
Когда настройка параметра в PostgreSQL не помогает
Пересказ статьи Henrietta Dombrovskaya. When PostgreSQL Parameter Tuning is not the Answer
Так много говорится о настройке параметров, и это всегда помогает?
Добро пожаловать в третью и последнюю статью серии "магия параметров". В двух предыдущих статьях мы обсудили, как настройка параметров PostgreSQL может помочь улучшить общую производительность системы. Однако самый первый параграф самой первой статьи этой темы утверждает, что:
Хотя некоторая настройка параметров действительно может улучшить производительность базы данных, мы обычно говорим о 10%, 20% и в более редких случаях о 50% улучшении производительности, если некоторые параметры установлены плохо. Эти цифры могут звучать впечатляюще, но индивидуальная рутинная оптимизация запроса делает его выполнение в несколько раз быстрее, а в некоторых случаях в десять и более раз быстрее, а реструктуризация приложений может улучшить общую производительность системы в сотни раз!
В той первой статье мы не приводили никаких примеров практического влияния настройки параметров на производительность. В самом деле, непросто смоделировать такое влияние на учебной базе данных.
В этой статье мы перейдем от обсуждения лучшего применения системных параметров PostgreSQL к другим способам настройки производительности. Кроме того, мы продемонстрируем, что существенная настройка производительности базы данных лежит за пределами выбора подходящих установок параметров.
Имея это в виду, давайте проверим влияние изменения параметров и альтернативных способов настройки производительности. Для выполнения наших экспериментов мы будем использовать базу данных, которую я создала для примеров настройки производительности: база данных postgres_air. Если вы хотите повторить эксперименты, описанные в этой статье, загрузите последнюю версию этой базы данных (файл postges_air_2023.backup) и восстановите его на экземпляре Postgres, где вы собираетесь выполнять эти эксперименты. Мы предполагаем, что вы делаете это на своем персональном устройстве или любом другом экземпляре, где вы имеете полный контроль над тем, что вы делаете, поскольку вам потребуется перезапускать экземпляр пару раз во время экспериментов. Мы выполняли примеры на версии 15.2, однако они будут работать так же, по меньшей мере, на версиях 13 и 14.
Восстановление базы создаст схему postgres_air, наполненную данными, но без индексов, за исключением тех, которые поддерживают ограничения уникальности. Чтобы иметь возможность продублировать примеры, вам потребуется создать пару дополнительных индексов:
Давайте проверим план выполнения запроса, который вычисляет число пассажиров на каждом рейсе:
Сначала мы выполним его с параметрами выделения памяти по умолчанию:
Замечание: чтобы проверить установки параметров, вы можете выполнить команду show all для получения полного списка параметров или show <имя_параметра> для получения значения конкретного параметра. Поэтому выполнение SHOW work_mem вернет текущую установку этого параметра.
Чтобы гарантировать, что мы вычисляем не только сам план выполнения, но также фактические время выполнения и использование буфера, выполните команду EXPLAIN со следующими параметрами:
План выполнения этого запроса представлен на Рисунке 1. Ваши результаты могут немного отличаться, особенно в том, что касается фактических чисел, но должны быть очень похожи, если вы восстановили копию базы данных Air и добавили индексы, которые мы указали. План запроса будет представлен в тексте, как и результирующий набор в любом инструменте, который вы используете.

Рисунок 1. План выполнения с выделением памяти по умолчанию
Глядя на этот план, можно увидеть, что оптимизатор использует два индекса на таблице flight,
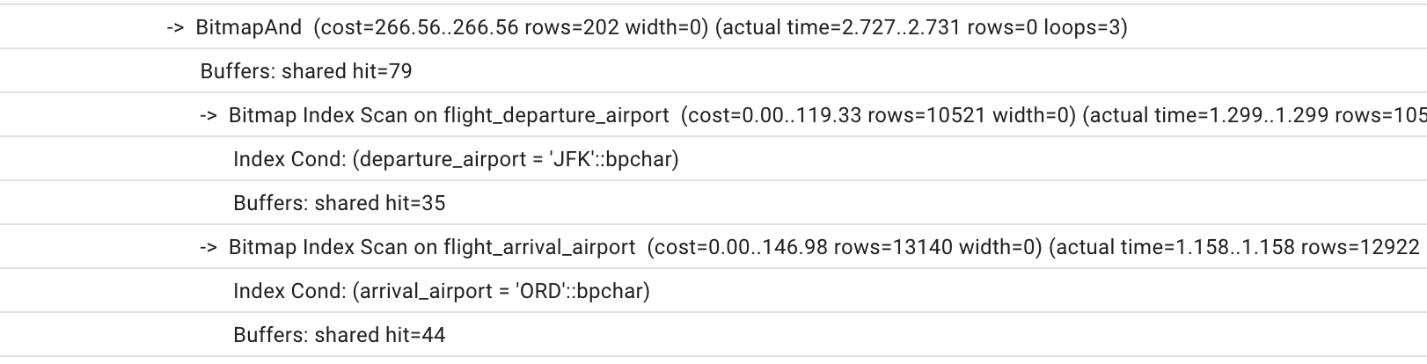
а затем сканирует все блоки, проверяя фактическое отправление.

Мы можем также отметить, что число общих буферов недостаточно (чтобы достичь согласующихся результатов, выполните тот же запрос или EXPLAIN ANALYZE более одного раза) и что PostgreSQL для ускорения процесса выбрал вариант с двумя параллельными рабочими потоками. Общее время выполнения небольшое, но превышает одну секунду.
Поскольку мы не моделируем эффект множества одновременно выполняющихся запросов, параметрами, которые могли оказать существенное влияние на время выполнения запроса, являются shared_buffers (изменение требует перезапуска) и work_mem (может быть изменено в рамках сессии). Давайте сначала попытаемся увеличить размер work_mem, а затем изменим параметр shared_buffers на 1 Гб, перезапустим кластер баз данных и повторим изменения work_mem.
Изменение параметра work_mem не требует перезапуска - вы можете изменить его локально для текущей сессии и повторить эксперимент. Постепенно увеличивая work_mem вплоть до 1 Гб, мы не замечаем каких-нибудь значительных изменений в плане и времени выполнения. Ограничивающим фактором, видимо, является недостаточный размер shared_buffers. Мы не видим никакого использования диска, означающее, что work_mem было достаточно изначально.
На рисунке 2 представлен план выполнения при shared_buffers=128Мб и work_mem=500Мб. Общее время выполнения колеблется в районе 1 секунды на моем компьютере для этих текущих параметров. План после изменения:

Рисунок 2. План выполнения при увеличенном work_mem и принимаемом по умолчанию shared_buffers
Давайте теперь увеличим shared_buffers до 1Гб. Чтобы это сделать, вам потребуется отредактировать этот параметр в файле postgresql.conf и перезапустить экземпляр PostgreSQL. Прежде чем начать измерять время выполнения, выполните этот запрос пару раз, чтобы убедиться, что общие буферы подходят.
К сожалению, уменьшение времени выполнения будет незначительным. План выполнения остается тем же с единственным отличием в немного меньшем числе чтений, благодаря увеличенному shared_buffers (смотри на рисунке 3 часть плана выполнения)

Рисунок 3. Часть плана выполнения с увеличенным значением shared_buffers, который показывает меньшее число чтений, чем на рисунке 2.
Если мы продолжим увеличивать work_mem до 200Мб, 500Мб, 1Гб, то заметим медленное уменьшение времени выполнения, достигающее в конце концов 750мс. Однако нам следует иметь в виду, что такое увеличение work_mem не будет возможным на промышленном сервере при одновременном выполнении множества сессий. Так или иначе, это запрос не кажется слишком уж сложным. Есть ли другие способы улучшить производительность?
Глядя на все планы выполнения, произведенными во время наших экспериментов, можно заметить один главный недостаток: PostgreSQL должен был читать кучу (строки таблицы), чтобы найти записи, у которых фактическое отправление находится в диапазоне между 8 и 12 августа. Это говорит о том, что может помочь индекс на этом атрибуте. Давайте двинемся в этом направлении и создадим отсутствующий индекс:
Сразу станет заметной разница в плане выполнения (смотри рисунок 4).

Рисунок 4. Усеченный план выполнения с индексом на столбце actual_departure
Мы также можем увидеть, что время выполнения наконец-то стало уменьшаться, и мы дошли до времени выполнения 0,5 с. Однако эта разница все еще не столь существенная, как нам хотелось бы. Продолжая исследовать план выполнения, мы замечаем, что Postgres выполняет полное сканирование таблицы passenger (смотри рисунок 5).
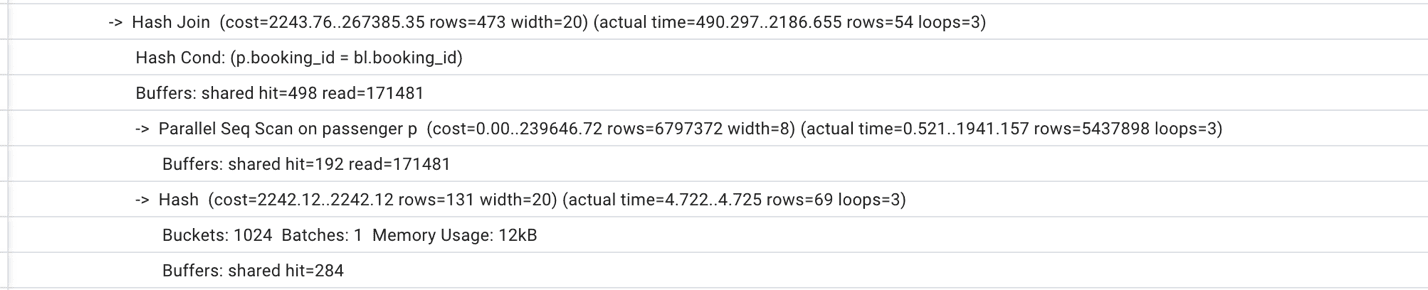
Рисунок 5. Часть плана выполнения с полным сканированием таблицы
Глядя на условие соединения и ограничение внешнего ключа поля booking_id, мы может сделать вывод, что может помочь индекс на booking_id. Действительно, если мы создадим новый индекс:
план выполнения изменится радикально - смотри рисунок 6. Теперь общее время выполнения всего лишь 10мс, что в пятьдесят раз меньше, чем лучшее время за счет настройки параметров.

Рисунок 6. План выполнения с двумя индексами
Более важно, что если мы откатим системные параметры к их значениям по умолчанию и уменьшим shared_buffers до 128Мб, ни в плане выполнения, ни во времени выполнения ничего не изменится. Ничего удивительного - внимательно рассмотрев новый план выполнения на рисунке 6, мы можем увидеть, что, поскольку нам не потребовались объемные сканирования таблиц, нам не потребовалось и так много общих буферов!
Когда мы думаем о значении конфигурационных параметров в Postgres, важно помнить, что все, что мы делаем, является, по сути взаимодействием планировщика запросов с доступными аппаратными ресурсами. Postgres знает, какой объем памяти имеется на хосте, где он запущен, какой тип хранилища используется, сколько ядер процессора доступно и какие еще системы выполняются на том же самом хосте. Мы предоставляем некоторые "входные параметры" для оптимизации посредством установки параметров в указанные значения.
Например, если мы определим shared_buffers=128MB, в то время как на хосте имеется 16Гб оперативной памяти, планировщик не сможет использовать большую часть этой памяти. Однако может быть выбран другой способ ускорить запросы, например, выполнение его на множестве параллельных процессов, что мы видели на рисунках 1 - 3.
Обратное также верно. Если мы имеем те же самые 16Гб оперативной памяти и выделяем 4Гб на общие буферы, то же время устанавливая значения по умолчанию work_mem=200MB и max_connections=700, есть большая вероятность того, что Postgres спровоцирует ошибку “out of memory” (не хватает памяти) из операционной системы.
Другой пример. Параметр random_page_cost помогает оптимизатору оценить стоимость доступа на основе индексов. Значение по умолчанию 4 в более старых версиях Postgres отражало характеристики дисков, которые были доступны десять лет назад. Теперь сохранение этого значения на уровне 4 может помешать оптимизатору выбрать лучший план выполнения. Однако если мы уменьшим это значение для системы, в которой используются медленные диски, результат будет противоположный.
Хотя важно установить конфигурационные параметры Postgres наилучшим образом для конкретной системы, этого будет далеко не достаточно для достижения наилучшей производительности. Как было продемонстрировано, настройка параметров системы обычно помогает улучшить производительность системы на десять или двадцать процентов, а в некоторых случаях, возможно, и выше. В то же время, создание отсутствующих индексов может заставить запрос выполняться в десять раз быстрее и, в то же время, сократить использование ресурсов.
В последующих статьях серии мы поговорим о многочисленных методах, которые делают такую оптимизацию возможной.
Ссылки по теме
1. Понимание CRUD операций, адресованных к куче, и указатели пересылки
2. Введение в B-Tree и хэш-индексы в PostgreSQL
3. Проектирование индекса в базах данных и оптимизация: некоторые рекомендации
4. Типы индексов в PostgreSQL: изучаем PostgreSQL вместе с Grant Fritchey
В этой статье мы перейдем от обсуждения лучшего применения системных параметров PostgreSQL к другим способам настройки производительности. Кроме того, мы продемонстрируем, что существенная настройка производительности базы данных лежит за пределами выбора подходящих установок параметров.
Измерение влияния
Имея это в виду, давайте проверим влияние изменения параметров и альтернативных способов настройки производительности. Для выполнения наших экспериментов мы будем использовать базу данных, которую я создала для примеров настройки производительности: база данных postgres_air. Если вы хотите повторить эксперименты, описанные в этой статье, загрузите последнюю версию этой базы данных (файл postges_air_2023.backup) и восстановите его на экземпляре Postgres, где вы собираетесь выполнять эти эксперименты. Мы предполагаем, что вы делаете это на своем персональном устройстве или любом другом экземпляре, где вы имеете полный контроль над тем, что вы делаете, поскольку вам потребуется перезапускать экземпляр пару раз во время экспериментов. Мы выполняли примеры на версии 15.2, однако они будут работать так же, по меньшей мере, на версиях 13 и 14.
Восстановление базы создаст схему postgres_air, наполненную данными, но без индексов, за исключением тех, которые поддерживают ограничения уникальности. Чтобы иметь возможность продублировать примеры, вам потребуется создать пару дополнительных индексов:
SET search_path TO postgres_air;
CREATE INDEX flight_departure_airport ON
flight(departure_airport);
CREATE INDEX flight_arrival_airport ON
flight(arrival_airport);
CREATE INDEX flight_scheduled_departure ON
flight (scheduled_departure);Давайте проверим план выполнения запроса, который вычисляет число пассажиров на каждом рейсе:
SELECT f.flight_no,
f.actual_departure,
count(passenger_id) passengers
FROM postgres_air.flight f
JOIN postgres_air.booking_leg bl
ON bl.flight_id = f.flight_id
JOIN postgres_air.passenger p
ON p.booking_id=bl.booking_id
WHERE f.departure_airport = 'JFK'
AND f.arrival_airport = 'ORD'
AND f.actual_departure BETWEEN
'2023-08-08' and '2023-08-12'
GROUP BY f.flight_id, f.actual_departure;Сначала мы выполним его с параметрами выделения памяти по умолчанию:
shared_buffers=128MB
work_mem=4MBЗамечание: чтобы проверить установки параметров, вы можете выполнить команду show all для получения полного списка параметров или show <имя_параметра> для получения значения конкретного параметра. Поэтому выполнение SHOW work_mem вернет текущую установку этого параметра.
Чтобы гарантировать, что мы вычисляем не только сам план выполнения, но также фактические время выполнения и использование буфера, выполните команду EXPLAIN со следующими параметрами:
EXPLAIN (ANALYZE, BUFFERS, TIMING)
SELECT … План выполнения этого запроса представлен на Рисунке 1. Ваши результаты могут немного отличаться, особенно в том, что касается фактических чисел, но должны быть очень похожи, если вы восстановили копию базы данных Air и добавили индексы, которые мы указали. План запроса будет представлен в тексте, как и результирующий набор в любом инструменте, который вы используете.
Рисунок 1. План выполнения с выделением памяти по умолчанию
Глядя на этот план, можно увидеть, что оптимизатор использует два индекса на таблице flight,
а затем сканирует все блоки, проверяя фактическое отправление.
Мы можем также отметить, что число общих буферов недостаточно (чтобы достичь согласующихся результатов, выполните тот же запрос или EXPLAIN ANALYZE более одного раза) и что PostgreSQL для ускорения процесса выбрал вариант с двумя параллельными рабочими потоками. Общее время выполнения небольшое, но превышает одну секунду.
Поскольку мы не моделируем эффект множества одновременно выполняющихся запросов, параметрами, которые могли оказать существенное влияние на время выполнения запроса, являются shared_buffers (изменение требует перезапуска) и work_mem (может быть изменено в рамках сессии). Давайте сначала попытаемся увеличить размер work_mem, а затем изменим параметр shared_buffers на 1 Гб, перезапустим кластер баз данных и повторим изменения work_mem.
Изменение параметра work_mem не требует перезапуска - вы можете изменить его локально для текущей сессии и повторить эксперимент. Постепенно увеличивая work_mem вплоть до 1 Гб, мы не замечаем каких-нибудь значительных изменений в плане и времени выполнения. Ограничивающим фактором, видимо, является недостаточный размер shared_buffers. Мы не видим никакого использования диска, означающее, что work_mem было достаточно изначально.
На рисунке 2 представлен план выполнения при shared_buffers=128Мб и work_mem=500Мб. Общее время выполнения колеблется в районе 1 секунды на моем компьютере для этих текущих параметров. План после изменения:
Рисунок 2. План выполнения при увеличенном work_mem и принимаемом по умолчанию shared_buffers
Давайте теперь увеличим shared_buffers до 1Гб. Чтобы это сделать, вам потребуется отредактировать этот параметр в файле postgresql.conf и перезапустить экземпляр PostgreSQL. Прежде чем начать измерять время выполнения, выполните этот запрос пару раз, чтобы убедиться, что общие буферы подходят.
К сожалению, уменьшение времени выполнения будет незначительным. План выполнения остается тем же с единственным отличием в немного меньшем числе чтений, благодаря увеличенному shared_buffers (смотри на рисунке 3 часть плана выполнения)
Рисунок 3. Часть плана выполнения с увеличенным значением shared_buffers, который показывает меньшее число чтений, чем на рисунке 2.
Если мы продолжим увеличивать work_mem до 200Мб, 500Мб, 1Гб, то заметим медленное уменьшение времени выполнения, достигающее в конце концов 750мс. Однако нам следует иметь в виду, что такое увеличение work_mem не будет возможным на промышленном сервере при одновременном выполнении множества сессий. Так или иначе, это запрос не кажется слишком уж сложным. Есть ли другие способы улучшить производительность?
Если ли лучшие способы настроить этот запрос?
Глядя на все планы выполнения, произведенными во время наших экспериментов, можно заметить один главный недостаток: PostgreSQL должен был читать кучу (строки таблицы), чтобы найти записи, у которых фактическое отправление находится в диапазоне между 8 и 12 августа. Это говорит о том, что может помочь индекс на этом атрибуте. Давайте двинемся в этом направлении и создадим отсутствующий индекс:
CREATE INDEX flight_actual_departure
ON postgres_air.flight (actual_departure);Сразу станет заметной разница в плане выполнения (смотри рисунок 4).
Рисунок 4. Усеченный план выполнения с индексом на столбце actual_departure
Мы также можем увидеть, что время выполнения наконец-то стало уменьшаться, и мы дошли до времени выполнения 0,5 с. Однако эта разница все еще не столь существенная, как нам хотелось бы. Продолжая исследовать план выполнения, мы замечаем, что Postgres выполняет полное сканирование таблицы passenger (смотри рисунок 5).
Рисунок 5. Часть плана выполнения с полным сканированием таблицы
Глядя на условие соединения и ограничение внешнего ключа поля booking_id, мы может сделать вывод, что может помочь индекс на booking_id. Действительно, если мы создадим новый индекс:
CREATE INDEX IF NOT EXISTS passenger_booking_id
ON postgres_air.passenger (booking_id);план выполнения изменится радикально - смотри рисунок 6. Теперь общее время выполнения всего лишь 10мс, что в пятьдесят раз меньше, чем лучшее время за счет настройки параметров.
Рисунок 6. План выполнения с двумя индексами
Более важно, что если мы откатим системные параметры к их значениям по умолчанию и уменьшим shared_buffers до 128Мб, ни в плане выполнения, ни во времени выполнения ничего не изменится. Ничего удивительного - внимательно рассмотрев новый план выполнения на рисунке 6, мы можем увидеть, что, поскольку нам не потребовались объемные сканирования таблиц, нам не потребовалось и так много общих буферов!
Другие ограничения настройки параметров
Когда мы думаем о значении конфигурационных параметров в Postgres, важно помнить, что все, что мы делаем, является, по сути взаимодействием планировщика запросов с доступными аппаратными ресурсами. Postgres знает, какой объем памяти имеется на хосте, где он запущен, какой тип хранилища используется, сколько ядер процессора доступно и какие еще системы выполняются на том же самом хосте. Мы предоставляем некоторые "входные параметры" для оптимизации посредством установки параметров в указанные значения.
Например, если мы определим shared_buffers=128MB, в то время как на хосте имеется 16Гб оперативной памяти, планировщик не сможет использовать большую часть этой памяти. Однако может быть выбран другой способ ускорить запросы, например, выполнение его на множестве параллельных процессов, что мы видели на рисунках 1 - 3.
Обратное также верно. Если мы имеем те же самые 16Гб оперативной памяти и выделяем 4Гб на общие буферы, то же время устанавливая значения по умолчанию work_mem=200MB и max_connections=700, есть большая вероятность того, что Postgres спровоцирует ошибку “out of memory” (не хватает памяти) из операционной системы.
Другой пример. Параметр random_page_cost помогает оптимизатору оценить стоимость доступа на основе индексов. Значение по умолчанию 4 в более старых версиях Postgres отражало характеристики дисков, которые были доступны десять лет назад. Теперь сохранение этого значения на уровне 4 может помешать оптимизатору выбрать лучший план выполнения. Однако если мы уменьшим это значение для системы, в которой используются медленные диски, результат будет противоположный.
Заключение
Хотя важно установить конфигурационные параметры Postgres наилучшим образом для конкретной системы, этого будет далеко не достаточно для достижения наилучшей производительности. Как было продемонстрировано, настройка параметров системы обычно помогает улучшить производительность системы на десять или двадцать процентов, а в некоторых случаях, возможно, и выше. В то же время, создание отсутствующих индексов может заставить запрос выполняться в десять раз быстрее и, в то же время, сократить использование ресурсов.
В последующих статьях серии мы поговорим о многочисленных методах, которые делают такую оптимизацию возможной.
Ссылки по теме
1. Понимание CRUD операций, адресованных к куче, и указатели пересылки
2. Введение в B-Tree и хэш-индексы в PostgreSQL
3. Проектирование индекса в базах данных и оптимизация: некоторые рекомендации
4. Типы индексов в PostgreSQL: изучаем PostgreSQL вместе с Grant Fritchey
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой