
Операторы (итераторы) плана выполнения в SQL Server
Пересказ статьи Bert Wagner. SQL Server Execution Plan Operators
При исследовании плана выполнения запроса некоторые операторы возникают снова и снова в качестве виновников многих проблем с производительностью.
Ссылки на статьи этой серии:
Здесь я хочу рассмотреть те операторы плана выполнения, которые я обычно ищу в первую очередь, когда решаю проблемы производительности. Наличие этих операторов в ваших планах не обязательно плохо, но стоит их дважды проверить на предмет причины узкого места производительности запроса.
Одни из первых операторов плана выполнения, с которыми знакомятся многие люди, это поиск и сканирование некластеризованного индекса. Общая мудрость гласит, что поиск (seek) - это хорошо для производительности, поскольку он представляет собой прямой доступ SQL Server к требуемым строкам данных, в то время как сканирование (scan) - это плохо, поскольку он предполагает последовательное чтение индекса для извлечения большого числа строк, приводя к более медленной обработке.
В целом, это довольно хорошее обобщение. Однако часто важно проверить, что делают ваши операторы поиска и сканирования, поскольку это может быть не всегда то, что вы ожидали.
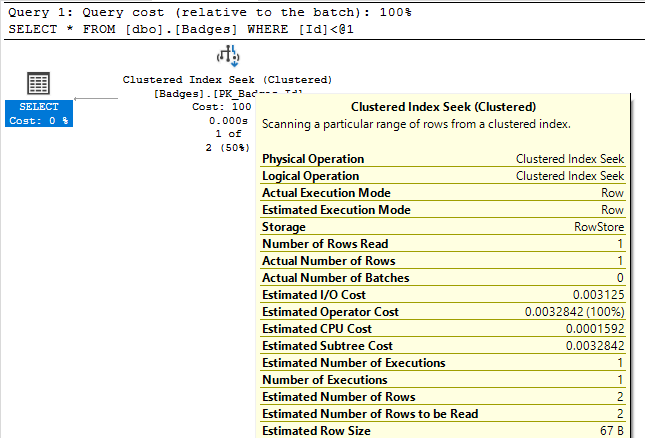
Например, взгляните на свойство Actual Number of Rows (фактическое число строк) для этих двух операторов index seek:
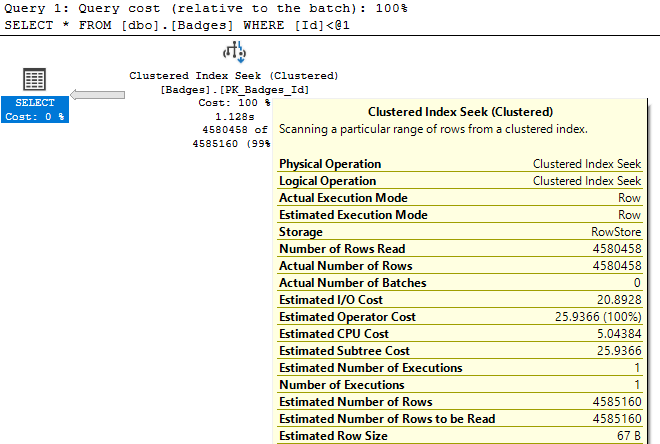
В первом результирующем наборе мы видим, что index seek возвращает 1 строку на основании предложения WHERE нашего запроса. Это та производительность, которая бы нам понравилась! Однако во втором запросе SQL Server "ищет" 4 миллиона строк. Когда index seek возвращает 4 миллиона строк, это необязательно плохо, если именно это и требовалось от запроса. Этот пример показывает, что не все поисковые операции сильно таргетированы и быстро возвращают результат, как вы это могли бы ожидать, видя в плане оператор index seek.
Как и то, что index scan не обязательно означает плохую производительность:
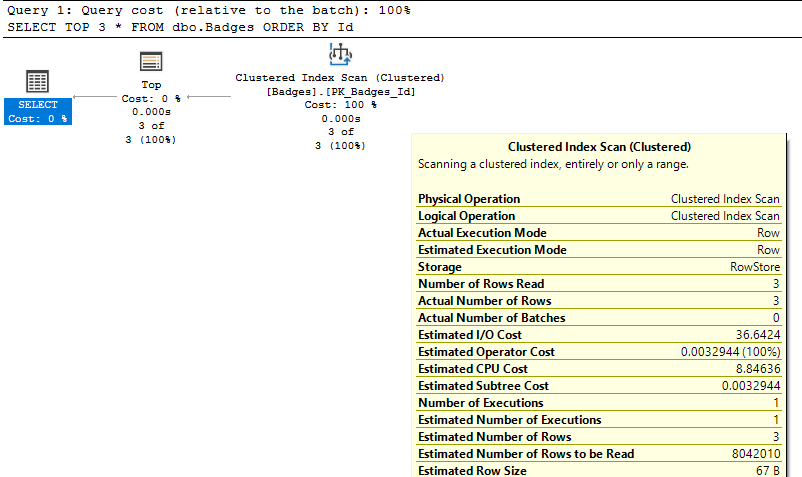
В этом случае сканирование индекса возвращает только 3 записи. Вы не смогли бы получить лучшую производительность, чем ту, которую уже имеете, даже если вы попытаетесь перестроить запрос/индексы, чтобы добиться операции Index Seek.
Еще одна пара операторов, на которые я обращаю внимание в плане запроса при анализе производительности, это операторы RID Lookup (поиск идентификатора записи) и Key Lookup (поиск ключа).
RID Lookup легко пофиксить - если вы видите этот оператор, это означает, что у вас отсутствует кластеризованный индекс на таблице. По крайней мере, вы должны добавить кластеризованный индекс. И вы тут же получите некоторый рост производительности для большинства, если не для всех, ваших запросов.
Поиск ключей имеет больше нюансов. SQL Server использует Key Lookup, когда он знает, что с большей эффективностью может использовать некластеризованный индекс, а затем перейти к кластерзованному индексу для поиска оставшихся значения строк, которые отсутствуют в некластеризованном индексе.
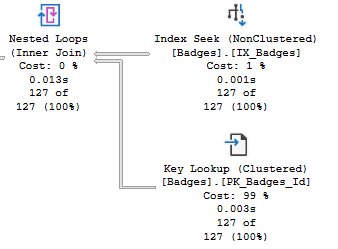
Поиск ключей - это не обязательно всегда плохо. Обращение SQL Server к кластеризованному индексу для извлечения недостающих значений довольно эффективен по сравнению с необходимостью создавать и поддерживать совершенно новые индексы.
Однако, если все, что нужно SQL Server от операции Key Lookup, это единственный столбец данных, возможно, проще всего добавить этот столбец в ваш существующий некластеризованный индекс. Да, размер индекса увеличится на один столбец, но если SQL Server сможет избежать необходимости обращаться к двум индексам для извлечения всех необходимых данных, это, вероятно, в целом окажется более эффективным.

Действия операторов Sort просты - они изменяют порядок строк в проходящем потоке данных.
Сортировка является одной из наиболее дорогих операций, которые могут быть в плане выполнения, поэтому лучше избегать их, насколько это возможно.
Одним из самых простых способов избежать оператора сортировки - иметь данные, хранящиеся в предварительно упорядоченном виде. Это может быть выполнено созданием индекса с ключевыми столбцами, перечисленными в том же самом порядке, который использует оператор сортировки.
Если SQL Server должен выполнить сортировку одних и тех же данных в одном и том же порядке несколько раз в плане выполнения, еще одной возможностью является разбиение запроса на несколько этапов при использовании временных индексированных таблиц для сохранения данных между этапами. Замена единственного оператора сортировки на индексную временную таблицу не даст выигрыша в производительности. Но если вы можете повторно использовать временную таблицу неоднократно в плане выполнения вашего запроса, то вы получите чистую экономию.

Спулы бывают разных типов, но большинство из них можно сформулировать как операторы, которые сохраняют промежуточную таблицу результатов в tempdb.
SQL Server часто использует спул для обработки сложных запросов, преобразуя данные в рабочую таблицу в базе tempdb для использования её данных в последующих операциях. Побочным эффектом здесь является необходимость записи данных на диск в tempdb.
Когда я вижу операцию спула, то, первую очередь, пытаюсь найти способ перезаписи запроса, чтобы избежать спула. Если это не получается, использую метод "разделяй и властвуй" для временных таблиц, который может также заменить спул, обеспечивая больший контроль по сравнению с тем, как SQL Server записывает и индексирует данные в tempdb.

Интересно выделить соединения слиянием (Merge join), поскольку я редко вижу их в реальных запросах. Они вызывают радость, а не беспокойство, так как они, как правило, являются наиболее эффективными из операторов логического соединения.
Соединения вложенными циклами (Nested loops join), как раз наоборот, я вижу часто. Обычно я не уделяю им много внимания, если что-то не покажется мне подозрительным в их окружении. Nested loops join выполняют довольно эффективное соединение относительно небольших наборов данных.
Я всегда тщательно исследую Hash match join. Эти операторы соединения обычно выбираются оптимизатором запросов по одной из двух причин:
1. Соединяемые наборы данных настолько велики, что они могут быть обработаны только с помощью hash match join.
2. Наборы данных не упорядочены по столбцам соединения, и SQL Server думает, что вычисление хэшей и цикл по ним будет быстрей, чем сортировка данных.
Для первого сценария вы мало что можете сделать, если не найти способа соединять меньшие объемы данных.
Второй сценарий полезно рассмотреть немного более внимательно. Если есть некоторый способ получить данные в упорядоченном виде до соединения, типа предопределенного порядка сортировки в индексе, то возможно, что SQL Server выберет вместо этого более быстрый алгоритм соединения.
Операторы Parallelism обычно считаются хорошими вещами: SQL Server дробит ваши данные на множество частей для асинхронной обработки на множестве процессоров, сокращая общее время работы, требуемое для выполнения вашего запроса.

Однако параллелизм может стать плохим, если ВСЕ (или большинство) запросов используют его. Параллелизм не магия, процессоры по-прежнему выполняют тот же самый объем работы (и отнимают ресурсы у других запросов, которые могут быть запущены), плюс дополнительная нагрузка, которую вы должны учесть, на SQL Server по дроблению и последующему объединению всех данных из множества потоков процессоров.
Я обычно подозреваю параллелизм, если оказывается, что большинство исследуемых запросов на сервере производят параллельные планы. Если это так, я могу рассмотреть вопрос о пересмотре порогового значения стоимости для настройки параллелизма, если оно установлено слишком низким.
- Введение в планы выполнения SQL Server.
- Планы выполнения: статистика.
- 5 вещей, которые вам нужно знать при чтении планов выполнения в SQL Server.
- Эта статья.
- Как я использую планы выполнения SQL Server для решения проблем.
Здесь я хочу рассмотреть те операторы плана выполнения, которые я обычно ищу в первую очередь, когда решаю проблемы производительности. Наличие этих операторов в ваших планах не обязательно плохо, но стоит их дважды проверить на предмет причины узкого места производительности запроса.
Index Seek и Index Scan
Одни из первых операторов плана выполнения, с которыми знакомятся многие люди, это поиск и сканирование некластеризованного индекса. Общая мудрость гласит, что поиск (seek) - это хорошо для производительности, поскольку он представляет собой прямой доступ SQL Server к требуемым строкам данных, в то время как сканирование (scan) - это плохо, поскольку он предполагает последовательное чтение индекса для извлечения большого числа строк, приводя к более медленной обработке.
В целом, это довольно хорошее обобщение. Однако часто важно проверить, что делают ваши операторы поиска и сканирования, поскольку это может быть не всегда то, что вы ожидали.
Например, взгляните на свойство Actual Number of Rows (фактическое число строк) для этих двух операторов index seek:
В первом результирующем наборе мы видим, что index seek возвращает 1 строку на основании предложения WHERE нашего запроса. Это та производительность, которая бы нам понравилась! Однако во втором запросе SQL Server "ищет" 4 миллиона строк. Когда index seek возвращает 4 миллиона строк, это необязательно плохо, если именно это и требовалось от запроса. Этот пример показывает, что не все поисковые операции сильно таргетированы и быстро возвращают результат, как вы это могли бы ожидать, видя в плане оператор index seek.
Как и то, что index scan не обязательно означает плохую производительность:
В этом случае сканирование индекса возвращает только 3 записи. Вы не смогли бы получить лучшую производительность, чем ту, которую уже имеете, даже если вы попытаетесь перестроить запрос/индексы, чтобы добиться операции Index Seek.
RID Lookup и Key Lookup
Еще одна пара операторов, на которые я обращаю внимание в плане запроса при анализе производительности, это операторы RID Lookup (поиск идентификатора записи) и Key Lookup (поиск ключа).
RID Lookup легко пофиксить - если вы видите этот оператор, это означает, что у вас отсутствует кластеризованный индекс на таблице. По крайней мере, вы должны добавить кластеризованный индекс. И вы тут же получите некоторый рост производительности для большинства, если не для всех, ваших запросов.
Поиск ключей имеет больше нюансов. SQL Server использует Key Lookup, когда он знает, что с большей эффективностью может использовать некластеризованный индекс, а затем перейти к кластерзованному индексу для поиска оставшихся значения строк, которые отсутствуют в некластеризованном индексе.
Поиск ключей - это не обязательно всегда плохо. Обращение SQL Server к кластеризованному индексу для извлечения недостающих значений довольно эффективен по сравнению с необходимостью создавать и поддерживать совершенно новые индексы.
Однако, если все, что нужно SQL Server от операции Key Lookup, это единственный столбец данных, возможно, проще всего добавить этот столбец в ваш существующий некластеризованный индекс. Да, размер индекса увеличится на один столбец, но если SQL Server сможет избежать необходимости обращаться к двум индексам для извлечения всех необходимых данных, это, вероятно, в целом окажется более эффективным.
Sort (сортировка)
Действия операторов Sort просты - они изменяют порядок строк в проходящем потоке данных.
Сортировка является одной из наиболее дорогих операций, которые могут быть в плане выполнения, поэтому лучше избегать их, насколько это возможно.
Одним из самых простых способов избежать оператора сортировки - иметь данные, хранящиеся в предварительно упорядоченном виде. Это может быть выполнено созданием индекса с ключевыми столбцами, перечисленными в том же самом порядке, который использует оператор сортировки.
Если SQL Server должен выполнить сортировку одних и тех же данных в одном и том же порядке несколько раз в плане выполнения, еще одной возможностью является разбиение запроса на несколько этапов при использовании временных индексированных таблиц для сохранения данных между этапами. Замена единственного оператора сортировки на индексную временную таблицу не даст выигрыша в производительности. Но если вы можете повторно использовать временную таблицу неоднократно в плане выполнения вашего запроса, то вы получите чистую экономию.
Spools
Спулы бывают разных типов, но большинство из них можно сформулировать как операторы, которые сохраняют промежуточную таблицу результатов в tempdb.
SQL Server часто использует спул для обработки сложных запросов, преобразуя данные в рабочую таблицу в базе tempdb для использования её данных в последующих операциях. Побочным эффектом здесь является необходимость записи данных на диск в tempdb.
Когда я вижу операцию спула, то, первую очередь, пытаюсь найти способ перезаписи запроса, чтобы избежать спула. Если это не получается, использую метод "разделяй и властвуй" для временных таблиц, который может также заменить спул, обеспечивая больший контроль по сравнению с тем, как SQL Server записывает и индексирует данные в tempdb.
Соединения
Интересно выделить соединения слиянием (Merge join), поскольку я редко вижу их в реальных запросах. Они вызывают радость, а не беспокойство, так как они, как правило, являются наиболее эффективными из операторов логического соединения.
Соединения вложенными циклами (Nested loops join), как раз наоборот, я вижу часто. Обычно я не уделяю им много внимания, если что-то не покажется мне подозрительным в их окружении. Nested loops join выполняют довольно эффективное соединение относительно небольших наборов данных.
Я всегда тщательно исследую Hash match join. Эти операторы соединения обычно выбираются оптимизатором запросов по одной из двух причин:
1. Соединяемые наборы данных настолько велики, что они могут быть обработаны только с помощью hash match join.
2. Наборы данных не упорядочены по столбцам соединения, и SQL Server думает, что вычисление хэшей и цикл по ним будет быстрей, чем сортировка данных.
Для первого сценария вы мало что можете сделать, если не найти способа соединять меньшие объемы данных.
Второй сценарий полезно рассмотреть немного более внимательно. Если есть некоторый способ получить данные в упорядоченном виде до соединения, типа предопределенного порядка сортировки в индексе, то возможно, что SQL Server выберет вместо этого более быстрый алгоритм соединения.
Параллелизм (Parallelism)
Операторы Parallelism обычно считаются хорошими вещами: SQL Server дробит ваши данные на множество частей для асинхронной обработки на множестве процессоров, сокращая общее время работы, требуемое для выполнения вашего запроса.
Однако параллелизм может стать плохим, если ВСЕ (или большинство) запросов используют его. Параллелизм не магия, процессоры по-прежнему выполняют тот же самый объем работы (и отнимают ресурсы у других запросов, которые могут быть запущены), плюс дополнительная нагрузка, которую вы должны учесть, на SQL Server по дроблению и последующему объединению всех данных из множества потоков процессоров.
Я обычно подозреваю параллелизм, если оказывается, что большинство исследуемых запросов на сервере производят параллельные планы. Если это так, я могу рассмотреть вопрос о пересмотре порогового значения стоимости для настройки параллелизма, если оно установлено слишком низким.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой