
Адаптивные соединения в SQL Server
Пересказ статьи Monica Rathbun. Adaptive Joins in SQL Server
SQL Server 2017 (уровень совместимости 140) внес много интеллекта в обработку запросов, формально известного как адаптивная обработка запросов, функциональности, которая улучшает производительность при рабочих нагрузках прямо из коробки без каких-либо изменений кода. Одной из введенных новинок являются адаптивные соединения (Adaptive Joins). При этой функциональности оптимизатор динамически выбирает оператор соединения во время выполнения; для этого используется пороговое число строк, на основании которого делается выбор между операторами соединения Nested Loop (вложенные циклы) и Hash Match (соединения при поиске совпадений в хеше). Этот переключатель оператора может выбрать лучший вариант и увеличить производительность ваших запросов без прикладывания рук.
Не все запросы подходят для этой новой функции. Она применяется только к тем операторам SELECT, которые бы в обычных условиях возвращали Nested Loop или Hash Match; ни к каким другим соединениям она не применяется. Кроме того, запрос должен быть запущен в пакетном режиме (использование поколоночного индекса в запросе) или при использовании SQL Server 2019 в пакетном режиме для построчного хранения. О последнем варианте можно почитать здесь .
Теперь давайте разберемся с разницей между двумя различными операторами соединения, выбор из которых будет делать оптимизатор.
Hash Match - создает хеш-таблицу (в памяти) для требуемых столбцов для каждой строки, затем создает хеш-таблицу для второй таблицы и ищет совпадения по каждой строке. Это очень дорогая операция и требует много памяти.
Nested Loop - выполняет поиск во внутренней (меньшей) таблице для каждой строки внешней (большей) таблицы. Операция менее дорогая, чем Hash Match, и идеально подходит для малого числа строк на входе. Это наиболее быстрый оператор соединения, который требует наименьшего количества операций ввода/вывода с наименьшим количеством строк для сравнения.
Для отображения этой функции был введен новый оператор, показывающий, что использовался Adaptive Join, свойства последнего дают нам подробности определения того, какое соединение использовать.

Во время исполнения, если количество строк меньше адаптивного порогового значения Adaptive Threshold Rows), будет выбран Nested Loop. Если значение больше порогового, будет выбран Hash Match; так просто. Это может оказаться полезным для таких рабочих нагрузок, когда для одного и того же запроса используются небольшое и большое количество входных строк. Обратите внимание на скриншот ниже. Используя оценки, план должен был вернуть Hash Match, однако во время фактического выполнения, он динамически изменился на Nested Loop.
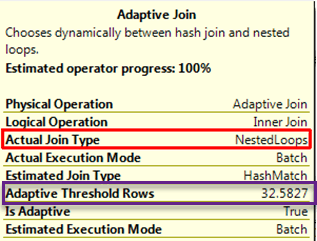
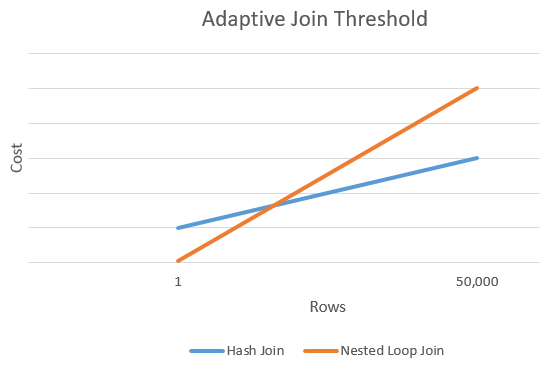
Пороговое значение числа строк определяется на основе стоимости оператора. Оптимизатор оценит стоимость каждого оператора, используя алгоритм для операции соединения. Точка, где стоимости пересекаются (критическая точка количества строк), используется для определения порогового значения. Документация Microsoft приводит хорошую картинку.
Подобно другим функциям, SQL Server дает возможность выключить её, если вы обнаружите, что она не дает выигрыша в производительности или вызывает замедление запроса в вашей рабочей среде.
— SQL Server 2017
— Azure SQL Database, SQL Server 2019 и выше
Интеллектуальная обработка запросов дает нам много новых "автоматических" корректировок для наших запросов. Адаптивные соединения - это то, что вызвало у меня интерес как администратора базы данных, который любит настраивать производительность. Неправильный выбор соединения, выполненный оптимизатором, может действительно ухудшить производительность, что, вероятно, потребовало бы от меня применения хинтов запроса или руководств по плану.
Мне очень нравится, что SQL Server теперь автоматически принимает интеллектуальные решения и меняет их на лету без моего вмешательства.
Теперь давайте разберемся с разницей между двумя различными операторами соединения, выбор из которых будет делать оптимизатор.
Hash Match - создает хеш-таблицу (в памяти) для требуемых столбцов для каждой строки, затем создает хеш-таблицу для второй таблицы и ищет совпадения по каждой строке. Это очень дорогая операция и требует много памяти.
Nested Loop - выполняет поиск во внутренней (меньшей) таблице для каждой строки внешней (большей) таблицы. Операция менее дорогая, чем Hash Match, и идеально подходит для малого числа строк на входе. Это наиболее быстрый оператор соединения, который требует наименьшего количества операций ввода/вывода с наименьшим количеством строк для сравнения.
Для отображения этой функции был введен новый оператор, показывающий, что использовался Adaptive Join, свойства последнего дают нам подробности определения того, какое соединение использовать.
Во время исполнения, если количество строк меньше адаптивного порогового значения Adaptive Threshold Rows), будет выбран Nested Loop. Если значение больше порогового, будет выбран Hash Match; так просто. Это может оказаться полезным для таких рабочих нагрузок, когда для одного и того же запроса используются небольшое и большое количество входных строк. Обратите внимание на скриншот ниже. Используя оценки, план должен был вернуть Hash Match, однако во время фактического выполнения, он динамически изменился на Nested Loop.
Пороговое значение числа строк определяется на основе стоимости оператора. Оптимизатор оценит стоимость каждого оператора, используя алгоритм для операции соединения. Точка, где стоимости пересекаются (критическая точка количества строк), используется для определения порогового значения. Документация Microsoft приводит хорошую картинку.
Подобно другим функциям, SQL Server дает возможность выключить её, если вы обнаружите, что она не дает выигрыша в производительности или вызывает замедление запроса в вашей рабочей среде.
— SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION
SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = ON;— Azure SQL Database, SQL Server 2019 и выше
ALTER DATABASE SCOPED CONFIGURATION
SET BATCH_MODE_ADAPTIVE_JOINS = OFF;Интеллектуальная обработка запросов дает нам много новых "автоматических" корректировок для наших запросов. Адаптивные соединения - это то, что вызвало у меня интерес как администратора базы данных, который любит настраивать производительность. Неправильный выбор соединения, выполненный оптимизатором, может действительно ухудшить производительность, что, вероятно, потребовало бы от меня применения хинтов запроса или руководств по плану.
Мне очень нравится, что SQL Server теперь автоматически принимает интеллектуальные решения и меняет их на лету без моего вмешательства.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой