
Советы по производительности оператора SQL TOP
Пересказ статьи Esat Erkec. SQL TOP statement performance tips
В этой статье мы будем использовать учебную базу данных Adventureworks2019. Мы также будем использовать скрипт Create Enlarged AdventureWorks Tables для получения увеличенной версии этой базы данных.
Что такое оператор SQL TOP
Оператор TOP используется для ограничения числа строк, которые извлекаются или обновляются в одной или нескольких таблицах. Это ограничение на число строк можно задать как фиксированным значением, так и процентом строк в таблице. Например, следующий запрос вернет первые 10 случайных строк из таблицы Production.
SELECT TOP 10 Name,ProductNumber,SafetyStockLevel FROM Production.Product
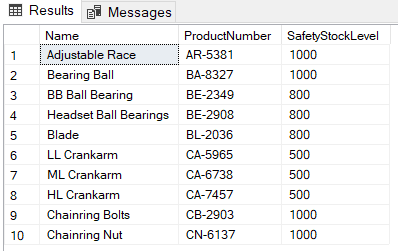
Также мы можем использовать ключевое слово PERCENT с оператором TOP, чтобы вернуть процент от общего количества строк результирующего набора. Следующий запрос вернет 12% строк таблицы Production.
SELECT TOP (12) PERCENT Name,ProductNumber,SafetyStockLevel FROM Production.Product
Этот запрос вернул 61 строку, поскольку таблица Production.Product содержит 504 строки, и 12 процентов от этого числа ((504/100)*12=60.48) равно 61.
Влияние оператора TOP на план запроса
Ежедневно оператор TOP часто используется разработчиками, чтобы ограничить число записей, которые возвращаются из их запросов. Однако оператор TOP может повлиять на план выполнения, который генерируется оптимизатором запросов. Когда мы используем в запросе оператор TOP, оптимизатор запросов может выбрать другой план для того же самого запроса, что и без предложения TOP. Следующий запрос соединяет таблицу SalesOrderHeaderEnlarged с таблицей SalesOrderDetailEnlarged, и когда мы выполним этот запрос, оптимизатор решит использовать адаптивный оператор JOIN. Этот оператор позволяет оптимизатору выбирать тип соединения - nested loop join или hash join - при выполнении запроса. Оптимизатор выбирает тип соединения на основе порогового числа строк и свойство Actual Join Type показывает, какой тип соединения использовался при выполнении запроса.
SELECT SO.AccountNumber FROM
Sales.SalesOrderHeaderEnlarged SO
INNER JOIN Sales.SalesOrderDetailEnlarged SD
ON SD.SalesOrderID = SO.SalesOrderID
Как видно на рисунке выше, оптимизатором для выполнения этого запроса был выбран оператор hash match join. Этот тип соединения предпочитает оптимизатор, когда требуется соединить большие объемы несортированных данных. При hash match join SQL Server создает хэш-таблицу в памяти, а затем начинает сканировать совпадающие строки в хэш-таблице. Теперь мы добавим выражение ТОР 10 в наш пример, и снова проанализируем план запроса.
SELECT TOP 10 SO.AccountNumber FROM
Sales.SalesOrderHeaderEnlarged SO
INNER JOIN Sales.SalesOrderDetailEnlarged SD
ON SD.SalesOrderID = SO.SalesOrderID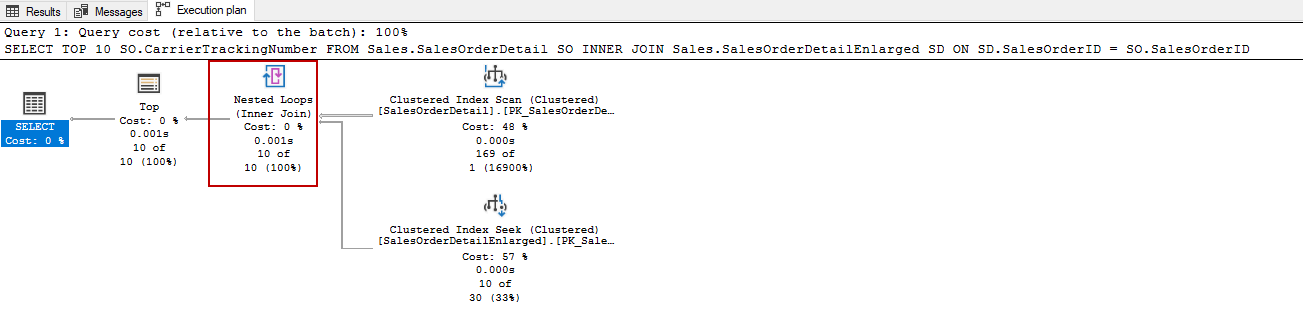
Как видно в плане выполнения запроса, оптимизатор начал использовать nested loop join вместо hash join. Тип соединения nested loop join основан на очень простом цикличном алгоритме. Для каждой строки из внешней таблицы разыскиваются строки внутренней таблицы, удовлетворяющие критериям соединения. Этот тип соединения показывает хорошую производительность при небольшом количестве строк. Изменение плана выполнения обусловлено тем, что оптимизатор запросов знает, что запрос вернет небольшое число строк из-за наличия предложения ТОР в запросе. Поэтому оптимизатор пытается найти более оптимальный план для более быстрого извлечения небольшого числа строк. В этих обстоятельствах nested loop join оказывается наиболее быстрым способом извлечения небольшого числа строк этого запроса и, кроме того, nested loop потребляет меньше ресурсов. Здесь стоит отметить один момент, оптимизатор пользуется преимуществом функции, которая называется row goal, для выполнения этого плана запроса, изменяющегося из-за предложения TOP.
Оператор TOP и Row Goal
Оптимизатор запросов SQL Server является оптимизатором на основе стоимости, и он генерирует различные альтернативы плана выполнения для запроса, а затем выбирает тот план выполнения, который имеет наименьшую стоимость. С другой стороны, некоторые ключевые слова запроса и хинты ограничивают число строк, которые возвращает запрос, поэтому оптимизатор предпочитает более эффективный план выполнения, который больше подходит в случае, когда возвращается небольшое число строк. Как мы указали, row goal применяется оптимизатором ко всему или части плана выполнения, чтобы извлекать строки более быстро. Теперь мы выполним, а затем проанализируем план выполнения следующего запроса, чтобы глубже понять эту особенность.
SELECT TOP 10 CarrierTrackingNumber FROM Sales.SalesOrderDetailEnlarged
WHERE ModifiedDate >='20140101'
and CarrierTrackingNumber IS NOT NULLВ этом запросе оцениваемое число строк равно 10, поскольку оптимизатор знает это в точности из-за наличия оператора ТОР.
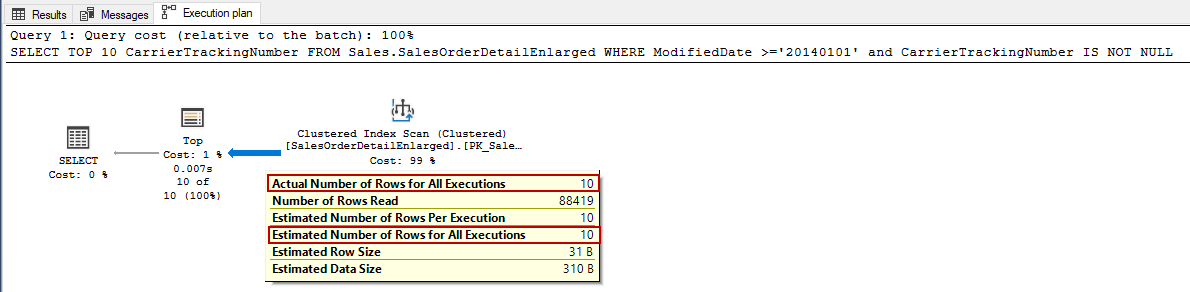
Однако этого недостаточно для понимания того, как оптимизатор применяет row goal к плану запроса. Атрибут EstimateRowsWithoutRowGoal показывает что row goal применяется к оператору плана запроса, и он определяет оценку количества строк, если row goal не будет использоваться оптимизатором.
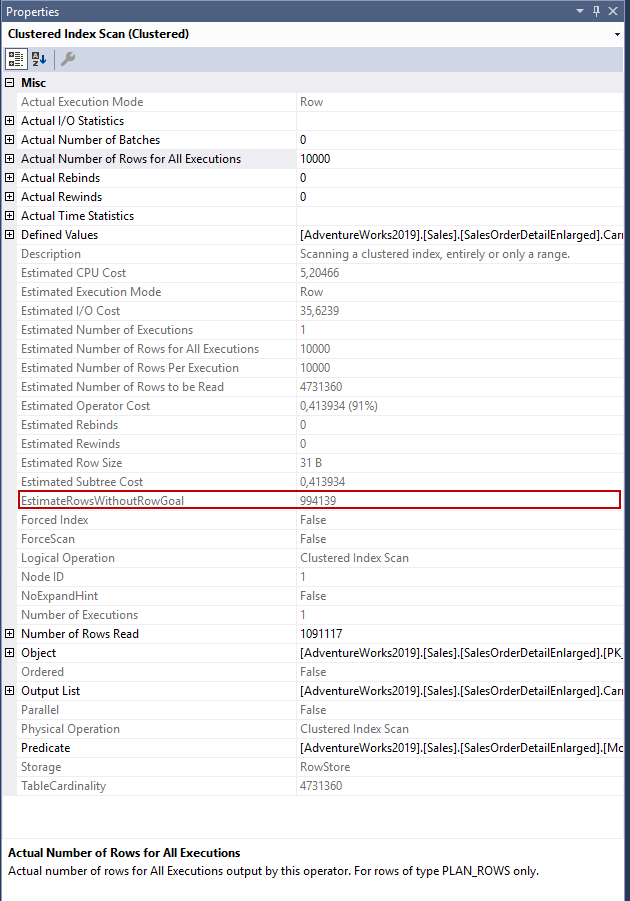
Мы можем использовать хинт запроса DISABLE_OPTIMIZER_ROWGOAL, чтобы отключить применение row goal к запросам. Если выполнить запрос с этим хинтом, оценка числа строк изменится.
SELECT TOP 10 CarrierTrackingNumber FROM Sales.SalesOrderDetailEnlarged
WHERE ModifiedDate >='20140101'
and CarrierTrackingNumber IS NOT NULL
OPTION (USE HINT ('DISABLE_OPTIMIZER_ROWGOAL'));
Пример использования: улучшение производительности оператора TOP
Здесь мы попытаемся улучшить производительность примера запроса с плохой производительностью. Прежде всего мы включим статистику времени выполнения и ввода/вывода, а затем выполним запрос для анализа этой статистики.
SET STATISTICS TIME ON
SET STATISTICS IO ON
GO
SELECT TOP 150 SO.AccountNumber FROM
Sales.SalesOrderHeader SO
INNER JOIN Sales.SalesOrderDetailEnlarged SD
ON SO.ModifiedDate = SD.ModifiedDate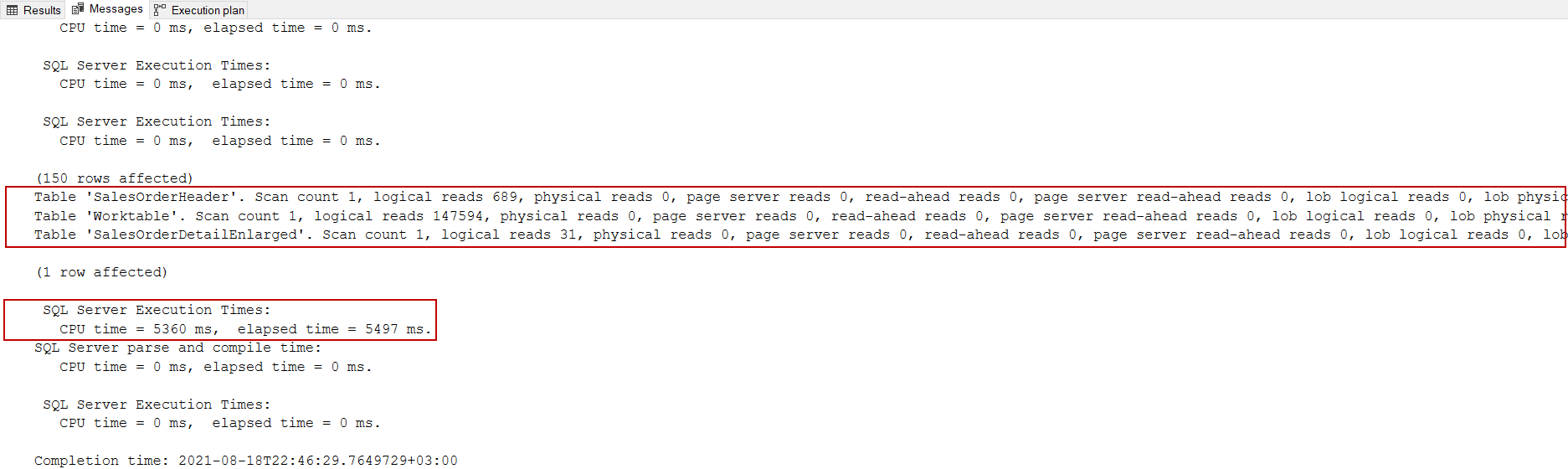
В выходных данных статистики запроса к Worktable было выполнено 147.594 логических чтений, несмотря на то, что в запросе не существует таблицы с именем Worktable. Причиной этого недоразумения является то, что worktable указывают на временные таблицы, которые создаются в базе данных tempdb при выполнении запроса. Основная цель создания этих таблиц - временное хранение промежуточных результирующих наборов. Теперь давайте поищем в плане запроса то, что вызвало такой громадный ввод/вывод. Сейчас мы будем смотреть фактический план выполнения запроса. В плане выполнения мы видим оператор Table Spool (Lazy Spool) и можем заметить, что он передает огромное число данных в оператор nested loop. Оператор Table Spool (Lazy Spool) создает временную таблицу в базе tempdb и сохраняет строки в этой временной таблице, когда родительский оператор запрашивает строку.

В то же время имеется огромная разница между оценкой и фактическим числом строк. В целом, для решения проблем данного типа мы можем обновить статистику, но в данном случае эта идея не поможет улучшить производительность запроса. Кроме того, спул таблицы находится на внутренней стороне соединения, это означает, что сумма фактического числа прокруток равна фактическому числу оператора на внешней стороне соединения (сканирование кластеризованного индекса).
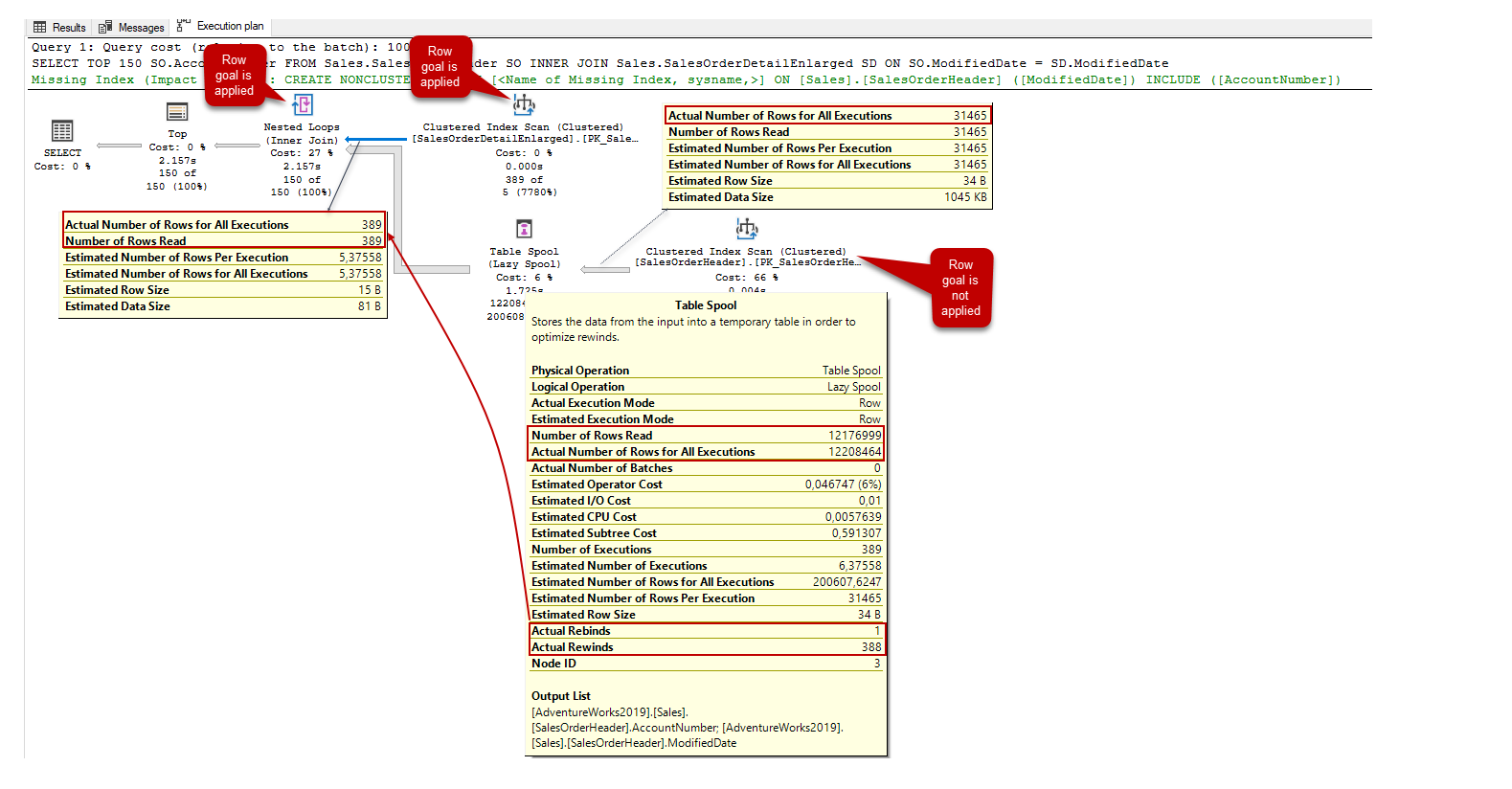
Оптимизатор запросов применил метод row goal к сканированию кластеризованного индекса (SalesOrderDetailEnlarged) и оператору nested loop, но этот метод не применялся к оператору сканирования кластеризованного индекса (SalesOrderHeader). Конкретно для этого запроса устранение оператора спула таблицы может уменьшить число операций ввода/вывода, что поможет улучшить производительность запроса. В целом, вы можете наблюдать оператор спула таблицы в сочетании с nested loop join, но мы можем заставить оптимизатор изменить этот тип соединения на другие альтернативные типы. Мы можем использовать предложение OPTION, чтобы добавить несколько хинтов, которые заставят оптимизатор изменить оптимальный план запроса. Чтобы избавиться от оператора спула таблицы, мы можем заставить оптимизатор использовать hash join вместо nested loop join. Для этого мы добавим оператор OPTION (HASH JOIN) в конец запроса.
SET STATISTICS TIME ON
SET STATISTICS IO ON
GO
SELECT TOP 150 SO.AccountNumber FROM
Sales.SalesOrderHeader SO
INNER JOIN Sales.SalesOrderDetailEnlarged SD
ON SO.ModifiedDate = SD.ModifiedDate
OPTION( HASH JOIN)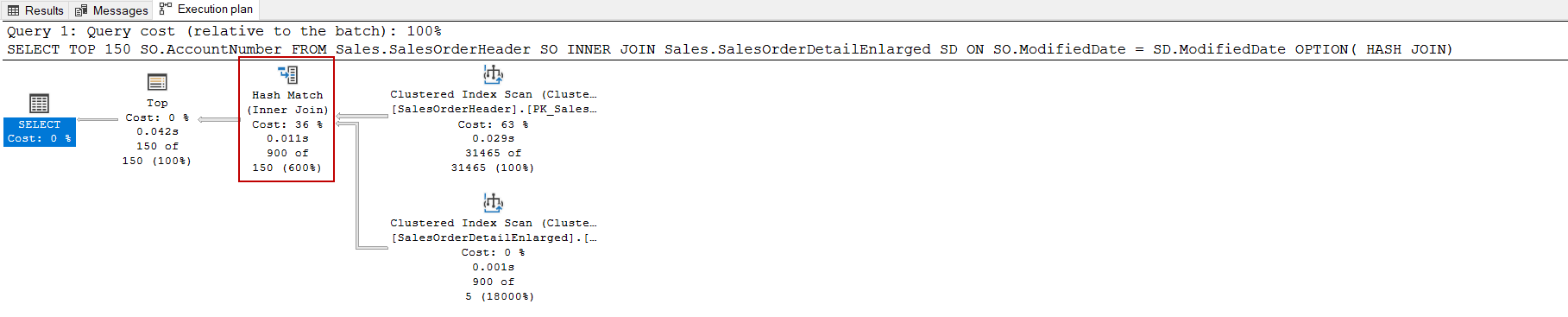
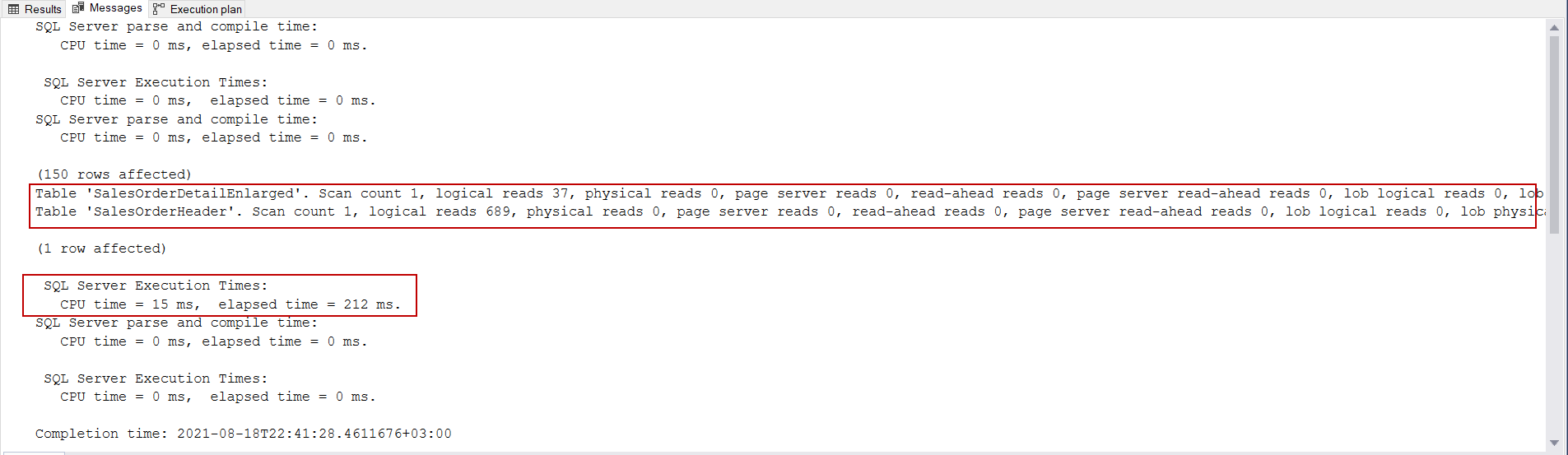
Как можно увидеть, после принуждения оптимизатора использовать hash join статистика по логическим чтениям и время выполнения сокращаются. В качестве альтернативы мы можем использовать флаг трассировки 8690 или NO_PERFORMANCE_SPOOL, чтобы отключить спул на внутренней стороне nested loop.
SELECT TOP 150 SO.AccountNumber FROM
Sales.SalesOrderHeader SO
INNER JOIN Sales.SalesOrderDetailEnlarged SD
ON SO.ModifiedDate = SD.ModifiedDate
OPTION(QUERYTRACEON 8690)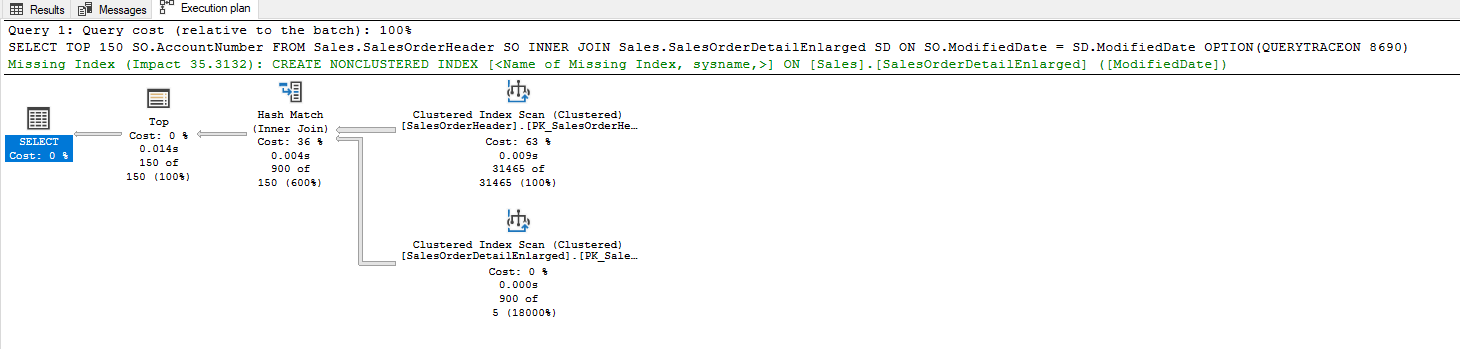
SELECT TOP 150 SO.AccountNumber FROM
Sales.SalesOrderHeader SO
INNER HASH JOIN Sales.SalesOrderDetailEnlarged SD
ON SO.ModifiedDate = SD.ModifiedDate
OPTION(NO_PERFORMANCE_SPOOL)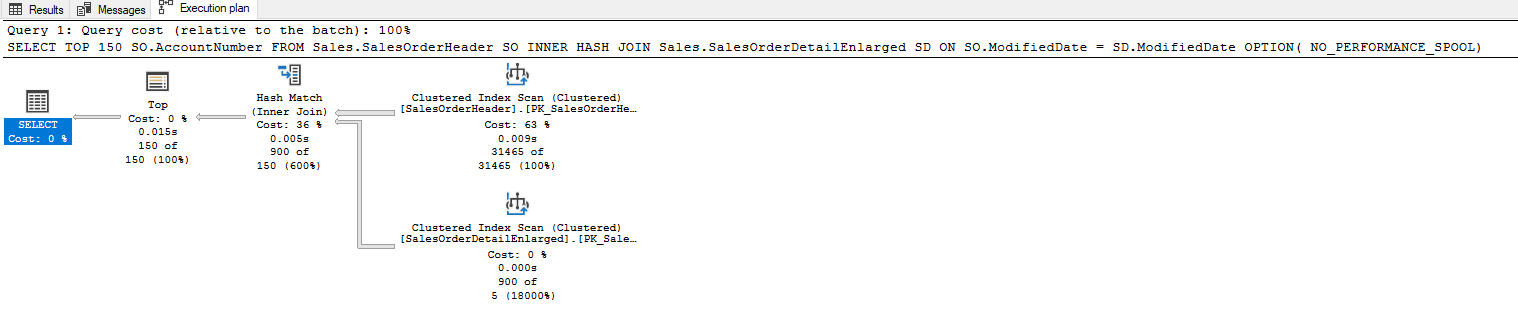
Оператор Table Spools используется для улучшения производительности запроса, но иногда он может стать узким местом в производительности.
Заключение
В этой статье мы подробно исследовали влияние оператора TOP на производительность. Оптимизатор запросов может изменить план выполнения, когда запрос включает предложение ТОР из-за наличия функции row goal.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой