
Запись, которая никогда не существовала (как зафиксированная строка)
Пересказ статьи Alessandro Mortola. The Record That Never Existed (as a committed row)
Введение
Согласно официальной документации уровень изоляции READ COMMITTED "определяет, что операторы не могут читать данные, которые были модифицированы, но не зафиксированы другими транзакциями". Поэтому можно подумать, что запись, возвращаемая при этом уровне изоляции, существовала в зафиксированном состоянии в момент чтения.
В этой статье я собираюсь доказать, что возможны пограничные ситуации, когда прочитанные данные вообще никогда не существовали, по крайней мере, в зафиксированном состоянии.
Замечание. На протяжении этой статьи я буду ссылаться на таблицу с построчным хранением для установки уровня изоляции в READ COMMITTED и установки READ_COMMITTED_SNAPSHOT в состояние OFF, которое является значением по умолчанию для SQL Server. Это не соответствует состоянию Azure SQL Database, где значением по умолчанию является ON.
Чтобы создать таблицу, необходимую для примера, я проделаю следующие шаги:
Вот код, выполняющий эти шаги:
Листинг 1
Теперь рассмотрим следующий запрос:
Листинг 2
Если внимательно рассмотреть запрос, то вы заметите, что он покрывается двумя только что определенными некластеризованными индексами. Напомню, что SalesOrderDetailID - это столбец, который определяет кластеризованный индекс и, следовательно, "включен" в оба некластеризованных индекса.
Кроме того, в предложении WHERE имеется набор из двух условий фильтрации. Один - на ProductID, который является первым полем индекса Idx_ProdId_TrackNumb. Второй фильтр на ModifiedDate, который является первым полем индекса Idx_ModDate_LineTot.
Неудивительно, что план выполнения использует только два некластеризованных индекса, не используя кластеризованного. Анализируя этот план, мы можем увидеть, что оптимизатор выбирает оператор Hash Match для соединения ("Join") результатов двух операторов "index seek".
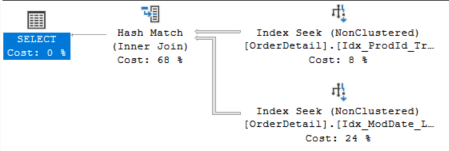
Рис.1
Hash Match имеет два входа:
В нашем случае фаза построения (build) состоит из поиска по индексу Idx_ProdId_TrackNumb (Index Seek) с фильтрацией по ProductID, и она возвращает значения SalesOrderDetailID, CarrierTrackingNumber и ProductID. Это можно увидеть ниже на рисунке 2 в разделе “Output List”. Если вы сгенерируете план, наведите мышку над графическим компонентом Idx_ProdId_TrackNumb, чтобы увидеть всю всплывающую подсказку.

Рис.2
Фаза проверки (probe) состоит из поиска по индексу другого некластеризованного индекса с фильтрацией по ModifiedDate и с полями SalesOrderDetailID, LineTotal, ModifiedDate на выходе (рис.3).

Рис.3
Ниже представлен результат выполнения запроса.
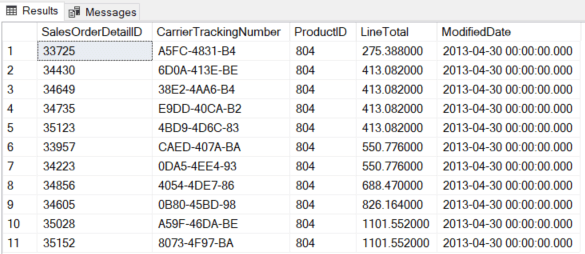
Рис.4
Результат, показанный на рис.4 очевидно корректен, но давайте посмотрим что случится в пограничной ситуации. Предположим, что два конкурирующих подключения выполняют следующие операции точно в таком порядке:
Подключение №1 открывает транзакцию и обновляет запись, идентифицированную по SalesOrderDetailID = 33725, изменяя значение столбца LineTotal на 999:
Листинг 3
Заметьте, что обновляемое поле LineTotal приведет к обновлению некластеризованного индекса Idx_ModDate_LineTot , но НЕ другого. В этот момент транзакция только что установила эксклюзивные блокировки на кластеризованный индекс и на индекс Idx_ModDate_LineTot на уровне ключа. Также обратите внимание, что индекс Idx_ModDate_LineTot, на который теперь наложена эксклюзивная блокировка, вовлечен в фазу проверки, которая выполняется второй на плане, показанном на Рис.1.
В последнем параграфе статьи я собираюсь дать более подробную информацию о блокировках, которые производит выполнение оператора UPDATE.
Подключение №2 выполняет запрос, только что проанализированный выше (Листинг 2). Запись, модифицированная подключением №1 входит в набор, который читает подключение №2. Как мы видели ранее, план выполнения стартует с фазы построения, осуществляя доступ к индексу Idx_ProdId_TrackNumb, который в данный момент свободен от блокировок, и поэтому может читать исходные значения ProductID и CarrierTrackingNumber, которое для записи, только что модифицированной подключением №1, равно A5FC-4831-B4.
После, согласно плану, оно пытается прочитать из индекса Idx_ModDate_LineTot (фаза проверки), но обнаруживает эксклюзивную блокировку, которая препятствует продолжению; поэтому процесс должен перейти в состояние ожидания.
Подключение №1 выполняет второе обновление, всегда на той же записи, теперь значение столбца CarrierTrackingNumber меняется на "YYZ". Оператор выполняется успешно, хотя значение только было прочитано подключением №2, поскольку при READ COMMITTED читатель не удерживает никакие блокировки после чтения.
Сразу после обновления, подключение №1 фиксирует транзакцию, снимая любую эксклюзивную блокировку.
Листинг 4
Мы оставили подключение №2 в момент времени 2 из-за эксклюзивной блокировки. В момент времени 3 эта блокировка была снята; фаза проверки может теперь продолжиться и прочитать новое значение LineTotal. Это значение было обновлено в момент времени 1 на подключении №1.
Подводя итоги, подключение №2 в момент времени 2 читает исходное значение CarrierTrackingNumber, в то время как в момент времени 4 оно читает новое значение LineTotal.
Следующая таблица дает схематичный обзор последовательности событий:
Вот результат, возвращаемый запросом, показанным в листинге 2 и выполненным на подключении №2:
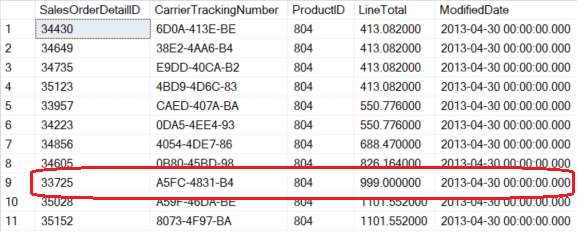
Рис.5
На первый взгляд результаты кажутся верными, но имеется небольшая проблема: красным выделена запись, которая НИКОГДА не существовала в зафиксированном состоянии! По факту в CarrierTrackingNumber выводится исходное значение, в то время как LineTotal имеет новое. Показывается только первое обновление на подключении №1, в целом это состояние записи в середине транзакции первого подключения.
Вы можете взглянуть на реальную ситуацию, снова выполняя запрос без каких-либо блокировок. Теперь вы получите корректный результат, когда оба поля содержат новые значения.
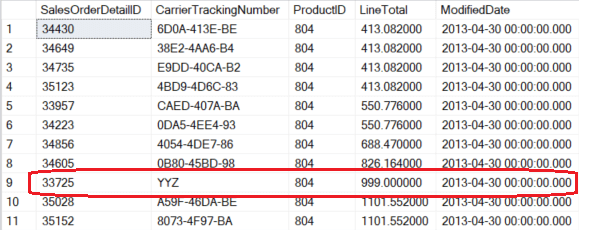
Рис.6
Пример, показанный в предыдущем параграфе, несомненно является пограничной ситуацией. Для того чтобы избежать этой ситуации, вы можете просто использовать другой уровень изоляции. Для подключения №2 вы могли бы выбрать решение на основе версионности строк, или использование SNAPSHOT ISOLATION LEVEL, или включение установки READ COMMITTED SNAPSHOT.
В противном случае вы могли бы выбрать решение на основе блокировок, повышая уровень изоляции, используя, по крайней мере, уровень REPEATABLE READ, но в этом случае подключение может быть убито из-за возникающего тупика.
Для последующей информации давайте рассмотрим блокировки, которые накладывали операторы в листинге 3. Для удобства я установлю их здесь снова.
Если вы уже выполняли эти операторы ранее, перестройте таблицу, используйте скрипт в из листинга 1 для воспроизводства исходного сценария. Затем выполните этот код:
Листинг 3
Выполняя следующий запрос, мы сможем посмотреть на применяемые блокировки:
Листинг 5
Этот результат я получил на своем ноутбуке:

Рис.7
Как и ожидалось, мы имеем одну Х-блокировку на уровне ключа и одну IX-блокировку на уровне страниц для кластеризованного индекса.
Что может вызвать интерес, так это две Х-блокировки на уровне ключа и три IX-блокировки на уровне страниц для некластеризованного индекса Idx_ModDate_LineTot. Почему мы имеем три блокировки на страничном уровне, когда мы просто обновляли одну единственную запись?
Мы можем найти ответ, выполнив запрос к динамическому административному представлению sys.dm_db_page_info, доступного, начиная с SQL Server 2019. Мы можем три раза выполнить запрос к этому представлению, передавая в качестве параметров номера соответствующих страниц (посмотрите на значения resource_description на рис.7):
Листинг 6
Вот результат:
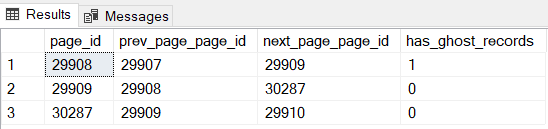
Рис.8
Теперь давайте проанализируем подробно каждую из этих трех страниц, помня о том, что обновление поля LineTotal выполняемое подключением №1 подразумевало изменение позиции записи в индексе, поскольку движок поддерживает упорядоченность записей.
Страница 29908 имеет записи-призраки, только одну в наших случаях. Согласно официальной документации, "запись-призрак - это запись, которая была помечена для удаления, но еще не удалена"; это страница, на которой исходная запись индекса находилась до обновления. Напротив, страница с номером 30287 - это страница, где будет находиться запись, если транзакция зафиксируется. Вы можете проверить это с помощью недокументированной команды DBCC PAGE.
В моем случае я выполнил следующую команду, в которой первый параметр - это database_id, второй - номер файла данных, а третий - номер страницы. Вы получите результат в сетку SSMS, установив последний параметр в 3.
Листинг 7
Ниже приводится подмножество результата. Мы видим записи индекса Idx_ModDate_LineTot, находящиеся на странице 30287, а красным отмечена запись, которая только одна изменилась. Показано значение кластерного ключа (SalesOrderDetailID = 33725) с двумя значениями полей, которые определяют индекс: ModifiedDate с его исходным и немодифицированным значением и LineTotal - с новым значением. Как можно видеть, порядок поддерживается в соответствии с определением индекса.
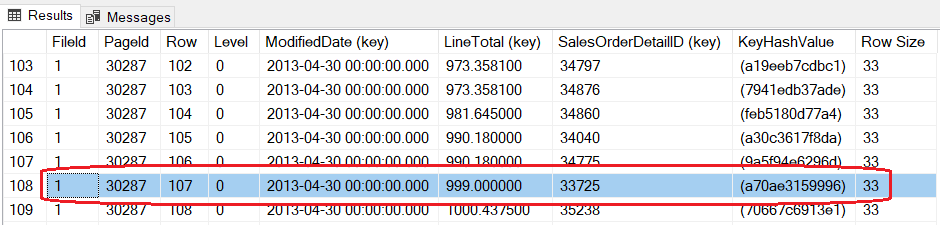
Рис.9
Вернемся к рисунку 8, третья анализируемая страница имеет номер 29909.
Это страница, куда должна быть перемещена запись после обновления, если на ней достаточно места. На момент обновления это не так, поэтому страница разбивается и создается новая страница с номером 30287, которая готова принять запись. Интересно отметить, что для страницы 29909 страница 30287 является "следующей" из-за разбиения, а для страницы 30287 "следующей" является страница 29910. Эта последняя страница была "следующей" для страницы 29909 непосредственно до разбиения страницы.
В этой статье я очертил пограничную ситуацию в T-SQL, пр этом используется несколько факторов: поведение уровня изоляции READ COMMITTED, механизм блокировок, частная форма запроса и порядок выполнения операторов. Играя с двумя конкурирующими транзакциями, от одной из которых мы получили запись, которая возникает в середине выполнения другой транзакции, и еще не зафиксирована: мы получили только часть запланированных обновлений. Шансы получить такое поведение весьма невелики, но в случае, если это произойдет, могут иметь место неприятные последствия, если данные будут напечатаны в отчете или использованы для дальнейших расчетов.
Установка
Чтобы создать таблицу, необходимую для примера, я проделаю следующие шаги:
- Создам копию таблицы Sales.SalesOrderDetail хорошо известной базы данных AdventureWorks, используя синтаксис SELECT…INTO, и назову её OrderDetails.
- Создам первичный ключ, как в оригинальной таблице, на SalesOrderDetailID.
- Создам два некластеризованных индекса. Первый с именем Idx_ProdId_TrackNumb определен на ProductID и CarrierTrackingNumber, а второй - Idx_ModDate_LineTot - на ModifiedDate и LineTotal.
Вот код, выполняющий эти шаги:
use master;
go
alter database AdventureWorks set read_committed_snapshot off with no_wait;
go
use AdventureWorks;
go
---------------------------------
--Установка данных
---------------------------------
drop table if exists OrderDetail;
go
--Создание таблицы
select *
into OrderDetail
from Sales.SalesOrderDetail;
go
alter table OrderDetail add constraint PK_OrderDetail primary key (SalesOrderDetailID);
go
create nonclustered index Idx_ProdId_TrackNumb on OrderDetail (ProductID, CarrierTrackingNumber);
go
create nonclustered index Idx_ModDate_LineTot on OrderDetail (ModifiedDate, LineTotal);
goЛистинг 1
Запрос и план
Теперь рассмотрим следующий запрос:
set transaction isolation level read committed;
go
select SalesOrderDetailID, CarrierTrackingNumber, ProductID, LineTotal, ModifiedDate
from OrderDetail
where ProductID = 804 and ModifiedDate = '20130430';Листинг 2
Если внимательно рассмотреть запрос, то вы заметите, что он покрывается двумя только что определенными некластеризованными индексами. Напомню, что SalesOrderDetailID - это столбец, который определяет кластеризованный индекс и, следовательно, "включен" в оба некластеризованных индекса.
Кроме того, в предложении WHERE имеется набор из двух условий фильтрации. Один - на ProductID, который является первым полем индекса Idx_ProdId_TrackNumb. Второй фильтр на ModifiedDate, который является первым полем индекса Idx_ModDate_LineTot.
Неудивительно, что план выполнения использует только два некластеризованных индекса, не используя кластеризованного. Анализируя этот план, мы можем увидеть, что оптимизатор выбирает оператор Hash Match для соединения ("Join") результатов двух операторов "index seek".
Рис.1
Hash Match имеет два входа:
- так называемый вход “build”, относящийся к наименьшему из двух входов. Он первым должен выполняться и графически представлен на том же уровне, что и оператор Hash Match.
- Вход “probe”, который представлен непосредственно ниже предыдущего и который должен выполняться вторым.
В нашем случае фаза построения (build) состоит из поиска по индексу Idx_ProdId_TrackNumb (Index Seek) с фильтрацией по ProductID, и она возвращает значения SalesOrderDetailID, CarrierTrackingNumber и ProductID. Это можно увидеть ниже на рисунке 2 в разделе “Output List”. Если вы сгенерируете план, наведите мышку над графическим компонентом Idx_ProdId_TrackNumb, чтобы увидеть всю всплывающую подсказку.
Рис.2
Фаза проверки (probe) состоит из поиска по индексу другого некластеризованного индекса с фильтрацией по ModifiedDate и с полями SalesOrderDetailID, LineTotal, ModifiedDate на выходе (рис.3).
Рис.3
Ниже представлен результат выполнения запроса.
Рис.4
Что могло случиться
Результат, показанный на рис.4 очевидно корректен, но давайте посмотрим что случится в пограничной ситуации. Предположим, что два конкурирующих подключения выполняют следующие операции точно в таком порядке:
ВРЕМЯ 1 - подключение №1
Подключение №1 открывает транзакцию и обновляет запись, идентифицированную по SalesOrderDetailID = 33725, изменяя значение столбца LineTotal на 999:
BEGIN TRAN;
UPDATE OrderDetail
SET LineTotal = 999
WHERE SalesOrderDetailID = 33725;Листинг 3
Заметьте, что обновляемое поле LineTotal приведет к обновлению некластеризованного индекса Idx_ModDate_LineTot , но НЕ другого. В этот момент транзакция только что установила эксклюзивные блокировки на кластеризованный индекс и на индекс Idx_ModDate_LineTot на уровне ключа. Также обратите внимание, что индекс Idx_ModDate_LineTot, на который теперь наложена эксклюзивная блокировка, вовлечен в фазу проверки, которая выполняется второй на плане, показанном на Рис.1.
В последнем параграфе статьи я собираюсь дать более подробную информацию о блокировках, которые производит выполнение оператора UPDATE.
ВРЕМЯ 2 - подключение №2
Подключение №2 выполняет запрос, только что проанализированный выше (Листинг 2). Запись, модифицированная подключением №1 входит в набор, который читает подключение №2. Как мы видели ранее, план выполнения стартует с фазы построения, осуществляя доступ к индексу Idx_ProdId_TrackNumb, который в данный момент свободен от блокировок, и поэтому может читать исходные значения ProductID и CarrierTrackingNumber, которое для записи, только что модифицированной подключением №1, равно A5FC-4831-B4.
После, согласно плану, оно пытается прочитать из индекса Idx_ModDate_LineTot (фаза проверки), но обнаруживает эксклюзивную блокировку, которая препятствует продолжению; поэтому процесс должен перейти в состояние ожидания.
ВРЕМЯ 3 - подключение №1
Подключение №1 выполняет второе обновление, всегда на той же записи, теперь значение столбца CarrierTrackingNumber меняется на "YYZ". Оператор выполняется успешно, хотя значение только было прочитано подключением №2, поскольку при READ COMMITTED читатель не удерживает никакие блокировки после чтения.
Сразу после обновления, подключение №1 фиксирует транзакцию, снимая любую эксклюзивную блокировку.
UPDATE OrderDetail
SET CarrierTrackingNumber = 'YYZ'
WHERE SalesOrderDetailID = 33725;
COMMIT;Листинг 4
ВРЕМЯ 4 - подключение №2
Мы оставили подключение №2 в момент времени 2 из-за эксклюзивной блокировки. В момент времени 3 эта блокировка была снята; фаза проверки может теперь продолжиться и прочитать новое значение LineTotal. Это значение было обновлено в момент времени 1 на подключении №1.
Резюме и результат
Подводя итоги, подключение №2 в момент времени 2 читает исходное значение CarrierTrackingNumber, в то время как в момент времени 4 оно читает новое значение LineTotal.
Следующая таблица дает схематичный обзор последовательности событий:
Вот результат, возвращаемый запросом, показанным в листинге 2 и выполненным на подключении №2:
Рис.5
На первый взгляд результаты кажутся верными, но имеется небольшая проблема: красным выделена запись, которая НИКОГДА не существовала в зафиксированном состоянии! По факту в CarrierTrackingNumber выводится исходное значение, в то время как LineTotal имеет новое. Показывается только первое обновление на подключении №1, в целом это состояние записи в середине транзакции первого подключения.
Вы можете взглянуть на реальную ситуацию, снова выполняя запрос без каких-либо блокировок. Теперь вы получите корректный результат, когда оба поля содержат новые значения.
Рис.6
Как этого избежать
Пример, показанный в предыдущем параграфе, несомненно является пограничной ситуацией. Для того чтобы избежать этой ситуации, вы можете просто использовать другой уровень изоляции. Для подключения №2 вы могли бы выбрать решение на основе версионности строк, или использование SNAPSHOT ISOLATION LEVEL, или включение установки READ COMMITTED SNAPSHOT.
В противном случае вы могли бы выбрать решение на основе блокировок, повышая уровень изоляции, используя, по крайней мере, уровень REPEATABLE READ, но в этом случае подключение может быть убито из-за возникающего тупика.
Более пристальный взгляд на блокировки
Для последующей информации давайте рассмотрим блокировки, которые накладывали операторы в листинге 3. Для удобства я установлю их здесь снова.
Если вы уже выполняли эти операторы ранее, перестройте таблицу, используйте скрипт в из листинга 1 для воспроизводства исходного сценария. Затем выполните этот код:
BEGIN TRAN;
UPDATE OrderDetail
SET LineTotal = 999
WHERE SalesOrderDetailID = 33725;Листинг 3
Выполняя следующий запрос, мы сможем посмотреть на применяемые блокировки:
SELECT tl.resource_type,
tl.resource_description,
tl.resource_associated_entity_id,
tl.request_mode,
tl.request_type,
tl.request_status,
p.index_id,
i.name,
i.type_desc
FROM sys.dm_tran_locks tl
INNER JOIN sys.partitions p
ON tl.resource_associated_entity_id = p.hobt_id
INNER JOIN sys.indexes i
ON i.object_id = p.object_id
AND i.index_id = p.index_id
WHERE OBJECT_NAME(p.object_id) = 'OrderDetail'
ORDER BY tl.resource_type,
i.type_desc;Листинг 5
Этот результат я получил на своем ноутбуке:
Рис.7
Как и ожидалось, мы имеем одну Х-блокировку на уровне ключа и одну IX-блокировку на уровне страниц для кластеризованного индекса.
Что может вызвать интерес, так это две Х-блокировки на уровне ключа и три IX-блокировки на уровне страниц для некластеризованного индекса Idx_ModDate_LineTot. Почему мы имеем три блокировки на страничном уровне, когда мы просто обновляли одну единственную запись?
Два полезных инструмента: sys.dm_db_page_info и DBCC PAGE
Мы можем найти ответ, выполнив запрос к динамическому административному представлению sys.dm_db_page_info, доступного, начиная с SQL Server 2019. Мы можем три раза выполнить запрос к этому представлению, передавая в качестве параметров номера соответствующих страниц (посмотрите на значения resource_description на рис.7):
select page_id, prev_page_page_id, next_page_page_id, has_ghost_records
from sys.dm_db_page_info(db_id(), 1, 29908, 'DETAILED')
union
select page_id, prev_page_page_id, next_page_page_id, has_ghost_records
from sys.dm_db_page_info(db_id(), 1, 29909, 'DETAILED')
union
select page_id, prev_page_page_id, next_page_page_id, has_ghost_records
from sys.dm_db_page_info(db_id(), 1, 30287, 'DETAILED');Листинг 6
Вот результат:
Рис.8
Теперь давайте проанализируем подробно каждую из этих трех страниц, помня о том, что обновление поля LineTotal выполняемое подключением №1 подразумевало изменение позиции записи в индексе, поскольку движок поддерживает упорядоченность записей.
Страницы с номерами 29908 и 30287
Страница 29908 имеет записи-призраки, только одну в наших случаях. Согласно официальной документации, "запись-призрак - это запись, которая была помечена для удаления, но еще не удалена"; это страница, на которой исходная запись индекса находилась до обновления. Напротив, страница с номером 30287 - это страница, где будет находиться запись, если транзакция зафиксируется. Вы можете проверить это с помощью недокументированной команды DBCC PAGE.
В моем случае я выполнил следующую команду, в которой первый параметр - это database_id, второй - номер файла данных, а третий - номер страницы. Вы получите результат в сетку SSMS, установив последний параметр в 3.
--dbcc page ( {'dbname' | dbid}, filenum, pagenum [, printopt={0|1|2|3} ])
dbcc page(5, 1, 30287, 3)Листинг 7
Ниже приводится подмножество результата. Мы видим записи индекса Idx_ModDate_LineTot, находящиеся на странице 30287, а красным отмечена запись, которая только одна изменилась. Показано значение кластерного ключа (SalesOrderDetailID = 33725) с двумя значениями полей, которые определяют индекс: ModifiedDate с его исходным и немодифицированным значением и LineTotal - с новым значением. Как можно видеть, порядок поддерживается в соответствии с определением индекса.
Рис.9
Страница с номером 29909
Вернемся к рисунку 8, третья анализируемая страница имеет номер 29909.
Это страница, куда должна быть перемещена запись после обновления, если на ней достаточно места. На момент обновления это не так, поэтому страница разбивается и создается новая страница с номером 30287, которая готова принять запись. Интересно отметить, что для страницы 29909 страница 30287 является "следующей" из-за разбиения, а для страницы 30287 "следующей" является страница 29910. Эта последняя страница была "следующей" для страницы 29909 непосредственно до разбиения страницы.
Заключение
В этой статье я очертил пограничную ситуацию в T-SQL, пр этом используется несколько факторов: поведение уровня изоляции READ COMMITTED, механизм блокировок, частная форма запроса и порядок выполнения операторов. Играя с двумя конкурирующими транзакциями, от одной из которых мы получили запись, которая возникает в середине выполнения другой транзакции, и еще не зафиксирована: мы получили только часть запланированных обновлений. Шансы получить такое поведение весьма невелики, но в случае, если это произойдет, могут иметь место неприятные последствия, если данные будут напечатаны в отчете или использованы для дальнейших расчетов.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой