
Понимание CRUD операций, адресованных к куче, и указатели пересылки
Пересказ статьи Mohsin Khan. Understanding CRUD Operations Against Heaps and Forwarding Pointers
Введение
Транзакции языка манипуляции данными (DML) являются ключевыми для любой рабочей нагрузки, которая выполняется на SQL Server. Твердые знания того, что происходит под капотом, когда вы выполняете оператор DML, имеют решающее значение для написания более производительного кода. В этой статье мы посмотрим изнутри на три основных оператора DML, выполняемых на куче: вставка, обновление и удаление. Мы начнем с понимания того, что происходит внутри, когда каждый из этих трех операторов DML выполняется на куче. Затем мы разберемся с тем, что представляют собой указатели пересылки (forwarding pointers), и что вызывает их появление. Прочитав статью, вы должны понимать, почему SQL Server ведет себя так, а не иначе, при определенных шаблонах рабочей нагрузки DML на кучах, что вызывает появление указателей пересылки в кучах, и как управлять ими.
Важно понимать, что SQL Server никогда не выполняет операции DML непосредственно со страницами на диске. Он переносит их в ту часть памяти, которая называется буферным пулом, выполняет обновление там, выполняет синхронную запись в журнал транзакций, и асинхронно сохраняет "грязные" страницы в файле (файлах) данных на диске.
Куча - это просто таблица без кластеризованного индекса. Она не следует какому-либо логическому порядку расположения строк, поскольку не имеется ключевого столбца для упорядочения страниц. SQL Server использует страницы карты размещения индекса (IAM) для отслеживания и сканирования страниц данных, занятых таблицей.
Как показано на диаграмме ниже, куча - это стопка 8-килобайтных страниц данных. SQL Server просматривает все страницы данных для поиска записей, отвечающих критерию фильтрации оператора запроса, что выражается в плохой производительности из-за полного сканирования.
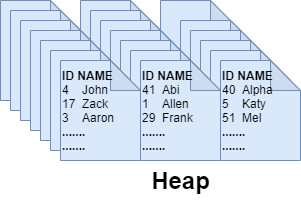
Куча
Для вставки строки в таблицу SQL Server должен найти место для ее хранения. Если таблица является кучей, SQL server вставляет её туда, где имеется достаточно места, поскольку в отличие от индекса B-Tree куча не поддерживает логического порядка. SQL Server использует IAM-страницы для нахождения экстентов, которые принадлежат соответствующей таблице, и, основываясь на этом, он использует PFS-страницы для отслеживания свободного пространства на страницах, записывая строку на страницу с достаточным местом для её размещения. Если на существующих страницах нет места, то SQL Server пытается найти нераспределенные страницы в пределах того же экстента, принадлежащего таблице. Если таких нет, он размещает новый экстент.
При вставке SQL Server должен проделать много работы по нахождению места для строки на страницах данных, в отличие от кластеризованного индекса, когда строка получает определенное размещение на основе ключа кластеризации, который диктует, где она должна находиться.
При удалении строки из кучи SQL Server автоматически не освобождает место и не удаляет данные на странице или перестраивает её. SQL Server физически не удаляет строки со страницы. Он просто устанавливает сдвиг удаленной строки в 0, указывая, что на это место может быть вставлена новая строка. Мы не только не реорганизуем место на странице после удаления, но и не возвращаем пустые страницы. Если мы удалим все строки на странице, SQL Server автоматически не освободит пустую страницу. Куча продолжит использовать страницу до тех пор, пока мы не перестроим таблицу кучи.
Среди пользователей SQL Server бытует миф, что пространство на странице, занятое удаленными строками никогда не используется повторно. Хотя верно, что страница не освобождается, пока мы не перестроим таблицу кучи, она доступна для любых будущих вставок. Если нам требуется пометить страницу свободной, то нужно либо перестроить таблицу кучи, используя операторalter table….rebuild, либо создать кластеризованный индекс для установления логического порядка для всех строк на основе ключа кластеризации. В обоих случаях, если имеются какие-либо некластеризованные индексы на таблице, они перестраиваются, когда идентификаторы строк кучи изменяются после перестроения или когда мы создаем на ней кластеризованный индекс, в котором идентификатор строки является ключом кластеризации.
Некластеризованные индексы должны использовать новые идентификаторы строк для связи строк из некластеризованного индекса с соответствующими строками в базовой таблице. Идентификаторы строк могут быть либо физическими адресами (RID) строк в куче, либо ключами кластеризации, если имеется кластеризованный индекс.
Обновления строк на странице могут происходить либо по месту, либо не по месту. Когда обновление изменяет строку новым значением, не перемещая строку на странице либо на другую страницу, это - обновление по месту. Измененная строка остается на том же месте той же страницы, и это справедливо независимо от того, является ли таблица кучей или таблицей с кластеризованным индексом. Если кластеризованный ключ меняется таким образом, что строка не перемещается со своего места и остается на той же странице в том же месте, мы рассматриваем это как обновление по месту с кластеризованным индексом.
Предположим, что обновление привело к перемещению строки на другую страницу или другое место на той же странице. В этом случае, мы считаем это обновлением не по месту, и оно происходит как удаление с последующей вставкой. Если удаление не по месту происходит в таблице кучи, это приводит к проблеме указателя пересылки, что вредит производительности.
В таблицах кучи обновление не по месту приводит к перемещению строки в другое место и размещением в исходном местоположении 16-байтовой строки с адресным указателем на новое местоположение строки. Эта 16-байтовая строка называется указателем пересылки, а новая строка, которая пересылалась, называется перенаправленной строкой (forwarded row). При этом вообще не требуется обновлять никакие некластеризованные индексы на таблице кучи. Если SQL Server должен выполнить поиск по некластеризованному индексу и использовать поиск RID в таблице кучи, он сначала перейдет к старому местоположению строки, а затем использует 16-байтовый указатель пересылки для перехода к местоположению, где теперь находится строка. Предположим, что перенаправленная строка обновляется снова с перемещением. В этом случае SQL Server обновляет указатель пересылки в исходном месте для отражения нового местоположения, тем самым избегая ситуации указателя пересылки, указывающего на другой указатель пересылки.
Другим преимуществом указателей пересылки является минимизация дублирующих чтений, когда отдельная строка читается несколько раз при сканировании таблицы в одной и той же транзакции. Скажем, например, что SQL Server сканирует страницы данных с 1 по 10. Мы читаем строку на странице 5, а SQL Server в настоящее время читает страницу 7. Обновление этой строки вызвало её перемещение на страницу 9, которую еще предстоит прочитать. Поскольку SQL Server идет последовательно слева направо, вы можете вообразить, что он должен повторно прочитать строку, когда он достигнет страницы 9; однако этого не происходит при наличии указателей пересылки. SQL Server идентифицирует бит в байте состояния A перенаправленной строки и игнорирует ее повторное чтение на странице 9, избегая тем самым дублирующих чтений.
Указатели пересылки приводят к множественным чтениям во время единственного поиска RID (RID lookup), что ухудшает производительность. Понятно, что указатели пересылки реально влияют на производительность, когда SQL Server выполняет тяжелые поиски RID, и существует много указателей пересылки. Указатели пересылки возникают, главным образом, в кучах, когда обновляются столбцы переменной длины, чтобы вместить значения, длиннее чем те, которые могли бы поместиться на прежнем месте. Это приводит к обновлению не по месту и перемещению строки в другое местоположение.
Это может заставить вас думать, что кучи обладают лучшей производительностью, чем таблицы с кластеризованным индексом. Поскольку, в отличие от поиска ключа в кластеризованном индексе, при котором SQL Server должен выполнить перемещение к корневой странице индекса, а затем к промежуточным страницам, чтобы достичь листовых страниц для чтения данных, поиски RID непосредственно переходят к фактическому физическому местоположению строки в базовой таблице кучи, что лучше с точки зрения производительности. Это до некоторой степени справедливо. Однако корневая и промежуточные страницы индекса, по большей части, находятся в памяти (буферном пуле). Таким образом, навигация по нелистовым страницам индекса требует минимального времени.
Влияние на производительность логических чтений по нелистовым страницам кластеризованного индекса во время поиска ключа минимально по сравнению с физическим вводом-выводом, выполняемым при поиске RID в кучах. Можно сказать, что кучи обычно выигрывают в производительности при вставке большого количества данных, но в целом выгоды наличия кластеризованного индекса намного перевешивают достоинства куч.
Если строка, перенаправленная в результате увеличения длины столбца, сжимается до соответствия оригинальному местоположению, строка может быть возвращена назад, и SQL server удалит указатель пересылки. То же самое происходит при сжатии базы данных. При операции сжатия базы данных перенаправленные строки перемещаются обратно на свои исходные места, если это возможно, и SQL Server удаляет пустые страницы, чтобы освободить место. Однако идеальным методом, чтобы избавиться от указателей пересылки, является создание кластеризованного индекса на таблице, который определяет порядок сортировки, в котором SQL Server сохраняет строки в индексе.
Мы можем удалить указатели пересылки перестройкой таблицы кучи с помощью оператора alter table…rebuild, но при перестройке кучи перестраиваются некластеризованные индексы на таблице кучи.
Посмотрим на указатели пересылки в действии.
Шаг 1: Давайте создадим новую базу данных с именем DML_DB и таблицу в ней. Вставим также пару строк по 3000 байт в каждой. Мы намереваемся оставить около 2000 байтов свободного пространства на странице.
Шаг 2: Используя динамическую административную функцию (DMF) sys.dm_db_index_physical_stats, мы можем увидеть, что есть только одна страница без перенаправленной записи. SQL Server разместил обе строки на одной странице.

Шаг 3: Давайте выполним три оператора обновления строки с ID = 1 поочередно, обращая внимание на то, какое из трех обновлений приведет к появлению указателя пересылки. Комментарии у каждого оператора поясняют происходящее.
Выполняя ту же динамическую административную функцию после третьего обновления, мы можем увидеть, что увеличение значения строки в результате обновления привело к её перемещению на новую страницу и созданию указателя пересылки в старом местоположении строки.

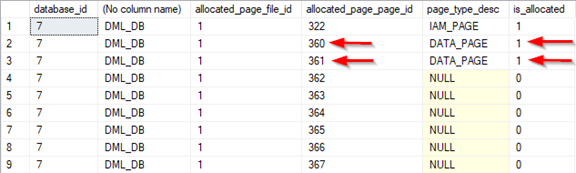
Шаг 4: Используя динамическую административную функцию sys.dm_db_database_page_allocations, проверим выделенные страницы и получим идентификаторы этих страниц и файлов.
Выделенный SQL Server восьмистраничный экстент состоит из двух страниц данных с идентификаторами страниц 360 и 361 и идентификатором файла 1.
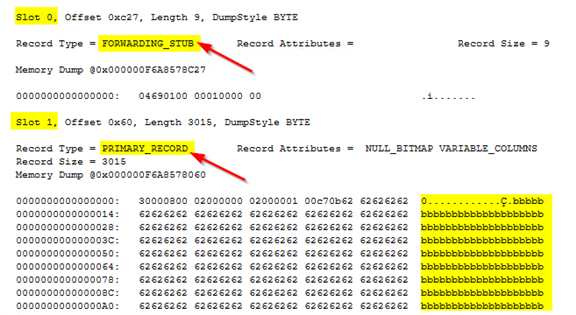
Шаг 5: Будем использовать недокументированную DBCC PAGE для проверки двух страниц данных. DBCC PAGE имеет следующие параметры: имя базы данных, идентификатор файла, идентификатор страницы, опции печати (0 - 3, 1 печатает заголовок страницы и дамп массива слотов каждой строки. Используйте флаг трассировки 3604 для отображения вывода в SSMS.
Ниже я покажу частичный вывод. Слот 0 показывает тип записи как FORWARDING_STUB, это означает, что в этом слоте была строка с ID = 1, Name = aaaa… 6000 раз.
И поскольку мы обновили строку на большее значение, чем может принять страница, она переместилась на страницу 361, а исходная строка на странице была заменена указателем пересылки. Следующая строка находится в слоте 1 с типом записи PRIMARY_RECORD, что показывает, что это обычная запись со значением bbbb...3000 раз. Значение столбца Name выделено справа.
В SQL Server 2019 появилась новая динамическая административная функция sys.dm_db_page_info, которая может чем-то заменить DBCC PAGE.

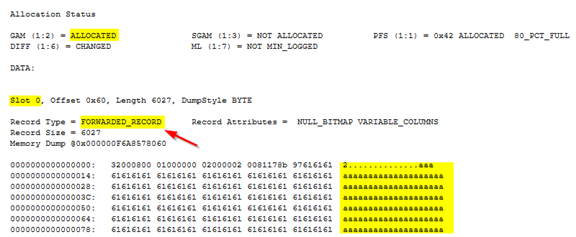
Шаг 6: Давайте исследуем страницу 361 и проверим, имеется ли на ней перенаправленная строка.
Она здесь! На странице 361 находится только одна запись, и её идентификатор = 1. Обратите внимание на тип записи - FORWARDED_RECORD, что подтверждает, что эта запись является перенаправленной.
Шаг 7: Давайте удалим единственную строку со страницы 361, чтобы она стала пустой, и проверим её.
Хотя страница пустая, поток уборки мусора не освободил её, поскольку это таблица кучи, и она остается выделенной. Также обратите внимание на то, что поскольку мы использовали опцию печати 1 в команде dbcc page, удаленная запись не показывается, но она по-прежнему физически присутствует на странице. Использование опции печати 2 показывает удаленную запись и байты, которые она занимает.

Шаг 8: Давайте перестроим таблицу и выясним, какие новые страницы выделяет SQL из-за перестройки.
Перестройка таблицы приводит к тому, что единственная строка (с id=2) перемещается на новую страницу 376. Таблица сейчас содержит только одну строку. Как вы помните, мы ранее удалили строку с id=1.
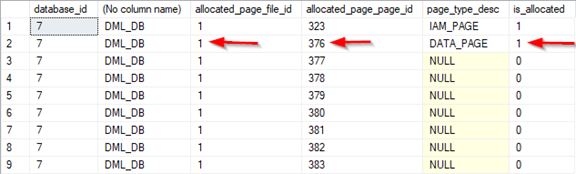
Давайте проверим старые страницы, которые ранее содержали две строки, т.е. страницы 361 и 360.
После перестройки кучи, страница 361, которая была бы в противном случае пуста, теперь показывает отсутствие выделения и доступна для новых вставок в эту таблицу.
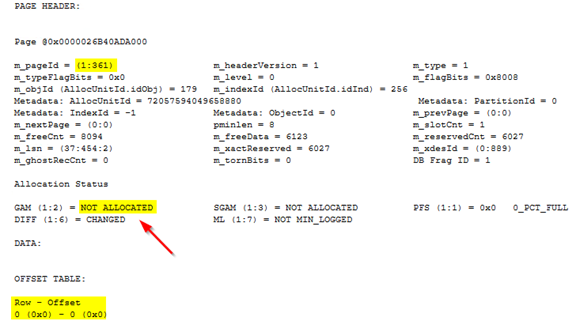
Страница 360, первоначально содержащая запись с id=2 (запись, которую SQL Server переместил на страницу 376 при перестройке), показывает отсутствие выделения и доступна для будущих вставок. Однако SQL физически не удалил записи с этой страницы. То же самое справедливо для страницы 361 (используйте опцию печати 2 в dbcc page).
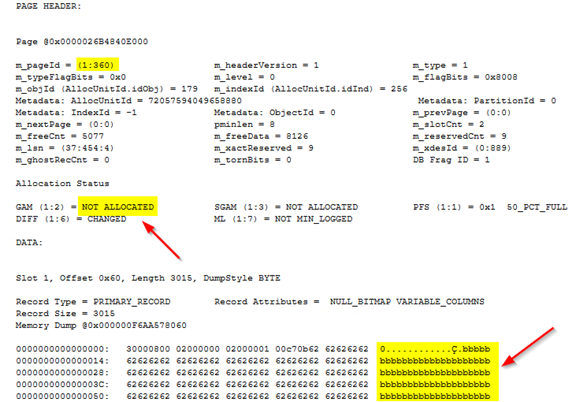
Мы удалили строки-призраки, выполнив вручную sp_clean_db_free_space.
Как правило большого пальца, всегда имейте кластеризованный индекс на таблицах, чтобы избежать указателей пересылки, если это не постановочная среда и имеет значение скорость вставки; в этом случае приемлемо применение куч. Указатели пересылки потенциально добавляют лишние физические чтения, когда SQL Server должен перейти с одной страницы с forwarding_stubs на другую страницу с forwarded_records в одной операции чтения, влияя на производительность. Указатели пересылки могут быть удалены при помощи перестройки таблицы кучи, но это приводит к перестройке некластеризованных индексов, которые имеют ссылки на кучу посредством физических идентификаторов строк. Наконец, SQL Server не освобождает пустые страницы в куче в процессе очистки призраков, и, чтобы решить эту проблему, нужно иметь либо кластеризованный индекс, либо перестроить таблицу.
Теперь, когда мы понимаем DML на кучах, в следующей статье мы посмотрим, что происходит при вставке, обновлении и удалении с индексами b-tree, и что вызывает расщепление страниц и, как результат, фрагментацию индекса.
DML на кучах
Куча - это просто таблица без кластеризованного индекса. Она не следует какому-либо логическому порядку расположения строк, поскольку не имеется ключевого столбца для упорядочения страниц. SQL Server использует страницы карты размещения индекса (IAM) для отслеживания и сканирования страниц данных, занятых таблицей.
Как показано на диаграмме ниже, куча - это стопка 8-килобайтных страниц данных. SQL Server просматривает все страницы данных для поиска записей, отвечающих критерию фильтрации оператора запроса, что выражается в плохой производительности из-за полного сканирования.
Куча
Вставка строк в кучу
Для вставки строки в таблицу SQL Server должен найти место для ее хранения. Если таблица является кучей, SQL server вставляет её туда, где имеется достаточно места, поскольку в отличие от индекса B-Tree куча не поддерживает логического порядка. SQL Server использует IAM-страницы для нахождения экстентов, которые принадлежат соответствующей таблице, и, основываясь на этом, он использует PFS-страницы для отслеживания свободного пространства на страницах, записывая строку на страницу с достаточным местом для её размещения. Если на существующих страницах нет места, то SQL Server пытается найти нераспределенные страницы в пределах того же экстента, принадлежащего таблице. Если таких нет, он размещает новый экстент.
При вставке SQL Server должен проделать много работы по нахождению места для строки на страницах данных, в отличие от кластеризованного индекса, когда строка получает определенное размещение на основе ключа кластеризации, который диктует, где она должна находиться.
Удаление строк из кучи
При удалении строки из кучи SQL Server автоматически не освобождает место и не удаляет данные на странице или перестраивает её. SQL Server физически не удаляет строки со страницы. Он просто устанавливает сдвиг удаленной строки в 0, указывая, что на это место может быть вставлена новая строка. Мы не только не реорганизуем место на странице после удаления, но и не возвращаем пустые страницы. Если мы удалим все строки на странице, SQL Server автоматически не освободит пустую страницу. Куча продолжит использовать страницу до тех пор, пока мы не перестроим таблицу кучи.
Среди пользователей SQL Server бытует миф, что пространство на странице, занятое удаленными строками никогда не используется повторно. Хотя верно, что страница не освобождается, пока мы не перестроим таблицу кучи, она доступна для любых будущих вставок. Если нам требуется пометить страницу свободной, то нужно либо перестроить таблицу кучи, используя операторalter table….rebuild, либо создать кластеризованный индекс для установления логического порядка для всех строк на основе ключа кластеризации. В обоих случаях, если имеются какие-либо некластеризованные индексы на таблице, они перестраиваются, когда идентификаторы строк кучи изменяются после перестроения или когда мы создаем на ней кластеризованный индекс, в котором идентификатор строки является ключом кластеризации.
Некластеризованные индексы должны использовать новые идентификаторы строк для связи строк из некластеризованного индекса с соответствующими строками в базовой таблице. Идентификаторы строк могут быть либо физическими адресами (RID) строк в куче, либо ключами кластеризации, если имеется кластеризованный индекс.
Обновление строк в таблице кучи
Обновления строк на странице могут происходить либо по месту, либо не по месту. Когда обновление изменяет строку новым значением, не перемещая строку на странице либо на другую страницу, это - обновление по месту. Измененная строка остается на том же месте той же страницы, и это справедливо независимо от того, является ли таблица кучей или таблицей с кластеризованным индексом. Если кластеризованный ключ меняется таким образом, что строка не перемещается со своего места и остается на той же странице в том же месте, мы рассматриваем это как обновление по месту с кластеризованным индексом.
Предположим, что обновление привело к перемещению строки на другую страницу или другое место на той же странице. В этом случае, мы считаем это обновлением не по месту, и оно происходит как удаление с последующей вставкой. Если удаление не по месту происходит в таблице кучи, это приводит к проблеме указателя пересылки, что вредит производительности.
Указатели пересылки
В таблицах кучи обновление не по месту приводит к перемещению строки в другое место и размещением в исходном местоположении 16-байтовой строки с адресным указателем на новое местоположение строки. Эта 16-байтовая строка называется указателем пересылки, а новая строка, которая пересылалась, называется перенаправленной строкой (forwarded row). При этом вообще не требуется обновлять никакие некластеризованные индексы на таблице кучи. Если SQL Server должен выполнить поиск по некластеризованному индексу и использовать поиск RID в таблице кучи, он сначала перейдет к старому местоположению строки, а затем использует 16-байтовый указатель пересылки для перехода к местоположению, где теперь находится строка. Предположим, что перенаправленная строка обновляется снова с перемещением. В этом случае SQL Server обновляет указатель пересылки в исходном месте для отражения нового местоположения, тем самым избегая ситуации указателя пересылки, указывающего на другой указатель пересылки.
Другим преимуществом указателей пересылки является минимизация дублирующих чтений, когда отдельная строка читается несколько раз при сканировании таблицы в одной и той же транзакции. Скажем, например, что SQL Server сканирует страницы данных с 1 по 10. Мы читаем строку на странице 5, а SQL Server в настоящее время читает страницу 7. Обновление этой строки вызвало её перемещение на страницу 9, которую еще предстоит прочитать. Поскольку SQL Server идет последовательно слева направо, вы можете вообразить, что он должен повторно прочитать строку, когда он достигнет страницы 9; однако этого не происходит при наличии указателей пересылки. SQL Server идентифицирует бит в байте состояния A перенаправленной строки и игнорирует ее повторное чтение на странице 9, избегая тем самым дублирующих чтений.
Указатели пересылки приводят к множественным чтениям во время единственного поиска RID (RID lookup), что ухудшает производительность. Понятно, что указатели пересылки реально влияют на производительность, когда SQL Server выполняет тяжелые поиски RID, и существует много указателей пересылки. Указатели пересылки возникают, главным образом, в кучах, когда обновляются столбцы переменной длины, чтобы вместить значения, длиннее чем те, которые могли бы поместиться на прежнем месте. Это приводит к обновлению не по месту и перемещению строки в другое местоположение.
Исправление указателей пересылки
Это может заставить вас думать, что кучи обладают лучшей производительностью, чем таблицы с кластеризованным индексом. Поскольку, в отличие от поиска ключа в кластеризованном индексе, при котором SQL Server должен выполнить перемещение к корневой странице индекса, а затем к промежуточным страницам, чтобы достичь листовых страниц для чтения данных, поиски RID непосредственно переходят к фактическому физическому местоположению строки в базовой таблице кучи, что лучше с точки зрения производительности. Это до некоторой степени справедливо. Однако корневая и промежуточные страницы индекса, по большей части, находятся в памяти (буферном пуле). Таким образом, навигация по нелистовым страницам индекса требует минимального времени.
Влияние на производительность логических чтений по нелистовым страницам кластеризованного индекса во время поиска ключа минимально по сравнению с физическим вводом-выводом, выполняемым при поиске RID в кучах. Можно сказать, что кучи обычно выигрывают в производительности при вставке большого количества данных, но в целом выгоды наличия кластеризованного индекса намного перевешивают достоинства куч.
Если строка, перенаправленная в результате увеличения длины столбца, сжимается до соответствия оригинальному местоположению, строка может быть возвращена назад, и SQL server удалит указатель пересылки. То же самое происходит при сжатии базы данных. При операции сжатия базы данных перенаправленные строки перемещаются обратно на свои исходные места, если это возможно, и SQL Server удаляет пустые страницы, чтобы освободить место. Однако идеальным методом, чтобы избавиться от указателей пересылки, является создание кластеризованного индекса на таблице, который определяет порядок сортировки, в котором SQL Server сохраняет строки в индексе.
Мы можем удалить указатели пересылки перестройкой таблицы кучи с помощью оператора alter table…rebuild, но при перестройке кучи перестраиваются некластеризованные индексы на таблице кучи.
Демонстрация
Посмотрим на указатели пересылки в действии.
Шаг 1: Давайте создадим новую базу данных с именем DML_DB и таблицу в ней. Вставим также пару строк по 3000 байт в каждой. Мы намереваемся оставить около 2000 байтов свободного пространства на странице.
--Создать новую базу данных с именем DML_DB
IF NOT EXISTS (
SELECT *
FROM sys.databases
WHERE name = 'DML_DB'
)
BEGIN
CREATE DATABASE DML_DB
END
GO
USE DML_DB
GO
--Создать таблицу с именем Forwarding_Pointer
IF NOT EXISTS (
SELECT *
FROM sysobjects
WHERE name = 'Forwarding_Pointer'
AND xtype = 'U'
)
BEGIN
CREATE TABLE dbo.Forwarding_Pointer (
ID INT NOT NULL
,NAME VARCHAR(8000) NULL
)
END
--Вставим 2 строки ~3000 байтов в каждой, чтобы осталось ~2000 байтов свободного места на странице
INSERT INTO Forwarding_Pointer
VALUES (
1
,REPLICATE('a', 3000)
);
INSERT INTO Forwarding_Pointer
VALUES (
2
,REPLICATE('b', 3000)
);
GOШаг 2: Используя динамическую административную функцию (DMF) sys.dm_db_index_physical_stats, мы можем увидеть, что есть только одна страница без перенаправленной записи. SQL Server разместил обе строки на одной странице.
-- Проверим поличество страниц в таблице
SELECT page_count
,avg_record_size_in_bytes
,avg_page_space_used_in_percent
,forwarded_record_count
FROM sys.dm_db_index_physical_stats(db_id('DML_DB'), object_id(N'dbo.Forwarding_Pointer'), 0, NULL, 'DETAILED');
GO
Шаг 3: Давайте выполним три оператора обновления строки с ID = 1 поочередно, обращая внимание на то, какое из трех обновлений приведет к появлению указателя пересылки. Комментарии у каждого оператора поясняют происходящее.
--Обновляем одну из двух записей.
--Указателя пересылки нет, т.к. размер строки не изменяется
--Следовательно, это обновление по месту.
UPDATE dbo.Forwarding_Pointer
SET Name = replicate('c', 3000)
WHERE ID = 1;
--Хотя размер строки увеличивается, она все еще может разместиться на той же странице,
--следовательно, по-прежнему указателя пересылки нет.
UPDATE dbo.Forwarding_Pointer
SET Name = replicate('a', 5000)
WHERE ID = 1;
--Это обновление увеличивает размер строки настолько, что она не может поместиться на странице;
--следовательно, выделяется новая страница, что вызывает появление указателя пересылки,
--т.к. это обновление не по месту.
UPDATE dbo.Forwarding_Pointer
SET Name = replicate('a', 6000)
WHERE ID = 1;Выполняя ту же динамическую административную функцию после третьего обновления, мы можем увидеть, что увеличение значения строки в результате обновления привело к её перемещению на новую страницу и созданию указателя пересылки в старом местоположении строки.
Шаг 4: Используя динамическую административную функцию sys.dm_db_database_page_allocations, проверим выделенные страницы и получим идентификаторы этих страниц и файлов.
--Получаем детали размещения страниц,
--а также идентификаторы страниц и файлов.
SELECT database_id
,db_name(database_id)
,allocated_page_file_id
,allocated_page_page_id
,page_type_desc
,is_allocated
FROM sys.dm_db_database_page_allocations(db_id('DML_DB'), object_id('Forwarding_Pointer'), NULL, NULL, 'DETAILED'); Выделенный SQL Server восьмистраничный экстент состоит из двух страниц данных с идентификаторами страниц 360 и 361 и идентификатором файла 1.
Шаг 5: Будем использовать недокументированную DBCC PAGE для проверки двух страниц данных. DBCC PAGE имеет следующие параметры: имя базы данных, идентификатор файла, идентификатор страницы, опции печати (0 - 3, 1 печатает заголовок страницы и дамп массива слотов каждой строки. Используйте флаг трассировки 3604 для отображения вывода в SSMS.
DBCC TRACEON (3604);
GO
DBCC PAGE(DML_DB, 1, 360, 1) -- проверка страницы 360
GOНиже я покажу частичный вывод. Слот 0 показывает тип записи как FORWARDING_STUB, это означает, что в этом слоте была строка с ID = 1, Name = aaaa… 6000 раз.
И поскольку мы обновили строку на большее значение, чем может принять страница, она переместилась на страницу 361, а исходная строка на странице была заменена указателем пересылки. Следующая строка находится в слоте 1 с типом записи PRIMARY_RECORD, что показывает, что это обычная запись со значением bbbb...3000 раз. Значение столбца Name выделено справа.
В SQL Server 2019 появилась новая динамическая административная функция sys.dm_db_page_info, которая может чем-то заменить DBCC PAGE.
Новая DMF в SQL 2019, которая возвращает результат,
--подобный DBCC PAGE
--sys.dm_db_page_info (базаданныхId, файлId, страницаId, режим)
SELECT database_id, file_id, page_id, gam_status_desc
FROM sys.dm_db_page_info(7, 1, 360, 'detailed')Шаг 6: Давайте исследуем страницу 361 и проверим, имеется ли на ней перенаправленная строка.
DBCC PAGE(DML_DB, 1, 361, 1)
GOОна здесь! На странице 361 находится только одна запись, и её идентификатор = 1. Обратите внимание на тип записи - FORWARDED_RECORD, что подтверждает, что эта запись является перенаправленной.
Шаг 7: Давайте удалим единственную строку со страницы 361, чтобы она стала пустой, и проверим её.
--Удаляем единственную строку на странице
DELETE
FROM Forwarding_Pointer
WHERE id = 1
--Хотя на странице нет строк, она по-прежнему показана как выделенная,
--и пространство недоступно для других объектов
DBCC PAGE(DML_DB, 1, 361, 1)
GOХотя страница пустая, поток уборки мусора не освободил её, поскольку это таблица кучи, и она остается выделенной. Также обратите внимание на то, что поскольку мы использовали опцию печати 1 в команде dbcc page, удаленная запись не показывается, но она по-прежнему физически присутствует на странице. Использование опции печати 2 показывает удаленную запись и байты, которые она занимает.
Шаг 8: Давайте перестроим таблицу и выясним, какие новые страницы выделяет SQL из-за перестройки.
--Перестроим кучу, чтобы исправить указатель пересылки
ALTER TABLE Forwarding_Pointer rebuild
--Выделяются все новые страницы. Страница с удаленной строкой освобождается
SELECT database_id
,db_name(database_id)
,allocated_page_file_id
,allocated_page_page_id
,page_type_desc
,is_allocated
FROM sys.dm_db_database_page_allocations(db_id('DML_DB'),
object_id('Forwarding_Pointer'), NULL, NULL, 'DETAILED');Перестройка таблицы приводит к тому, что единственная строка (с id=2) перемещается на новую страницу 376. Таблица сейчас содержит только одну строку. Как вы помните, мы ранее удалили строку с id=1.
Давайте проверим старые страницы, которые ранее содержали две строки, т.е. страницы 361 и 360.
--проверим, что стало с 2 старыми страницами после перестройки таблицы
--обе показывают отсутствие выделения, что означает,
--что любые вставки могут их использовать.
--Заметим однако, что страница 360, которая ранее содержала данные, все еще имеет старые строки,
которые никакие запросы не могут увидеть, но они все же присутствуют на странице физически
DBCC PAGE(DML_DB, 1, 361, 1)
GO
DBCC PAGE(DML_DB, 1, 360, 1)
GOПосле перестройки кучи, страница 361, которая была бы в противном случае пуста, теперь показывает отсутствие выделения и доступна для новых вставок в эту таблицу.
Страница 360, первоначально содержащая запись с id=2 (запись, которую SQL Server переместил на страницу 376 при перестройке), показывает отсутствие выделения и доступна для будущих вставок. Однако SQL физически не удалил записи с этой страницы. То же самое справедливо для страницы 361 (используйте опцию печати 2 в dbcc page).
Мы удалили строки-призраки, выполнив вручную sp_clean_db_free_space.
--очищаем строки-призраки по всей базе данных.
--Это вычистит наши строки-призраки на странице 360.
EXEC sp_clean_db_free_space 'dml_db'
--посмотрим, ушли ли строки-призраки
DBCC PAGE(DML_DB, 1, 360, 1)
GOЗаключение
Как правило большого пальца, всегда имейте кластеризованный индекс на таблицах, чтобы избежать указателей пересылки, если это не постановочная среда и имеет значение скорость вставки; в этом случае приемлемо применение куч. Указатели пересылки потенциально добавляют лишние физические чтения, когда SQL Server должен перейти с одной страницы с forwarding_stubs на другую страницу с forwarded_records в одной операции чтения, влияя на производительность. Указатели пересылки могут быть удалены при помощи перестройки таблицы кучи, но это приводит к перестройке некластеризованных индексов, которые имеют ссылки на кучу посредством физических идентификаторов строк. Наконец, SQL Server не освобождает пустые страницы в куче в процессе очистки призраков, и, чтобы решить эту проблему, нужно иметь либо кластеризованный индекс, либо перестроить таблицу.
Теперь, когда мы понимаем DML на кучах, в следующей статье мы посмотрим, что происходит при вставке, обновлении и удалении с индексами b-tree, и что вызывает расщепление страниц и, как результат, фрагментацию индекса.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой