
Режимы хранилища SQL Server - выбор между построчным и поколоночным хранением
Пересказ статьи Jared Westover. SQL Server Storage Modes - Choosing Rowstore or Columnstore
Я слышал, что SQL Server описывают как приложение, имеющее фут в ширину и милю в глубину. Я думаю, что мог бы привести аргумент в пользу 10 миль в глубину. Есть несколько существенных моментов, о которых должен знать инженер данных. Например, знаете ли вы, что есть два режима хранения записей в SQL Server? Если вы собираетесь на интервью или проектируете архитектуру базы данных вашего следующего приложения, выходите на свет. Как говорил Уоррен Баффетт, "чем больше вы учитесь, тем больше зарабатываете".
В этом руководстве мы рассмотрим два режима хранения записей на страницах данных. Начнем с подробного описания каждого режима, а затем рассмотрим различные ситуации, когда вам потребуется сделать выбор в пользу того или иного решения. К концу руководства вы будете на пути к тому, чтобы сделать лучший выбор на сегодняшний день при проектировании базы данных.
Два режима хранения в SQL Server
Когда речь идет о SQL Server, часто приходится слышать о том, что режимами хранения данных являются кучи или кластеризованный индекс. Здесь же я говорю о том, как SQL Server хранит записи на страницах внешней памяти. С этой точки зрения двумя режимами хранения являются построчное (rowstore) и поколоночное (columnstore).
Почувствуйте разницу
Почему важно знать, чем они отличаются? По меньшей мере, понимание основ позволяет вам выбрать лучшее решение для вашей таблицы и рабочей нагрузки на базу данных. Кроме того, это полезно знать, если вы являетесь консультантом или претендуете на роль инженера данных. Давайте начнем разбираться в этом детально.
Рассмотрение построчного хранения
Наиболее распространенным типом хранения записей является построчный. Это ваш традиционный метод, при котором SQL Server хранит строки или записи на 8Кб странице данных. Microsoft определяет построчное хранение как данные, логически организованные как таблицы со строками и столбцами и физически хранимые в построчном формате. Я не знаю, существовал ли термин "построчное хранения" до того, как появилось поколоночное хранение, хотя бы в мире SQL Server. Ниже я привожу простую иллюстрацию того, как SQL Server хранит записи в традиционной построчной манере. Скажем, мы хотим создать таблицу, содержащую следующие значения.
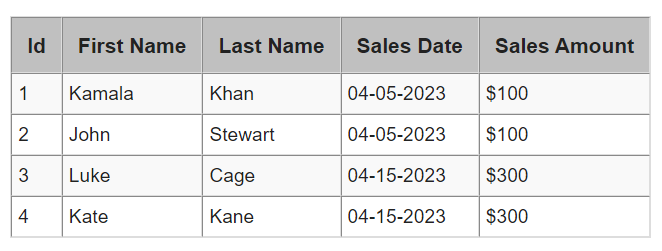
Вот синтаксис T-SQL для создания и заполнения этой таблицы:
CREATE TABLE dbo.Sales
(
Id INT NOT NULL,
FirstName VARCHAR(50) NOT NULL,
LastName VARCHAR(50) NOT NULL,
SalesDate DATE NOT NULL,
SalesAmount DECIMAL(10, 2) NOT NULL,
CONSTRAINT PK_Sales_Id
PRIMARY KEY CLUSTERED (Id)
);
GO
INSERT INTO dbo.Sales
(
Id,
FirstName,
LastName,
SalesDate,
SalesAmount
)
VALUES
(1, 'Kamala', 'Khan', '2023-04-05', 100.00),
(2, 'John', 'Stewart', '2023-04-05', 100.00),
(3, 'Luke', 'Cage', '2023-04-15', 300.00),
(4, 'Kate', 'Kane', '2023-04-15', 300.00);Как может выглядеть хранение записей на страницах данных, показано на рисунке ниже. Конечно, мы можем хранить более одной записи на странице.

В SQL Server построчное хранение было единственным методом до выпуска 2012. Для тех, кто хорошо разбирается в columnstore, это произошло намного раньше, чем когда этот метод стал стабильным. Тем не менее, Microsoft начал производить значительные улучшения в поколоночном хранении, начиная с SQL Server 2016. Возможность иметь некластеризованный обновляемый поколоночный индекс стал для меня главной причиной апгрейда, наряду с появлением хранилища запросов.
Когда использовать построчные индексы
Если ваша рабочая нагрузка требует быстрых выборок, вставок, обновления и удаления, то построчное хранение - правильный выбор. Например, вы используете традиционную OLTP систему, работающую с заказами клиентов. Если клиенты размещают заказы на сайте, только незначительное число транзакций, как правило, будет иметь место в каждый момент времени. В этом случае построчное хранение обеспечит наилучшую производительность запросов.
Размер таблицы также является существенным фактором, который следует иметь в виду. При работе с таблицами, содержащих менее пары миллионов строк, я бы даже не рассматривал вариант использования поколоночного хранения. Вы не увидите какого-нибудь заметного преимущества, если, по моему опыту, таблица не содержит, по крайней мере, 3-5 миллионов строк.
Рассмотрение поколоночных индексов в SQL Server
Теперь перейдем к менее используемому режиму хранения, поколоночному. Он впервые появился в SQL Server 2012 с ограниченной функциональностью. Microsoft определяет поколоночное хранение данных на логическом уровне в виде таблицы со строками и столбцами, но физически хранящиеся в поколоночном формате. Начиная с SQL Server 2016, имеется два доступных варианта - кластеризованный и некластеризованный.
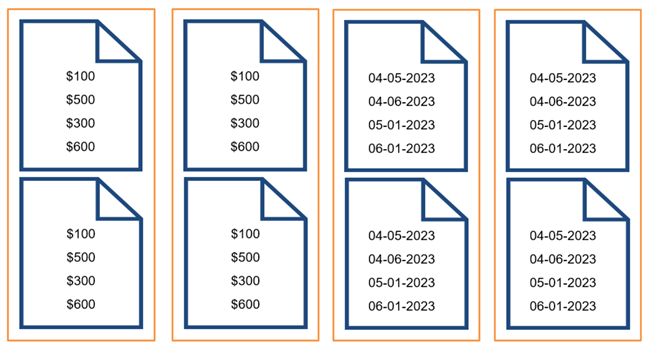
Используя ту же таблицу, что и ранее, ниже иллюстрируется, как SQL Server хранит группы, содержащих порядка миллиона строк в сжатых сегментах. Давайте представим, что наша таблица содержит несколько миллионов строк. Для нескольких столбцов множество этих значений повторяется. Например, вы могли иметь миллион строк со стоимостью продажи (SalesAmount) $100.
CREATE NONCLUSTERED COLUMNSTORE INDEX NCCS_SalesAmount_SalesDate
ON dbo.Sales (
SalesAmount,
SalesDate
);
Поколоночное хранение прошло долгий путь с момента своего зарождения. Изначально вы не могли обновлять таблицу с поколоночным индексом. Стандартный метод, который использовали люди для обновления, заключался в удалении или отключения индекса, выполнения модификаций с последующей перестройкой индекса. Довольно хлопотно. Если вы не интересовались поколоночным хранением после этого релиза, обратитесь к этой статье Microsoft по поводу новых возможностей. По умолчанию Azure Synapse использует кластеризованные поколоночные индексы как табличную структуру.
Когда использовать поколоночное хранение
В основном поколоночное хранение прекрасно себя ведет при выполнении аналитических запросов, охватывающих большое число строк. Поскольку столбцы хранятся порознь, вы можете получить значительный рост производительности в силу развитых методов сжатия. Представьте себе, что целочисленный столбец, являющийся частью таблицы с миллиардом строк, может содержать только десяток тысяч уникальных значений. Представьте размещение всех этих данных в кэше и выполнение с ними некоторого агрегирующего действия.
Выбор режима
Итак, какой метод хранения следует выбрать? Мы можем ответить на этот вопрос словами "это зависит от". Однако этого не вполне достаточно. Вам необходимо понимать, от чего зависит ответ. Для большинства баз данных и таблиц в обычной транзакционной среде вы захотите придерживаться построчного хранения. Даже при этом вы можете применять сжатие строк и данных, значительно улучшая производительность на больших таблицах.
Если вам требуется хранилище данных (ХД) или смешанная среда, рассмотрите вариант поколоночного хранения. Если таблица содержит менее двух миллионов строк, я бы не использовал поколоночное хранение. Я ошибочно применял поколоночное хранения в подобных таблицах и не видел преимуществ, а лишь дополнительные накладные расходы. Однако прирост производительности может быть ошеломляющим, если таблица хорошо подходит для columnstore.
Ключевые моменты
- Построчное и поколоночное хранение - это два метода размещения записей на страницах данных.
- Microsoft впервые ввел поколоночное хранение в SQL Server 2012, но произвел объемные улучшения к 2016, включая возможность добавления некластеризованного поколоночного индекса поверх таблицы с построчным хранением.
- Построчное хранение - это традиционный метод, который хорошо работает в большинстве транзакционных баз данных.
- Поколоночное хранение хорошо работает, когда таблицы содержат более трех миллионов строк, т.е. больших таблиц. Подумайте о гибридной транзакционной системе, когда важна аналитика в реальном времени и требуется прирост производительности.
- Правило большого пальца: Если ваша таблица содержит менее трех миллионов строк, откажитесь совсем от поколоночного хранения. Подождите, так таблицы могут только начинать расти.
Ссылки по теме
1. Сканирование поколоночного индекса
2. Все, что вам нужно знать о поколоночных индексах, в одной статье
3. Почему народ не использует индексы поколоночного хранения?
4. Поколоночные индексы - что это?
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой