
План выполнения: статистика
Пересказ статьи Bert Wagner. Execution Plans: Statistics
Во второй части серии я хочу обсудить, какие данные использует оптимизатор запросов для проведения расчетов на основе стоимости при генерации планов выполнения. Понимание метаданных, которые SQL Server использует для генерации планов запроса, поможет нам в дальнейшем исправлять непроизводительные запросы.
Ссылки на статьи этой серии:
Статистика - это первичные метаданные, используемые оптимизатором для оценки стоимости запрошенных данных конкретным планом выполнения.
Причина использования статистики SQL Server - избежать необходимости вычисления информации о данных во время генерации плана запроса. Например, вы не хотите, чтобы оптимизатор сканировал миллиард строк в таблице, чтобы узнать информацию о ней, и только затем сканировал её повторно при фактическом выполнении запроса.
Вместо этого предпочтительно иметь сводную статистику, которая рассчитывается заранее. Это позволяет оптимизатору запросов быстро генерировать и сравнивать многочисленные альтернативные планы, прежде чем выбрать тот, который будет фактически исполнен.
Статистика поддерживается автоматически, если установлены свойства базы данных Auto Create Statistics и Auto Update Statistics (т.е. вы оставляете их включенными):
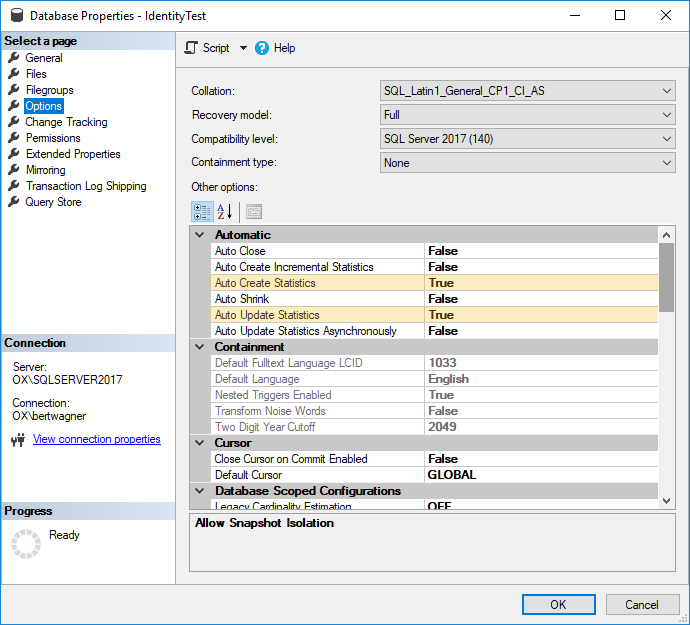
Теперь при всяком создании индекса или достаточном изменении данных в нем (пороговое значение смотрите в документации SQL Server) статистическая информация будет обновляться и поддерживаться в актуальном состоянии.
Чтобы увидеть статистику для индекса или столбца, вы можете выполнить команду DBCC SHOW_STATISTICS:
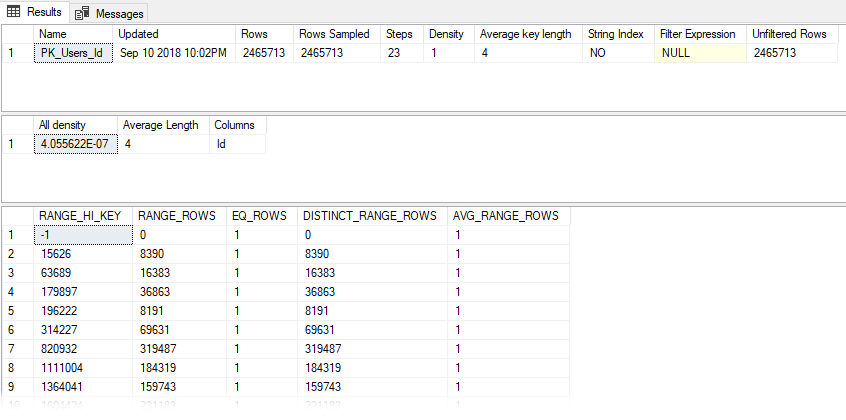
Данные, возвращаемые командой DBCC SHOW_STATISTICS, используются SQL Server для интерпретации данных в вашем индексе.
Я не буду глубоко вдаваться в статистику, но есть несколько ключевых вещей, которые вы должны знать об этом выводе статистики:
- Rows: число строк в таблице.
- Rows Sampled: сколько строк было использовано для вычисления этой статистики. Это может быть подмножество или все строки таблицы.
- All Density: мера количества различных значений, имеющихся в ваших данных.
- Histogram: показывает частоты для до 200 диапазонов значений в вашем индексе.
Вся вместе эта информация помогает нарисовать картину данных для оптимизатора запросов SQL Server, чтобы использовать её для принятия решения о способе получения ваших данных.
Если картина точна, оптимизатор запросов принимает решения, которые позволяют вашим запросам выполняться относительно эффективно. Если она имеет корректные оценки о числе строк, которые нужно обработать, и об уникальности значений в этих строках, то SQL Server с большой вероятностью выделит подходящий объем памяти, выберет эффективный алгоритм соединения и примет другие производительные решения, которые позволят вашему запросу выполняться эффективно.
Если статистика неточно представляет данные, оптимизатор запросов по-прежнему будет пытаться найти наилучшее решение по той информации, которой он обладает, но зачастую это приводит к неоптимальному выбору.
Мы оставим исследование статистики для другой статьи, а пока позаботьтесь о том, чтобы ваша статистика была точна, т.к. в противном случае весьма вероятно, что SQL Server не сможет сгенерировать эффективный план выполнения.
Иметь статистику о ваших данных на высоком уровне есть только первая часть уравнения. Для SQL Server требуется использовать эту статистику наряду с некоторыми предположениями о том, насколько дорогим будет получение этих данных.
Предположения, которые SQL Server делает относительно данных содержатся в оценщике кардинального числа (Cardinality Estimator). Оценщик кардинального числа представляет собой модель, которая делает предположения о таких вещах, как корреляция данных, распределение и т.п.
В настоящее время имеется две модели оценки кардинального числа в SQL Server: унаследованный оценщик, существовавший с SQL Server 7.0 и до SQL Server 2012, и новый оценщик, введенный в SQL Server 2014. Каждый из оценщиков кардинального числа исходит из различных предположений о ваших данных и, следовательно, может давать различающиеся результаты. Общие рекомендации предлагают использовать новый оценщик кардинального числа для новых работ, однако иногда выгодней использовать унаследованный оценщик, если его предположения лучше согласуются с вашими данными.
Опять таки, я не хочу углубляться в различия между оценщиками кардинальных чисел, но полезно знать, что, если вы получаете плохие оценки от нового оценщика, вы можете легко возвратиться к унаследованному оценщику, используя следующий хинт в конце вашего запроса:
SQL Server предварительно рассчитывает статистику данных в индексах и столбцах, предоставляя оптимизатору запросов информацию о данных, которые он должен получить. Когда эта статистика точно отражает фактическое состояние данных, SQL Server обычно генерирует хороший план выполнения. Если эти данные устарели или отсутствуют, SQL Server делает неинформированное предположение о том, как получать данные, что потенциально может вызвать серьезные проблемы с производительностью.
- Введение в планы выполнения SQL Server.
- Эта статья.
- 5 вещей, которые вам нужно знать при чтении планов выполнения в SQL Server.
- Операторы плана выполнения в SQL Server.
- Как я использую планы выполнения SQL Server для решения проблем.
Статистика
Статистика - это первичные метаданные, используемые оптимизатором для оценки стоимости запрошенных данных конкретным планом выполнения.
Причина использования статистики SQL Server - избежать необходимости вычисления информации о данных во время генерации плана запроса. Например, вы не хотите, чтобы оптимизатор сканировал миллиард строк в таблице, чтобы узнать информацию о ней, и только затем сканировал её повторно при фактическом выполнении запроса.
Вместо этого предпочтительно иметь сводную статистику, которая рассчитывается заранее. Это позволяет оптимизатору запросов быстро генерировать и сравнивать многочисленные альтернативные планы, прежде чем выбрать тот, который будет фактически исполнен.
Создание и наблюдение статистики
Статистика поддерживается автоматически, если установлены свойства базы данных Auto Create Statistics и Auto Update Statistics (т.е. вы оставляете их включенными):
Теперь при всяком создании индекса или достаточном изменении данных в нем (пороговое значение смотрите в документации SQL Server) статистическая информация будет обновляться и поддерживаться в актуальном состоянии.
Чтобы увидеть статистику для индекса или столбца, вы можете выполнить команду DBCC SHOW_STATISTICS:
DBCC SHOW_STATISTICS('dbo.Users','PK_Users_Id')Данные статистики
Данные, возвращаемые командой DBCC SHOW_STATISTICS, используются SQL Server для интерпретации данных в вашем индексе.
Я не буду глубоко вдаваться в статистику, но есть несколько ключевых вещей, которые вы должны знать об этом выводе статистики:
- Rows: число строк в таблице.
- Rows Sampled: сколько строк было использовано для вычисления этой статистики. Это может быть подмножество или все строки таблицы.
- All Density: мера количества различных значений, имеющихся в ваших данных.
- Histogram: показывает частоты для до 200 диапазонов значений в вашем индексе.
Вся вместе эта информация помогает нарисовать картину данных для оптимизатора запросов SQL Server, чтобы использовать её для принятия решения о способе получения ваших данных.
Если картина точна, оптимизатор запросов принимает решения, которые позволяют вашим запросам выполняться относительно эффективно. Если она имеет корректные оценки о числе строк, которые нужно обработать, и об уникальности значений в этих строках, то SQL Server с большой вероятностью выделит подходящий объем памяти, выберет эффективный алгоритм соединения и примет другие производительные решения, которые позволят вашему запросу выполняться эффективно.
Если статистика неточно представляет данные, оптимизатор запросов по-прежнему будет пытаться найти наилучшее решение по той информации, которой он обладает, но зачастую это приводит к неоптимальному выбору.
Мы оставим исследование статистики для другой статьи, а пока позаботьтесь о том, чтобы ваша статистика была точна, т.к. в противном случае весьма вероятно, что SQL Server не сможет сгенерировать эффективный план выполнения.
Оценщики кардинального числа
Иметь статистику о ваших данных на высоком уровне есть только первая часть уравнения. Для SQL Server требуется использовать эту статистику наряду с некоторыми предположениями о том, насколько дорогим будет получение этих данных.
Предположения, которые SQL Server делает относительно данных содержатся в оценщике кардинального числа (Cardinality Estimator). Оценщик кардинального числа представляет собой модель, которая делает предположения о таких вещах, как корреляция данных, распределение и т.п.
В настоящее время имеется две модели оценки кардинального числа в SQL Server: унаследованный оценщик, существовавший с SQL Server 7.0 и до SQL Server 2012, и новый оценщик, введенный в SQL Server 2014. Каждый из оценщиков кардинального числа исходит из различных предположений о ваших данных и, следовательно, может давать различающиеся результаты. Общие рекомендации предлагают использовать новый оценщик кардинального числа для новых работ, однако иногда выгодней использовать унаследованный оценщик, если его предположения лучше согласуются с вашими данными.
Опять таки, я не хочу углубляться в различия между оценщиками кардинальных чисел, но полезно знать, что, если вы получаете плохие оценки от нового оценщика, вы можете легко возвратиться к унаследованному оценщику, используя следующий хинт в конце вашего запроса:
OPTION (USE HINT ('FORCE_LEGACY_CARDINALITY_ESTIMATION')); Заключение
SQL Server предварительно рассчитывает статистику данных в индексах и столбцах, предоставляя оптимизатору запросов информацию о данных, которые он должен получить. Когда эта статистика точно отражает фактическое состояние данных, SQL Server обычно генерирует хороший план выполнения. Если эти данные устарели или отсутствуют, SQL Server делает неинформированное предположение о том, как получать данные, что потенциально может вызвать серьезные проблемы с производительностью.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой