
Как я использую планы выполнения в SQL Server для решения проблем
Пересказ статьи Bert Wagner. How I Troubleshoot SQL Server Execution Plans
Сегодня я подвожу итоги моей серии статей по планам выполнения SQL Server, рассматривая конкретные шаги, которые я предпринимаю при устранении проблем с медленно выполняющимися запросами.
Ссылки на предыдущие статьи:
В первой части серии мы обсуждали различные типы доступных планов выполнения и как их просматривать. Я предпочитаю начинать с плохо выполняющегося запроса и запросить для него план выполнения.
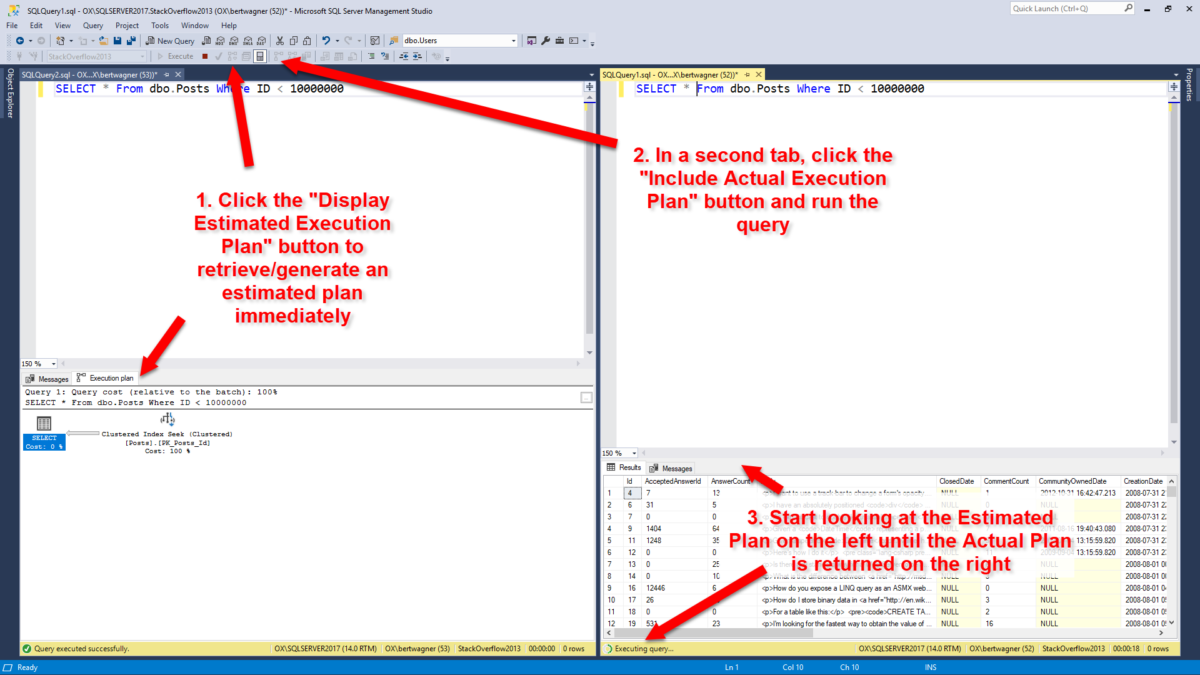
Надписи на рисунке:
При вставленном и отформатированном запросе в окне моего редактора SSMS мне нравится сначала получить предварительный план выполнения, а затем вставить запрос во второе окно редактора и выполнить его при включенной опции “Include Actual Execution Plan”. Дополнительно я разбиваю окно SSMS вертикально, поэтому могу начинать смотреть оценочный план выполнения, пока запрос выполняется и возвращает действительный план выполнения: в такой комбинации я (почти) сразу получаю оценочный план выполнения моего запроса и могу начать искать проблемы. Как только запрос справа заканчивает выполнения, и я получаю фактический план со всей его прекрасной статистикой времени выполнения, то обычно переключаюсь на него.
Некоторые используют обратный подход, сначала просматривая кэшированный план запроса, прежде чем выполнить запрос для получения плана. Это тоже замечательно, но по моему опыту запуск запроса вначале дает мне некоторые другие данные для работы: по-прежнему ли запрос выполняется медленно, или это временная проблема? Может быть человек, для которого я рассматриваю запрос, допустил некоторые ошибки и увидел плохую производительность из-за других несвязанных с запросом причин? Получение мной плана выполнения поможет ответить на некоторые из этих вопросов.
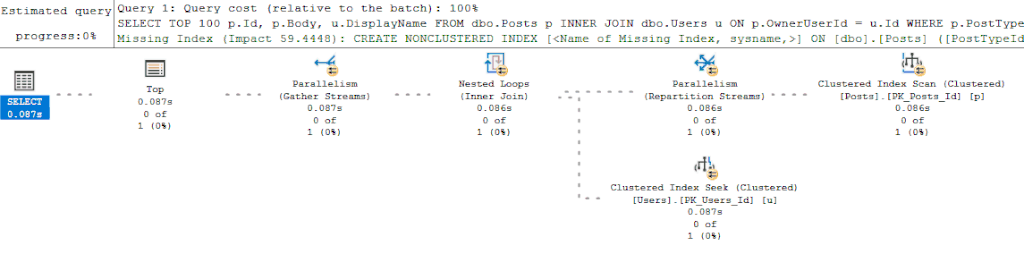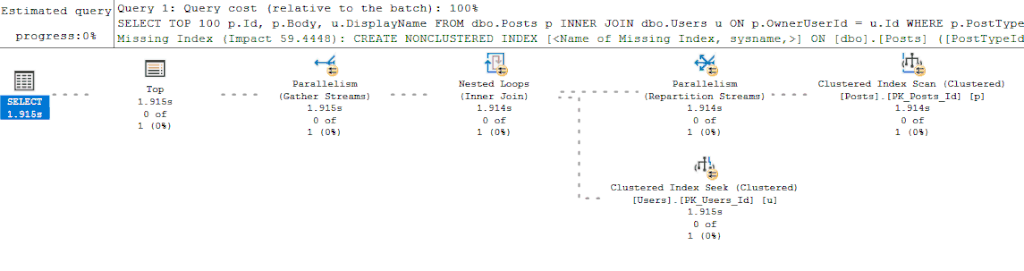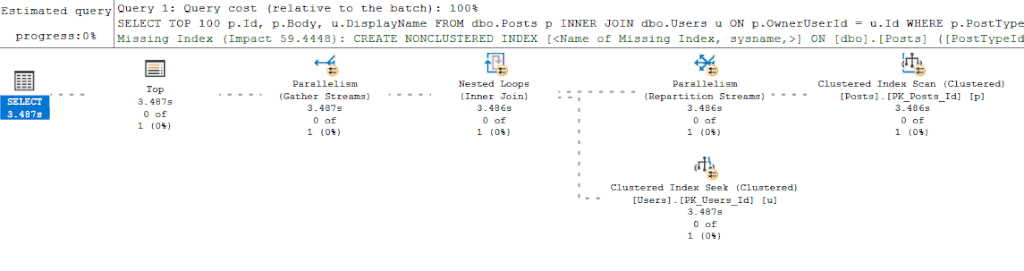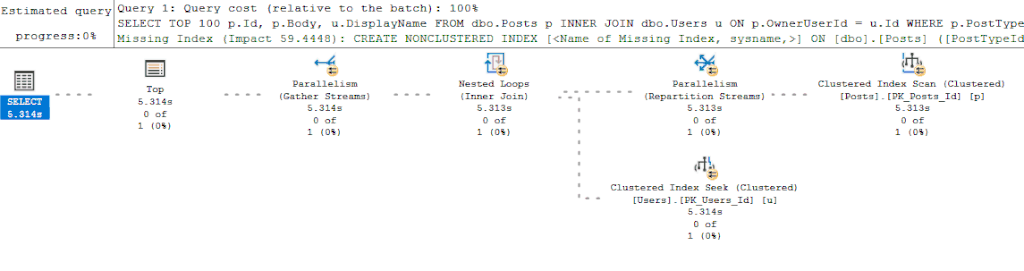
Но в моем подходе тоже есть недостатки. Например, выполнение запроса в окне SSMS может сгенерировать новый план вместо повторно используемого кэшированного плана (если тексты запроса отличаются чем-то вроде пробела). Это одна из тех вещей, которые хороши, пока вы помните о том, что может произойти. Отсюда даже можно извлечь пользу, т.к. если вы получаете различные планы между запущенным вами запросом и тем, который находится в кэше, то вы знаете, что у вас может быть проблема с прослушиванием параметров (parameter sniffing). Наконец, если получение действительного плана выполнения непрактично (выполнение запроса занимает слишком много времени), тогда я включу живую статистику запроса (Live Query Statistics): я не начинаю с этого варианта, поскольку большинство запросов, с которыми я имею дело, вернут результат к тому времени, когда я закончу просмотр оценочного плана выполнения (и к этому моменту дополнительная нагрузка (Live Query Statistics будет нежелательна). Однако если у меня нет времени дождаться получения фактического плана выполнения, переключение на Live Query Statistics и наблюдение за долгоиграющими запросами в реальном времени обычно помогает диагностировать проблемы с производительностью.
Как только я вижу один из вышеприведенных планов выполнения, первым делом я проверяю, откуда извлекаются мои данные.
Если я вижу, что данные напрямую поступают из некластеризованных индексов, то доволен, что данные извлекаются эффективно, поскольку возвращается только ограниченное число столбцов, и надеюсь, что они вернутся в предпочтительном порядке (оттого, что я создаю свои индексы довольно узкими).
Если все, что я вижу, это Index scan (сканирование индекса), тогда все прекрасно, но следует убедиться, что:
Наконец, мне нравится выполнять двойной щелчок на любом index seek, который я вижу как часть поиска ключей (key lookups). Опять таки, поиск ключей не обязательно плохо, но если я могу включить всего лишь один лишний столбец в некластеризованный индекс и избавиться от закладок, я могу рассмотреть этот вариант, если эта часть плана кажется узким местом.
Далее я начинаю смотреть на дорогостоящие операторы и сравнивать оценочное число строк с фактическим числом строк (для запросов, которые не быстро возвращают результат, Live Query Statistics помогает легко их идентифицировать). Я могу также обратить внимание на относительный размер стрелок, если покажется, что оператор возвращает или читает значительно больше строк, чем я ожидаю.
Если фактическое число строк значительно отличается от оценки (обычно, если фактическое число больше оценочного более чем в 100 раз), я начинаю думать, почему SQL Server так неправильно оценил число строк - из общих соображений или глядя на используемую статистику.
Здесь я также также учитываю, является ли запрос параметризованным (либо явно в запросе, либо автоматически SQL Server). Если так, я обычно перехожу к проверке на сниффинг параметры.
Затем я ищу в плане любые другие операторы, обычно вызывающие проблемы: сортировки, спулы, хэш-соединения и т.д.
Я уже говорил об этом в предыдущей статье, но стоит повторить, что я всегда присматриваю за этими операторами.
Наконец, я быстро просматриваю план в поисках желтых восклицательных знаков на любых операторах в плане. Эти символы отмечают действия, о которых SQL Server считает, что должен нас предупредить. Более детально я говорил об этом в части 3, однако полезно снова упомянуть, поскольку поиск этих предупреждений может оказать огромную помощь в идентификации проблемных частей вашего плана выполнения.
Нет одного правильного способа устранения проблем или настройки производительности запроса. Я использую описанный метод, поскольку он имеет смысл в моей деятельности, когда большинство запросов, которые я настраиваю, являются моими собственными, и я достаточно хорошо знаю также о других типах запросов, выполняющихся в моей базе данных. Я надеюсь, что знакомство с этим процессом поможет вам разработать свой собственный процесс для настройки запросов в вашем окружении.
- Введение в планы выполнения SQL Server.
- Планы выполнения: статистика.
- 5 вещей, которые вам нужно знать при чтении планов выполнения в SQL Server.
- Операторы плана выполнения в SQL Server
- Эта статья.
Получение плана выполнения
В первой части серии мы обсуждали различные типы доступных планов выполнения и как их просматривать. Я предпочитаю начинать с плохо выполняющегося запроса и запросить для него план выполнения.
Надписи на рисунке:
- Щелкните кнопку "Display Estimated Execution Plan" для немедленного получения/генерации предварительного плана плана.
- На второй вкладке щелкните кнопку "Include Actual Execution Plan" и выполните запрос.
- Начинайте смотреть предварительный план слева, пока не появится действительный план справа.
При вставленном и отформатированном запросе в окне моего редактора SSMS мне нравится сначала получить предварительный план выполнения, а затем вставить запрос во второе окно редактора и выполнить его при включенной опции “Include Actual Execution Plan”. Дополнительно я разбиваю окно SSMS вертикально, поэтому могу начинать смотреть оценочный план выполнения, пока запрос выполняется и возвращает действительный план выполнения: в такой комбинации я (почти) сразу получаю оценочный план выполнения моего запроса и могу начать искать проблемы. Как только запрос справа заканчивает выполнения, и я получаю фактический план со всей его прекрасной статистикой времени выполнения, то обычно переключаюсь на него.
Некоторые используют обратный подход, сначала просматривая кэшированный план запроса, прежде чем выполнить запрос для получения плана. Это тоже замечательно, но по моему опыту запуск запроса вначале дает мне некоторые другие данные для работы: по-прежнему ли запрос выполняется медленно, или это временная проблема? Может быть человек, для которого я рассматриваю запрос, допустил некоторые ошибки и увидел плохую производительность из-за других несвязанных с запросом причин? Получение мной плана выполнения поможет ответить на некоторые из этих вопросов.
Но в моем подходе тоже есть недостатки. Например, выполнение запроса в окне SSMS может сгенерировать новый план вместо повторно используемого кэшированного плана (если тексты запроса отличаются чем-то вроде пробела). Это одна из тех вещей, которые хороши, пока вы помните о том, что может произойти. Отсюда даже можно извлечь пользу, т.к. если вы получаете различные планы между запущенным вами запросом и тем, который находится в кэше, то вы знаете, что у вас может быть проблема с прослушиванием параметров (parameter sniffing). Наконец, если получение действительного плана выполнения непрактично (выполнение запроса занимает слишком много времени), тогда я включу живую статистику запроса (Live Query Statistics): я не начинаю с этого варианта, поскольку большинство запросов, с которыми я имею дело, вернут результат к тому времени, когда я закончу просмотр оценочного плана выполнения (и к этому моменту дополнительная нагрузка (Live Query Statistics будет нежелательна). Однако если у меня нет времени дождаться получения фактического плана выполнения, переключение на Live Query Statistics и наблюдение за долгоиграющими запросами в реальном времени обычно помогает диагностировать проблемы с производительностью.
Неожиданный поиск вместо сканирования
Как только я вижу один из вышеприведенных планов выполнения, первым делом я проверяю, откуда извлекаются мои данные.
Если я вижу, что данные напрямую поступают из некластеризованных индексов, то доволен, что данные извлекаются эффективно, поскольку возвращается только ограниченное число столбцов, и надеюсь, что они вернутся в предпочтительном порядке (оттого, что я создаю свои индексы довольно узкими).
Если все, что я вижу, это Index scan (сканирование индекса), тогда все прекрасно, но следует убедиться, что:
- Я не вижу table scan (сканирование таблицы) - на худой конец, это может быть сканирование кластерного индекса.
- Я не использую без необходимости SELECT * в своем запросе - зачем считывать все эти лишние данные в память или мешать использованию более узкого индекса, если в этом нет необходимости.
- SQL Server не сканирует весь индекс, чтобы вернуть только ограниченное подмножество строк.
Наконец, мне нравится выполнять двойной щелчок на любом index seek, который я вижу как часть поиска ключей (key lookups). Опять таки, поиск ключей не обязательно плохо, но если я могу включить всего лишь один лишний столбец в некластеризованный индекс и избавиться от закладок, я могу рассмотреть этот вариант, если эта часть плана кажется узким местом.
Неточные оценки числа строк
Далее я начинаю смотреть на дорогостоящие операторы и сравнивать оценочное число строк с фактическим числом строк (для запросов, которые не быстро возвращают результат, Live Query Statistics помогает легко их идентифицировать). Я могу также обратить внимание на относительный размер стрелок, если покажется, что оператор возвращает или читает значительно больше строк, чем я ожидаю.
Если фактическое число строк значительно отличается от оценки (обычно, если фактическое число больше оценочного более чем в 100 раз), я начинаю думать, почему SQL Server так неправильно оценил число строк - из общих соображений или глядя на используемую статистику.
Здесь я также также учитываю, является ли запрос параметризованным (либо явно в запросе, либо автоматически SQL Server). Если так, я обычно перехожу к проверке на сниффинг параметры.
Подозрительные операторы
Затем я ищу в плане любые другие операторы, обычно вызывающие проблемы: сортировки, спулы, хэш-соединения и т.д.
Я уже говорил об этом в предыдущей статье, но стоит повторить, что я всегда присматриваю за этими операторами.
Предупреждения
Наконец, я быстро просматриваю план в поисках желтых восклицательных знаков на любых операторах в плане. Эти символы отмечают действия, о которых SQL Server считает, что должен нас предупредить. Более детально я говорил об этом в части 3, однако полезно снова упомянуть, поскольку поиск этих предупреждений может оказать огромную помощь в идентификации проблемных частей вашего плана выполнения.
Заключение
Нет одного правильного способа устранения проблем или настройки производительности запроса. Я использую описанный метод, поскольку он имеет смысл в моей деятельности, когда большинство запросов, которые я настраиваю, являются моими собственными, и я достаточно хорошо знаю также о других типах запросов, выполняющихся в моей базе данных. Я надеюсь, что знакомство с этим процессом поможет вам разработать свой собственный процесс для настройки запросов в вашем окружении.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой