
Внутри оптимизатора: подробно о ROW GOAL
Пересказ статьи Paul White. Inside the Optimizer: Row Goals In Depth
Одно из главных предположений, из которых исходит модель оптимизатора запросов SQL Server, заключается в том, что клиенты потребляют все строки, производимые запросом. Это приводит к планам, которые исходят из полной стоимости выполнения, хотя строки могут больше не производиться.
Давайте рассмотрим пример:
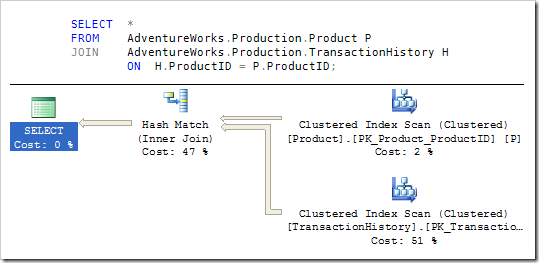
Оптимизатор выбирает для выполнения логического соединения физический итератор Hash Match, что подтверждается оценкой стоимости плана приблизительно в 1,4 единиц. Принудительно заставляя выбрать альтернативное физическое соединение при помощи хинта запроса, мы увидим, что план на основе merge join имеет оценку стоимости под 10, а nested loops join получает оценку свыше 18 единиц. Все эти оценки стоимости опираются на предположение, что нужны все строки.
Как подробно описано в предыдущей статье , итератор Hash Match начинает с получения всех строк build input (таблица Product) для того, чтобы построить хэш-таблицу. Это делает Hash Match самоблокирующим итератором: он может начать производить выходные строки только тогда, когда фаза построения завершена. Если нам нужно быстро получить несколько первых строк запроса, этот тип соединения может оказаться не оптимальным.
Насколько быстро merge join начинает выдавать строки зависит от того, нуждается ли какой-либо из его входных потоков в явной сортировке. Если merge может получить упорядоченные строки обоих входных потоков из индекса или предшествующей операции без сортировки, он может направить строки в родительский узел без стартовой задержки.
Итератор сортировки в плане запроса всегда является блокирующей операцией, поскольку мы не можем знать, какая строка будет первой в отсортированном порядке без проверки их всех. В запросе из примера строки из таблицы истории требуют явной сортировки, поэтому merge join не будет хорошим выбором для быстрого получения первых строк.
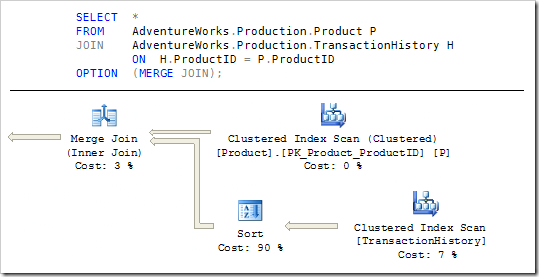
Наш третий вариант операции соединения - nested loops - является обычно конвейерным итератором. Это означает отсутствие стартовой задержки, и первые совпадающие строки возвращаются быстро. К сожалению, он также имеет наивысшую предварительную построчную стоимость среди трех физических операций соединения.
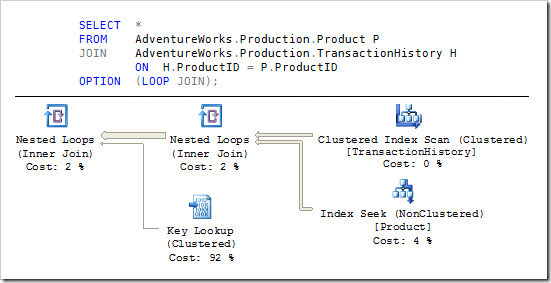
Итератор nested loops выполняет свой внутренний (нижний) вход один раз для каждой строки, производимой его внешним (верхним) входом, что делает общую стоимость пропорциональной произведению числа строк, полученных из дочерних входных потоков. Напротив, стратегии hash и merge соединений сканируют каждый из входов один раз, что дает оценку стоимости пропорциональной сумме числа строк входных потоков.
Получение нескольких первых строк, производимых запросом, является задачей, легко решаемой на уровне автора запроса: просто добавить предложение TOP. Предположим, что нас интересует только одна строка из результатов запроса:
Исходный запрос возвращает 113443 строк. Данный запрос возвращает только одну, и делает это очень быстро. Поскольку это очевидно, вы можете так и думать, однако все не то, чем кажется.
Прежде чем я углублюсь в этот вопрос, замечу, что вышеприведенный запрос с TOP(1) содержит "баг": в нем отсутствует предложение ORDER BY, отвечающее за то, какая строка будет "верхней". В принципе, производимая этим запросом строка может быть выбрана случайным образом. На практике же результат зависит от плана запроса и деталей внутренней реализации в SQL Server. Поскольку каждая из этих вещей может измениться в любой момент, вы должны почти всегда указывать детерминированное предложение ORDER BY при использовании TOP.
Если вы задумались о том, что может быть недетерминированным в ORDER BY, рассмотрите что может случиться, если добавить в запрос "ORDER BY P.ProductID". Сложность возникает, поскольку ProductID не является уникальным для каждой строки результирующего набора (таблица истории транзакций может содержать множество строк для каждого продукта). В качестве конкретного примера предположим, что продукт #1 является наименьшим ProductID, и есть 75 записей в исторической таблице для этого продукта. Эти 75 записей сортируются равноправно по ProductID, тогда какая запись будет возвращена операцией TOP(1)?
Есть два метода сделать операцию детерминированной. Первый, мы можем переписать ORDER BY для включения в него комбинации столбцов, которые формируют уникальный ключ для множества выводимых строк; добавление ID транзакции из исторической таблицы позволяет этого добиться. Второй, мы можем добавить WITH TIES в спецификацию TOP, хотя это произведет более одной строки в случае дубликатов.
Я опустил ORDER BY в нашем простом примере, поскольку я действительно не представляю, какую строку мы получим, и мне хочется избежать изменения семантики оригинального запроса, чтобы продемонстрировать этот момент.
План запрос с TOP(1) выглядит следующим образом:
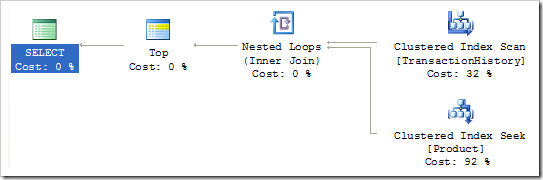
Этот план значительно отличается от оригинального плана запроса, который применял hash join. Понятно, что когда мы добавили предложение TOP в запрос, оптимизатор сделал больше простого добавления итератора TOP в корень плана, который он строит обычно. С целью сравнения, приведу план запроса, построенный для запроса с TOP(1), для которого навязан hash join.
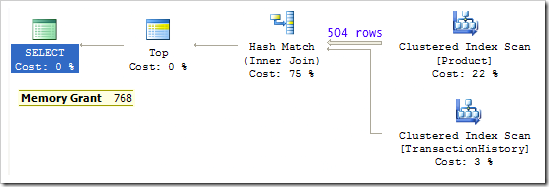
Важно заметить, что входной поток построения в hash join должен получить все 504 строки таблицы Product, прежде чем сможет стартовать процесс зондирования хэш-таблицы в поисках совпадений со строками из таблицы TransactionHistory. Подобно всем операциям с хэшем, hash join также требует выделения памяти, прежде чем план сможет начать выполнение. Предполагаемая стоимость плана hash join равна 0.1, в то время как план loops join, выбранный оптимизатором имеет оценку 0.01 единиц.
Проблемы, стоящие перед построителем оптимизированного плана для запросов с ограничением на вывод строк и сохранением хорошей производительности при обычной оптимизации запросов с полным выводом, являются более сложными, чем простая замена hash или merge соединений на nested loops. Представляется разумным обрабатывать запросы с TOP непосредственно в корне плана, используя специальный код, разработанный для распознавания конкретных сценариев. Однако такой подход ограничил бы широкие возможности оптимизации плана в более общих случаях.
Предложение TOP может быть указано много раз в различных местах запроса: на самом внешнем уровне (как в примере); в подзапросе; или в общем табличном выражении - каждое из них может быть сколь-угодно сложным. Хинт запроса FAST `n` также может быть использован, чтобы сообщить оптимизатору предпочесть план, который быстро вернет первые `n` строк, не ограничивая при этом общее число возвращаемых строк, как это имеет место в случае с TOP. Наконец, примите во внимание, что логическое полусоединение - semi-join - (например, для подзапроса, вводимого EXISTS) тоже в теме: оно должно быть оптимизировано для быстрого нахождения первой совпадающей строки.
Оптимизатор запросов SQL Server обеспечивает способ удовлетворить всем этим требованиям введением концепции `row goal` (назначение строк), которая просто устанавливает целевое число строк в конкретной точке плана.
Существенное различие возникает, когда оптимизатор решает, какой из планов-кандидатов является "лучшим". Обычные процедуры определяют стоимость итераторов и делают оценки числа строк на основе запроса, отправленного на выполнение. В нашем примере это приводит к плану, использующему hash join, при котором таблица Product выбирается в качестве build input.
Обычная оценка числа строк и селективности начинается на листовом уровне плана (например, index scan) и движется вверх по плану, изменяя оценки статистики (частоты и гистограммы) и кардинального числа по мере прохождения итераторов. Некоторые итераторы (типа Filter) имеют простое влияние на статистику и число строк, в то время как другие (например, соединения, объединения) могут потребовать более сложных вычислений и настроек гистограмм. Если присутствует row goal, оптимизатор начинает перемещаться вниз по плану (от row goal к листьям плана), изменяя стоимость итераторов и оценки числа строк, приводя их в соответствие. Для пояснения давайте выполним наш тестовый запрос снова, только теперь зададим TOP(50):
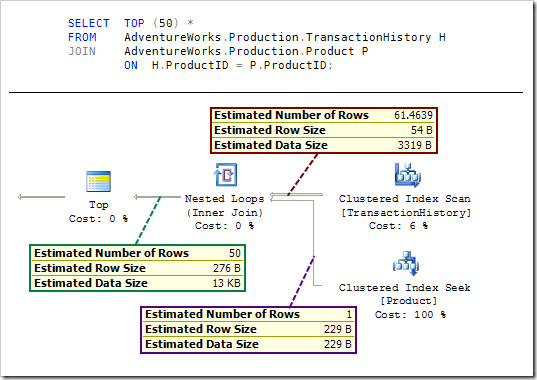
Двигаясь вниз по плану от итератора TOP замечаем, что оценка числа строк равна 50, как это требуется row goal. Оценка числа строк от каждого выполнения Index Seek равна 1 (поскольку столбец ProductID является ключом). Оценка кардинального числа другого входного потока соединения более интересна и требует дополнительного объяснения...
Еще один запрос, демонстрирующий тот же самый запрос, но без row goal:
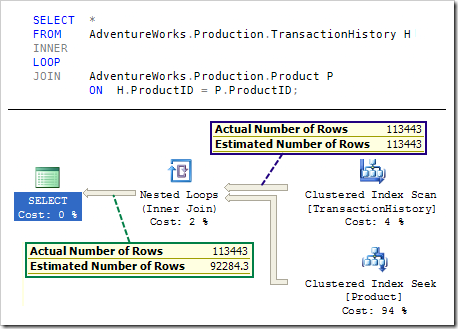
Обычная оценка числа строк (без row goal) дает 113443 строк для таблицы TransactionHistory, которая при соединении с таблицей Product дает 92284 строк. Оставляя в стороне ошибочность этих вычислений (которые игнорируют связь PK-FK между этими двумя таблицами), видим, что 113443/92284.3 = 1.22928 (вычисление использует плавающую арифметику для скорости). Этот коэффициент используется при расчетах row goal в обратном движении от итератора nested loops join. Выходное значение равно 50 (row goal), поэтому внешний вход в loop join оценивается как 50*1.22928 = 61.46400 строк. Это согласуется с оценкой числа строк в плане row goal и иллюстрирует природу обратных действий при оценке числа строк row goal. Возможны ошибки в оценке кардинального числа при получении новой оценки, которая превышает общее число строк в источнике и может считаться оценкой сверху числа строк в этом случае.
Подобные вычисления применяются к внутренней части loops join, однако отчет несколько отличается. В плане с row-goal, число строк inner input оценивается как 1, но предполагаемое число выполнений модифицируется row goal:
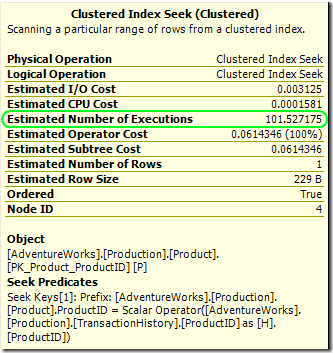
Отметим также, что оценки для стоимости CPU И I/O не проводились; они показывают такую стоимость на выполнение, как будто row goal не принималось в расчет. Предполагаемая стоимость оператора проводится с учетом row goal; это значение используется при вычислении стоимости поддерева. Разницу проще увидеть на внешнем входе:
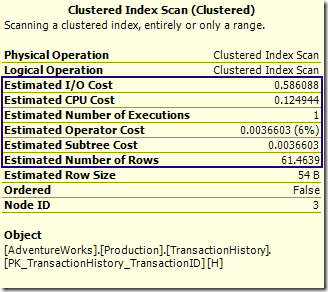
Предполагаемые стоимости I/O и CPU соответствуют стоимости возвращения всех строк. Оценки для "operator" и "sub-tree" модифицируются с учетом row goal. Эта особенность планов с row goal часто вызывает недоумение, однако теперь на вопрос, почему стоимость оператора значительно меньше суммы двух его слагаемых, у вас есть ответ! Стоимость оператора и поддерева используются для определения лучшего плана среди кандидатов. Посредством проведения этих простых модификаций применения row goal гарантируется, что построенный план отражает требование на ограничение числа строк.
Столкнувшись с казалось бы противоречивыми требованиями к оптимизации полных запросов и ранним ограничением на основе заданного числа строк, команда оптимизации запросов SQL Server нашла элегантное решение. Запросы, которые используют row goal (TOP, FAST N, EXISTS и т.д.), получают выгоду от всех преобразований и оптимизационных трюков со стороны SQL Server, производящему по-прежнему план на основе стоимости.
Иллюстрация сказанного: наш тестовый запрос выбирал loops join вплоть до TOP(97). При задании TOP(98) оптимизатор выбирает hash join на основе стоимости. (Точная граница может различаться на различных версиях продукта, и зависит от статистики).
Оптимизатор выбирает для выполнения логического соединения физический итератор Hash Match, что подтверждается оценкой стоимости плана приблизительно в 1,4 единиц. Принудительно заставляя выбрать альтернативное физическое соединение при помощи хинта запроса, мы увидим, что план на основе merge join имеет оценку стоимости под 10, а nested loops join получает оценку свыше 18 единиц. Все эти оценки стоимости опираются на предположение, что нужны все строки.
Hash Match
Как подробно описано в предыдущей статье , итератор Hash Match начинает с получения всех строк build input (таблица Product) для того, чтобы построить хэш-таблицу. Это делает Hash Match самоблокирующим итератором: он может начать производить выходные строки только тогда, когда фаза построения завершена. Если нам нужно быстро получить несколько первых строк запроса, этот тип соединения может оказаться не оптимальным.
Merge
Насколько быстро merge join начинает выдавать строки зависит от того, нуждается ли какой-либо из его входных потоков в явной сортировке. Если merge может получить упорядоченные строки обоих входных потоков из индекса или предшествующей операции без сортировки, он может направить строки в родительский узел без стартовой задержки.
Итератор сортировки в плане запроса всегда является блокирующей операцией, поскольку мы не можем знать, какая строка будет первой в отсортированном порядке без проверки их всех. В запросе из примера строки из таблицы истории требуют явной сортировки, поэтому merge join не будет хорошим выбором для быстрого получения первых строк.
Наш третий вариант операции соединения - nested loops - является обычно конвейерным итератором. Это означает отсутствие стартовой задержки, и первые совпадающие строки возвращаются быстро. К сожалению, он также имеет наивысшую предварительную построчную стоимость среди трех физических операций соединения.
Итератор nested loops выполняет свой внутренний (нижний) вход один раз для каждой строки, производимой его внешним (верхним) входом, что делает общую стоимость пропорциональной произведению числа строк, полученных из дочерних входных потоков. Напротив, стратегии hash и merge соединений сканируют каждый из входов один раз, что дает оценку стоимости пропорциональной сумме числа строк входных потоков.
Предложение TOP
Получение нескольких первых строк, производимых запросом, является задачей, легко решаемой на уровне автора запроса: просто добавить предложение TOP. Предположим, что нас интересует только одна строка из результатов запроса:
SELECT TOP (1) *
FROM AdventureWorks.Production.TransactionHistory H
JOIN AdventureWorks.Production.Product P
ON H.ProductID = P.ProductID;
Исходный запрос возвращает 113443 строк. Данный запрос возвращает только одну, и делает это очень быстро. Поскольку это очевидно, вы можете так и думать, однако все не то, чем кажется.
Небольшое отклонение относительно TOP и детерминированных результатов
Прежде чем я углублюсь в этот вопрос, замечу, что вышеприведенный запрос с TOP(1) содержит "баг": в нем отсутствует предложение ORDER BY, отвечающее за то, какая строка будет "верхней". В принципе, производимая этим запросом строка может быть выбрана случайным образом. На практике же результат зависит от плана запроса и деталей внутренней реализации в SQL Server. Поскольку каждая из этих вещей может измениться в любой момент, вы должны почти всегда указывать детерминированное предложение ORDER BY при использовании TOP.
Если вы задумались о том, что может быть недетерминированным в ORDER BY, рассмотрите что может случиться, если добавить в запрос "ORDER BY P.ProductID". Сложность возникает, поскольку ProductID не является уникальным для каждой строки результирующего набора (таблица истории транзакций может содержать множество строк для каждого продукта). В качестве конкретного примера предположим, что продукт #1 является наименьшим ProductID, и есть 75 записей в исторической таблице для этого продукта. Эти 75 записей сортируются равноправно по ProductID, тогда какая запись будет возвращена операцией TOP(1)?
Есть два метода сделать операцию детерминированной. Первый, мы можем переписать ORDER BY для включения в него комбинации столбцов, которые формируют уникальный ключ для множества выводимых строк; добавление ID транзакции из исторической таблицы позволяет этого добиться. Второй, мы можем добавить WITH TIES в спецификацию TOP, хотя это произведет более одной строки в случае дубликатов.
Я опустил ORDER BY в нашем простом примере, поскольку я действительно не представляю, какую строку мы получим, и мне хочется избежать изменения семантики оригинального запроса, чтобы продемонстрировать этот момент.
План TOP(1)
План запрос с TOP(1) выглядит следующим образом:
Этот план значительно отличается от оригинального плана запроса, который применял hash join. Понятно, что когда мы добавили предложение TOP в запрос, оптимизатор сделал больше простого добавления итератора TOP в корень плана, который он строит обычно. С целью сравнения, приведу план запроса, построенный для запроса с TOP(1), для которого навязан hash join.
Важно заметить, что входной поток построения в hash join должен получить все 504 строки таблицы Product, прежде чем сможет стартовать процесс зондирования хэш-таблицы в поисках совпадений со строками из таблицы TransactionHistory. Подобно всем операциям с хэшем, hash join также требует выделения памяти, прежде чем план сможет начать выполнение. Предполагаемая стоимость плана hash join равна 0.1, в то время как план loops join, выбранный оптимизатором имеет оценку 0.01 единиц.
ROW GOAL
Проблемы, стоящие перед построителем оптимизированного плана для запросов с ограничением на вывод строк и сохранением хорошей производительности при обычной оптимизации запросов с полным выводом, являются более сложными, чем простая замена hash или merge соединений на nested loops. Представляется разумным обрабатывать запросы с TOP непосредственно в корне плана, используя специальный код, разработанный для распознавания конкретных сценариев. Однако такой подход ограничил бы широкие возможности оптимизации плана в более общих случаях.
Предложение TOP может быть указано много раз в различных местах запроса: на самом внешнем уровне (как в примере); в подзапросе; или в общем табличном выражении - каждое из них может быть сколь-угодно сложным. Хинт запроса FAST `n` также может быть использован, чтобы сообщить оптимизатору предпочесть план, который быстро вернет первые `n` строк, не ограничивая при этом общее число возвращаемых строк, как это имеет место в случае с TOP. Наконец, примите во внимание, что логическое полусоединение - semi-join - (например, для подзапроса, вводимого EXISTS) тоже в теме: оно должно быть оптимизировано для быстрого нахождения первой совпадающей строки.
Оптимизатор запросов SQL Server обеспечивает способ удовлетворить всем этим требованиям введением концепции `row goal` (назначение строк), которая просто устанавливает целевое число строк в конкретной точке плана.
Стоимость и кардинальное число
Существенное различие возникает, когда оптимизатор решает, какой из планов-кандидатов является "лучшим". Обычные процедуры определяют стоимость итераторов и делают оценки числа строк на основе запроса, отправленного на выполнение. В нашем примере это приводит к плану, использующему hash join, при котором таблица Product выбирается в качестве build input.
Обычная оценка числа строк и селективности начинается на листовом уровне плана (например, index scan) и движется вверх по плану, изменяя оценки статистики (частоты и гистограммы) и кардинального числа по мере прохождения итераторов. Некоторые итераторы (типа Filter) имеют простое влияние на статистику и число строк, в то время как другие (например, соединения, объединения) могут потребовать более сложных вычислений и настроек гистограмм. Если присутствует row goal, оптимизатор начинает перемещаться вниз по плану (от row goal к листьям плана), изменяя стоимость итераторов и оценки числа строк, приводя их в соответствие. Для пояснения давайте выполним наш тестовый запрос снова, только теперь зададим TOP(50):
Двигаясь вниз по плану от итератора TOP замечаем, что оценка числа строк равна 50, как это требуется row goal. Оценка числа строк от каждого выполнения Index Seek равна 1 (поскольку столбец ProductID является ключом). Оценка кардинального числа другого входного потока соединения более интересна и требует дополнительного объяснения...
Обратная оценка числа строк
Еще один запрос, демонстрирующий тот же самый запрос, но без row goal:
Обычная оценка числа строк (без row goal) дает 113443 строк для таблицы TransactionHistory, которая при соединении с таблицей Product дает 92284 строк. Оставляя в стороне ошибочность этих вычислений (которые игнорируют связь PK-FK между этими двумя таблицами), видим, что 113443/92284.3 = 1.22928 (вычисление использует плавающую арифметику для скорости). Этот коэффициент используется при расчетах row goal в обратном движении от итератора nested loops join. Выходное значение равно 50 (row goal), поэтому внешний вход в loop join оценивается как 50*1.22928 = 61.46400 строк. Это согласуется с оценкой числа строк в плане row goal и иллюстрирует природу обратных действий при оценке числа строк row goal. Возможны ошибки в оценке кардинального числа при получении новой оценки, которая превышает общее число строк в источнике и может считаться оценкой сверху числа строк в этом случае.
Интересный побочный эффект
Подобные вычисления применяются к внутренней части loops join, однако отчет несколько отличается. В плане с row-goal, число строк inner input оценивается как 1, но предполагаемое число выполнений модифицируется row goal:
Отметим также, что оценки для стоимости CPU И I/O не проводились; они показывают такую стоимость на выполнение, как будто row goal не принималось в расчет. Предполагаемая стоимость оператора проводится с учетом row goal; это значение используется при вычислении стоимости поддерева. Разницу проще увидеть на внешнем входе:
Предполагаемые стоимости I/O и CPU соответствуют стоимости возвращения всех строк. Оценки для "operator" и "sub-tree" модифицируются с учетом row goal. Эта особенность планов с row goal часто вызывает недоумение, однако теперь на вопрос, почему стоимость оператора значительно меньше суммы двух его слагаемых, у вас есть ответ! Стоимость оператора и поддерева используются для определения лучшего плана среди кандидатов. Посредством проведения этих простых модификаций применения row goal гарантируется, что построенный план отражает требование на ограничение числа строк.
Заключительные мысли
Столкнувшись с казалось бы противоречивыми требованиями к оптимизации полных запросов и ранним ограничением на основе заданного числа строк, команда оптимизации запросов SQL Server нашла элегантное решение. Запросы, которые используют row goal (TOP, FAST N, EXISTS и т.д.), получают выгоду от всех преобразований и оптимизационных трюков со стороны SQL Server, производящему по-прежнему план на основе стоимости.
Иллюстрация сказанного: наш тестовый запрос выбирал loops join вплоть до TOP(97). При задании TOP(98) оптимизатор выбирает hash join на основе стоимости. (Точная граница может различаться на различных версиях продукта, и зависит от статистики).
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой