
Мои любимые улучшения T-SQL в SQL Server 2022
Пересказ статьи Aaron Bertrand. My Favorite T-SQL Enhancements in SQL Server 2022
Каждый релиз SQL Server содержит новые возможности, которые возбуждают некоторые группы пользователей - иногда изменения вводятся, чтобы порадовать администраторов системы, иногда - финансистов, иногда - клиентов других платформ, а иногда - разработчиков. Теперь, когда стала доступной первая предварительная версия SQL Server 2022, я хочу поделиться некоторыми из моих любимых новых возможностей, которые порадуют каждого, кто пишет на T-SQL, оставив некоторые другие новинки для другой статьи.
Мне хочется поговорить сначала о развитии T-SQL, поскольку, в отличие от основных функций, они в значительной степени реализованы к тому времени, когда первые общедоступные бета-версии поступят на прилавки. Они также не подвержены дальнейшим изменениям или переименованиям со стороны других бизнес-подразделений Microsoft (например, отдела маркетинга).
Пока вот несколько наиболее полезных изменений, с которыми я мог познакомиться в SQL Server 2022:
В этой статье я объясню каждую из них и покажу несколько практических примеров их использования.
Как отмечалось ранее, эти функции напоминают MAX и MIN, но по столбцам, а не по строкам. Быстрая демонстрация:
В этом простом примере логика во многом подобна выражению CASE. Возьмем только первый случай:
При оценке двух выражений это действительно просто: первое выражение превосходит второе, или нет? (Однако, вспоминая о NULL, обе новые функции игнорируют NULL, как и MAX/MIN.)
Хотя, если добавить третье значение, это становится более сложным. В то время как новый синтаксис предложит такое решение:
То, как это выразилось через CASE в текущей и более старых версиях, выглядит муторно:
И, как вы можете себе представить, это будет выглядеть еще хуже при сравнении 4 или более значений в CASE. Я даже не буду пытаться печатать такую паутину.
Давайте рассмотрим реальную задачу, поскольку трудно симулировать сложность, когда мы говорим о вещах, которые можно легко решить в голове. Возьмем следующую таблицу, которая содержит по строке на каждый год и столбцы с месячными продажами (мы возьмем только три месяца для упрощения):
Если мы хотим вернуть наибольшую и наименьшую сумму продаж для каждого года, то могли бы написать утомительные выражения CASE (опять просто представьте, что если бы мы имели все 12 месяцев):
Результат
Имеется пара других способов решить эту задачу, которые, по крайней мере, лучше масштабируются без экспоненциального усложнения кода. Один из методов использует UNPIVOT:
А другой использует CROSS APPLY:
Эти методы легче обобшить на большее число столбцов, но они все же утомительны, и мне не нравится, что они оба используют операции транспонирования и группировки. Теперь мы можем выполнить такого рода задачи с большой легкостью:
Я писал об усилении этой функции в плане enable_ordinal, но я хотел бы сейчас упомянуть об этом снова, т.к. не мог тогда подтвердить сделанные изменения в SQL Server 2022. Теперь могу, и я хотел бы привести несколько случаев использования, когда исходная позиция важна.
Я встречал много запросов для возвращения второго или третьего элемента в списке, которые раньше громоздко выполнялись с помощью STRING_SPLIT, поскольку выходной порядок не гарантировался. Помимо этого вы могли видеть более громоздкие решения с помощью OPENJSON или трюков с PARSENAME. С новым параметром я могу просто написать:
Пусть вы хотите назначить новые списки продавцам на основе прошлой работы. У вас есть такая таблица:
И теперь у вас есть набор новых поступивших списков, ранжированных по предпочтениям:
В этом случае мы хотели бы назначить наиболее предпочтительный список (81) продавцу 6, второй список (76) продавцу 3, а третий (80) - продавцу 2. Имея осмысленный и надежный ordinal, результат достигается легко:
Результат:
Другим сценарием с утомительным приемом решения является реконструкция строки для удаления дубликатов. Допустим, что у нас есть такая строка:
Мы хотим удалить дубликаты из списка, но оставить исходный порядок, т.е. требуемый выход должен быть таким:
С этой новой функциональностью мы можем точно перестроить строку непосредственно, выбирая первый экземпляр любой строки в списке, а затем с помощью его общего исходного положения задать порядок, используя STRING_AGG:
Результат:
Это значительно более простой подход, чем те неуклюжие решения, которые я использовал в прошлом.
Тем не менее...
К сожалению, STRING_SPLIT все еще ограничен односимвольным разделителем. Хотя новый аргумент enable_ordinal упрощает некоторые наиболее часто используемые случаи, которые традиционно требовали утомительных обходных путей. Это также дает преимущество в производительности по сравнению с текущими методами, поскольку оптимизатор знает, что данные вернутся отсортированными. Это означает, что не всегда требуется явно добавлять оператор сортировки в план, если требуется упорядочить данные по исходным позициям. В то время как пример выше требовал сортировки, в следующем примере это не делается:
Вот план:
Эта функция сжимает дату/время к фиксированному интервалу, устраняя необходимость округлять значения datetime, вытаскивать компоненты даты, выполнять дикие преобразования в и из других типов данных типа float или делать сложные и интуитивно непонятные вычисления dateadd/datediff (иногда используя магические даты из прошлого).
Аргументами являются:
Результатом является тип даты/времени (на основе входа), но с интервалом, определяемым компонентой_даты и шириной. Например, если бы я хотел упростить вывод определенного столбца, чтобы он просто давал мне границы месяца, то раньше я мог бы сделать это так:
Или так для SQL Server 2012 и выше:
Теперь на SQL Server 2022 я могу сделать это так:
Все три вышеприведенных запроса дадут идентичные результаты:
Кроме того, это может дать лучшую производительность в ряде случаев. Поскольку функция сохраняет порядок, есть случаи, когда сортровки можно избежать. Отставив в сторону системные объекты, давайте создадим упрощенную таблицу и сравним планы, созданные группировкой:
Вот эти планы:
Важно то, что функция позволяет делать и более сложные вещи, например, разбивку данных на 5-минутные интервалы:
Результат:
Как насчет 10-минутных интервалов? Без проблем. Мы можем даже передать параметр или переменную, чтобы можно было подстраиваться на лету:
Результат:
Еще одна вещь, которую я могу сделать, — это значительно упростить расчет недельных границ. Вот совершенно неинтуитивный загадочный способ получить предыдущую субботу (независимо от пользовательских установок SET DATEFIRST или SET LANGUAGE):
Если вы знаете какую-либо субботу в прошлом, например 1 января 2000, то можем упростить это, передав эту дату в параметре источник:
Это даст тот же ответ (на момент написания - во вторник 24 мая 2022 - будет получена суббота 21 мая 2022). И, как и выше, если мы имеем набор данных, то можем использовать такую же технику, чтобы фильтровать или группировать на основе любого известного дня недели.
Результат:
Это значтельно более простой способ сегментировать данные на основе нестандартной рабочей недели. В качестве еще одного примера могу привести график дежурств нашей команды в Stack Overflow, который циклически повторяется по средам, и я уже использовал эту функцию, чтобы спрогнозировать наше будущее расписание.
Эта функция производит основанную на множестве последовательность числовых значений. Она заменяет громоздкие таблицы чисел, рекурсивные CTE и другие методы генерации последовательностей на лету, которые все мы использовали так или иначе.
У функции имеются следующие аргументы:
Пара простых примеров:
Результаты:
(Обратите внимание на отсутствие значения STOP или близкого к нему, если следующий шаг (STEP) обходит его.)
В предшествующих версиях для генерации подобной последовательсности чисел вы, вероятно, использовал бы таблицу чисел или такой рекурсивный CTE:
GENERATE_SERIES имеет очевидные преимущества в смысле простоты использования.
Эта функция имеет один недостаток - она является оператором, а не табличнозначной функцией, поэтому, если вы не укажите имя параметра явно, то получите неожиданный результат:
Вы увидите сбивающее с толку сообщение об ошибке:
Это подразумевает разнообразие проблем, включая то, что функция не существует, что требуется указать префикс dbo., что мы подключены не к тому серверу, что апгрейд завершился неудачно, или что это на самом деле скалярная функция.
Другой недостаток состот в том - по крайней мере, в текущем билде - что эта функция не сохраняет порядок. Это означает, что если вы попробуете отсортировать по value, то получите сортировку в плане, в то время как во многих случаях этого удавалось избегать для других функций, упомянутых выше. Например:
Вот план:
Тем не менее, это универсальная функция, которая упростит код и - даже с сортировкой - будет выполняться не хуже, чем существующие методы, также требующие сортировки. Microsoft а курсе этой проблемы, поэтому при ее решении функция станет еще лучше!
Мы можем комбинировать DATE_BUCKET и GENERATE_SERIES, чтобы построить последовательность значений даты/времени. Я знаю людей, которые стараются построить полный набор данных, когда они делают отчет по интервалам, и не все интервалы заполнены значениями. Например, я хочу выяснить почасовые продажи в течение дня, но, если мы продаем что-то типа автомобилей, то не каждый час будет содержать продажу. Пусть у нас есть такие данные:
Если я хочу получить продажи по часам в рабочее время 1 мая, я мог бы написать такой запрос:
Вот что я получу:
А то, что я действительно хочу, это по строке на каждый час, даже если там не было продаж:
Обычно мы начнаем с простого рекурсивного CTE, который строит все возможные строки в диапазоне, а затем выполняем левое соединение с имеющимся данными.
Что мне меньше всего нравится в этом решении, так это неудобное выражение dateadd/datediff для нормализации данных даты/времени на начало часа. Функции типа SMALLDATETIMEFROMPARTS более понятны в этом смысле, но еще более утомительны при конструировании. Вместо этого я хотел использовать DATE_BUCKET и GENERATE_SERIES, чтобы перевернуть весь этот шаблон с ног на голову:
Я вижу большой потенциал обеих функций для упрощения логики и уменьшения зависимости от вспомогательных объектов.
Есть еще несколько других улучшенй T-SQL в SQL Server 2022, но я оставлю их Itzik Ben-Gan, чтобы упомянуть эту статью:
Пока вот несколько наиболее полезных изменений, с которыми я мог познакомиться в SQL Server 2022:
- GREATEST / LEAST
- STRING_SPLIT
- DATE_BUCKET
- GENERATE_SERIES
В этой статье я объясню каждую из них и покажу несколько практических примеров их использования.
GREATEST / LEAST
Как отмечалось ранее, эти функции напоминают MAX и MIN, но по столбцам, а не по строкам. Быстрая демонстрация:
SELECT GREATEST(1, 5), -- возвращает 5
GREATEST(6, 2), -- возвращает 6
LEAST (1, 5), -- возвращает 1
LEAST (6, 2); -- возвращает 2В этом простом примере логика во многом подобна выражению CASE. Возьмем только первый случай:
SELECT CASE WHEN 1 > 5 THEN 1 ELSE 5 END;При оценке двух выражений это действительно просто: первое выражение превосходит второе, или нет? (Однако, вспоминая о NULL, обе новые функции игнорируют NULL, как и MAX/MIN.)
Хотя, если добавить третье значение, это становится более сложным. В то время как новый синтаксис предложит такое решение:
SELECT GREATEST(1, 5, 3); -- возвращает 5То, как это выразилось через CASE в текущей и более старых версиях, выглядит муторно:
SELECT CASE
WHEN 1 > 5 THEN
CASE WHEN 1 > 3 THEN 1 ELSE 3 END
ELSE
CASE WHEN 5 > 3 THEN 5 ELSE 3 END
END;И, как вы можете себе представить, это будет выглядеть еще хуже при сравнении 4 или более значений в CASE. Я даже не буду пытаться печатать такую паутину.
Давайте рассмотрим реальную задачу, поскольку трудно симулировать сложность, когда мы говорим о вещах, которые можно легко решить в голове. Возьмем следующую таблицу, которая содержит по строке на каждый год и столбцы с месячными продажами (мы возьмем только три месяца для упрощения):
CREATE TABLE dbo.SummarizedSales
(
Year int,
Jan int,
Feb int,
Mar int --,...
);
INSERT dbo.SummarizedSales(Year, Jan, Feb, Mar)
VALUES
(2021, 55000, 81000, 74000),
(2022, 60000, 92000, 86000);Если мы хотим вернуть наибольшую и наименьшую сумму продаж для каждого года, то могли бы написать утомительные выражения CASE (опять просто представьте, что если бы мы имели все 12 месяцев):
SELECT Year,
BestMonth = CASE
WHEN Jan > Feb THEN
CASE WHEN Jan > Mar THEN Jan ELSE Mar END
ELSE
CASE WHEN Mar > Feb THEN Mar ELSE Feb END
END,
WorstMonth = CASE
WHEN Jan < Feb THEN
CASE WHEN Jan < Mar THEN Jan ELSE Mar END
ELSE
CASE WHEN Mar < Feb THEN Mar ELSE Feb END
END
FROM dbo.SummarizedSales;Результат
Year BestMonth WorstMonth
---- --------- ----------
2021 81000 55000
2022 92000 60000
Имеется пара других способов решить эту задачу, которые, по крайней мере, лучше масштабируются без экспоненциального усложнения кода. Один из методов использует UNPIVOT:
SELECT Year,
BestMonth = MAX(Months.MonthlyTotal),
WorstMonth = MIN(Months.MonthlyTotal)
FROM dbo.SummarizedSales AS s
UNPIVOT
(
MonthlyTotal FOR [Month] IN ([Jan],[Feb],[Mar])
) AS Months
GROUP BY Year;А другой использует CROSS APPLY:
SELECT Year,
BestMonth = MAX(MonthlyTotal),
WorstMonth = MIN(MonthlyTotal)
FROM
(
SELECT s.Year, Months.MonthlyTotal
FROM dbo.SummarizedSales AS s
CROSS APPLY (VALUES([Jan]),([Feb]),([Mar])) AS [Months](MonthlyTotal)
) AS Sales
GROUP BY Year;Эти методы легче обобшить на большее число столбцов, но они все же утомительны, и мне не нравится, что они оба используют операции транспонирования и группировки. Теперь мы можем выполнить такого рода задачи с большой легкостью:
SELECT Year,
BestMonth = GREATEST([Jan],[Feb],[Mar]),
WorstMonth = LEAST ([Jan],[Feb],[Mar])
FROM dbo.SummarizedSales;STRING_SPLIT
Я писал об усилении этой функции в плане enable_ordinal, но я хотел бы сейчас упомянуть об этом снова, т.к. не мог тогда подтвердить сделанные изменения в SQL Server 2022. Теперь могу, и я хотел бы привести несколько случаев использования, когда исходная позиция важна.
Нахождение n-го элемента в списке с запятой-разделителем
Я встречал много запросов для возвращения второго или третьего элемента в списке, которые раньше громоздко выполнялись с помощью STRING_SPLIT, поскольку выходной порядок не гарантировался. Помимо этого вы могли видеть более громоздкие решения с помощью OPENJSON или трюков с PARSENAME. С новым параметром я могу просто написать:
DECLARE @list nvarchar(max) = N'35, Bugatti, 89, Astley';
SELECT value FROM STRING_SPLIT(@list, N',', 1) WHERE ordinal = 2;
-- теперь на выходе гарантировано получение BugattiСоединение с отсортированными данными на базе позиции в списке
Пусть вы хотите назначить новые списки продавцам на основе прошлой работы. У вас есть такая таблица:
CREATE TABLE dbo.SalesLeaderBoard
(
SalesPersonID int,
SalesSoFar int
);
INSERT dbo.SalesLeaderBoard(SalesPersonID, SalesSoFar)
VALUES(1,2),(2,7),(3,8),(4,5),(5,1),(6,12);И теперь у вас есть набор новых поступивших списков, ранжированных по предпочтениям:
DECLARE @NewListings varchar(max) = '81, 76, 80';В этом случае мы хотели бы назначить наиболее предпочтительный список (81) продавцу 6, второй список (76) продавцу 3, а третий (80) - продавцу 2. Имея осмысленный и надежный ordinal, результат достигается легко:
SELECT Leaders.SalesPersonID, Listing = Listings.value
FROM STRING_SPLIT(@NewListings, ',', 1) AS Listings
INNER JOIN
(
SELECT TOP (3) SalesPersonID,
Ranking = ROW_NUMBER() OVER
(ORDER BY SalesSoFar DESC, SalesPersonID)
FROM dbo.SalesLeaderBoard
ORDER BY SalesSoFar DESC
) AS Leaders
ON Listings.ordinal = Leaders.Ranking;Результат:
SalesPersonID Listing
------------- -------
6 81
3 76
2 80
Реконструкция строк и сохранение порядка
Другим сценарием с утомительным приемом решения является реконструкция строки для удаления дубликатов. Допустим, что у нас есть такая строка:
Bravo/Alpha/Bravo/Tango/Delta/Bravo/Alpha/Delta
Мы хотим удалить дубликаты из списка, но оставить исходный порядок, т.е. требуемый выход должен быть таким:
Bravo/Alpha/Tango/Delta
С этой новой функциональностью мы можем точно перестроить строку непосредственно, выбирая первый экземпляр любой строки в списке, а затем с помощью его общего исходного положения задать порядок, используя STRING_AGG:
DECLARE @List nvarchar(max), @Delim nchar(1) = N'/';
SET @List = N'Bravo/Alpha/Bravo/Tango/Delta/Bravo/Alpha/Delta';
SELECT STRING_AGG(value, N'/') WITHIN GROUP (ORDER BY ordinal)
FROM
(
SELECT value, ordinal = MIN(ordinal)
FROM STRING_SPLIT(@List, @Delim, 1)
GROUP BY value
) AS src;
Результат:
Bravo/Alpha/Tango/Delta
Это значительно более простой подход, чем те неуклюжие решения, которые я использовал в прошлом.
Тем не менее...
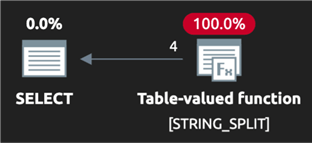
К сожалению, STRING_SPLIT все еще ограничен односимвольным разделителем. Хотя новый аргумент enable_ordinal упрощает некоторые наиболее часто используемые случаи, которые традиционно требовали утомительных обходных путей. Это также дает преимущество в производительности по сравнению с текущими методами, поскольку оптимизатор знает, что данные вернутся отсортированными. Это означает, что не всегда требуется явно добавлять оператор сортировки в план, если требуется упорядочить данные по исходным позициям. В то время как пример выше требовал сортировки, в следующем примере это не делается:
DECLARE @List varchar(max) = N'32,27,6,54';
SELECT value FROM STRING_SPLIT(@List, ',', 1)
ORDER BY ordinal;Вот план:
DATE_BUCKET
Эта функция сжимает дату/время к фиксированному интервалу, устраняя необходимость округлять значения datetime, вытаскивать компоненты даты, выполнять дикие преобразования в и из других типов данных типа float или делать сложные и интуитивно непонятные вычисления dateadd/datediff (иногда используя магические даты из прошлого).
Аргументами являются:
DATE_BUCKET(<компонента_даты>, <ширина>, <входная дата/время> [, <источник>])
Результатом является тип даты/времени (на основе входа), но с интервалом, определяемым компонентой_даты и шириной. Например, если бы я хотел упростить вывод определенного столбца, чтобы он просто давал мне границы месяца, то раньше я мог бы сделать это так:
SELECT name, modify_date,
MonthModified = DATEADD(MONTH, DATEDIFF(MONTH, '19000101', modify_date), '19000101')
FROM sys.all_objects;Или так для SQL Server 2012 и выше:
SELECT name, modify_date,
MonthModified = DATEFROMPARTS(YEAR(modify_date), MONTH(modify_date), 1)
FROM sys.all_objects;Теперь на SQL Server 2022 я могу сделать это так:
SELECT name, modify_date,
MonthModified = DATE_BUCKET(MONTH, 1, modify_date)
FROM sys.all_objects;Все три вышеприведенных запроса дадут идентичные результаты:
name modify_date MonthModified
--------------------------- ----------------------- -----------------------
sp_MSalreadyhavegeneration 2022-04-05 17:46:02.420 2022-04-01 00:00:00.000
sp_MSwritemergeperfcounter 2022-04-05 17:46:15.410 2022-04-01 00:00:00.000
sp_drop_trusted_assembly 2022-04-05 17:45:32.097 2022-04-01 00:00:00.000
sp_replsetsyncstatus 2022-04-05 17:45:41.850 2022-04-01 00:00:00.000
sp_replshowcmds 2022-04-05 17:45:48.197 2022-04-01 00:00:00.000
...
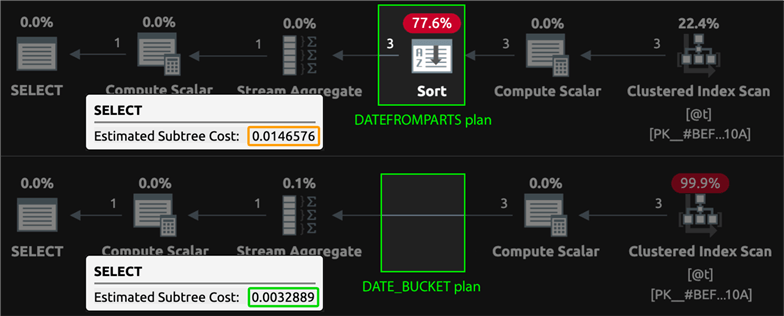
Кроме того, это может дать лучшую производительность в ряде случаев. Поскольку функция сохраняет порядок, есть случаи, когда сортровки можно избежать. Отставив в сторону системные объекты, давайте создадим упрощенную таблицу и сравним планы, созданные группировкой:
DECLARE @t table(TheDate date PRIMARY KEY);
INSERT @t(TheDate) VALUES('20220701'),('20220702'),('20220703');
SELECT TheMonth = DATEFROMPARTS(YEAR(TheDate), MONTH(TheDate), 1),
TheCount = COUNT(*)
FROM @t GROUP BY DATEFROMPARTS(YEAR(TheDate), MONTH(TheDate), 1);
SELECT TheMonth = DATE_BUCKET(MONTH, 1, TheDate),
TheCount = COUNT(*)
FROM @t GROUP BY DATE_BUCKET(MONTH, 1, TheDate);Вот эти планы:
Важно то, что функция позволяет делать и более сложные вещи, например, разбивку данных на 5-минутные интервалы:
DECLARE @Orders table(OrderID int, OrderDate datetime);
INSERT @Orders(OrderID, OrderDate) VALUES (1,'20220501 00:03'),
(1,'20220501 00:04'), (1,'20220501 00:05'), (1,'20220501 00:06'),
(1,'20220501 00:07'), (1,'20220501 00:10'), (1,'20220501 00:11');
SELECT Interval = DATE_BUCKET(MINUTE, 5, OrderDate),
OrderCount = COUNT(*)
FROM @Orders
GROUP BY DATE_BUCKET(MINUTE, 5, OrderDate); Результат:
Interval OrderCount
----------------------- ----------
2022-05-01 00:00:00.000 2
2022-05-01 00:05:00.000 3
2022-05-01 00:10:00.000 2
Как насчет 10-минутных интервалов? Без проблем. Мы можем даже передать параметр или переменную, чтобы можно было подстраиваться на лету:
DECLARE @MinuteWindow tinyint = 10;
SELECT Interval = DATE_BUCKET(MINUTE, @MinuteWindow, OrderDate),
OrderCount = COUNT(*)
FROM @Orders
GROUP BY DATE_BUCKET(MINUTE, @MinuteWindow, OrderDate);Результат:
Interval OrderCount
----------------------- ----------
2022-05-01 00:00:00.000 5
2022-05-01 00:10:00.000 2
Еще одна вещь, которую я могу сделать, — это значительно упростить расчет недельных границ. Вот совершенно неинтуитивный загадочный способ получить предыдущую субботу (независимо от пользовательских установок SET DATEFIRST или SET LANGUAGE):
DECLARE @d date = GETDATE(), @PrevSat date;
SET @PrevSat = DATEADD(DAY, -(DATEPART(WEEKDAY, @d) + @@DATEFIRST) % 7, @d);
SELECT @PrevSat; Если вы знаете какую-либо субботу в прошлом, например 1 января 2000, то можем упростить это, передав эту дату в параметре источник:
DECLARE @KnownSat date = '20000101';
SET @PrevSat = DATE_BUCKET(WEEK, 1, @d, @KnownSat);
SELECT @PrevSat;Это даст тот же ответ (на момент написания - во вторник 24 мая 2022 - будет получена суббота 21 мая 2022). И, как и выше, если мы имеем набор данных, то можем использовать такую же технику, чтобы фильтровать или группировать на основе любого известного дня недели.
DECLARE @LawnServices table(CustomerID int, ServiceDate date);
INSERT @LawnServices(CustomerID, ServiceDate) VALUES (1, '20220501'),
(1, '20220508'), (1, '20220516'), (1, '20220526'), (1, '20220603'),
(2, '20220501'), (2, '20220517'), (2, '20220527'), (1, '20220602');
DECLARE @KnownSat date = '20000101';
SELECT [Week] = DATE_BUCKET(WEEK, 1, ServiceDate, @KnownSat), Services = COUNT(*)
FROM @LawnServices
GROUP BY DATE_BUCKET(WEEK, 1, ServiceDate, @KnownSat);Результат:
Week Services
---------- ---------
2022-04-30 2
2022-05-07 1
2022-05-14 2
2022-05-21 2
2022-05-28 2
Это значтельно более простой способ сегментировать данные на основе нестандартной рабочей недели. В качестве еще одного примера могу привести график дежурств нашей команды в Stack Overflow, который циклически повторяется по средам, и я уже использовал эту функцию, чтобы спрогнозировать наше будущее расписание.
GENERATE_SERIES
Эта функция производит основанную на множестве последовательность числовых значений. Она заменяет громоздкие таблицы чисел, рекурсивные CTE и другие методы генерации последовательностей на лету, которые все мы использовали так или иначе.
У функции имеются следующие аргументы:
GENERATE_SERIES(START =, STOP = [, STEP = ])
Пара простых примеров:
SELECT value FROM GENERATE_SERIES(START = 1, STOP = 5);
SELECT value FROM GENERATE_SERIES(START = 1, STOP = 32, STEP = 7);Результаты:
value
-----
1
2
3
4
5
value
-----
1
8
15
22
29
(Обратите внимание на отсутствие значения STOP или близкого к нему, если следующий шаг (STEP) обходит его.)
В предшествующих версиях для генерации подобной последовательсности чисел вы, вероятно, использовал бы таблицу чисел или такой рекурсивный CTE:
WITH cte(n) AS
(
SELECT 1 UNION ALL
SELECT n + 1 FROM n WHERE n < 5
)
SELECT value = n /* или ((n-1)*7)+1 */ FROM cte;GENERATE_SERIES имеет очевидные преимущества в смысле простоты использования.
Эта функция имеет один недостаток - она является оператором, а не табличнозначной функцией, поэтому, если вы не укажите имя параметра явно, то получите неожиданный результат:
SELECT * FROM GENERATE_SERIES(1, 5); Вы увидите сбивающее с толку сообщение об ошибке:
Msg 208, Level 16, State 1, Line 1
Invalid object name 'GENERATE_SERIES'.
Это подразумевает разнообразие проблем, включая то, что функция не существует, что требуется указать префикс dbo., что мы подключены не к тому серверу, что апгрейд завершился неудачно, или что это на самом деле скалярная функция.
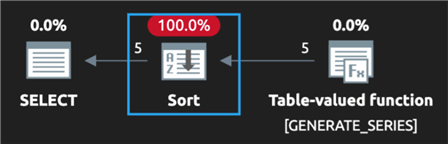
Другой недостаток состот в том - по крайней мере, в текущем билде - что эта функция не сохраняет порядок. Это означает, что если вы попробуете отсортировать по value, то получите сортировку в плане, в то время как во многих случаях этого удавалось избегать для других функций, упомянутых выше. Например:
SELECT value FROM GENERATE_SERIES(START = 1, STOP = 5) ORDER BY value;Вот план:
Тем не менее, это универсальная функция, которая упростит код и - даже с сортировкой - будет выполняться не хуже, чем существующие методы, также требующие сортировки. Microsoft а курсе этой проблемы, поэтому при ее решении функция станет еще лучше!
Бонус
Мы можем комбинировать DATE_BUCKET и GENERATE_SERIES, чтобы построить последовательность значений даты/времени. Я знаю людей, которые стараются построить полный набор данных, когда они делают отчет по интервалам, и не все интервалы заполнены значениями. Например, я хочу выяснить почасовые продажи в течение дня, но, если мы продаем что-то типа автомобилей, то не каждый час будет содержать продажу. Пусть у нас есть такие данные:
CREATE TABLE dbo.Sales
(
OrderDateTime datetime,
Total decimal(12,2)
);
INSERT dbo.Sales(OrderDateTime, Total) VALUES
('20220501 09:35', 21000), ('20220501 09:47', 30000),
('20220501 11:35', 23000), ('20220501 12:55', 32500),
('20220501 12:57', 16000), ('20220501 13:42', 17900),
('20220501 15:05', 20950), ('20220501 15:45', 24700),
('20220501 15:49', 18750), ('20220501 15:51', 21800);Если я хочу получить продажи по часам в рабочее время 1 мая, я мог бы написать такой запрос:
DECLARE @Start datetime = '20220501 09:00',
@End datetime = '20220501 17:00';
SELECT OrderHour, HourlySales = SUM(Total)
FROM
(
SELECT Total,
OrderHour = DATEADD(HOUR, DATEDIFF(HOUR, @Start, OrderDateTime), @Start)
FROM dbo.Sales
WHERE OrderDateTime >= @Start
AND OrderDateTime < @End
) AS sq
GROUP BY OrderHour;Вот что я получу:
OrderHour HourlySales
---------------- -----------
2022-05-01 09:00 51000.00
2022-05-01 11:00 23000.00
2022-05-01 12:00 48500.00
2022-05-01 13:00 17900.00
2022-05-01 15:00 86200.00А то, что я действительно хочу, это по строке на каждый час, даже если там не было продаж:
OrderHour HourlySales
---------------- -----------
2022-05-01 09:00 51000.00
2022-05-01 10:00 0.00
2022-05-01 11:00 23000.00
2022-05-01 12:00 48500.00
2022-05-01 13:00 17900.00
2022-05-01 14:00 0.00
2022-05-01 15:00 86200.00
2022-05-01 16:00 0.00
Обычно мы начнаем с простого рекурсивного CTE, который строит все возможные строки в диапазоне, а затем выполняем левое соединение с имеющимся данными.
DECLARE @Start datetime = '20220501 09:00',
@End datetime = '20220501 17:00';
;WITH Hours(OrderHour) AS
(
SELECT @Start
UNION ALL
SELECT DATEADD(HOUR, 1, OrderHour)
FROM Hours WHERE OrderHour < @End
),
SalesData AS
(
SELECT OrderHour, HourlySales = SUM(Total)
FROM
(
SELECT Total,
OrderHour = DATEADD(HOUR, DATEDIFF(HOUR, @Start, OrderDateTime), @Start)
FROM dbo.Sales
WHERE OrderDateTime >= @Start
AND OrderDateTime < @End
) AS sq
GROUP BY OrderHour
)
SELECT OrderHour = h.OrderHour,
HourlySales = COALESCE(sd.HourlySales, 0)
FROM Hours AS h
LEFT OUTER JOIN SalesData AS sd
ON h.OrderHour = sd.OrderHour
WHERE h.OrderHour < @End;Что мне меньше всего нравится в этом решении, так это неудобное выражение dateadd/datediff для нормализации данных даты/времени на начало часа. Функции типа SMALLDATETIMEFROMPARTS более понятны в этом смысле, но еще более утомительны при конструировании. Вместо этого я хотел использовать DATE_BUCKET и GENERATE_SERIES, чтобы перевернуть весь этот шаблон с ног на голову:
DECLARE @Start datetime = '20220501 09:00',
@End datetime = '20220501 17:00';
;WITH Hours(OrderHour) AS
(
SELECT DATE_BUCKET(HOUR, 1, DATEADD(HOUR, gs.value, @Start))
FROM GENERATE_SERIES
(
START = 0,
STOP = DATEDIFF(HOUR, @Start, @End) – 1
) AS gs
)
SELECT h.OrderHour, HourlySales = COALESCE(SUM(Total),0)
FROM Hours AS h
LEFT OUTER JOIN dbo.Sales AS s
ON h.OrderHour = DATE_BUCKET(HOUR, 1, s.OrderDateTime)
/* -- альтернатива:
ON s.OrderDateTime >= h.OrderHour
AND s.OrderDateTime < DATEADD(HOUR, 1, h.OrderHour)
*/
GROUP BY h.OrderHour; Я вижу большой потенциал обеих функций для упрощения логики и уменьшения зависимости от вспомогательных объектов.
Авторитетные упоминания
Есть еще несколько других улучшенй T-SQL в SQL Server 2022, но я оставлю их Itzik Ben-Gan, чтобы упомянуть эту статью:
- Предложение WINDOW
- Предложене обработки NULL (IGNORE NULLS | RESPECT NULLS)
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой