
Поколоночные индексы - что это?
Пересказ статьи Monica Rathbun. What are Columnstore Indexes?
Майкрософт продолжает повышать производительность SQL Server, вводя новые возможности. В этой статье объясняется как работать с индексами поколоночного хранения - отличным от построчного способом хранить таблицы, который значительно улучшает производительность при определенной рабочей нагрузке.
Теперь я признаю, что когда индексы поколоночного хранения впервые появились, я нашла их пугающими. В то время вы не могли обновить таблицу с поколоночным индексом без его предварительного удаления. К счастью, с тех пор произошло много изменений к лучшему. Для меня всякое упоминание поколоночного хранения давало сигнал тревоги, говорящий "погоди, остановись, это слишком сложно." Поэтому я постараюсь упростить эту возможность для вас. Такие индексы очень полезны при работе с данными хранилищ и большими таблицами. Они улучшают производительность некоторых запросов в 10 раз, поэтому знание о них и понимание, как они работают, существенно, если вы работаете в области больших масштабируемых данных. На их изучение стоит потратить время.
Архитектура индексов поколоночного хранения
Сначала необходимо усвоить терминологию и разницу между индексом поколоночного хранения и индексом построчного хранения (обычный способ, который мы все используем). Начну с терминологии.
Поколоночное хранение просто означает новый способ хранения данных в индексе. Вместо обычных индексов Построчного хранения или B-Tree, когда данные логически и физически организуются и сохраняются как таблица со строками и столбцами, данные в индексах поколоночного хранения физически сохраняются в столбцах, а логически организуются в строках и столбцах. Вместо сохранения всей строки или строк на странице, на странице хранится один столбец из множества строк. Это то различие в архитектуре, которое обеспечивает индексу поколоночного хранения очень высокий уровень сжатия наряду с уменьшением занимаемого пространства и существенным улучшением производительности чтения.
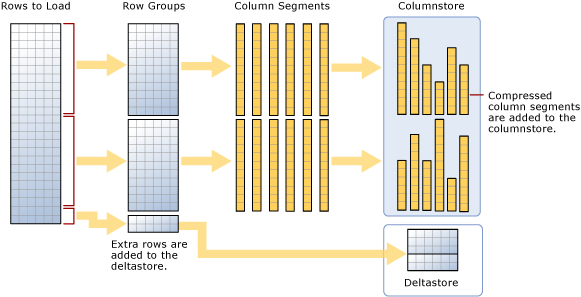
Индекс работает, нарезая данные на сжимаемые сегменты. Берется группа строк - минимум 102400 строк и максимум более 1 миллиона - называемая строковой группой, которая затем преобразуется в колоночные сегменты. Эти сегменты являются базовыми единицами хранения в поколоночном индексе, как показано ниже. Я понимаю, что без картинки трудно понять сказанное.
 (Рисунок от Майкрософт)
(Рисунок от Майкрософт)
Представьте, что это таблица с 2.1 миллионами строк и шестью столбцами. Это означает, что имеется две строковых группы по 1048576 строк в каждой плюс остаток из 2848 строк, который называется дельта-группой. Поскольку каждая строковая группа содержит минимум 102400 строк, группа строк дельта используется для хранения всех оставшихся индексных записей, пока их не наберется для создания еще одной строковой группы. Вы можете иметь множество групп строк дельта, дожидающихся перемещения в хранилище столбцов. Множество групп дельта хранятся в дельта-хранилище, и оно фактически представляет собой индекс B-tree, использующийся дополнительно к хранилищу столбцов. В идеале в вашем индексе должны быть группы строк, содержащие около 1 миллиона строк, чтобы уменьшить накладные расходы на операции сканирования.
Следующий шаг более сложный, этот процесс, который запускает перемещение групп строк дельта из дельта-хранилища в индекс поколоночного хранения, называется процессом перемещения кортежей (tuple-mover process). Он проверяет, что группы закрыты, т.е. группа содержит максимум 1 миллион записей и готова для сжатия и добавления в индекс. Как показано на картинке, индекс поколоночного хранения теперь содержит две строковые группы, которые затем делятся на столбцовые сегменты для каждого столбца таблицы. Это создает шесть столбиков по 1 миллиону строк на строковую группу, что в сумме дает 12 столбцовых сегментов. В чем смысл? Это именно те столбцовые сегменты, которые сжимаются порознь для записи на диск. Движок берет эти столбики и использует их для очень быстрого параллельного сканирования данных. Вы также можете вызвать процесс перемещения кортежей, выполнив перестройку вашего поколоночного индекса.
Для более быстрого доступа к данным, только значения Min и Max для группы строк сохраняются в заголовке страницы. Помимо этого, обработка запроса, относящаяся к хранилищу столбцов, использует пакетный режим (Batch mode), позволяющий движку обрабатывать множество строк одновременно. Это также позволяет в некоторых случаях обрабатывать строки исключительно быстро, давая выигрыш в производительности в 2-4 раза при обработке отдельного запроса. Например, если вы выполняете агрегацию, это происходит очень быстро, т.к. только агрегируемая строка считывается в память, и, используя группы строк, движок может пакетно обработать группы в 1 миллион строк. В SQL Server 2019 пакетный режим также будет введен для некоторых индексов хранилища строк и планов выполнения.
Другим интересным различием между индексами поколоночного хранения и индексами B-tree является то, что поколоночные индексы не имеют ключей. Вы можете также добавить все столбцы таблицы, если это позволяет тип данных, в некластеризованный поколоночный индекс. И здесь нет понятия включенных (included) столбцов. Это принципиально новый способ мышления, если вы привыкли настраивать традиционные индексы.
Пример поколоночного хранения
Теперь, я надеюсь, вы понимаете в общих чертах, что представляет собой индекс поколоночного хранения. Давайте посмотрим, как его создать, узнаем, какие ограничения имеются при использовании этих индексов, а также увидим индекс в действии по сравнению с построчным индексом.
В примере будет использоваться база данных AdventureworksDW2016CTP3 и таблица FactResellerSalesXL (см. скрипт ниже), в которой содержится 11,6 миллионов строк. Простой запрос будет выбирать ProductKey и возвращать некоторые агрегаты, сгруппированные по различным ключам продуктов.
USE [AdventureworksDW2016CTP3]
GO
SELECT * into FactResellerSalesXL From FactResellerSaleXL_CCI
USE [AdventureworksDW2016CTP3]
GO
SET ANSI_PADDING ON
GO
ALTER TABLE [dbo].[FactResellerSalesXL] ADD
CONSTRAINT [PK_FactResellerSalesXL_SalesOrderNumber_SalesOrderLineNumber]
PRIMARY KEY CLUSTERED
(
[SalesOrderNumber] ASC,
[SalesOrderLineNumber] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
SORT_IN_TEMPDB = OFF,
IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON,
ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GOСначала выполним запрос при отсутствии индекса поколоночного хранения и наличии только текущего кластеризованного построчного (обычного) индекса. Обратите внимание, что я включила параметры STATISTICS IO и TIME. Эти два оператора SET помогут лучше проиллюстрировать преимущества, обеспечиваемые поколоночным индексом. SET STATISTICS IO выводит статистику по количеству затронутых запросом страниц. Это даст нам такую важную информацию, как логические, физические чтения, сканирования, логические и физические чтения LOB. SET STATISTICS TIME отображает количество времени, необходимое для разбора, компиляции и выполнения каждого оператора в запросе. Вывод содержит время в миллисекундах для выполнения каждой операции. Это позволит нам увидеть разницу в цифрах.
USE [AdventureworksDW2016CTP3]
GO
SET STATISTICS IO ON
GO
SET STATISTICS TIME ON;
GO
SELECT ProductKey, sum(SalesAmount) SalesAmount, sum(OrderQuantity) ct
FROM dbo.FactResellerSalesXL
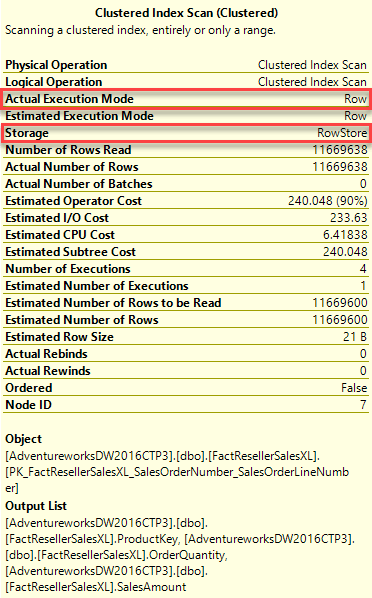
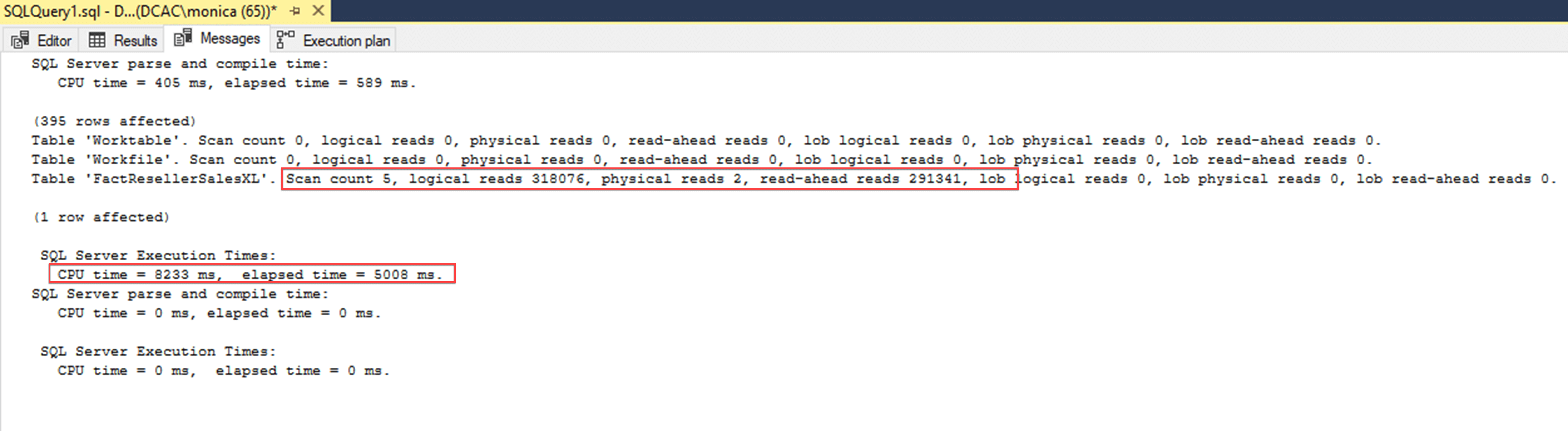
GROUP BY ProductKeyКак видно из результатов ниже, выполняется 5 сканирований, 318076 логических чтений, два физических чтения и 291341 упреждающих чтений. Время процессора (CPU Time) 8233 миллисекунд, а затраченное время 5008 миллисекунд. Оптимизатор выбирает сканирование существующего построчного кластеризованного индекса со стоимостью 91%. При этом просканировано 11,6 миллионов записей, и возвращено 395 записей в результирующем наборе.

Важно заметить, что если поместить курсор над оператором Clustered Index scan, вы сможете увидеть что типом хранения индекса являются строки (Row), и фактический режим выполнения (Actual Execution Mode) также Row.
Создадим теперь поколоночный индекс на этой таблице. Используя графический интерфейс, выполним щелчок правой кнопкой на индексах и выберем команду Новый индекс (New Index), затем Кластеризованный поколоночный индекс (Clustered Columnstore Index).
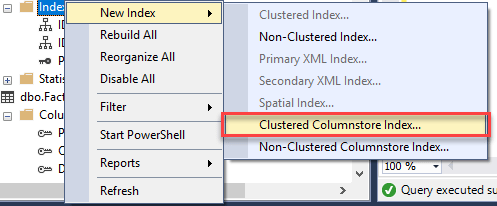
В таблице General вам нужно задать имя индекса. Если в таблице есть несовместимые объекты, вы увидите их список в подсвеченной области ниже. Существует много ограничений и исключений для поколоночных индексов, например, специфические типы данных - text, ntext, image - и такие особенности, как разреженные столбцы. Полный список ограничений можно найти в документации Майкрософт.
Поскольку используется сжатие данных, создание поколоночного индекса может интенсивно использовать процессор. Чтобы уменьшить нагрузку, SQL Server предлагает опцию (на вкладке Options) для изменения текущей установки сервера MaxDop для параллельного процесса построения. Это иногда следует иметь в виду при создании поколоночных индексов на рабочем сервере. В данном примере оставим значение по умолчанию. С другой стороны, если вы строите этот индекс во время простоя, имейте в виду, что операции поколоночного хранения масштабируются линейно по производительности вплоть до MaxDOP 64, и это может помочь быстрей завершить процесс построения индекса за счет обычного параллелизма.
Из документации Майкрософт
max_degree_of_parallelism может принимать значения:
- 1 - Подавляет генерацию параллельного плана.
- >1 - Ограничивает максимальное число процессоров, используемых в параллельной операции индексирования, заданным числом или меньшим в зависимости от текущей системной нагрузки. Например, когда MAXDOP = 4, используемое число процессоров - 4 или меньше.
- 0 (по умолчанию) - Используется фактическое число процессоров или меньшее в зависимости от текущей нагрузки на систему.
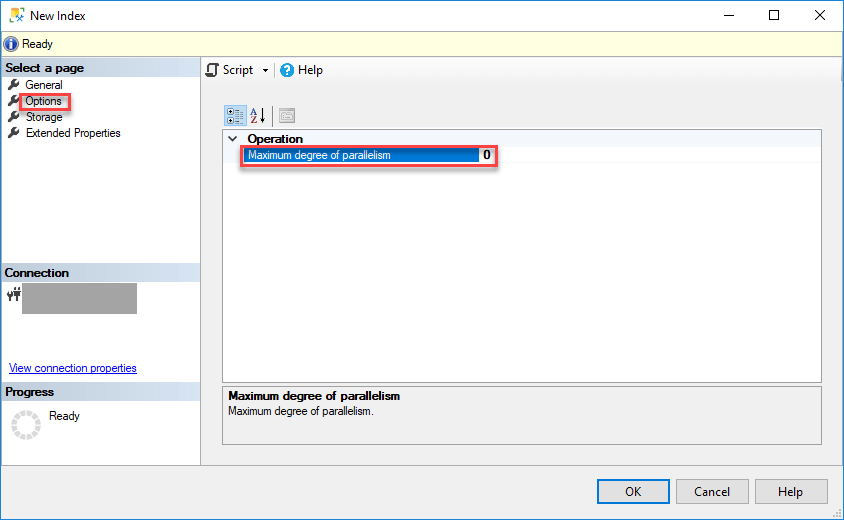 Если вы щелкните ОК для создания индекса, то получите ошибку, которую я объясняю ниже. Если вы выберите заскриптовать (script), то получите нижеприведенный оператор T-SQL создания индекса.
Если вы щелкните ОК для создания индекса, то получите ошибку, которую я объясняю ниже. Если вы выберите заскриптовать (script), то получите нижеприведенный оператор T-SQL создания индекса.USE [AdventureworksDW2016CTP3]
GO
CREATE CLUSTERED COLUMNSTORE INDEX [CS_IDX_FactResellerSalesXL]
ON [dbo].[FactResellerSalesXL]
WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0)
GOЕсли вы запустите этот оператор, то получите ошибку, которая сообщает о невозможности создания индекса, поскольку вы не можете создать более одного кластерного индекса на таблице.
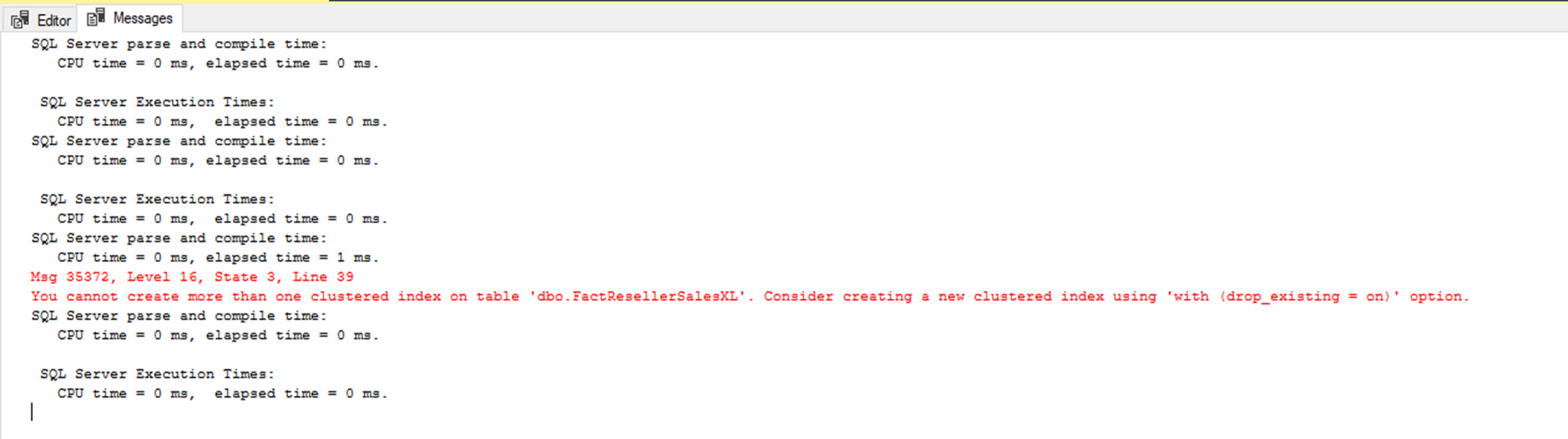 Это говорит о том, что вы можете иметь только один кластеризованный индекс на таблице, вне зависимости от того, какой это индекс - столбцовый или строчный. Вы можете изменить параметр на DROP_EXISTING = ON, чтобы удалить построчный кластеризованный индекс и заменить его на поколоночный. Более того, вместо кластеризованного у вас есть вариант создания некластеризованного поколоночного индекса или добавления традиционных некластеризованных индексов. (Замечание: вы можете добавить только один поколоночный индекс на таблицу.) Этот вариант обычно используется, когда большинство запросов к таблице возвращают большие агрегаты, но другое подмножество выполняет поиск по определенному значению. Добавление дополнительного некластеризованного индекса будет значительно увеличивать время загрузки данных в таблицу.
Это говорит о том, что вы можете иметь только один кластеризованный индекс на таблице, вне зависимости от того, какой это индекс - столбцовый или строчный. Вы можете изменить параметр на DROP_EXISTING = ON, чтобы удалить построчный кластеризованный индекс и заменить его на поколоночный. Более того, вместо кластеризованного у вас есть вариант создания некластеризованного поколоночного индекса или добавления традиционных некластеризованных индексов. (Замечание: вы можете добавить только один поколоночный индекс на таблицу.) Этот вариант обычно используется, когда большинство запросов к таблице возвращают большие агрегаты, но другое подмножество выполняет поиск по определенному значению. Добавление дополнительного некластеризованного индекса будет значительно увеличивать время загрузки данных в таблицу.Заметим, что база данных AdventureWorksDW2016CTP3 содержит таблицу с именем dbo.FactResellerSalesXL_CCI, которая уже имеет созданный кластеризованный поколоночный индекс. Вы можете заскриптовать её, чтобы увидеть в точности то, что вы пытаетесь создать. Для простоты вместо создания индекса используйте эту таблицу, которая идентична таблице FactResellerSalesXL и отличается только отсутствием/наличием поколоночного индекса.
USE [AdventureworksDW2016CTP3]
GO
CREATE CLUSTERED COLUMNSTORE INDEX [IndFactResellerSalesXL_CCI]
ON [dbo].[FactResellerSalesXL_CCI] WITH (DROP_EXISTING = OFF,
COMPRESSION_DELAY = 0) ON [PRIMARY]
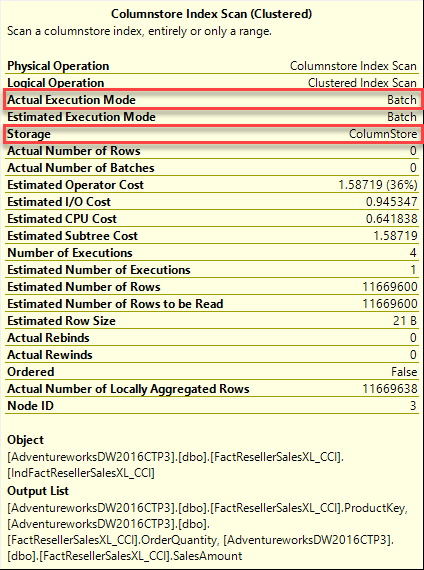
GOВзглянем сначала на план выполнения. Легко увидеть, что оптимизатор от восьми операций пришел только к пяти, чтобы выполнить транзакцию, и он использует Index scan кластеризованного поколоночного индекса, но теперь при стоимости только 36% он читает ноль из 11,6 миллионов записей.
 Теперь давайте смотреть на цифры. Чтобы разница было видна отчетливо, я ниже привожу оба результата для сравнения.
Теперь давайте смотреть на цифры. Чтобы разница было видна отчетливо, я ниже привожу оба результата для сравнения.Построчное хранение
Поколоночное хранение
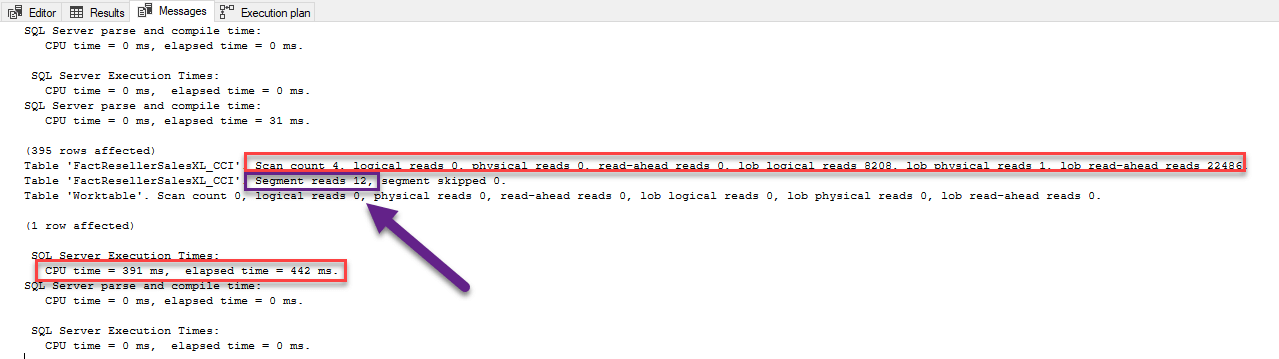 Результаты для поколоночного хранилища дают четыре сканирования, ноль логических чтений, ноль физических чтений, ноль предупреждающих чтений, 22486 предупреждающих чтений LOB, и время выполнения менее секунды. Причина, по которой наблюдается работа с большими объектами (LOB), объясняется тем, что SQL Server использует механизм естественного хранилища LOB для хранения поколоночных сегментов. Также имеется дополнительный кэш для этих сегментов в основной памяти SQL Server, который отделен от буферного пула. Построчный индекс показывает значительно больше чтений. Наконец, отметим дополнительную строку в таблице - Segments Reads =12. Вспомним, как столбцы сохраняются в колоночных сегментах. Здесь мы видим, что оптимизатор читает эти сегменты.
Результаты для поколоночного хранилища дают четыре сканирования, ноль логических чтений, ноль физических чтений, ноль предупреждающих чтений, 22486 предупреждающих чтений LOB, и время выполнения менее секунды. Причина, по которой наблюдается работа с большими объектами (LOB), объясняется тем, что SQL Server использует механизм естественного хранилища LOB для хранения поколоночных сегментов. Также имеется дополнительный кэш для этих сегментов в основной памяти SQL Server, который отделен от буферного пула. Построчный индекс показывает значительно больше чтений. Наконец, отметим дополнительную строку в таблице - Segments Reads =12. Вспомним, как столбцы сохраняются в колоночных сегментах. Здесь мы видим, что оптимизатор читает эти сегменты.Можем также увидеть, что поколоночный индекс использует меньше времени процессора (CPU time). Первый результат давал 8233 мс при затраченном времени 5008 мс, в то время как второй - только 391 мс и 442 мс соответственно. Это огромный прирост производительности.
Напомню, что при использовании построчного индекса Actual Execution Mode был Row. Теперь, при использовании поколоночного хранения, использовался пакетный режим (Batch mode - красная рамка). Если вы помните, пакетный режим позволяет движку обрабатывать несколько строк одновременно. Это в некоторых случаях дает возможность обрабатывать строки исключительно быстро, увеличивая в 2-4 раза производительность выполнения отдельного запроса. Итак, мы видим, что пример с агрегацией выполнился очень быстро, потому что только агрегируемые строки считываются в память. Используя группы строк, движок может обрабатывать в пакетном режиме группы по 1 миллиону строк. Таким образом, 12 сегментов читают немногим более 11,6 миллиона строк.
Когда использовать поколоночные индексы
Теперь большие возможности требуют большой ответственности. Поколоночные индексы разработаны для больших нагрузок в хранилищах данных, но не для обычных таблиц OLTP-систем. Только потому, что эти индексы работают эффективно, не означает, что вам следует добавлять их повсюду. Исследуйте и тестируйте поколоночные индексы перед созданием их в рабочей системе.
Как и при любом проектировании индексов, важно понимать ваши данные и то, как они используются. Выясните, какие типы запросов выполняются, а также как данные загружаются и обслуживаются. Следует задать себе ряд вопросов, прежде чем решиться применить поколоночный индекс. Просто потому, что ваша таблица содержит миллионы строк, не означает, что поколоночное хранение - это правильный выбор.
Сначала нужно знать данные
Достаточно ли большая ваша таблица, чтобы получить преимущество? Обычно это означает, что миллионы записей разбиваются на группы строк, называемых строковыми группами. Строковая группа содержит минимум 102400 строк и максимум около 1 миллиона строк. Каждая строковая группа преобразуется в поколоночные сегменты. Следовательно, иметь поколоночный индекс на таблице, в которой менее 1 миллиона строк, не имеет смысла; для такой маленькой таблицы вы не получите выгоды за счет сжатия, которое выполняется для колоночных сегментов. Основная рекомендация для использования поколоночных индексов - это фактологическая таблица в хранилище данных и очень большие таблицы измерений, содержащие более 5 миллионов строк.
Являются ли ваши данные волатильными, т.е. часто ли они изменяются? Главное правило говорит, что вам нужны таблицы, в которых данные модифицируются редко, или, более конкретно, когда изменяется менее 10% строк вообще. Большое число удалений может вызвать фрагментацию, которая неблагоприятно повлияет на степень сжатия, тем самым уменьшая эффективность индекса. Что касается обновлений, то это дорогая операция, поскольку она выполняется как удаление с последующей вставкой, что отрицательно повлияет на производительность процесса загрузки.
Какого типа данные, содержатся в вашей таблице? Есть несколько типов данных, которые не поддерживаются поколоночным индексом. Данные типов varchar(max), nvarchar(max) или varbinary(max) не поддерживались до версии SQL Server 2017, и обычно они не очень подходят для данного типа рабочей нагрузки, особенно по причине их вероятно плохого сжатия. Кроме того, если вы используете уникальные идентификаторы (GUID), то не сможете создать индекс, поскольку они до сих пор не поддерживаются.
Далее, что вы делаете в своих запросах?
Вы считаете агрегатные значения, или выполняете аналитические запросы к данным, или ищете конкретные значения? Стандартные построчные индексы B-tree наилучшим образом подходят для поиска конкретных значений и иногда используются в тандеме с поколоночным индексом. Если вы используете индекс для покрытия предложения WHERE, которое не ищет диапазон значений, а лишь является фильтрующим предикатом, тогда поколоночное хранение не даст преимуществ. Это особенно справедливо, если вам нужно "покрыть" этот запрос включенными столбцами, т.к. поколоночный индекс не допускает включенных столбцов. Однако поколоночное хранение предназначено для быстрого процесса агрегации, особенно на сгруппированном диапазоне значений. Поэтому, если вы выполняете агрегацию или аналитику, обычно поколоночное хранение может дать вам существенный выигрыш в производительности, поскольку он может очень быстро выполнить полное сканирование таблицы для вычисления агрегатных значений.
Теперь случай, когда вы хотите найти конкретное значение и выполнить агрегацию (например, среднюю цену продажи за последний квартал конкретного продукта). В подобных случаях вы можете получить выгоду от комбинации поколоночного и построчного индексов. Создание поколоночного индекса для обработки группировки и агрегации и обеспечение требования поиска с помощью построчного индекса. Добавление таких B-tree индексов поможет вам улучшить производительность запроса, но может весьма негативно сказаться на процессе загрузки - если нагрузка загрузки достаточно велика. Тогда может оказаться более эффективным удалить индекс B-tree, и перестроить его после загрузки данных в поколоночный индекс.
Являются ли данные в хранилище таблицей фактов или же измерения? Как вы знаете, таблица измерений обычно используется для поиска конкретных значений,
в основном это поиск для сопоставления с агрегированным значением из таблицы фактов. Если это таблица измерений, обычно предпочтительно использовать модели на основе B-tree, за исключением очень больших измерений. Наилучшим вариантом является использование поколоночного хранения на таблице фактов в хранилище данных, поскольку эти таблицы обычно являются источником агрегатов.
Заключение
Избавить от страха перед поколоночным хранением легко, если вы потратите время на его понимание. Надеюсь, что эта статья помогла вам в этом. Но не нужно сразу переходить к поколоночным индексам, как только вы поняли, что это такое, и имеете большие таблицы. Найдите время, как и в любом другом проектировании, чтобы выбрать правильный вариант для вашего использования и программной среды. Понимание ваших данных имеет решающее значение при принятии решения о том, является ли поколоночный индекс лучшим выбором для ваших запросов.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой