
Кучи в SQL Server: часть 3 - некластеризованные индексы
Пересказ статьи Uwe Ricken. Heaps in SQL Server: Part 3 Nonclustered Indexes
Пока эта серия состоит из:
- Кучи в SQL Server: часть 1 - основы
- Кучи в SQL Server: часть 2 - оптимизация чтений
- Кучи в SQL Server: часть 3 - некластеризованные индексы (эта статья)
В предыдущей статье описывалось как можно оптимизировать выборку данных из кучи. Настоящая статья посвящена возможности достижения оптимального времени выполнения запроса для кучи с помощью некластеризованных индексов.
Некластеризованный индекс
Некластеризованный индекс - это структура индекса, который отделен от данных в таблице. При этом данные могут находиться быстрей, чем с помощью поиска в самой таблице. Как правило, некластеризованные индексы создаются для улучшения производительности часто используемых запросов, которые не покрываются кластеризованным индексом или кучей.
Демонстрация
Поскольку куча не сортирует данные по ключевому атрибуту, только некластеризованный индекс может сформировать ссылку, используя положение записи данных в куче. Положение записи данных в куче определяется тремя элементами информации:
- Номер файла
- Страница данных
- Слот
Эти три элемента информации записываются в качестве ссылки в каждом некластеризованном индексе для фактического ключа индекса.
Для работы с примерами обратитесь к предыдущей статье. Используется таблица с приблизительно 4000000 записями данных.
К этой таблице очень часто обращаются пользователи для вывода заказов за определенный период. Поскольку не существует индекса на атрибуте OrderDate, всегда должно выполняться сканирование таблицы.
SELECT * FROM dbo.CustomerOrderList
WHERE OrderDate = '20081220'
OPTION (QUERYTRACEON 9130);
GO
Использование сканирования таблицы видно в плане выполнения на рис.1.
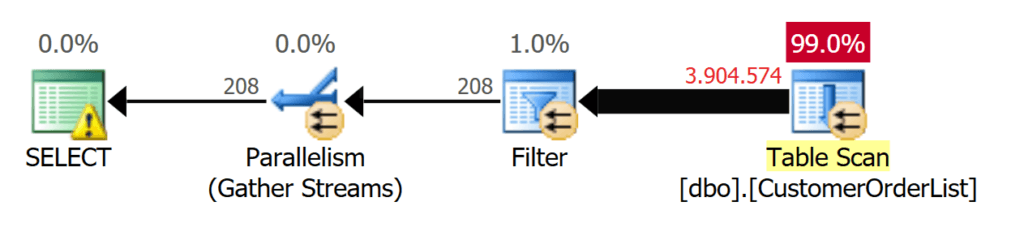
Рис.1: TABLE SCAN используется для получения 208 записей
Сканирования таблицы может быть достаточно быстрым на быстрых системах (0,716 секунд), и программиста может устроить такой временной интервал.
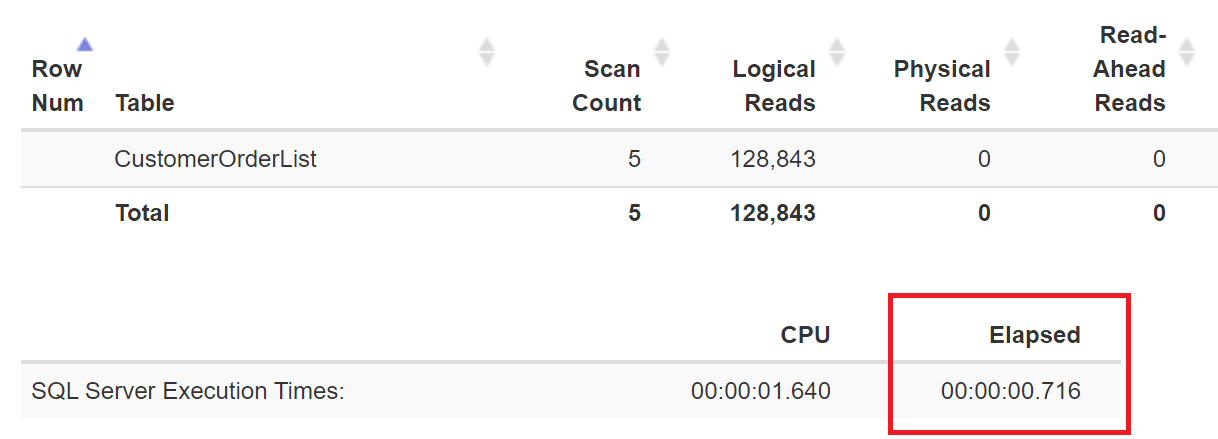
Рис.2: ЦП используется более 1,6 секунды, и затраченное время 0,716 секунды
Высокое время ЦП обусловлено тем фактом, что запрос использует параллельное выполнение, показанное на рис.3.
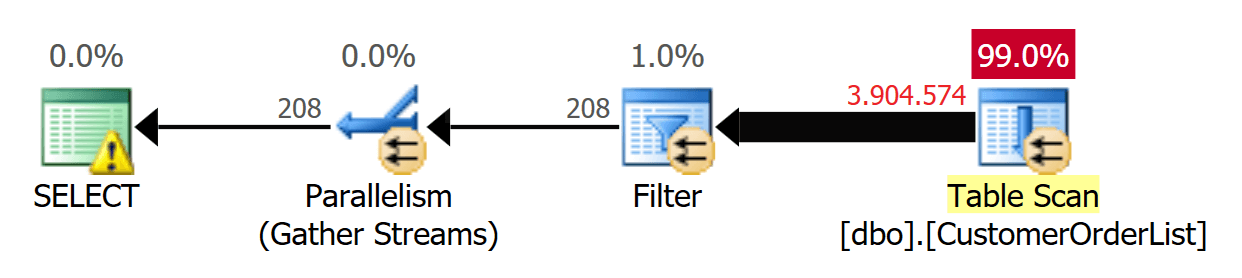
Рис.3: Параллельный план
К сожалению, часто игнорируются следующие моменты, которые имеют к этому отношение, вне зависимости от времени:
- Запрос распараллеливается и использует процессоры, сконфигурированные для MAXDOP!
- Блокировка [SCH-S] удерживается на таблице во все время выполнения!
- Что происходит, если не только один пользователь выполнит запрос, но также имеется веб-клиент, выполняющий параллельно тысячи запросов?
По указанным причинам рекомендуется оптимизировать запрос. Чтобы оптимизировать запрос, создается некластеризованный индекс на атрибуте OrderDate.
CREATE NONCLUSTERED INDEX nix_CustomerOrderList_OrderDate
ON dbo.CustomerOrderList (OrderDate);
GOЕсли вы снова выполните тот же запрос из предыдущего примера, то получите следующее улучшение, показанное на рисунке 4:
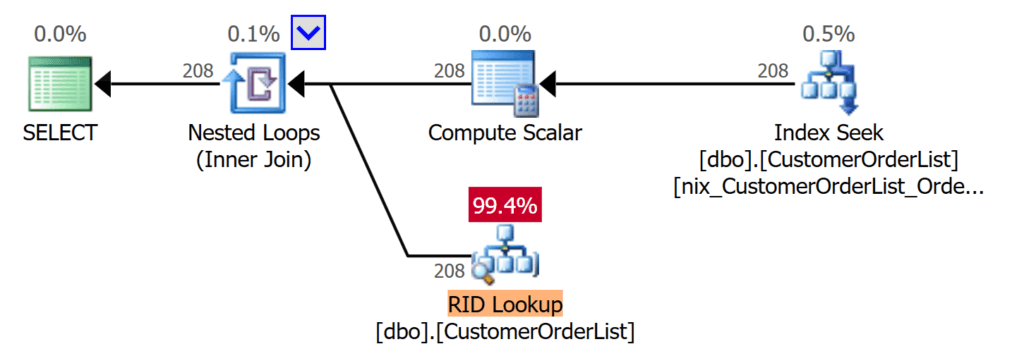
Рис.4: Уменьшается число операций ввода/вывода при использовании подходящего индекса
Теперь запрос уже не сканирует таблицу, и время выполнения также существенно уменьшилось, что видно на рисунке 5:
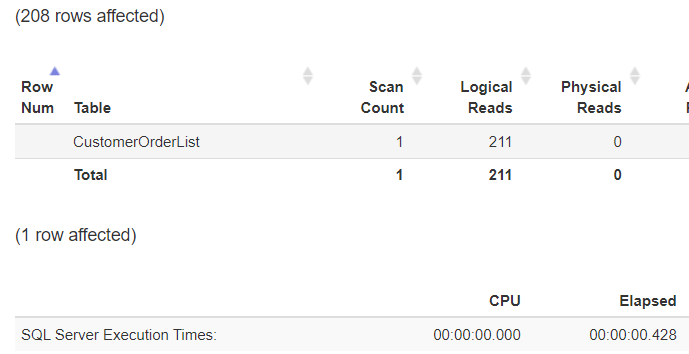
Рис.5: Нет избыточного использования ресурсов
Некоторые недостатки сканирования таблицы были устранены использованием индекса:
- Запрос больше не распараллеливается, поскольку его стоимость упала ниже порога параллелизации.
- Затраты ЦП больше не могут быть измерены.
- Только блокировка SCH-S все еще используется, однако, имея в виду время выполнения, возможно, это можно проигнорировать,
Можно сказать, что некластеризованные индексы дают большое преимущество!
Внутренние структуры
Некластеризованный индекс (НКИ) должен ВСЕГДА хранить ссылку на запись в таблице. Поскольку НКИ обычно содержит только несколько атрибутов таблицы, необходимо гарантировать, что атрибуты, которые не используются в НКИ, могут в любое время быть определены из таблицы. Эта ссылка хранится в куче как RID (RowLocatorID) и имеет размер 8 байт!
В примере выше запрос требует всего 211 операций ввода/вывода для извлечения данных. Если посмотреть план выполнения, можно увидеть использование ранее созданного индекса. Каждый индекс имеет структуру дерева со ссылками на следующий уровень. Это означает, что данные в индексе могут быть найдены быстро и эффективно. На рисунке 6 показана структура индекса.
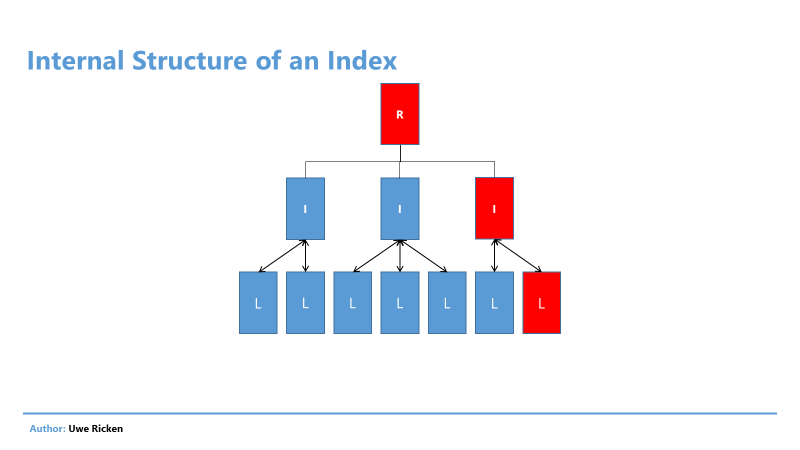
Рис.6: Поиск в структуре индекса B-Tree
Просмотр индекса показывает эту структуру. Для этого сначала должна быть определена страница данных, которая представляет корневой узел.
-- Получить информацию о корневом узле индекса
SELECT P.index_id,
SIAU.total_pages,
SIAU.used_pages,
SIAU.data_pages,
SIAU.root_page,
sys.fn_PhysLocFormatter(SIAU.root_page) AS root_page
FROM sys.system_internals_allocation_units AS SIAU
INNER JOIN sys.partitions AS P
ON (SIAU.container_id = P.partition_id)
WHERE P.object_id = OBJECT_ID(N'dbo.CustomerOrderList', N'U');
GOПодробная информация о структуре индекса, показанная на рисунке 7, получена с помощью системного dmv (динамического представления). Помним, что индексы с ID = 0 или ID = 1 представляют сами таблицы! ID = 0 - это куча, а ID = 1 представляет кластеризованный индекс. Все остальные индексы некластеризованные.

Рис.7: Индексы
Корневой узел в индексе nix_CustomerOrderList_OrderDate находится в файле #1 на странице данных 73346. Содержимое страницы данных можно проверить с помощью недокументированной команды DBCC PAGE.
DBCC TRACEON (3604);
DBCC PAGE (0, 1, 73346, 3);
GO
Можно увидеть, что индекс использует только атрибуты, указанные при его создании. Все остальные атрибуты должны читаться из самой таблицы!

Рис.8: Поиск 2008-12-20 должен быть продолжен на странице 73348
Для поиска заказов за 20 декабря 2008 должен использоваться атрибут OrderDate, чтобы найти предельное значение, в котором размещается искомая дата. Поиск продолжается на следующем уровне на странице 73348, пока не будет достигнут самый нижний уровень.
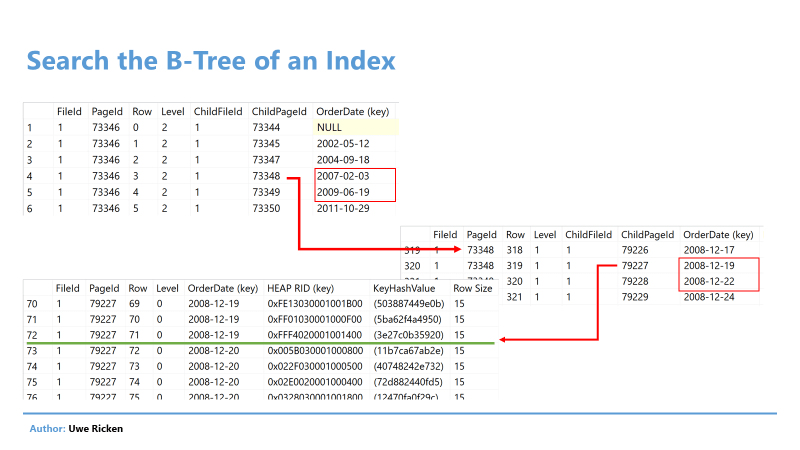
Рис.9: С помощью 3 операций ввода/вывода вы достигаете первой записи в индексе
Фактически требуется три операции ввода/вывода. Принимая во внимание общее число операций 211, становится ясно, что произойдет на следующем шаге. Поскольку индекс хранит только атрибут OrderDate, информация о других атрибутах записи данных отсутствует. Чтобы получить эту информацию, Microsoft SQL Server должен декодировать RID для получения страницы данных, где размещена запись.
RID хранится в индексе для каждой записи и имеет фиксированную длину 8 байтов. Эти 8 байтов содержат всю необходимую информацию для получения записи данных.

Рис.10: Положение набора данных как RID
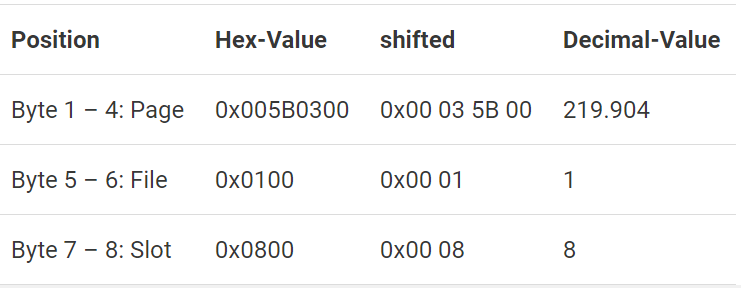
Запись, чья OrderDate представлена в индексе, находится в файле #1 на странице #219904 в слоте #8.
DBCC PAGE (0, 1, 219904, 3) WITH TABLERESULTS;
GO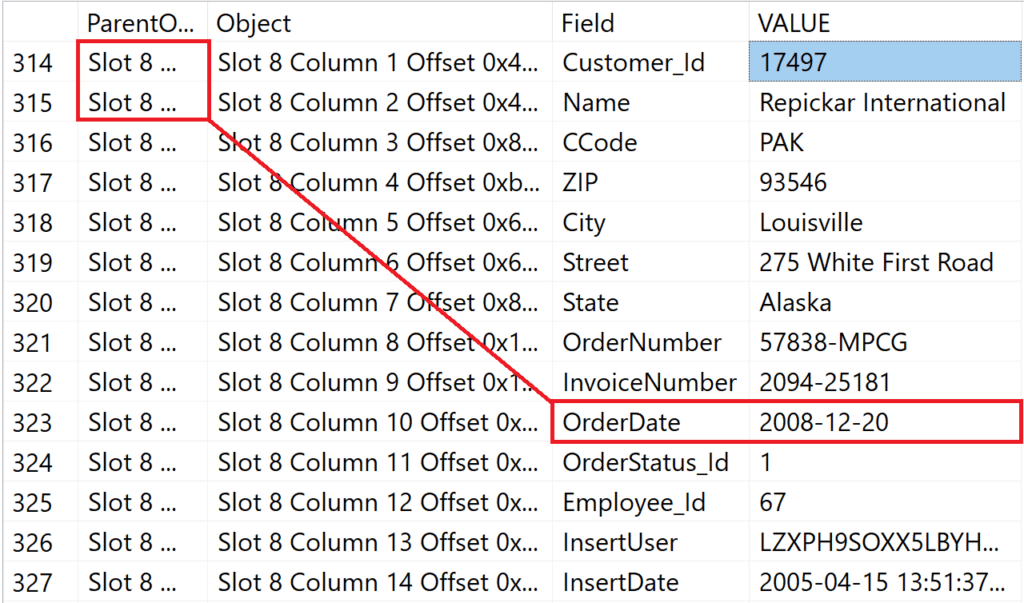
Рис.11: Содержимое слота #8
Процесс повторяется для каждой записи, найденной в индексе. Математика, стоящая за 211, довольно тривиальна: 3 операции ввода/вывода для поиска в индексе + 208*1 операций для ссылок на саму таблицу.
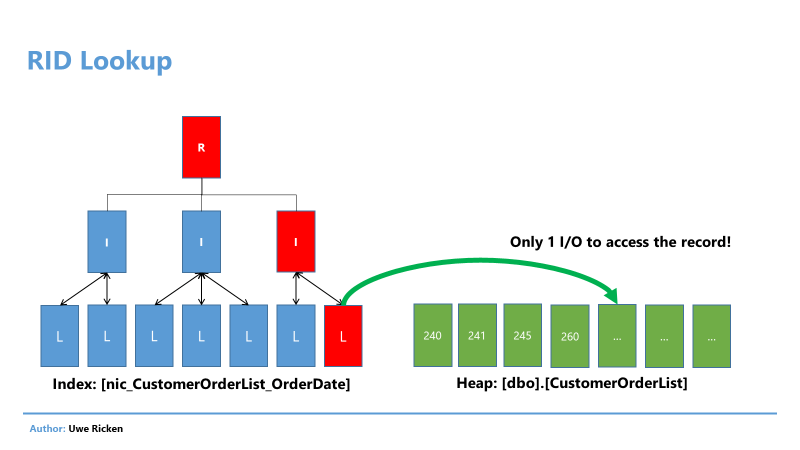
Рис.12: Доступ к куче по RID
Поиск RID против поиска ключа
В отличие от кучи, Microsoft SQL Server не может обратиться непосредственно к странице данных, на которой размещается запись, в таблице с кластеризованным индексом. При кластеризованном индексе Microsoft SQL Server сохраняет не положение записи данных в НКИ для таблицы со сгруппированным индексом, а значение ключа атрибута кластеризованного индекса.
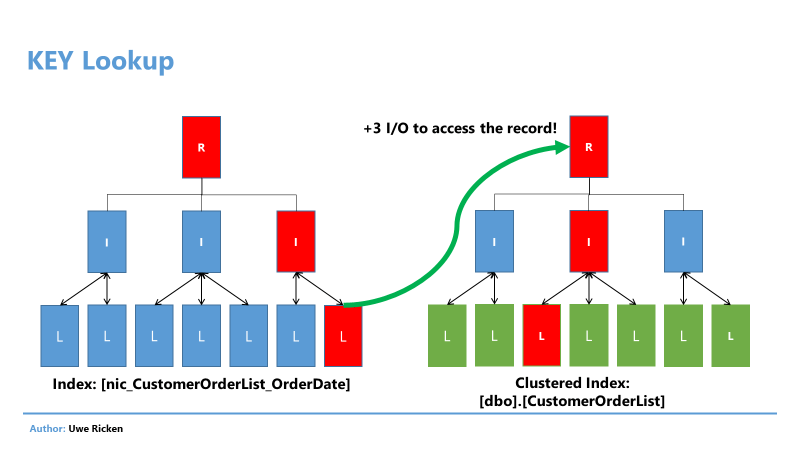
Рис.13: Дополнительные операции ввода/вывода при использовании кластеризованного индекса
Преимущество использования кластеризованного индекса заключается в обслуживании кластеризованных индексов, а не в производительности запросов (обсуждается в следующей статье). Сравнив один и тот же запрос для кучи и для кластеризованного индекса, можно обнаружить следующие различия в плане выполнения:
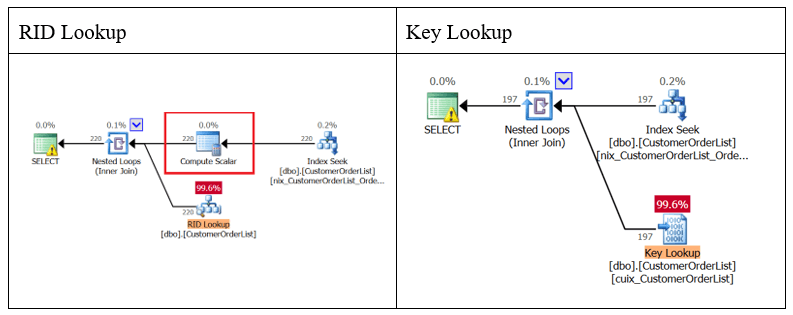
Рис.14: Сравнение планов с RID Lookup и Key Lookup
При поиске RID, потребуется преобразовывать RowLocatorID, что приведет (предположительно) к более высокой нагрузке на процессор. Одной из самых больших проблем в плане выполнения Microsoft SQL Server является оценка стоимости скалярных (SCALAR) операций. По умолчанию они оцениваются в 0%; однако тут забывается, что оператор должен выполняться для КАЖДОЙ записи, выходящей из предыдущего оператора.
Чтобы сделать обоснованное утверждение о стоимости преобразования, выполняется следующий код с SQLQueryStress Адама Мачаника и четырьмя потоками (число ЦП в тестовой машине):
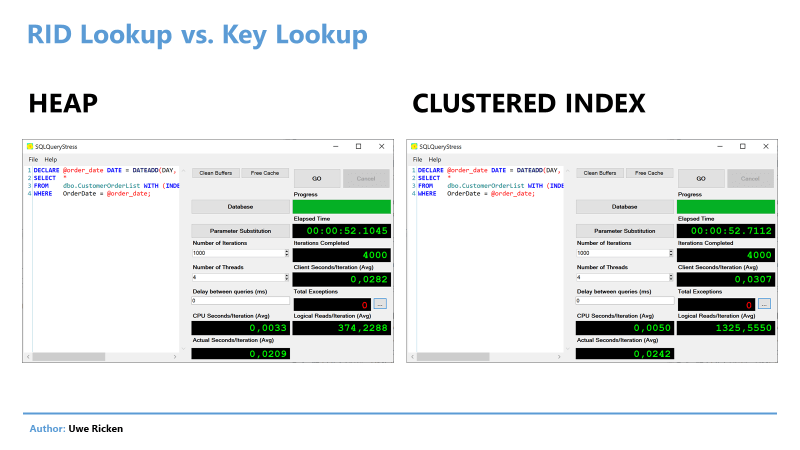
Рис.15: Сравнение производительности кучи и кластеризованного индекса
При непосредственном сравнении куча "побеждает" по всем позициям. Особенно интересно в этом сравнении тот факт, что нагрузка на процессор в 3,3 мс/итерация значительно ниже нагрузки для кластеризованного индекса (5мс).
Другое различие - не следует недооценивать - операции ввода/вывода на итерацию. Конечно, куча тут может набрать очки, поскольку требует одну операцию для доступа к таблице, в то время как кластеризованный индекс - 3 операции.
Выводы
Почему разработчики из команды Microsoft SQL Server так сильно сопротивляются кучам? Многие статьи в блогах известных экспертов в SQL Server постоянно указывают на преимущественное использование таблиц с кластеризованным индексом. В прошлом я всегда следовал этим рекомендациям, пока не прочитал пару статей, которые заставили меня думать иначе:
- Markus Wienand. Nonsensical defaults: primary key as cluster key
- Thomas Kejser. Clustered Index Vs. Heap
Я могу только предложить переосмыслить "общий" подход к использованию кластеризованных индексов. Я не собираюсь отрицать, что есть ситуации, когда кластеризованный индекс имеет смысл, а также преимущество; он определенно не требуется для чистых операций SELECT. Принцип при выборке данных - индексировать атрибуты, которые используются в качестве предиката и/или в операторе JOIN
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой