
Практический анализ данных с Pandas
Пересказ статьи Tirendaz AI. Practical Data Analysis with Pandas
Реально существующие данные - "грязные". Они требуют предварительной очистки, чтобы осуществлять их анализ. Pandas является наиболее часто используемой библиотекой Python для очистки данных. В то же время Pandas является очень мощной библиотекой для анализа данных. В этой статье я покажу вам, как анализировать данные с помощью Pandas на реальном наборе данных.
Загрузка набора данных
Сначала давайте импортируем Pandas.

Затем импортируем набор данных, используя метод ad_csv.

Понимание набора данных
Вы можете загрузить этот набор данных отсюда. Это набор данных о транспортных средствах, задержанных на дорогах полицией Сан Диего, Калифорния. Набор данных содержит такие данные, как время задержания, возраст водителя, причину задержания и статус ареста. Давайте посмотрим на первые 5 строк этого набора данных.
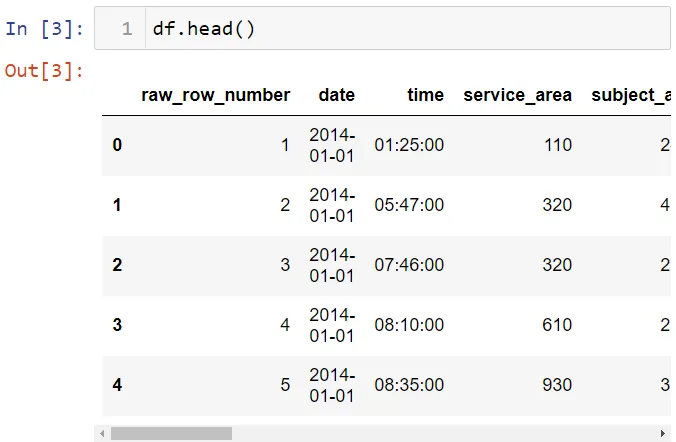
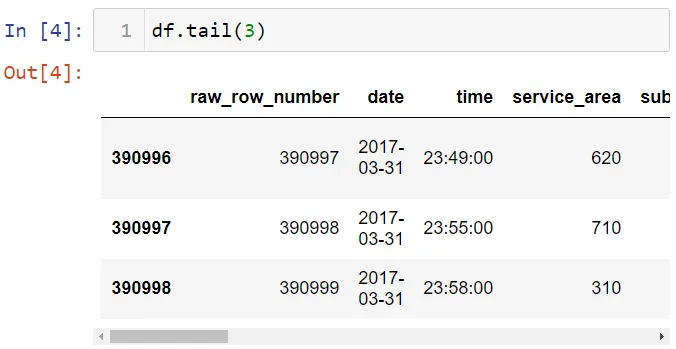
А теперь последние 3 строки:
А вот форма набора данных:

Посмотрим типы данных столбцов в наборе данных:

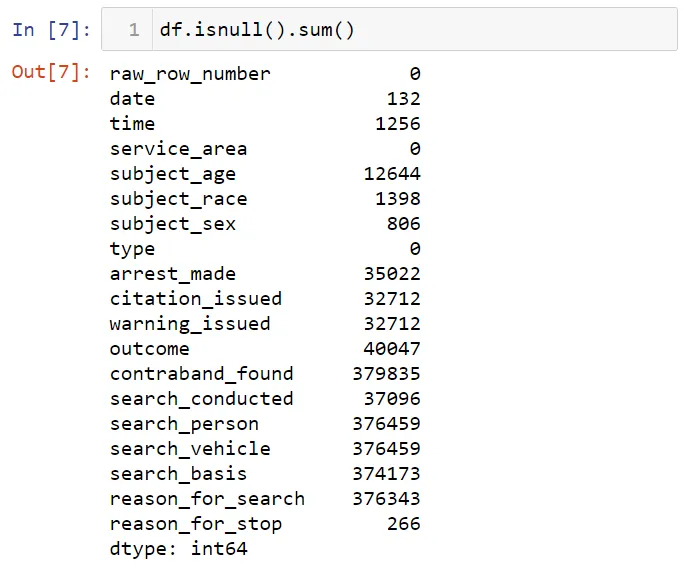
Вы можете использовать метод isnull, чтобы обнаружить отсутствующие в наборе данных значения. Этот метод возвращает логическое значение. False означает, что нет отсутствующих данные, а True - их наличие. Давайте оценим общее число отсутствующих данных в каждом столбце:
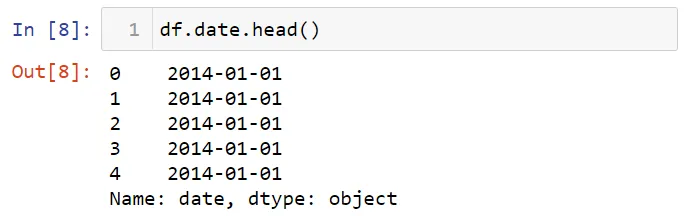
Имеется три важных структуры данных в Pandas: ряд, фрейм данных и индекс. Набор данных представляет собой фрейм данных. Каждый столбец фрейма данных является рядом. Вот один столбец в этом фрейме данных:
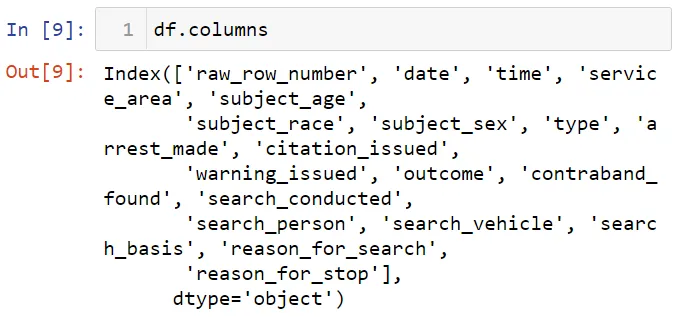
Вы можете увидеть столбцы в наборе данных с помощью атрибута columns:
Выборка с помощью Pandas
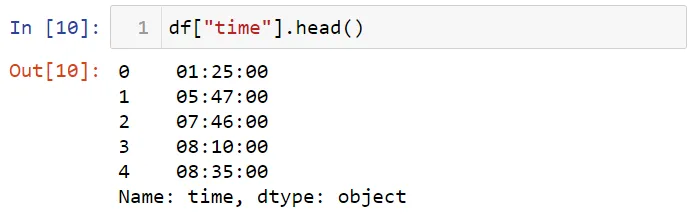
Вы можете выбрать столбец в наборе данных. Например, давайте выберем столбец time:
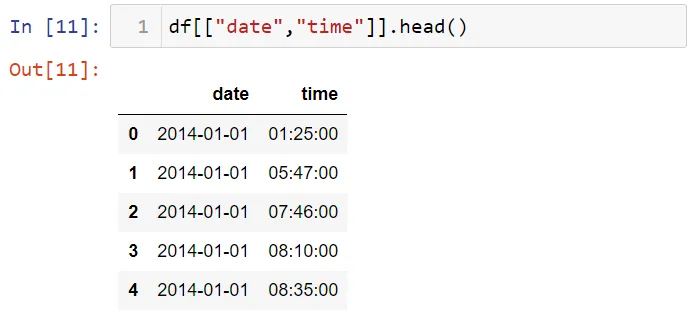
Вы можете использовать двойные квадратные скобки для выбора более одного столбца:
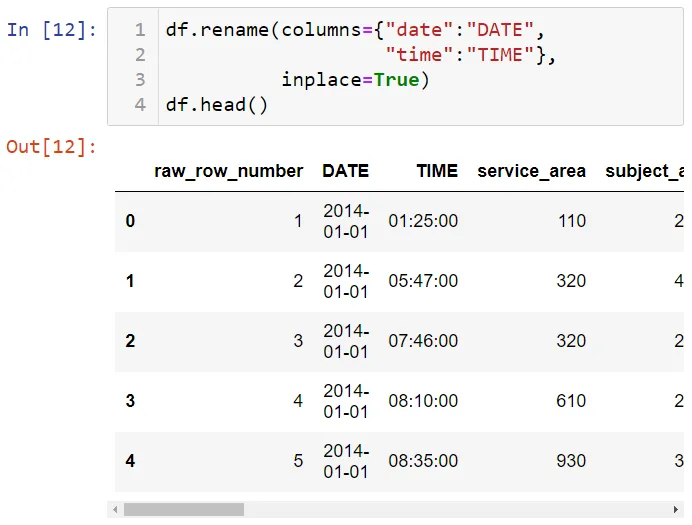
Вы можете изменить имена столбцов, используя метод rename:
Вы можете также использовать методы loc или iloc для выборки столбцов или строк. Вам нужно использовать имена строк и столбцов в методе iloc, в то время как для метода loc требуются индексы строки и столбца. Например, давайте получим первую строку:
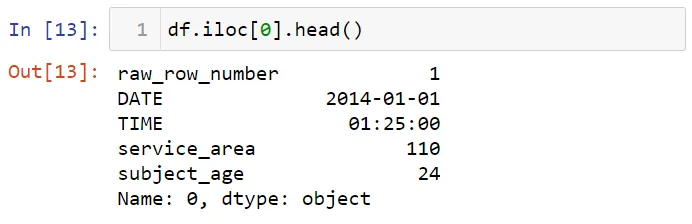
Теперь получим значение первой строки и столбца:

Вы можете выбрать больше одного столбца:
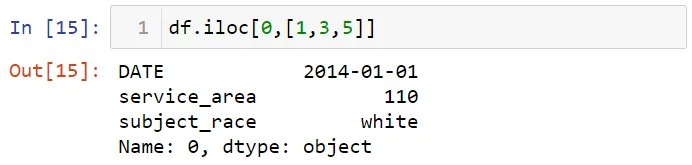
Можно сделать срез строк:
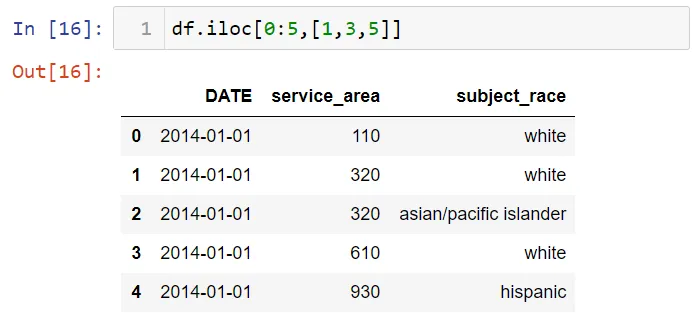
Можно делать срезы как строк, так и столбцов:
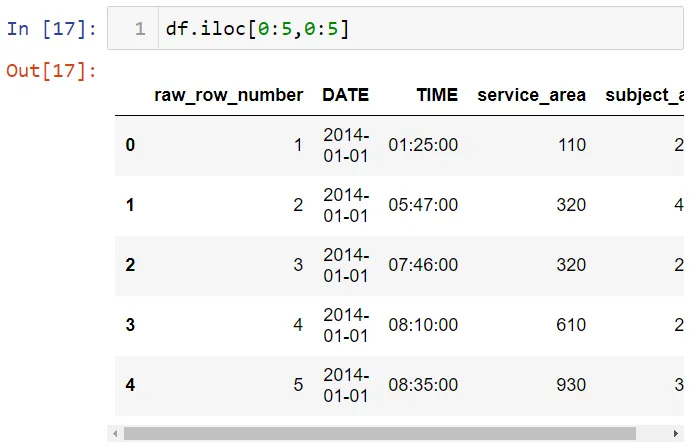
В методе loc требуется использовать имя. Например:
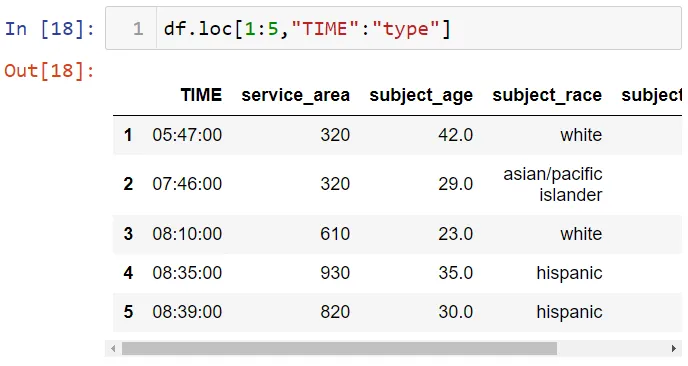
Срезы столбцов также можно делать:
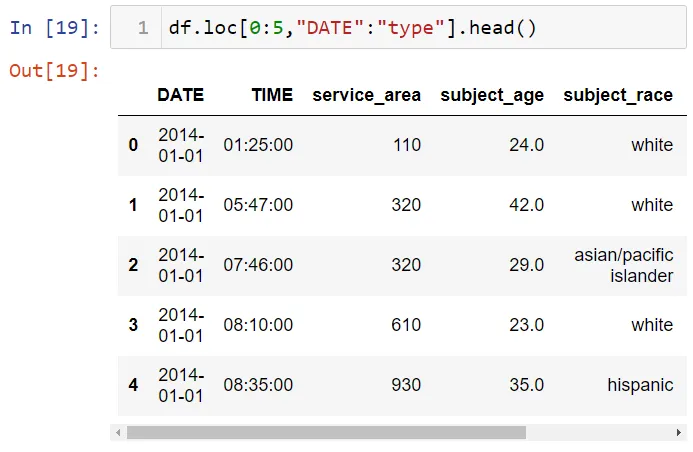
Обработка отсутствующих данных в Pandas
Вы можете использовать метод dropna для работы с отсутствующими данными. Давайте сначала опять взглянем на форму набора данных.

Вы можете использовать how = "all", чтобы удалить все столбцы, которые содержат только отсутствующие значения (не содержат значений вообще),

Можно использовать how = "any" для удаления всех столбцов, которые имеют отсутствующие значения,

Простой анализ с помощью Pandas
Я собираюсь выяснить, кто больше, мужчины или женщины, совершили нарушений. Сначала давайте посмотрим на причины и число задержаний транспортных средств.
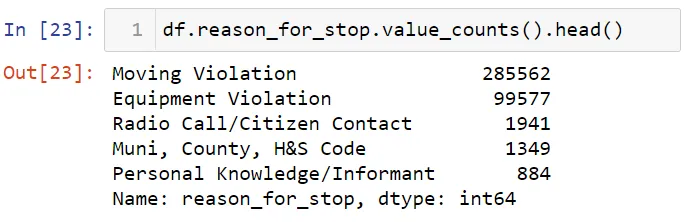
Главным образом транспортные средства останавливались за превышение скорости (speed violations). Давайте посмотрим число мужчин и женщин, которые были остановлены по этой причине. Сначала я собираюсь выполнить фильтрацию по значению нарушения правил движения (moving violation). Затем я выберу столбец subject_sex (пол) и использую функцию value_counts для получения общего числа.
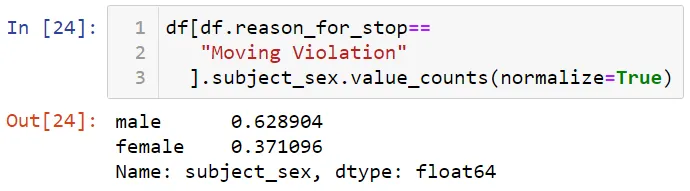
Здесь используется normalized = True для получения процентного отношения мужчин и женщин.
Давайте посмотрим причины задержания женщин в процентном отношении. Для этого я выполню фильтрацию по значению female в столбце пола:
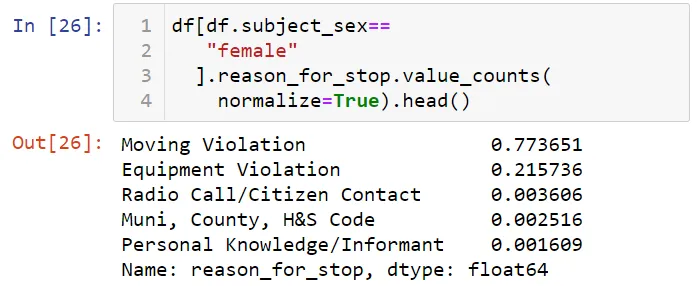
77 процентов женщин были остановлены за нарушение правил дорожного движения. Теперь давайте посмотрим причины задержания с помощью метода groupby.
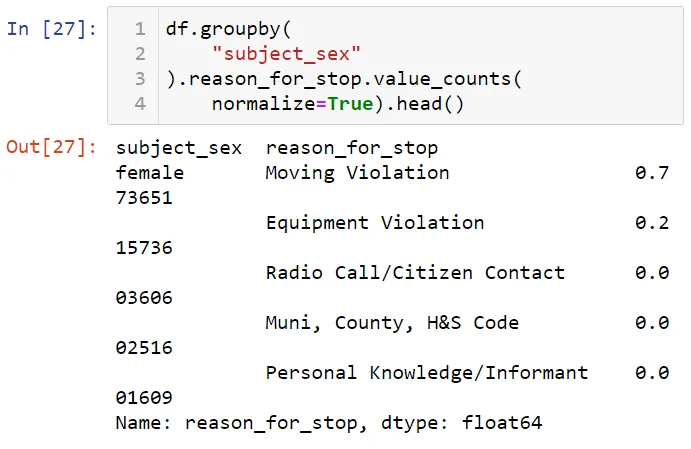
Давайте преобразуем эти данные в табличную форму:
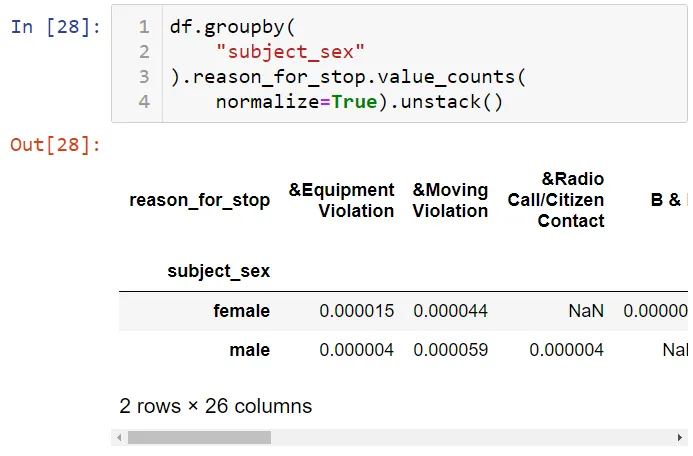
Теперь рассмотрим зависимость пола на ситуацию при аресте. Сначала определим число арестов.
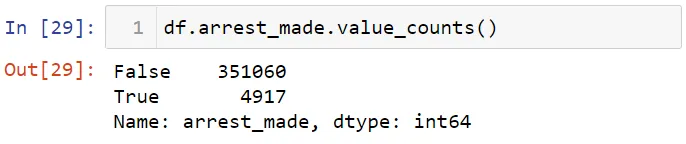
Затем проверим процентное отношение числа арестов.
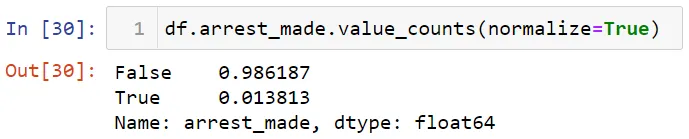
Теперь процентное соотношение арестов по полу.
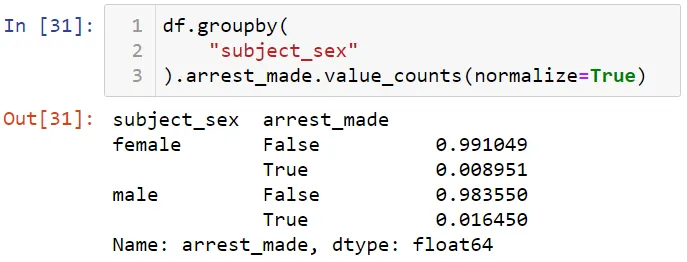
Мужчины арестовываются вдвое чаще женщин. Посмотрим на аресты по расе и полу.
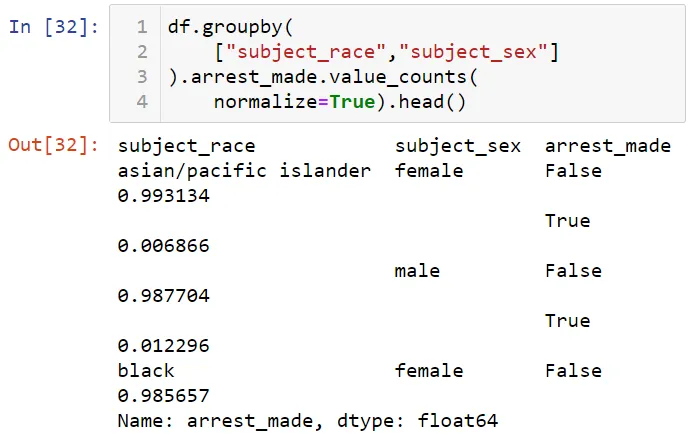
Отметим, что черные мужчины и женщины арестовывались чаще других. Давайте выясним, в каком году число задержаний было меньше. Для этого выведем первые 4 значения по годам для столбца date.
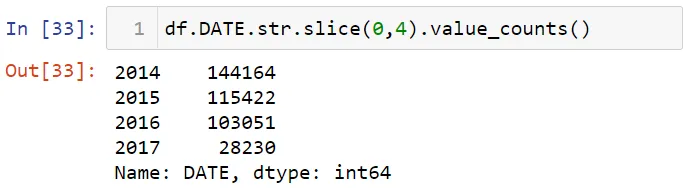
Скомбинируем переменные даты и времени в структуру дата-время. Сначала я соберу вместе переменные даты и времени.

Теперь преобразуем эту переменную даты в структуру даты-времени Pandas и добавим эту переменную в набор данных:
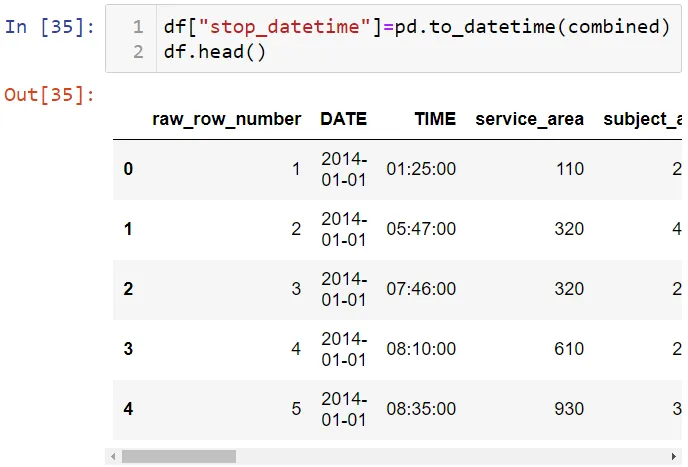
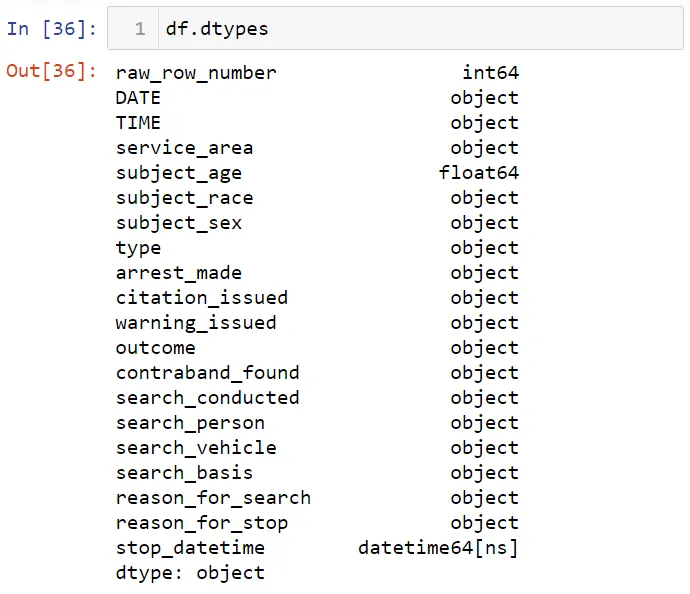
Посмотрим на структуру переменных в наборе данных:
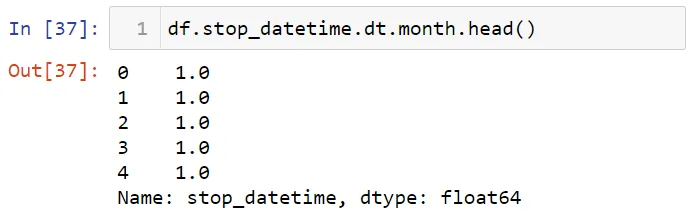
Круто. Мы создали столбец stop_datetime. А теперь, для примера, месяцы:
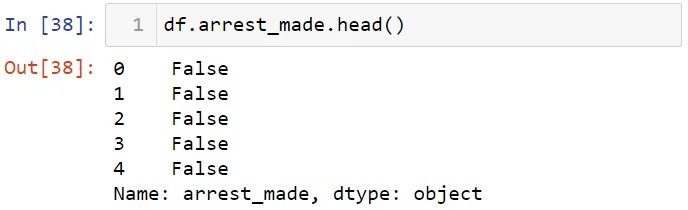
Проверим изменение ситуации по арестам в течение дня. Сначала давайте взглянем на столбец arrest_made:
Давайте преобразуем этот столбец к структуре логических данных.

Давайте посмотрим число арестов.
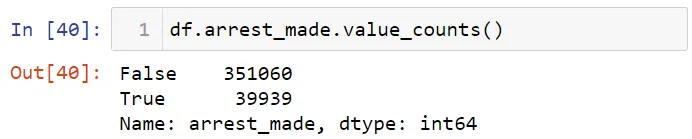
А теперь выведем процентное отношение арестов.

Примерно 10 процентов нарушителей было арестовано. Теперь посмотрим среднее число арестов в день.
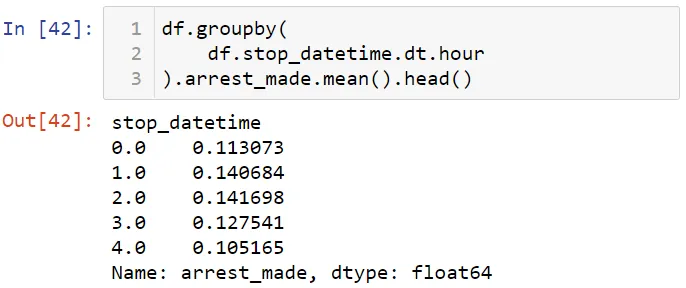
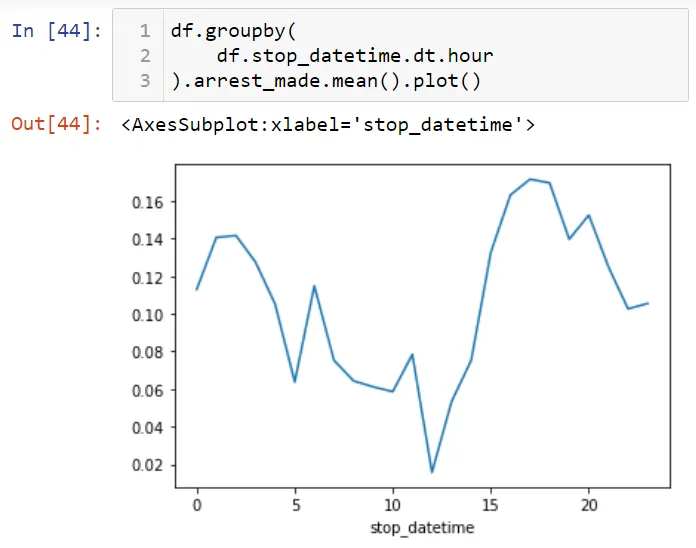
Давайте отобразим эти данные на графике. Чтобы увидеть график, я буду использовать встроенную команду % Matplotlib.

Давайте нарисуем график:
Теперь посмотрим часы задержания.
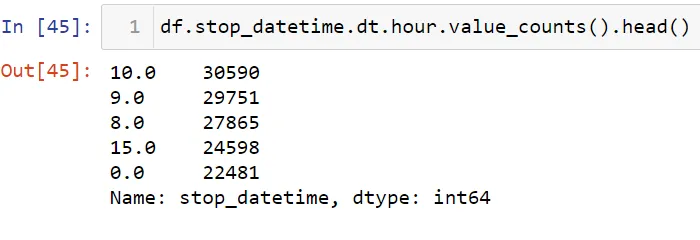
Отсортируем эти данные:
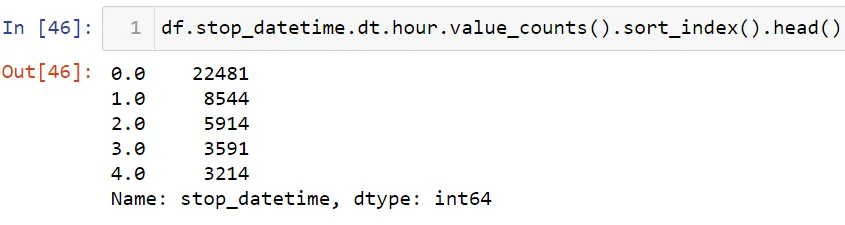
Давайте построим график.
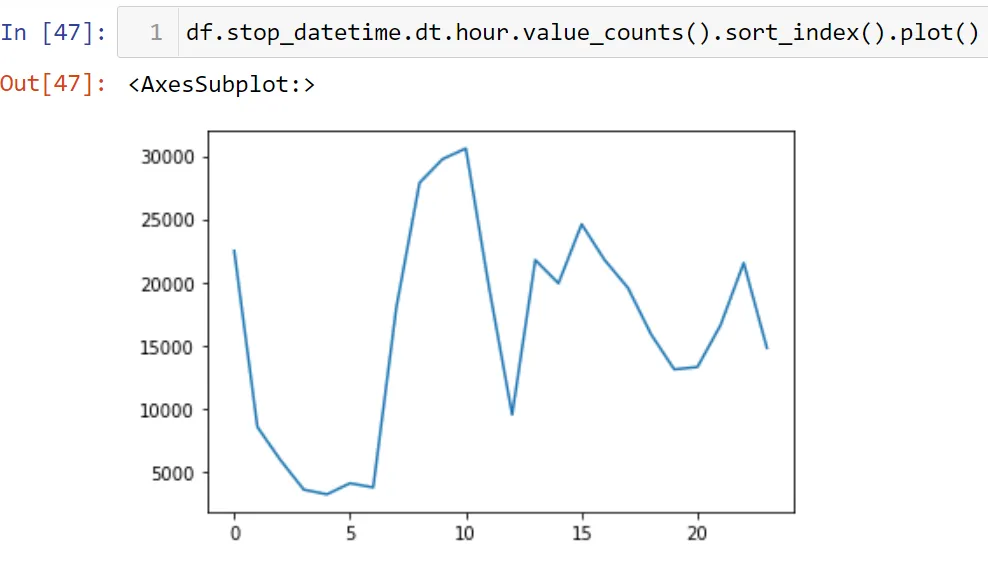
Я могу сказать, что больше всего задержаний совершается в 10 часов утра.
Ссылки по теме
1. Python для анализа и визуализации данных
2. От SQL к Pandas: руководство по переходу
3. Команды Pandas, которые я часто использую для анализа данных
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой