
Как думать подобно SQL Server: что означает поиск ключа?
Пересказ статьи Brent Ozar. How to Think Like the SQL Server Engine: What’s a Key Lookup?
В паре наших последних статей мы использовали простой запрос для нахождения ИД тех, кто входил в систему с середины 2014 года:
SELECT Id
FROM dbo.Users
WHERE LastAccessDate > '2014-07-01'
ORDER BY LastAccessDate;Но один лишь ИД не очень полезен. Поэтому давайте добавим еще несколько столбцов в наш запрос:
SELECT LastAccessDate, Id, DisplayName, Age
FROM dbo.Users
WHERE LastAccessDate > '2014-07-01'
ORDER BY LastAccessDate;Теперь подумайте о том, как вы собираетесь выполнить этот план запроса на естественном языке. У вас есть две копии таблицы: некластеризованный индекс (черные страницы), содержащий LastAccessDate, Id:
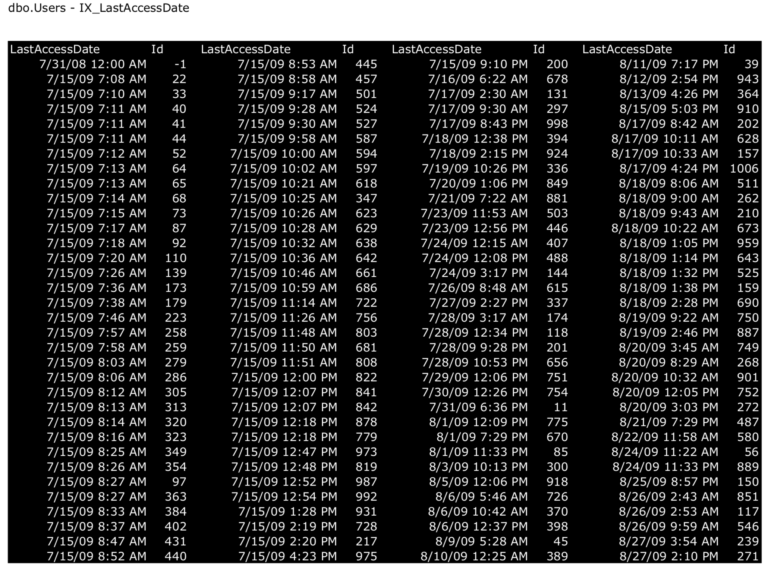
и кластеризованный индекс (белые страницы), содержащий все столбцы таблицы:
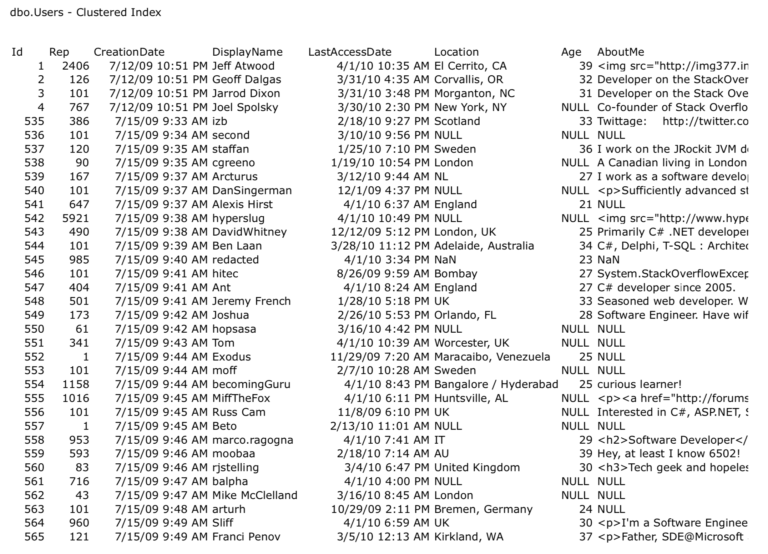
Один способ - это использовать сначала некластеризованный индекс.
Мы могли бы:
- Мы могли бы взять черные страницы, найти 2014-07-01 и начать составлять список нужных нам LastAccessDates и Id.
- Взять белые страницы, и для каждого Id, который мы нашли на черных страницах, найти эти id на белых страницах для получения дополнительных столбцов (DisplayName, Age), которых нет в черном индексе.
Вот как выглядит этот план запроса:
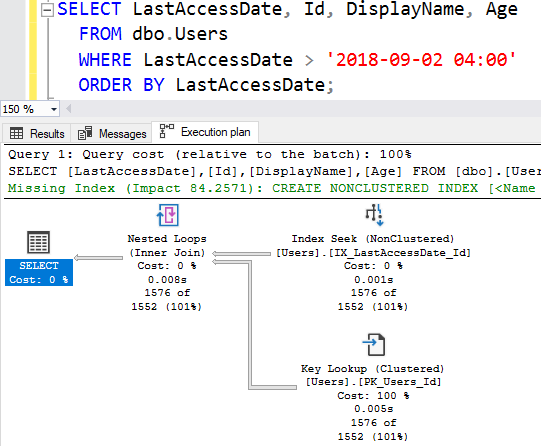 Мы читаем планы справа налево, но также сверху вниз.
Мы читаем планы справа налево, но также сверху вниз. Первое, что сделал SQL Server, это Index Seek (поиск по индексу) вверху справа - это поиск на черных страницах. SQL Server нашел конкретную дату-время, прочитал LastAccessDate и Id из каждой строки, и на этом закончилась работа Index Seek. (Это, в целом, отдельная автономная программа.)
Затем SQL Server берет этот список ИД и ищет каждый из них на белых страницах - это операция Key Lookup (поиск ключа). SQL Server использует свой кластеризованный ключ - в данном случае id, поскольку именно на id мы строили наш кластеризованный индекс. (Если вы не строите кластеризованный индекс, все равно тот же базовый процесс будет иметь место - но об этом в другой раз.)
Вот почему каждый некластеризованный индекс включает кластеризованные ключи.
Когда я впервые сказал вам, что создал черный индекс, я имел в виду это:
CREATE INDEX IX_LastAccessDate_Id
ON dbo.Users(LastAccessDate, Id);Но это не обязательно, я мог бы просто сделать так:
CREATE INDEX IX_LastAccessDate
ON dbo.Users(LastAccessDate);И мы получили бы те же самые черные страницы. SQL Server добавляет кластеризованные ключи в каждый некластеризованный индекс, поскольку он должен иметь возможность выполнить поиск этих ключей. Для каждой строки, которую он находит в некластеризованном индексе, он должен суметь перейти к соответствующей уникальной строке в кластеризованном индексе.
Я сначала сказал вам, что создал индекс на обоих столбцах, просто для того, чтобы вам легче было это понять.
Операторы Key Lookup скрывают множество деталей.
Я хочу, чтобы планы выполнения были трехмерными: Я бы хотел, чтобы операторы выдвигались со страницы столько раз, сколько раз они были выполнены. Вы видите этот "Key Lookup" и думаете, что он случился только раз, но это совсем не так. Наведите мышь на этот оператор, и вы увидите число выполнений (Number of Executions) - т.е. сколько раз он фактически выполнялся:
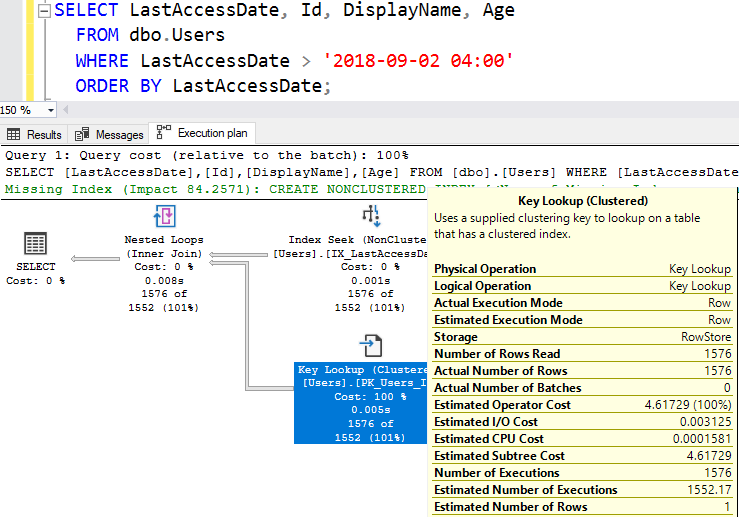
Ранее я писал, что когда Microsoft рисует что-то на экране, они либо выводят информацию в алфавитном порядке, либо загружают Data Cannon, запускают ее, и куда бы ни направлялись данные, туда они и попадают. Здесь эта подсказка была упорядочена с помощью Data Cannon, поэтому мы последуем за ней.
- Estimated Number of Executions основано на предположении SQL Server о том, сколько строк выйдет из Index Seek. Для каждой найденной строки, мы собираемся выполнять одну операцию Key Lookup.
- Estimated Number of Rows - как много строк вернет КАЖДЫЙ поиск ключа.
- Number of Executions - сколько раз мы фактически сделали это, основано на количестве строк, которые фактически вернул поиск по индексу.
- Actual Number of Rows - общее число строк, которые вернули ВСЕ поиски ключа (не каждая).
Я знаю. Иногда они говорят фактический (Actual), иногда - нет. Иногда числа на выполнение, иногда всего. Если вы ищите согласованность и организацию, не используйте Data Cannon. Я уверен, что они относятся к внутренним компонентам SQL Server гораздо точнее и осторожнее.
Стоимость поиска ключа - это логические чтения.
Всякий раз, когда мы выполняем поиск ключа - в данном случае 1576 раз - мы открываем белые страницы и выполняем несколько логических чтений. Чтобы увидеть это, давайте выполним запрос без поиска (который получает только Id), и многостолбцовый запрос (который получает также DisplayName и Age), и сравним число логических чтений:
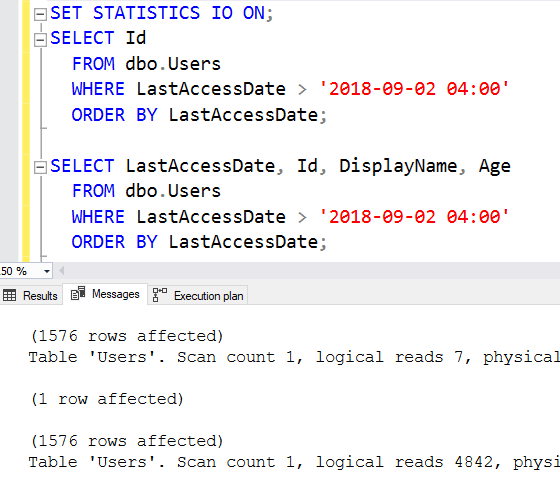
Верхний запрос дает только 7 чтений, а нижний - 4942! Эти 1576 поиска ключа должны выполнить около 3 логических чтений каждый. (Почему не просто 1 чтение каждый? Потому что им требуется навигация по древовидной структуре страниц, чтобы точно найти нужную страницу, которая содержит требуемые данные - это лишние пара или более страниц при всяком поиске в индексе. Мы еще поговорим об альтернативных решениях позже.)
Чем больше строк возвращает ваш поиск по индексу, тем больше вероятность того, что вы вообще не получите такой план выполнения. Обратите внимание, что в этой статье я не использовал 2014-07-01 в качестве даты фильтрации - я использовал более свежие данные. Почему? Об этом как раз в следующей публикации.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой