
Python для анализа и визуализации данных
Пересказ статьи Muhammad Sa'duddin. Python for Data Analysis and Data Visualization
Ранее мы обсуждали анализ данных с помощью SQL. Теперь я выполню анализ данных, используя Python. Но прежде, если вы хотите прочитать мою статью об анализе с помощью SQL, вот ссылка.
Для тех, кто не в курсе, скажу, что Python является языком программирования, который может использоваться в web и разработке программного обеспечения, науке о данных и анализе данных. Python классифицируется как высокоуровневый язык программирования, который довольно легко изучить и который весьма популярен в настоящее время.
В данном случае я проведу анализ набора данных по спросу на бронирование отелей и задам некоторые бизнес-вопросы. Сначала мы импортируем библиотеку с помощью следующего синтаксиса:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import re
sns.set()Затем импортируем набор данных, используемый для анализа:
df_hotels = pd.read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-02-11/hotels.csv')В этом наборе данных нет столбца с уникальным идентификатором, так что мы для этого упражнения предположим, что каждая строка является уникальной, обеспечивая столбец id в качестве уникального идентификатора, используя следующий синтаксис:
df_hotels = df_hotels.reset_index().rename(columns={'index':'id'})Теперь давайте начнем анализ данных с использованием Python.
Вопрос 1
Какой тип данных используется в наборе данных? Каково число и процентное отношение NULL-значений, а также число уникальных значений в наборе данных?
Решение 1
Мы можем проверить тип данных, число и процентное отношение NULL-значений, число уникальных значений, используя следующий синтаксис:
def check_values(df):
data = []
for col in df.columns:
data.append([col, \
df[col].dtype, \
df[col].isna().sum(), \
round(100*(df[col].isna().sum()/len(df)),2), \
df[col].nunique()
])
return pd.DataFrame(columns=['dataFeatures', 'dataType', 'null', 'nullPct', 'unique'],data=data)
check_values(df_hotels)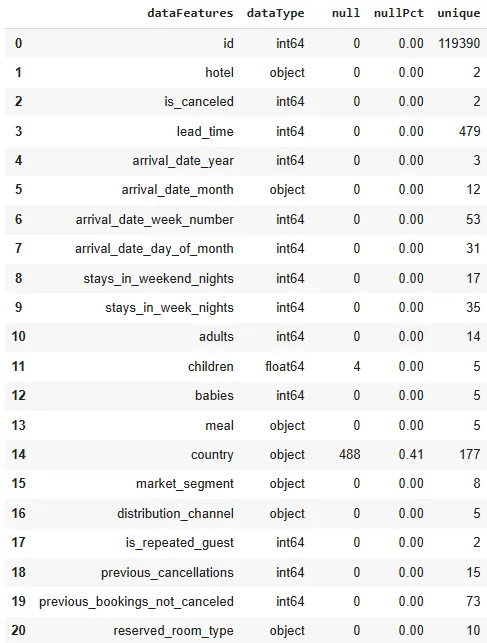
Вопрос 2
Сколько посетителей отменили бронь, а сколько нет? И по этому количеству сделать вывод о доле каждого!
Ответ 2
Вот синтаксис для нахождения посетителей, кто отменил бронь. 0 означает, что посетитель не отменял бронь, а 1 означает отмену брони посетителем.
df_hotels.is_canceled.value_counts()
Видно, что 44224 посетителей отменили бронь. Соотношение тех, кто отменил бронь и кто не отменял, представлено ниже.
sns.countplot(data=df_hotels, x='is_canceled')
plt.title('Cancelled')
plt.show()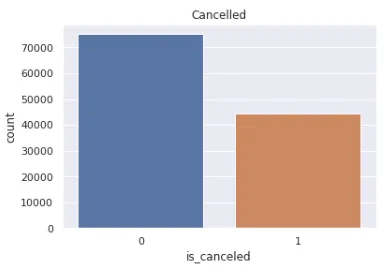
Процентное отношение тех, кто отменял бронь и кто не отменял:
df_hotels.is_canceled.value_counts(normalize=True)*100
Как видно, 37,04% посетителей отменило бронь.
Вопрос 3
A. Каково процентное отношение отмененной брони для "City Hotel"?
B. Каково процентное отношение отмененной брони для "Resort Hotels"?
Решение 3
Процентное отношение посетителей, кто отменил бронь в "City Hotel", составляет 41,72%, а для "Resort Hotels" этот процент составляет 27,76%, что можно увидеть в результатах ниже.
# Синтаксис для А
df_hotels[df_hotels.hotel=='City Hotel'].is_canceled.value_counts(normalize=True)
print("Percentage =",len(df_hotels[(df_hotels.hotel=='City Hotel')&(df_hotels.is_canceled==1)]) 100 / len(df_hotels[(df_hotels.hotel=='City Hotel')]),"%")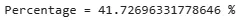
# Синтаксис для В
df_hotels[df_hotels.hotel=='Resort Hotel'].is_canceled.value_counts(normalize=True)
print("Percentage =",len(df_hotels[(df_hotels.hotel=='Resort Hotel')&(df_hotels.is_canceled==1)]) 100 / len(df_hotels[(df_hotels.hotel=='Resort Hotel')]),"%")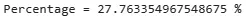
Вопрос 4
Выполнить фильтрацию таким образом, чтобы выводились данные для посетителей, которые не отменяли бронь, и сохранить результат в переменной df_checkout.
Решение 4
Ниже приведен синтаксис и результаты фильтрации для отображения только тех посетителей, которые не отменяли бронь.
df_hotels[df_hotels.is_canceled==0]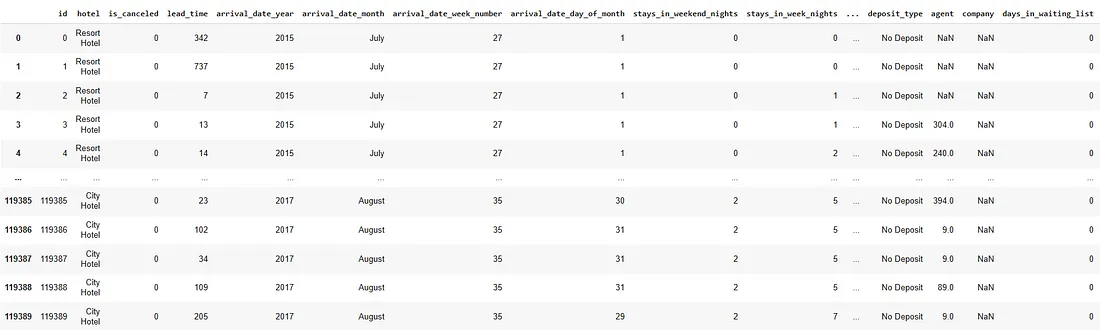
Затем сохраним результат в переменной df_checkout, используя следующий синтаксис:
df_checkout = df_hotels[df_hotels.is_canceled==0]Вопрос 5
А. Вывести число бронирований на месяц прибытия для отелей каждого типа.
В. В каком месяце было наибольшее число бронирований по каждому типу отелей? Одинакова ли тенденция для обоих типов отелей?
С. Сделайте подобное пункту В, но с названием месяца, который бы отображался в номер месяца.
Решение 5
Число бронирований по месяцам для каждого типа отелей показано ниже.
summary_tiap_hotel = df_checkout.groupby(['hotel','arrival_date_month']).size().reset_index()
summary_tiap_hotel.columns = ['hotel','arrival_date_month','jumlah_reservasi']
summary_tiap_hotel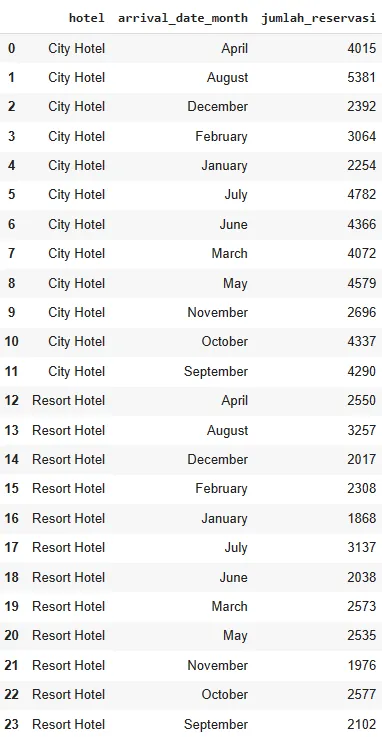
Наибольшее число бронирований для City Hotel и Resort Hotel наблюдается в августе. Эти данные можно увидеть ниже.
max_ch = summary_tiap_hotel[summary_tiap_hotel['hotel'] == 'City Hotel']['jumlah_reservasi'].max()
max_rh = summary_tiap_hotel[summary_tiap_hotel['hotel'] == 'Resort Hotel']['jumlah_reservasi'].max()
print('summary max reservasi City Hotel')
display(summary_tiap_hotel[summary_tiap_hotel['jumlah_reservasi'] == max_ch])
print('')
print('')
print('summary max reservasi Resort Hotel')
display(summary_tiap_hotel[summary_tiap_hotel['jumlah_reservasi'] == max_rh])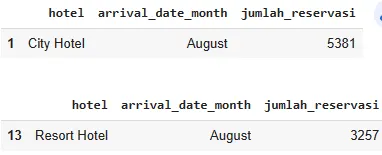
Теперь получим тренд для отелей каждого типа. Но прежде нам необходимо импортировать библиотеку calendar и создать новую переменную, чтобы можно было наблюдать тренды, с помощью следующего синтаксиса.
import calendar
month_dict = {month: index for index, month in enumerate(calendar.month_name) if month}
df_checkout['arrival_date_month_num'] = df_checkout['arrival_date_month'].map(month_dict)
df_checkout.groupby(['hotel','arrival_date_month_num']).size()
rf_df = df_checkout[df_checkout['hotel'] == "Resort Hotel"]
cf_df = df_checkout[df_checkout['hotel'] == "City Hotel"]Теперь давайте посмотрим тренд.
sns.lineplot(data = rf_df, x = 'arrival_date_month_num', y = 'id').set_title('Trend Resort Hotel Monthly')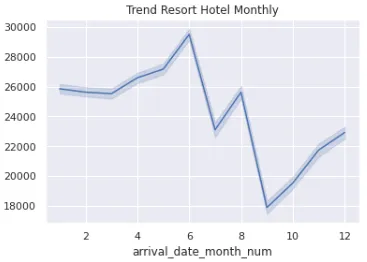
sns.lineplot(data = cf_df, x = 'arrival_date_month_num', y = 'id').set_title('Trend City Hotel Monthly')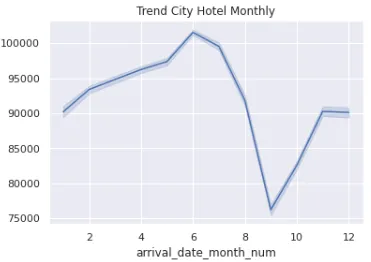
sns.countplot(data=df_checkout, x='arrival_date_month_num',hue='hotel')
plt.xlabel('bulan kedatangan')
plt.ylabel('jumlah reservasi')
plt.show()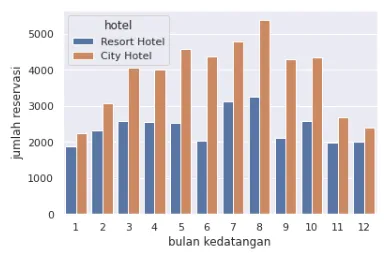
Вопрос 6
А. Создать новый столбец с именем arrival_date, который содержит полную информацию о годе, месяце и дате прибытия.
В. Изменить тип столбца на DateTime.
Решение 6
Синтаксис для создания нового столбца с именем arrival_date, который содержит полную информацию о годе, месяце и дате прибытия приведен ниже.
df_checkout['arrival_date'] = \
df_checkout['arrival_date_year'].astype('str') + '-' +\
df_checkout.arrival_date_month_num.astype('str').str.pad(2,fillchar='0') + '-' +\
df_checkout.arrival_date_day_of_month.astype('str').str.pad(2,fillchar='0')Тип данных столбца arrival_date:
df_checkout.arrival_date.dtype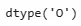
Теперь изменим тип данных столбца. Мы изменим тип данных столбца arrival_date на DateTime и проверим изменение с помощью следующего кода:
df_checkout['arrival_date'] = pd.to_datetime(df_checkout.arrival_date)
df_checkout['arrival_date']
Вопрос 7
Создать 2 фрейма данных, выводящих следующее:
1. Общее бронирование за день.
2. Среднее ежедневное бронирование за каждую неделю.
Решение 7
Фрейм данных общего ежедневного бронирования и его тренд представлены ниже.
df_reservation_perday = df_checkout.resample('D',on='arrival_date').size().reset_index().rename(columns={0:'total_reservation'})
df_reservation_perday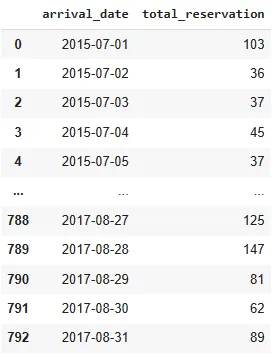
plt.figure(figsize=(10,4))
sns.lineplot(data=df_reservation_perday, x='arrival_date', y='total_reservation')
plt.title('Reservation per Day', fontsize='x-large')
plt.show()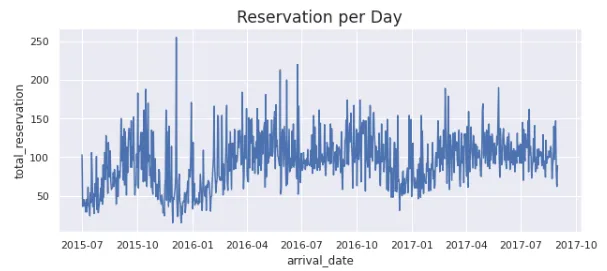
Фрейм данных для среднего ежедневного бронирования за каждую неделю и его тренд представлены ниже.
df_avg_reservation_perday = df_checkout.resample('D',on='arrival_date').size().reset_index().rename(columns={0:'total_reservation'}).\
resample('W',on='arrival_date')['total_reservation'].mean().reset_index()
df_avg_reservation_perday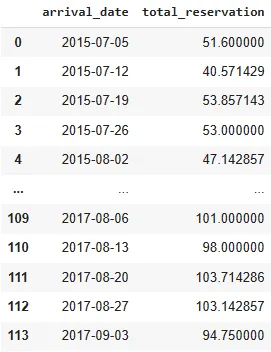
plt.figure(figsize=(10,4))
sns.lineplot(data=df_avg_reservation_perday, x='arrival_date', y='total_reservation')
plt.title('Average Reservation per Day', fontsize='x-large')
plt.show()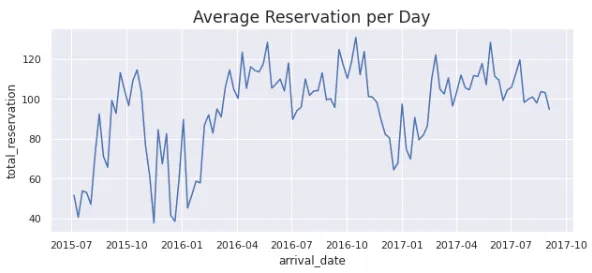
Вопрос 8
А. Каково среднее значение ADR (средняя цена номероночи) по типу отеля и типу заказчика (customer_type)?
В. Какой тип заказчика имеет наибольший ADR для каждого типа отеля?
Решение 8
Среднее значение ADR по типу отеля и типу заказчика можно увидеть ниже.
customer_summary = df_checkout.groupby(['hotel','customer_type'])['adr'].mean().reset_index()
customer_summary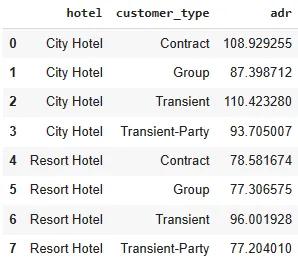
Наибольший ADR для каждого типа отеля имеет заказчик типа Transient. Это можно увидеть на результатах ниже.
max_chs = customer_summary[customer_summary['hotel'] == 'City Hotel']['adr'].max()
max_rhs = customer_summary[customer_summary['hotel'] == 'Resort Hotel']['adr'].max()
display(customer_summary[customer_summary['adr'] == max_chs])
print('')
print('')
display(customer_summary[customer_summary['adr'] == max_rhs])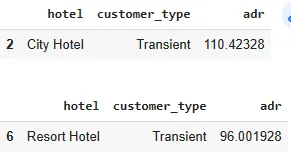
Вопрос 9
Вывести 10 стран с наибольшим числом бронирований!
Решение 9
Шаг 1
Импортируем df_country и чистим данные.
df_country = pd.read_csv('https://gist.githubusercontent.com/tadast/8827699/raw/f5cac3d42d16b78348610fc4ec301e9234f82821/countries_codes_and_coordinates.csv')
df_country['code'] = df_country['Alpha-3 code'].str.replace('"','').str.strip()Шаг 2
Выполняем слияние фреймов данных df_checkout и df_country. Используем поле 3-символьного кода, чтобы получить название страны.
df_merged = pd.merge(df_checkout[['id','country']],
df_country[['Country','code']],
left_on='country',
right_on='code',
indicator=True,
how='left')Шаг 3
Выводим 10 стран с наибольшим числом бронирования.
df_merged.Country.value_counts().head(10)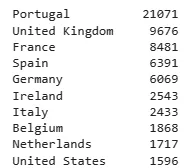
Шаг 4
Визуализация
df_merged.Country.value_counts().head(10).sort_values(ascending=True).plot.barh()
plt.show()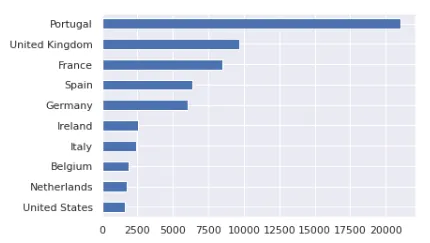
Вопрос 10
А. Сколько гостей проживает по каждому бронированию?
В. На основе этого набора данных определить максимальное число гостей. Вывести также строку данных бронирования с максимальным числом гостей.
Решение 10
Число гостей на каждое бронирование составляет 1,94 (округлено до 2).
Максимальное число гостей равно 12. Эти данные можно увидеть в строках mean и max в результатах ниже.
df_checkout['total_guest'] = df_checkout.adults + df_checkout.children + df_checkout.babies
df_checkout.total_guest.describe()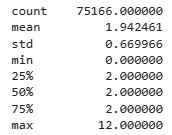
Строка данных бронирования, которая имеет максимальное число гостей, показана ниже.
df_checkout[df_checkout.total_guest==df_checkout.total_guest.max()].T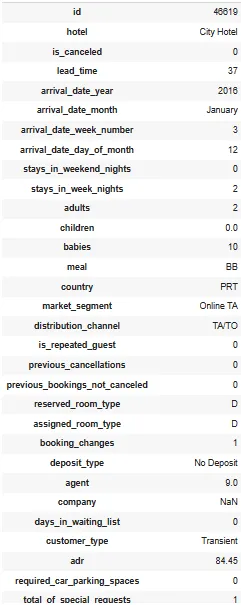
Ссылки по теме
1. Команды Pandas, которые я часто использую для анализа данных
2. Получение в Python данных из MySQL
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой