что и я не изучал эту возможность, когда она появилась. Однако, когда я впоследствии сделал это, то оценил новинку. Она дает лучше выглядящий код, но далеко не только это. В данной статье у нас будет возможность выяснить все эти великолепные возможности.
Но прежде чем мы углубимся в особенности использования hierarchyID, давайте проясним его смысл и область применения.
Что такое HierarchyID?
HierarchyID - это встроенный тип данных в SQL Server, предназначенный для представления деревьев, которые являются наиболее распространенным типом иерархических данных. Каждый элемент дерева называется узлом. В табличном формате это строка со столбцом типа данных hierarchyID.
Обычно мы проектируем иерархии с помощью таблиц. Столбец ID представляет узел, а другой столбец указывает на родителя. Используя HierarchyID нам потребуется только один столбец типа данных hierarchyID.
Если выполнить запрос к таблице со столбцом hierarchyID, вы увидите шестнадцатеричные числа. Это одно из визуальных представлений узла. Другим представлением является строка:
'/' - указывает на корневой узел;
‘/1/’, ‘/2/’, ‘/3/’ or ‘/n/’ - представляет потомков - прямые потомки от 1 до n;
‘/1/1/’ or ‘/1/2/’ - это потомки потомков или "внуки". Строка типа '/1/2/' означает, что первый потомок от корня имеет двух детей, которые, в свою очередь, являются двумя внуками корня.
Вот пример того, как это выглядит:
В отличие от других типов данных, столбец hierarchyID обладает тем преимуществом, что может иметь встроенные методы. Например, если у вас есть столбец в именем RankNode, вы можете использовать следующий синтаксис:
RankNode.<имя_метода>.Методы HierarchyID
Одним из имеющихся методов является IsDescendantOf. Он возвращает 1, если текущий узел является потомком значения hierarchyID.
Вы можете написать подобный код с использованием этого метода:
SELECT
r.RankNode
,r.Rank
FROM dbo.Ranks r
WHERE r.RankNode.IsDescendantOf(0x58) = 1;Другими методами, используемыми с hierarchyID являются:
- GetRoot - статический метод, который возвращает корень дерева.
- GetDescendant - возвращает дочерний узел родителя.
- GetAncestor - возвращает hierarchyID, представляющий n-го предка заданного узла.
- GetLevel - возвращает целое число, представляющее глубину узла.
- ToString - возвращает строку с логическим представлением узла. ToString вызывается неявно, когда имеет место преобразование из hierarchyID в строковый тип.
- GetReparentedValue - перемещает узел от старого родителя к новому.
- Parse - действует противоположно ToString. Он преобразует строковое представление значения hierarchyID к шестнадцатеричному.
Стратегии индексирования HierarchyID
Чтобы гарантировать максимально быстрое выполнение запросов к таблицам, использующим hierarchyID, вам потребуется проиндексировать столбец. Имеется две стратегии индексирования:
DEPTH-FIRST (сначала в глубину)
В индексе depth-first строки поддерева находятся рядом друг с другом. Это подходит таким запросам, как поиск отделов, их подразделений и сотрудников. Другой пример - управляющий и его подчиненные, которые сохраняются рядом.
В таблице вы можете реализовать индекс depth-first путем создания кластеризованного индекса на узлах. Теперь мы выполняем один из наших примеров именно так.
Рис.2. Стратегия индексирования в глубину. На схеме организации выделено поддерево Chief Engineer и результирующий набор. Список отсортирован для каждого поддерева.
BREADTH-FIRST (сначала в ширину)
В индексе breadth-first строки одного уровня находятся рядом. Это подходит запросам типа найти всех сотрудников, непосредственно подчиняющиеся руководителю. Если большинство запросов подобно этому, создайте кластеризованный индекс на основе (1) уровня и (2) узла.
Рис.3: Стратегия индексирования в ширину. На схеме организации выделена часть уровня второго ранга и результирующий набор. Список отсортирован по масштабу.
Нужен ли вам индекс depth-first, breadth-first или же оба, зависит от конкретных требований. Требуется найти баланс между важностью типа запросов и операторов DML, которые вы адресуете к таблице.
Ограничения HierarchyID
К сожалению, использование hierarchyID не поможет решить все проблемы:
- SQL Server не может угадать родителя ребенка. Вы должны определить дерево в таблице.
- Если вы не используете ограничение уникальности, генерируемое значение hierarchyID может оказаться неуникальным. Решение этой проблемы лежит на разработчике.
- Связь родительского и дочернего узлов не поддерживается по аналогии с ограничением внешнего ключа. Следовательно, перед удалением узла, нужно выполнить запрос на наличие существующих потомков.
Визуализация иерархий
Прежде, чем мы продолжим, рассмотрим еще один вопрос. Посмотрите на результирующий набор со строками узлов; легко ли вам визуализировать иерархию?
Что касается меня, то с трудом.
Поэтому мы будем использовать Power BI и Hierarchy Chart от Akvelon, наряду с нашими таблицами базы данных. Они помогут отобразить иерархию в организационной структуре. Я надеюсь, что это упростит работу.
Теперь перейдем к работе.
Использование HierarchyID
Вы можете использовать HierarchyID в следующих бизнес-сценариях:
- Структура организации
- Папки, подпапки и файлы
- Задачи и подзадачи в проекте
- Страницы и подчиненные страницы вебсайта
- Географические данные со странами, регионами и городами
Даже если ваш бизнес-сценарий подобен представленным выше, и вы редко выполняете запросы к разделам иерархии, вам не нужен hierarchyID.
Например, ваша организация формирует платежные ведомости для сотрудников. Нужен ли вам доступ к поддереву для формирования чьей-то ведомости. Определенно нет. Однако если вы начисляете комиссионные людям в многоуровневой маркетинговой системе, это может потребоваться.
В этой статье мы используем часть структуры организации и цепочку командования на круизном лайнере. Структура была адаптирована из следующей организационной схемы. Посмотрите на рисунок 4 ниже:
Рис.4: Структура организации типичного круизного лайнера, представленная с помощью Power BI, Hierarchy Chart от Akvelon и SQL Server. Имена вымышлены и не имеют отношения к конкретным людям и судам.
Теперь вы можете визуализировать указанную иерархию. Мы используем здесь повсюду следующие таблицы:
- Vessels - таблица для списка круизных судов.
- Ranks - таблица званий экипажа. Тут устанавливается иерархия с помощью hierarchyID.
- Crew - списочный состав экипажа каждого судна и их звания.
Таблицы имеют следующую структуру:
CREATE TABLE [dbo].[Vessel](
[VesselId] [int] IDENTITY(1,1) NOT NULL,
[VesselName] [varchar](20) NOT NULL,
CONSTRAINT [PK_Vessel] PRIMARY KEY CLUSTERED
(
[VesselId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Ranks](
[RankId] [int] IDENTITY(1,1) NOT NULL,
[Rank] [varchar](50) NOT NULL,
[RankNode] [hierarchyid] NOT NULL,
[RankLevel] [smallint] NOT NULL,
[ParentRankId] [int] -- this is redundant but we will use this to compare
-- with parent/child
) ON [PRIMARY]
GO
CREATE UNIQUE NONCLUSTERED INDEX [IX_RankId] ON [dbo].[Ranks]
(
[RankId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE UNIQUE CLUSTERED INDEX [IX_RankNode] ON [dbo].[Ranks]
(
[RankNode] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Crew](
[CrewId] [int] IDENTITY(1,1) NOT NULL,
[CrewName] [varchar](50) NOT NULL,
[DateHired] [date] NOT NULL,
[RankId] [int] NOT NULL,
[VesselId] [int] NOT NULL,
CONSTRAINT [PK_Crew] PRIMARY KEY CLUSTERED
(
[CrewId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Ranks] FOREIGN KEY([RankId])
REFERENCES [dbo].[Ranks] ([RankId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Ranks]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Vessel] FOREIGN KEY([VesselId])
REFERENCES [dbo].[Vessel] ([VesselId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Vessel]
GOВставка данных в таблицы с HierarchyID
Первая задача в использовании hierarchyID - это добавление записей в таблицу со столбцом hierarchyID. Это можно сделать двумя способами.
Использование строк
Наиболее быстро вставить данные с hierarchyID можно с использованием строк. Чтобы увидеть это в действии, давайте добавим несколько записей в таблицу Ranks.
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Captain', '/',0)
,('First Officer','/1/',1)
,('Chief Engineer','/2/',1)
,('Hotel Director','/3/',1)
,('Second Officer','/1/1/',2)
,('Second Engineer','/2/1/',2)
,('F&B Manager','/3/1/',2)
,('Chief Housekeeping','/3/2/',2)
,('Chief Purser','/3/3/',2)
,('Casino Manager','/3/4/',2)
,('Cruise Director','/3/5/',2)
,('Third Officer','/1/1/1/',3)
,('Third Engineer','/2/1/1/',3)
,('Asst. F&B Manager','/3/1/1/',3)
,('Asst. Chief Housekeeping','/3/2/1/',3)
,('First Purser','/3/3/1/',3)
,('Asst. Casino Manager','/3/4/1/',3)
,('Music Director','/3/5/1/',3)
,('Asst. Cruise Director','/3/5/2/',3)
,('Youth Staff Director','/3/5/3/',3)Этот код добавляет 20 записей в таблицу Ranks.
Как видно, структура дерева определяется в операторе INSERT. Это довольно легко, когда мы используем строки. Кроме того, SQL Server преобразует их в соответствующие шестнадцатеричные значения.
Использование Max(), GetAncestor() и GetDescendant()
Использование строк подходит для задачи пополнения исходными данными. В долгосрочной перспективе вам потребуется код для обработки вставки без предоставления строк.
Чтобы это сделать, получим последний узел, используемый родителем или предком. Мы выполним это при помощи функций Max() и GetAncestor(). Вот как это выглядит:
-- добавить запись ранга бармена к Assistant F&B Manager
DECLARE @MaxNode HIERARCHYID
DECLARE @ImmediateSuperior HIERARCHYID = 0x7AD6
SELECT @MaxNode = MAX(RankNode) FROM dbo.Ranks r
WHERE r.RankNode.GetAncestor(1) = @ImmediateSuperior;
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Bartender', @ImmediateSuperior.GetDescendant(@MaxNode,NULL),
@ImmediateSuperior.GetDescendant(@MaxNode, NULL).GetLevel());Пояснения к коду:
- Сначала нам нужна переменная для последнего узла и непосредственный начальник.
- Последний узел вы можем запросить с помощью MAX(RankNode) для указанного родителя или непосредственного начальника. В нашем случае это Assistant F&B Manager с значением узла 0x7AD6.
- Затем, чтобы гарантировать отсутствие появления дубликата потомка, воспользуется @ImmediateSuperior.GetDescendant(@MaxNode, NULL). Значение в @MaxNode - последний потомок. Если это не NULL, GetDescendant() возвращает следующее возможное значение узла.
- Наконец, GetLevel() возвращает уровень вновь созданного узла.
Получение данных
После добавления записей в вашу таблицу, самое время запросить их. Для это есть 2 способа.
Запрос для прямых потомков
Когда мы ищем сотрудников, непосредственно подчиняющихся управляющему, нам необходимо знать две вещи:
- Значение узла управляющего или родителя
- Уровень сотрудника этого управляющего
Для первой задачи мы можем использовать нижеприведенный код. На выходе - список сотрудников, подчиняющихся директору гостиницы.
-- Получить список людей, непосредственно подчиняющихся Hotel Director
DECLARE @Node HIERARCHYID = 0x78 -- узел/hierarchyid директора
DECLARE @Level SMALLINT = @Node.GetLevel()
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1
AND b.RankLevel = @Level + 1 -- добавить 1 к уровню подчиняющихся
-- директоруРезультат выполнения запроса показан на рисунке 5:
Рис.5: Результирующий набор, полученный для людей, непосредственно подчиняющихся директору отеля
Запрос для поддеревьев
Иногда также требуется получить список потомков и потомков потомков до самого нижнего уровня. Чтобы сделать это, нам необходимо иметь hierarchyID родителя.
Запрос будет похож на предыдущий, но без необходимости получения уровня. Вот пример кода:
-- Получить список подчиненных директору отеля
--вплоть до самого нижнего уровня
DECLARE @Node HIERARCHYID = 0x78 -- узел/hierarchyid директора отеля
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1Результат ниже.
Рис.6: Директор отеля и все подчиненные до последнего уровня
Перемещение узлов с HierarchyID
Другой стандартной операцией с иерархическими данными является перемещение потомка или всего поддерева к другому родителю. Однако прежде давайте отметим одну потенциальную проблему:
Потенциальная проблема
- Во-первых, перемещение узла связано с вводом/выводом. Насколько часто вы перемещаете узлы может стать решающим фактором, если вы используете hierarchyID или обычную схему родитель/потомок.
- Во-вторых, перемещение узла в схеме родитель/потомок приводит к обновлению одной строки. В то же время, когда вы перемещаете узел с hierarchyID, обновление затрагивает одну или более строк. Число задействованных строк зависит от глубины уровня иерархии. Это может вызвать серьезные проблемы с производительностью.
Решение
Вы можете справиться с этой проблемой на уровне схемы базы данных.
Давайте рассмотрим используемую здесь схему.
Вместо определения иерархии в таблице Crew, мы определили её в таблице Ranks. Такой подход отличается от таблицы Employee в учебной базе данных AdventureWorks, и это отличие дает следующие преимущества:
- Члены команды перемещаются более часто, чем их должность на судне. Эта схема уменьшит перемещение узлов в иерархии. Как следствие, это минимизирует описанную выше проблему.
- Определение более одной иерархии в таблице Crew усложняет дело, т.к. два судна должны иметь двух капитанов. В результате имеем два корневых узла.
- Если вам потребуется вывести все должности с указанием соответствующего члена команды, вы можете использовать LEFT JOIN. Если на борту нет никого в этой должности, будет получена пустая ячейка для этой позиции.
Перейдем теперь к цели этого параграфа. Добавим дочерние узлы к неправильным родителям. Чтобы наглядно представить себе происходящее, обратимся к нижеприведенной иерархии. Обратите внимание на желтые узлы.
Рис.7: Три желтых узла размещены неправильно в иерархии - Cruise Staff, Head Waiter и Waiter.
Перемещение узла, не имеющего потомков
Для перемещения дочернего узла требуется:
- Определить hierarchyID дочернего узла, который требуется переместить.
- Определить hierarchyID старого родителя.
- Определить hierarchyID нового родителя.
- Использовать UPDATE совместно с GetReparentedValue() для физического перемещения узла.
Начнем с перемещения узла, не имеющего потомков. В примере ниже мы перемещаем Cruise Staff от Cruise Director к Asst. Cruise Director.
-- Перемещение узла без потомков
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 24 -- cruise staff
SELECT @OldParent = @NodeToMove.GetAncestor(1)
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 19 -- assistant cruise director
UPDATE dbo.Ranks
SET RankNode = @NodeToMove.GetReparentedValue(@OldParent,@NewParent)
WHERE RankNode = @NodeToMoveКак только узел обновился, для узла будет использоваться новое шестнадцатеричное значение. После обновления моего подключения Power BI к SQL Server схема иерархии изменится следующим образом:
Рис.8: Узел Cruise Staff исправлен и перемещен к надлежащему родителю.
На рисунке 8 Cruise Staff больше не подчиняется Cruise Director - подчитение перешло к Assistant Cruise Director. Сравните с рисунком 7 выше.
Теперь давайте перейдем к следующей стадии и переместим Head Waiter к Assistant F&B Manager.
Перемещение узла с потомком
Тут есть вызов.
Дело в том, что предыдущий код не будет работать с узлом, имеющим даже одного потомка. Мы помним, что перемещение узла требует обновления одного или более дочерних узлов.
Более того, на этом дело не заканчивается. Если новый родитель имеет существующего потомка, мы можем столкнуться с дубликатами значений узлов.
В этом примере мы должны получить такую проблему: Asst. F&B Manager имеет дочерний узел Bartender.
Готовы? Вот код:
-- Перемещаем узел с по меньшей мере одним потомком
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 22 -- head waiter
SELECT @OldParent = @NodeToMove.GetAncestor(1) -- старый родитель для head waiter
--> asst chief housekeeping
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 14 -- assistant f&b manager
DECLARE children_cursor CURSOR FOR
SELECT RankNode FROM dbo.Ranks r
WHERE RankNode.GetAncestor(1) = @OldParent;
DECLARE @ChildId hierarchyid;
OPEN children_cursor
FETCH NEXT FROM children_cursor INTO @ChildId;
WHILE @@FETCH_STATUS = 0
BEGIN
START:
DECLARE @NewId hierarchyid;
SELECT @NewId = @NewParent.GetDescendant(MAX(RankNode), NULL)
FROM dbo.Ranks r WHERE RankNode.GetAncestor(1) = @NewParent; -- гарантирует
-- получение нового идентификатора на случай,
-- если имеется потомок
UPDATE dbo.Ranks
SET RankNode = RankNode.GetReparentedValue(@ChildId, @NewId)
WHERE RankNode.IsDescendantOf(@ChildId) = 1;
IF @@error <> 0 GOTO START -- При ошибке повторить
FETCH NEXT FROM children_cursor INTO @ChildId;
END
CLOSE children_cursor;
DEALLOCATE children_cursor;В этом примере итерация начинается с необходимости передать узел дочернему элементу на последнем уровне.
После выполнения кода таблица Ranks обновится. И опять, если вы хотите увидеть изменения, обновите отчет в Power BI. Вы увидите следующие изменения:
Рис.9: Все дочерние узлы Asst. F&B Manager исправлены
Преимущества использования HierarchyID по сравнению с моделью родитель/ребенок
Чтобы убедить кого-нибудь что-нибудь использовать, нужно осознавать выгоды.
Поэтому в этой части мы сравним операторы, использующие те же самые таблицы, приведенные в начале. Один будет использовать hierarchyID, а другой - подход родитель/ребенок. Результирующие наборы будут одинаковы для обоих подходов. Мы ожидаем такие, как на рисунке 6.
Теперь, когда требования уточнены, давайте детально рассмотрим преимущества.
Упрощение кода
Посмотрите код ниже:
-- список всех подчиненных Hotel Director
-- с использованием hierarchyID
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.RANK AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON d.RankNode = b.RankNode.GetAncestor(1)
WHERE a.VesselId = 1
AND b.RankNode.IsDescendantOf(0x78)=1Этот образец требует только значения hierarchyID. Вы можете при желании изменить значение, не меняя запрос.
Теперь сравните оператор для модели родитель/ребенок, дающий тот же самый результат:
-- список всех подчиненных Hotel Director
-- с использованием модели родитель/ребенок
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.Rank AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON b.RankParentId = d.RankId
WHERE a.VesselId = 1
AND (b.RankID = 4) OR (b.RankParentID = 4 OR b.RankParentId >= 7)Что вы думаете? Пример почти тот же за исключением одного момента.
Предложение WHERE во втором запросе не получится гибко адаптировать, если потребуется другое поддерево.
Сделайте второй запрос достаточно общим, и размер вашего кода увеличится.
Более быстрое выполнение
Согласно Microsoft, "запросы поддеревьев существенно быстрей с использованием hierarchyID" по сравнению со схемой родитель/потомок. Давайте это проверим.
Мы используем те же самые запросы. Одной из значимых метрик производительности является число логических чтений, которую можно получить с помощью установки SET STATISTICS IO. Она скажет, сколько 8Кб страниц потребуется прочитать SQL Server, чтобы получить нужный нам результат. Чем выше значение, тем к большему числу страниц SQL Server должен получить доступ и прочитать, и тем медленнее выполняется запрос. Выполните SET STATISTICS IO ON, а затем повторно запустите два вышеприведенных запроса. Запрос с меньшим числом логических чтений победит.
Рис.10: Запрос, использующий hierarchyID выполняется лучше с меньшим числом логических чтений
Анализ
Как видно на рисунке 10, статистика ввода/вывода для запроса с hierarchyID имеет меньше логических чтений, чем его конкурент родитель/потомок. Обратите внимание на следующие моменты результата:
- Таблица Vessel самая заметная из трех таблиц. Использование hierarchyID требует только 2*8Кб=16Кб, которые SQL Server должен прочитать из кэша (памяти). Между тем, использование схемы родитель/потомок требует чтения 26*8Кб=208Кб - существенно выше, чем при использовании hierarchyID.
- Таблица Ranks, которая включает определение иерархий, требует 92*8Кб=736Кб. С другой стороны, использование схемы родитель/потомок требует 132*8Кб=1056Кб.
- Таблица Crew требует 2*8Кб=16Кб для обоих подходов.
Килобайты страниц, возможно, сейчас невелики, но мы имеем лишь несколько записей. Тем не менее, это дает нам представление о том, насколько обременительным будет наш запрос на любом сервере. Для улучшения производительности вы можете сделать одно или несколько следующих действий:
- Добавить подходящие индексы
- Реструктурировать запрос
- обновить статистику
Если вы это сделали, и число логических чтений уменьшилось при том же количестве записей, производительность должна улучшиться. Если вы сделаете число логических чтений ниже, чем при использовании hierarchyID, это будет хорошей новостью.
Но зачем обращаться к логическим чтениям, а не к затраченному времени?
Проверка затраченного времени (elapsed time) для обоих запросов с помощью SET STATISTICS TIME ON обнаруживает незначительное расхождение в миллисекундах для нашего небольшого набора данных. Кроме того, ваш сервер разработки может иметь отличную аппаратную конфигурацию, настройки SQL Server и рабочую нагрузку. Затраченное время менее миллисекунды может ввести вас в заблуждение относительно того, быстро выполняется ваш запрос или нет.
Пошли дальше
SET STATISTICS IO ON не открывает вам вещи, которые происходят "под капотом". В этом параграфе мы выясним, почему SQL Server приходит к этим числам, изучая план выполнения.
Давайте начнем с плана выполнения первого запроса.
Рис.11: План выполнения первого запроса с hierarchyID
Теперь посмотрите план выполнения второго запроса.
Рис.12: План выполнения второго запроса, использующего модель родитель/ребенок
Сравнивая рисунки 11 и 12, мы видим, что SQL Server требуются дополнительные усилия для получения результата, если вы используете подход родитель/ребенок. За это усложнение отвечает предложение WHERE.
Однако виной всему может быть и структура таблицы. Мы использовали одну и ту же таблицу для обоих подходов: таблица Ranks. Итак, я попытался продублировать таблицу Ranks, но использовать разные кластеризованные индексы, соответствующие каждой процедуре.
В результате использование hierarchyID все еще имеет меньше логических чтений по сравнению с конкурентом родитель/ребенок. Итак, мы доказали, что Microsoft была права, заявляя об этом.
Заключение
Вот ключевые моменты, относящиеся к hierarchyID:
- hierarchyID - это встроенный тип данных, предназначенный для оптимального представления деревьев, которые являются наиболее общим представлением иерархических данных.
- Каждый элемент в дереве является узлом, а значения hierarchyID могут представляться в шестнадцатеричном или строковом форматах.
- hierarchyID применим для данных организационных структур, задач проекта, географических данных и тому подобное.
- Имеются методы для перемещения и манипуляции иерархическими данными, такие как GetAncestor(), GetDescendant(). GetLevel(), GetReparentedValue().
- Удобный способ запрашивать иерархические данные - получение прямых потомков узла или получение поддеревьев узла.
- Использование hierarchyID для запроса поддеревьев не только упрощает код, но и является более производительным способом по сравнению с подходом родитель/ребенок.
Схема родитель/ребенок в целом не плоха, и эта статья не для того, чтобы дискредитировать его. Однако расширение кругозора и усвоение новых идей всегда полезно для разработчика.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой