
Кучи в SQL Server: часть 2 - оптимизация чтений
Пересказ статьи Uwe Ricken. Heaps in SQL Server: Part 2 Optimizing Reads
Пока эта серия состоит из:
- Кучи в SQL Server: часть 1 - основы
- Кучи в SQL Server: часть 2 - оптимизация чтений (эта статья)
- Кучи в SQL Server: часть 3 - некластеризованные индексы
Кучи вряд ли являются любимцами разработчика, поскольку они не очень производительны, особенно когда дело доходит до выборки данных (так думает большинство людей!). Определенно, какая-то правда есть в этом мнении, однако окончательно все решает рабочая нагрузка. В этой статье я описываю, как работает куча при выборке данных. Если вы понимаете процесс, который происходит в SQL Server при чтении данных из кучи, вы сможете легко решить, является ли куча лучшим решением для вашей рабочей нагрузки.
Расширенное сканирование
Как вы знаете, для извлечения данных по запросу клиента кучи могут использовать только сканирование таблицы. В SQL Server Enterprise возможность расширенного сканирования позволяет множеству задач разделять полное сканирование таблиц. Если план выполнения оператора T-SQL требует сканирования страниц данных в таблице, а движок базы данных (Database Engine) обнаруживает, что таблица уже сканируется другим планом выполнения, он соединяет второй скан с первым, начиная с текущего места второго скана. Движок читает каждую страницу один раз и передает строки каждой страницы обоим планам выполнения. Это продолжается, пока не будет достигнут конец таблицы.
В этом месте первый план выполнения имеет полные результаты сканирования, но второй план выполнения должен еще получить страницы данных, которые были прочитаны до того, как он присоединился к процессу сканирования. Тогда второй план выполнения поворачивает назад к первой странице данных таблицы, и сканирует вперед до места, где он соединился с первым сканированием. Подобным образом может соединяться любое число сканирований. Движок будет продолжать цикл по страницам данных, пока не завершит все сканирования. Этот механизм также называется "карусельным сканированием" ("merry-go-round scanning") и демонстрирует, почему порядок возвращаемого результата оператором SELECT не может гарантироваться без предложения ORDER BY.
Выбрать данные в куче
Поскольку куча не имеет индексной структуры, Microsoft SQL Server должен всегда читать таблицу целиком. Microsoft SQL Server решает проблему предикатов с помощью оператора FILTER (Predicate Pushdown). Для всех примеров в этой статье я создал таблицу с приблизительно 4000000 записями данных из моей демонстрационной базы данных CustomerOrders. После восстановления базы данных выполните этот код для создания новой таблицы - CustomerOrderList.
-- Создание большой таблицы с ~4.000.000 строками
SELECT C.ID AS Customer_Id,
C.Name,
A.CCode,
A.ZIP,
A.City,
A.Street,
A.[State],
CO.OrderNumber,
CO.InvoiceNumber,
CO.OrderDate,
CO.OrderStatus_Id,
CO.Employee_Id,
CO.InsertUser,
CO.InsertDate
INTO dbo.CustomerOrderList
FROM CustomerOrders.dbo.Customers AS C
INNER JOIN CustomerOrders.dbo.CustomerAddresses AS CA
ON (C.Id = CA.Customer_Id)
INNER JOIN CustomerOrders.dbo.Addresses AS A
ON (CA.Address_Id = A.Id)
INNER JOIN CustomerOrders.dbo.CustomerOrders AS CO
ON (C.Id = CO.Customer_Id)
ORDER BY
C.Id,
CO.OrderDate
OPTION (MAXDOP 1);
GOКогда данные читаются из кучи, в плане выполнения используется оператор TABLE SCAN - независимо от числа записей данных, которые должны быть отправлены клиенту.
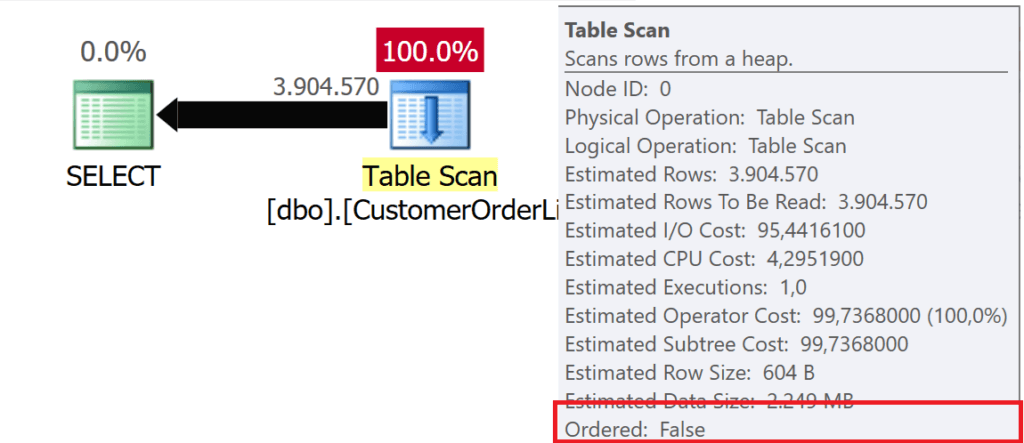
Рис.1: SELECT * FROM dbo.CustomerList
Когда Microsoft SQL Server читает данные из таблицы или индекса, это может быть сделано двумя способами:
- Выборка данных следует структуре индекса B-Tree.
- Данные выбираются в соответствии с логическим расположением страниц данных.
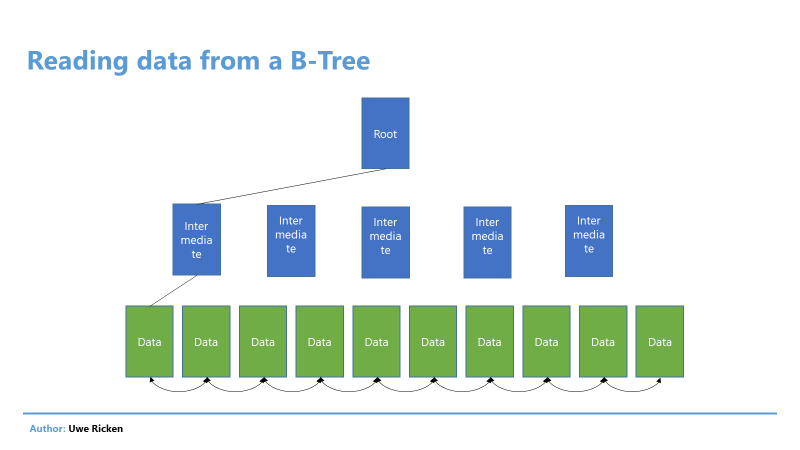
Рис.2: Чтение данных в B-Tree в основном следует структуре индекса
В куче процесс чтения происходит в порядке, в котором данные сохранялись на страницах данных. Microsoft SQL Server читает информацию о страницах данных кучи из IAM-страницы таблицы, которая описывалась в статье Кучи в SQL Server: часть 1 - основы.
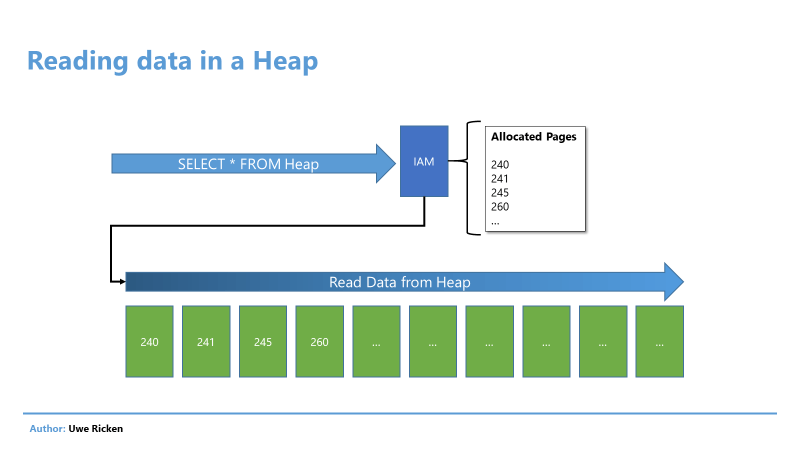
Рис.3: Чтение данных в куче следует логическому порядку страниц данных
После того, как «маршрут» для чтения данных был прочитан из IAM, процесс SCAN начинает посылать данные клиенту. Эта техника называется "сканированием в порядке размещения", который можно наблюдать прежде всего в кучах.
Если данные ограничены предикатом, работа процесса не меняется. Поскольку данные не отсортированы в куче, Microsoft SQL Server должен всегда искать во всей таблице (все страницы данных).
SELECT * FROM dbo.CustomerOrderList
WHERE Customer_Id = 10;
GO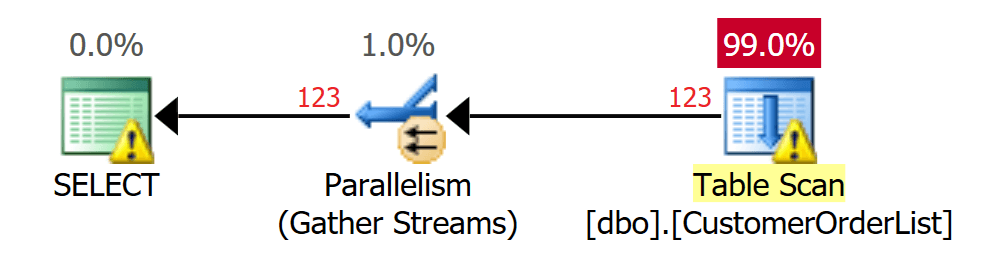
Рис.4: Сканирование всей таблицы
Фильтрация называется "проталкиванием предиката". Прежде чем перейти к следующим процессам, число записей данных сокращается насколько это возможно! Проталкивание предиката можно увидеть в плане выполнения, используя флаг трассировки 9130!
SELECT * FROM dbo.CustomerOrderList
WHERE Customer_Id = 10
OPTION (QUERYTRACEON 9130);
GO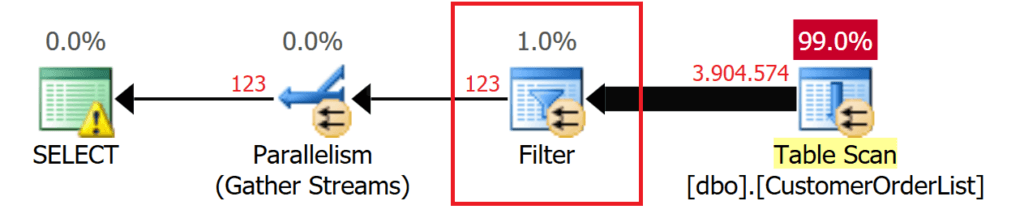
Рис.5: Оператор FILTER для выбранных данных
Преимущества чтения из кучи
Кажется, что кучи - это худший вариант при чтении данных по сравнению с индексом. Однако это утверждение применимо, только если данные должны быть ограничены предикатом. На самом деле, когда читается вся таблица, куча имеет два - на мой взгляд - значительных преимущества:
- Не нужно читать никакой структуры B-Tree; читаются только страницы данных.
- Если куча не фрагментирована и не имеет переносимых записей (описывается в следующей статье), данные кучи могут читаться последовательно. Данные читаются из хранилища в том порядке, в котором они вводились.
- Индекс всегда следует за указателями на следующую страницу данных. Если индекс фрагментирован, имеют место случайные чтения, которые не так производительны, как операторы последовательного чтения.
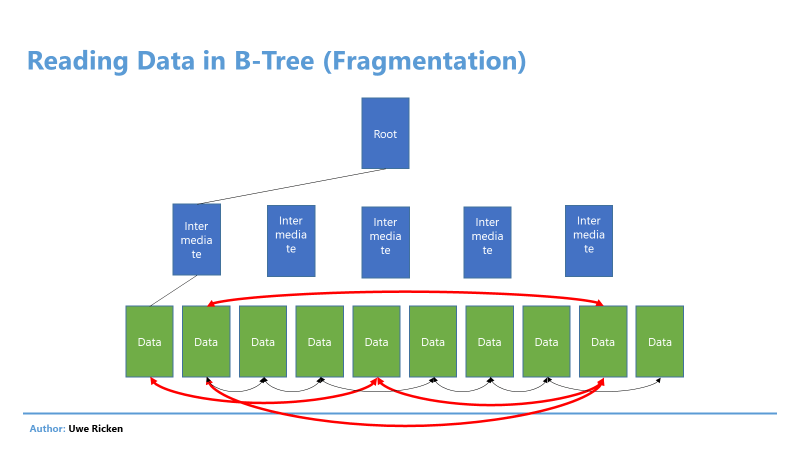
Рис.6: Чтение из B-Tree
Недостатки при чтении из кучи
Одним из наибольших недостатков чтения данных из кучи является сканирование IAM в процессе чтения данных. Microsoft SQL Server должен удерживать блокировку, чтобы гарантировать неизменность метаданных структуры таблиц в течении процесса чтения.
Представленный ниже код создает расширенное событие, которое записывает все установки блокировок в транзакции. Скрипт записывает только активность предварительно заданной пользовательской сессии, поэтому не забудьте заменить в скрипте ID сессии пользователя на ваш.
-- Создает XEvent для анализа блокировок
CREATE EVENT SESSION [Track Lockings]
ON SERVER
ADD EVENT sqlserver.lock_acquired
(ACTION (package0.event_sequence)
WHERE
(
sqlserver.session_id = 55
AND mode = 1
)
),
ADD EVENT sqlserver.lock_released
(ACTION (package0.event_sequence)
WHERE
(
sqlserver.session_id = 55
AND mode = 1
)
),
ADD EVENT sqlserver.sql_statement_completed
(ACTION (package0.event_sequence)
WHERE (sqlserver.session_id = 55)
),
ADD EVENT sqlserver.sql_statement_starting
(ACTION (package0.event_sequence)
WHERE (sqlserver.session_id = 55)
)
WITH
(
MAX_MEMORY = 4096KB,
EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY = 30 SECONDS,
MAX_EVENT_SIZE = 0KB,
MEMORY_PARTITION_MODE = NONE,
TRACK_CAUSALITY = ON,
STARTUP_STATE = OFF
);
GO
ALTER EVENT SESSION [Track Lockings]
ON SERVER
STATE = START;
GO Когда вы выполняете оператор SELECT из первого примера, сессия расширенного события будет записывать следующие действия:

Рис.7: Удерживание SCH_S-блокировки при чтении данных их кучи
Блокировки удерживаются до завершения операции SCAN.
В высоко конкурентных системах такие блокировки нежелательны, поскольку они упорядочивают операции. Чем больше куча, тем дольше блокировки будут препятствовать дальнейшим операциям с метаданными:
- Создание индексов
- Перестройка индексов
- Добавление или удаление столбцов
- Операции TRUNCATE
- ...
Другим недостатком кучи может быть высокое число I/O (ввод/вывод), если только небольшое количество данных должно быть выбрано. Хотя здесь применим совет использовать некластеризованный индекс для оптимизации таких операций.
Оптимизация операций SELECT
Как утверждалось выше, Microsoft SQL Server всегда должен читать таблицу целиком при выполнении оператора SELECT. Поскольку Microsoft SQL Server выполняет сканирование в порядке размещения, данные читаются в порядке их логического расположения.
Использование оператора TOP
С помощью оператора TOP(n) вам повезет, если затрагиваемые записи данных были записаны на первых страницах данных кучи.
-- Выбираем самую первую запись
SELECT TOP (1) * FROM dbo.CustomerOrderList
OPTION (QUERYTRACEON 9130);
GO
-- Выбираем самую первую запись с предикатом
-- который определяет запись в начале кучи
SELECT TOP (1) * FROM dbo.CustomerOrderList
WHERE Customer_Id = 1
OPTION (QUERYTRACEON 9130, MAXDOP 1);
GO
-- Выбираем самую первую запись с предикатом
-- который определяет запись в любом месте кучи
SELECT TOP (1) * FROM dbo.CustomerOrderList
WHERE Customer_Id = 22844
OPTION (QUERYTRACEON 9130);
GOКод выше выполняет три запроса, используя оператор TOP. Первый запрос находит физически первую запись данных, которая была записана в таблицу.
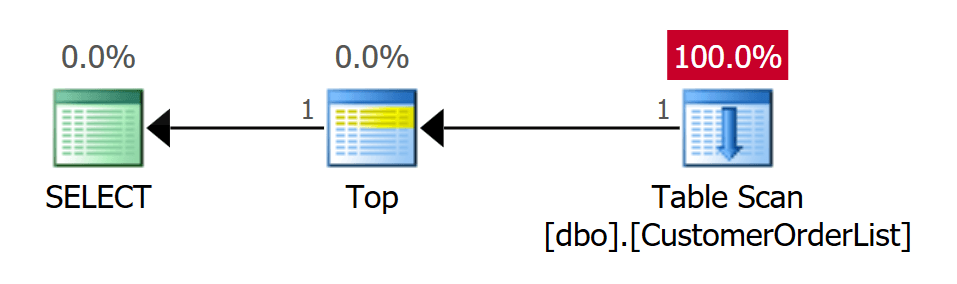
Рис.8: Сканирование таблицы для определения первой записи данных - 1 I/O
Как и ожидалось, план выполнения использует оператор сканирования таблицы. Это единственный оператор, который может использоваться для кучи. Однако оператор TOP предотвращает полный просмотр таблицы. Когда число записей данных, требуемых клиенту, достигается, оператор TOP прерывает соединение со сканированием таблицы, и процесс завершается.
Второй запрос также требует только 1 I/O. Однако это потому, что разыскиваемая запись является первой записью в таблице. Тем не менее, Microsoft SQL Server должен использовать оператор FILTER для предиката. Оператор TOP сразу прерывает последующие операции после получения первой записи данных.
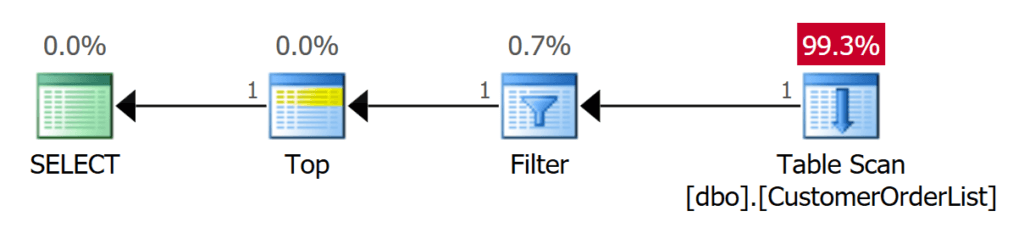
Рис.9: Поиск с предикатом должен найти 1 запись данных
Третий запрос использует предикат, который находит запись данных только на 1875 позиции. В этой ситуации Microsoft SQL Server должен прочитать намного больше страниц, прежде чем процесс получит желаемый результирующий набор и автоматически завершится.
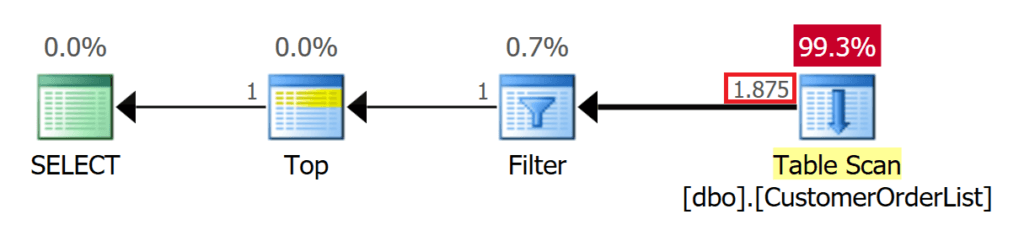
Рис.10: Поиск с предикатом должен найти 1875 записей
Суть в том, что оператор TOP может быть полезным; на практике это не всегда так, поскольку число прочитанных страниц всегда зависит от логической позиции записи данных.
Сжатие
Кажется невозможным уменьшить число операций ввода/вывода в куче (всегда должны быть прочитаны все страницы данных!), однако сжатие данных помогает уменьшить I/O.
Microsoft SQL Server предлагает два типа сжатия данных для возможного сокращения числа операций чтения:
- Сжатие строк
- Сжатие страниц
Для куч и секционированных куч сжатие данных может дать заметное преимущество относительно I/O. Однако имеется несколько специальных вещей, которые необходимо рассмотреть при сжатии данных в куче. Когда куча сконфигурирована для сжатия на уровне страниц, сжатие выполняется следующим образом:
- Сопоставление новых страниц данных в куче в части операций DML использует сжатие страниц только после пересоздания кучи.
- Изменение установки сжатия кучи приводит к перестройке всех некластеризованных индексов, поскольку должно быть переписано сопоставление позиций.
- Сжатие ROW (записей) или PAGE (страниц) может быть активировано и деактивировано онлайн или офлайн.
- Включение сжатия кучи в режиме онлайн выполняется с помощью одного потока.
Для определения того, дает ли сжатие таблиц и/или индексов реальное преимущество, можно использовать системную процедуру sp_estimate_data_compression_savings.
-- Оценить экономию за счет сжатия данных
DECLARE @Result TABLE
(
Data_Compression CHAR(4) NOT NULL DEFAULT '---',
object_name SYSNAME NOT NULL,
schema_name SYSNAME NOT NULL,
index_id INT NOT NULL,
partition_number INT NOT NULL,
current_size_KB BIGINT NOT NULL,
request_size_KB BIGINT NOT NULL,
sample_size_KB BIGINT NOT NULL,
sample_request_KB BIGINT NOT NULL
);
INSERT INTO @Result
(object_name, schema_name, index_id, partition_number,
current_size_KB, request_size_KB, sample_size_KB,
sample_request_KB)
EXEC sp_estimate_data_compression_savings
@schema_name = 'dbo',
@object_name = 'CustomerOrderList',
@index_id = 0,
@partition_number = NULL,
@data_compression = 'PAGE';
UPDATE @Result
SET Data_Compression = 'PAGE'
WHERE Data_Compression = '---';
-- Оценить экономию за счет сжатия данных
INSERT INTO @Result
(object_name, schema_name, index_id, partition_number,
current_size_KB, request_size_KB, sample_size_KB,
sample_request_KB)
EXEC sp_estimate_data_compression_savings
@schema_name = 'dbo',
@object_name = 'CustomerOrderList',
@index_id = 0,
@partition_number = NULL,
@data_compression = 'ROW';
UPDATE @Result
SET Data_Compression = 'ROW'
WHERE Data_Compression = '---';
SELECT Data_Compression,
current_size_KB,
request_size_KB,
(1.0 - (request_size_KB * 1.0 / current_size_KB * 1.0)) * 100.0
AS percentage_savings
FROM @Result;
GO Вышеприведенный скрипт используется для определения возможной экономии объема данных для строчного и страничного сжатия данных.

Рис.11: Возможная экономия более чем на 30%
Следующий скрипт вставляет все записи из таблицы [dbo].[CustomerOrderList] во временную таблицу. Измеряются времена I/O и CPU. Тест выполнялся на несжатых данных, страничном сжатии и строчном сжатии.
ALTER TABLE dbo.CustomerOrderList
REBUILD WITH (DATA_COMPRESSION = NONE);
GO
-- IO и CPU без сжатия
SELECT *
INTO #Dummy
FROM dbo.CustomerOrderList
GO
DROP TABLE #Dummy;
GO
ALTER TABLE dbo.CustomerOrderList
REBUILD WITH (DATA_COMPRESSION = PAGE);
GO
-- IO и CPU со страничным сжатием
SELECT *
INTO #Dummy
FROM dbo.CustomerOrderList
GO
DROP TABLE #Dummy;
GO
ALTER TABLE dbo.CustomerOrderList
REBUILD WITH (DATA_COMPRESSION = ROW);
GO
-- IO и CPU со строчным сжатием
SELECT *
INTO #Dummy
FROM dbo.CustomerOrderList
GO
DROP TABLE #Dummy;
GO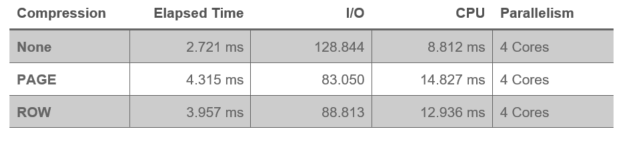
Измерения показывают проблемы сжатия данных. Значительно снижается I/O; однако потенциальная экономия "съедается" увеличением использования CPU.
Последняя строка для сжатия данных - это определенно то, что может быть вариантом снижения I/O. К сожалению, это "преимущество" быстро обнуляется непропорциональным потреблением других ресурсов (CPU). Если ваша система имеет досточно быстрые процессоры и в большом числе, вы можете рассмотреть этот вариант. В противном случае, следует предпочесть ресурсы CPU; тем более, если это относится к системам с большим количеством мелких транзакций.
Вам также следует очень тщательно проверить ваше приложение перед использованием технологий сжатия. Microsoft SQL Server создает планы выполнения, которые принимают во внимание оценки I/O. Значительно меньшие значения I/O, генерируемые использованием сжатия, могут привести в изменению плана выполнения (операторы HASH или MERGE становятся NESTED LOOP). Всякий, кто верит, что сжатие данных экономит память (как для буферного пула, так и для операций сортировки), ошибается!
- Данные всегда распаковываются в буферном пуле.
- Оператор SORT расчитывает потребности в памяти на основании записей данных, которые требуется обработать.
Секционирование
С помощью секционирования таблица разбивается горизонтально. Создается несколько групп, которые связываются по границам секций.
Авторитетный коллега из Норвегии (Cathrine Wilhelmsen) также написала замечательную серию статей по секционированию, с которой можно познакомиться здесь.
Преимущество секционирования куч может проявиться, только если куча используется для поиска по шаблонам предикатов, соответствующих ключу раздела. Если вы не ищете по ключу раздела, секционирование не может помочь вам находить данные.
Часто требуется найти заказы в [dbo].[CustomerOrderList].
-- Найти все заказы за 2016
SELECT * FROM dbo.CustomerOrderList
WHERE OrderDate >= '20160101'
AND OrderDate <= '20161231'
ORDER BY
Customer_Id,
OrderDate DESC
OPTION (QUERYTRACEON 9130);
GOMicrosoft SQL Server должен найти всю таблицу, чтобы выполнить запрос. Это заметно в I/O, а также нагрузке на процессоры (CPU)!

Рис.12: Сканируется (TABLE SCAN) свыше 4000000 записей
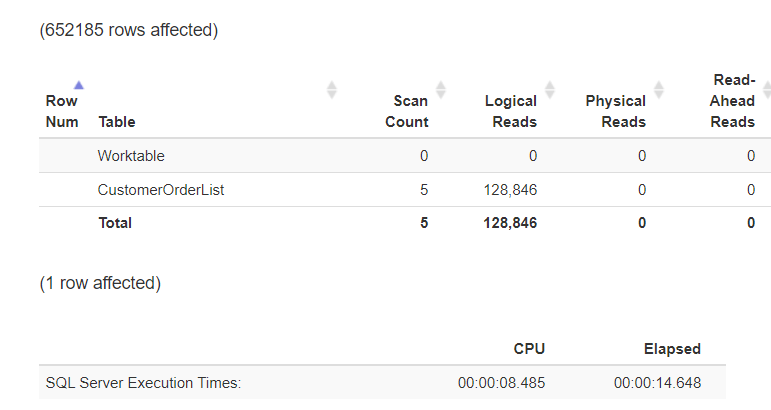
Рис.13: Статистика, отформатированная с помощью https://statisticsparser.com
Без индекса нет способа уменьшить нагрузку на ввод/вывод и процессор. Сокращения можно добиться только уменьшением объема читаемых данных. По этой причине таблица секционируется так, чтобы в каждом разделе был один год.
На первом шаге создаем файловую группу для каждого года заказов в базе данных. Для достижения лучшей производительности, каждый год заказов размещается в отдельном файле базы данных.
-- Мы создаем для каждого года вплоть до 2019 одну файловую группу
--и добавляем один файл для каждой файловой группы!
DECLARE @DataPath NVARCHAR(256) =
CAST(SERVERPROPERTY('InstanceDefaultDataPath') AS NVARCHAR(256));
DECLARE @stmt NVARCHAR(1024);
DECLARE @Year INT = 2000;
WHILE @Year <= 2019
BEGIN
SET @stmt = N'ALTER DATABASE CustomerOrders
ADD FileGroup ' + QUOTENAME(N'P_' +
CAST(@Year AS NCHAR(4))) + N';';
RAISERROR ('Statement: %s', 0, 1, @stmt);
EXEC sys.sp_executeSQL @stmt;
SET @stmt = N'ALTER DATABASE CustomerOrders
ADD FILE
(
NAME = ' + QUOTENAME(N'Orders_' +
CAST(@Year AS NCHAR(4)), '''') + N',
FILENAME = ''' + @DataPath + N'ORDERS_' +
CAST(@Year AS NCHAR(4)) + N'.ndf'',
SIZE = 128MB,
FILEGROWTH = 128MB
)
TO FILEGROUP ' + QUOTENAME(N'P_' + CAST(@Year AS NCHAR(4))) + N';';
RAISERROR ('Statement: %s', 0, 1, @stmt);
EXEC sys.sp_executeSQL @stmt;
SET @Year += 1;
END
GOВы можете увидеть, что после выполнения скрипта каждый год имеет свою собственную файловую группу и файл:
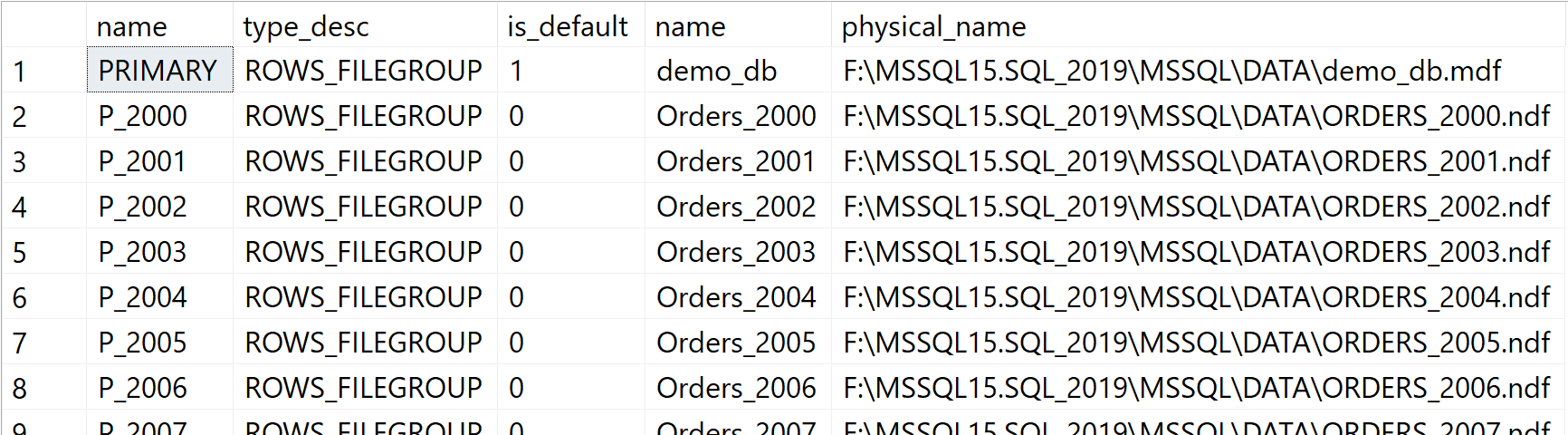
Рис.14: Каждый год заказов имеет собственный файл базы данных
На следующем шаге создается функция разбиения, которая гарантирует, что каждый год заказов правильно назначен и сохранен.
CREATE PARTITION FUNCTION pf_OrderDate(DATE)
AS RANGE LEFT FOR VALUES
(
'20001231', '20011231', '20021231', '20031231', '20041231',
'20051231', '20061231', '20071231', '20081231', '20091231',
'20101231', '20111231', '20121231', '20131231', '20141231',
'20151231', '20161231', '20171231', '20181231', '20191231'
);
GOНаконец, чтобы связать функцию разбиения с файловыми группами, вам нужна схема разбиения, которая генерируется следующим скриптом.
CREATE PARTITION SCHEME [OrderDates]
AS PARTITION pf_OrderDate
TO
(
[P_2000], [P_2001], [P_2002], [P_2003], [P_2004],
[P_2005], [P_2006], [P_2007], [P_2008], [P_2009],
[P_2010], [P_2011], [P_2012], [P_2013], [P_2014],
[P_2015], [P_2016], [P_2017], [P_2018], [P_2019]
,[PRIMARY]
);
GOКогда имеется схема разбиения, вы можете распределить данные из таблицы по всем секциям на основании года заказа. Чтобы переместить несекционированную кучу в схему разбиения, необходимо построить кластеризованный индекс на основании схемы разбиения, а затем его удалить.
CREATE CLUSTERED INDEX cix_CustomerOrderList_OrderDate
ON dbo.CustomerOrderList (OrderDate)
ON OrderDates(OrderDate);
GO
DROP INDEX cix_CustomerOrderList_OrderDate ON dbo.CustomerOrderList;
GO Данные по отдельным годам разбиты на 20 лет, и результат выглядит следующим образом:
-- Давайте объединим всю информацию в обзоре
SELECT p.partition_number AS [Partition #],
CASE pf.boundary_value_on_right
WHEN 1 THEN 'Right / Lower'
ELSE 'Left / Upper'
END AS [Boundary Type],
prv.value AS [Boundary Point],
stat.row_count AS [Rows],
fg.name AS [Filegroup]
FROM sys.partition_functions AS pf
INNER JOIN sys.partition_schemes AS ps
ON ps.function_id=pf.function_id
INNER JOIN sys.indexes AS si
ON si.data_space_id=ps.data_space_id
INNER JOIN sys.partitions AS p
ON
(
si.object_id=p.object_id
AND si.index_id=p.index_id
)
LEFT JOIN sys.partition_range_values AS prv
ON
(
prv.function_id=pf.function_id
AND p.partition_number=
CASE pf.boundary_value_on_right
WHEN 1 THEN prv.boundary_id + 1
ELSE prv.boundary_id
END
)
INNER JOIN sys.dm_db_partition_stats AS stat
ON
(
stat.object_id=p.object_id
AND stat.index_id=p.index_id
AND stat.index_id=p.index_id
AND stat.partition_id=p.partition_id
AND stat.partition_number=p.partition_number
)
INNER JOIN sys.allocation_units as au
ON
(
au.container_id = p.hobt_id
AND au.type_desc ='IN_ROW_DATA'
)
INNER JOIN sys.filegroups AS fg
ON fg.data_space_id = au.data_space_id
ORDER BY
[Partition #];
GO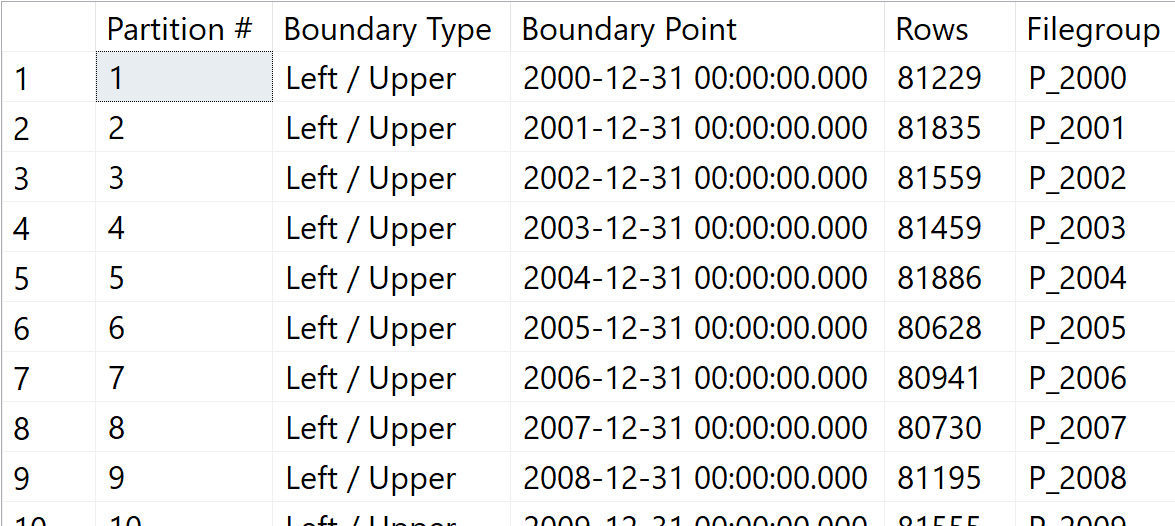
Рис.15: Куча с секционированными данными
Если ранее выполненный запрос выполняется на основе разбиения по столбцу предиката, то результаты демонстрируют совершенно отличное время исполнения:
-- Найти все заказы за 2016
SELECT * FROM dbo.CustomerOrderList
WHERE OrderDate >= '20160101'
AND OrderDate <= '20161231'
ORDER BY
Customer_Id,
OrderDate DESC
OPTION (QUERYTRACEON 9130);
GOMicrosoft SQL Server использует границы секций для идентификации того раздела, в котором должны находиться значения. Другие разделы больше не рассматриваются и, следовательно, "исключаются" из сканирования таблицы.
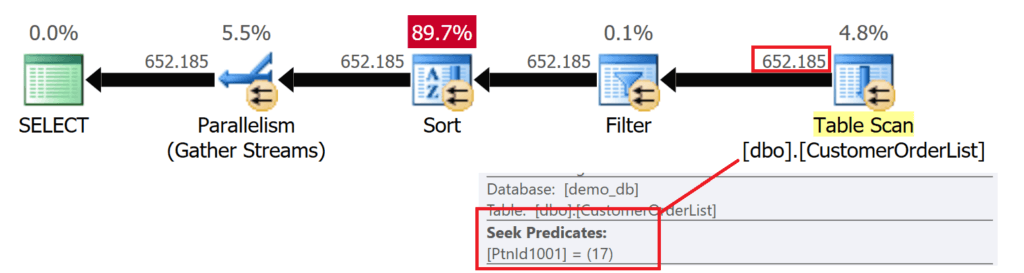
Рис.16: Исключение ненужных разделов
Время выполнения существенно не изменилось (не изменилось число записей данных, отправляемых клиенту!), но вы можете отчетливо увидеть, что нагрузка на процессор уменьшилась примерно на 25%.
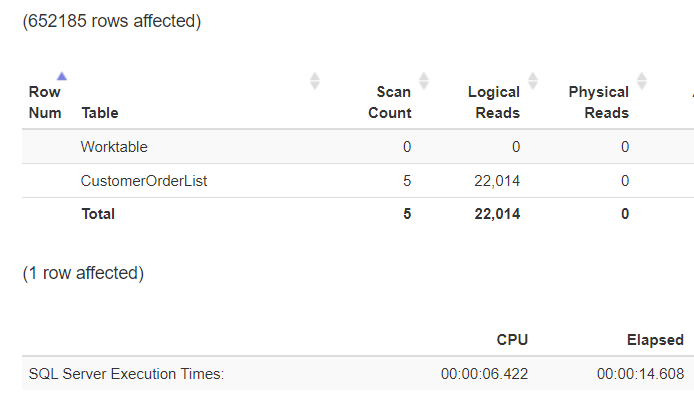
Рис.17: Уменьшение логических чтений за счет исключения разделов
Если вся рабочая нагрузка сосредоточена на вводе/выводе, а не на процессоре, то последняя возможность её уменьшения - сжатие данных на уровне разделов (секций)!
ALTER TABLE dbo.CustomerOrderList
REBUILD PARTITION = 17 WITH (DATA_COMPRESSION = ROW);
GO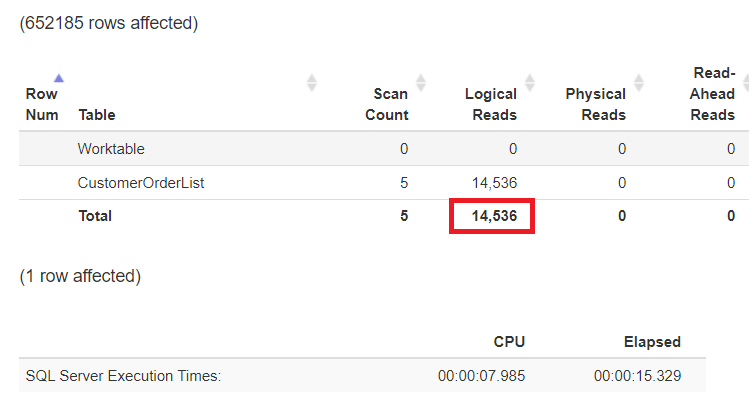
Рис.18: Логические чтения при выполненном секционировании и включенном сжатии
Заключение
Кучи безнадежно хуже индексов, если приходится выборочно извлекать данные. Однако если, например, для хранилища данных, требуется обработать большие объемы данных, куча может показать лучшую производительность. Надеюсь, что я смог продемонстрировать требования и технические возможности улучшения, если вы должны (или желаете) иметь дело с кучами.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой