
Команды Pandas, которые я часто использую для анализа данных
Пересказ статьи Insufficient. Pandas Commands I Frequently Use to Analyze Data
Pandas является широко используемой библиотекой среди тех, кто занимается наукой о данных. Она позволяет манипулировать таблицей как мы того пожелаем. В этой статье я собираюсь поделиться с вами теми командами Pandas, которые я часто использую.
Здесь я буду в качестве примера использовать набор данных по статистике покемонов. Она не самая современная, но все еще используемая! В этой статье я буду называть dataframe сокращенно ‘df’.
Очевидно, что первым шагом является загрузка набора данных в Python, вы можете сделать это с помощью функции ‘read_csv’ из Pandas.
Теперь давайте посмотрим на этот набор данных!
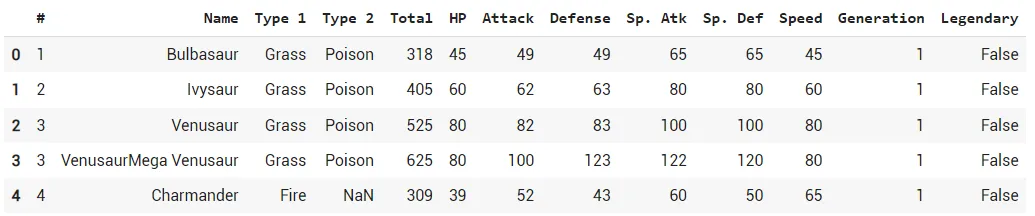
Первые 5 строк набора
Данные содержат 13 столбцов (за исключением индексного столбца) - 4 текстовых столбца и 7 числовых.
Теперь давайте пройдемся по некоторым командам Pandas, которые я часто использую.
Никому не нравятся отсутствующие данные. Есть много различных способов их обработки, но эти 2 наbболее простые. Но сначала давайте посмотрим, есть ли в нашем фрейме данных отсутствующие данные, с помощью следующей функции:
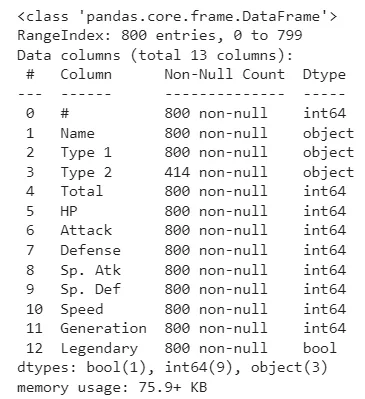
Из результатов видно, что в столбце ‘Type 2’ множество пропущенных данных! Чтобы разобраться с этой проблемой вы можете использовать либо fillna, либо dropna.
Команда fillna заполняет отсутствующие данные тем, что вы укажете.
Эта команда заполняет отсутствующие данные символом '-'. Посмотрим теперь на набор данных:
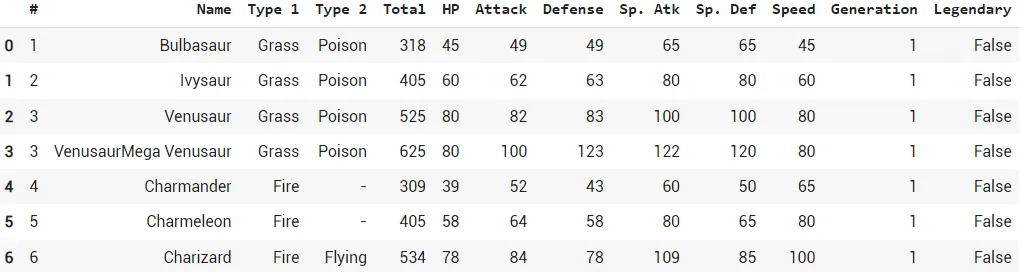
Результат выполнения fillna
Можно увидеть, что некоторые строки в столбце ‘Type 2’ теперь содержат ‘-’, потому что ранее они не содержали значения.
Другим способом обработки отсутствующих данных является команда dropna. Команда dropna удаляет все строки, которые включают отсутствующие значения.
Результат выполнения этой команды выглядит так:
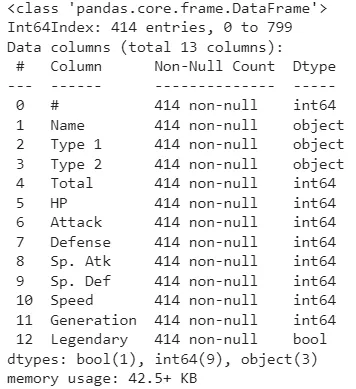
Результат выполнения команды dropna
Как видно, эта команда удаляет все строки с отсутствующими данными в столбце ‘Type 2’. Обратите внимание, что фрейм данных теперь содержит только 414 строк, а не исходные 800. Хотя эту команду легко использовать, я не рекомендую этот метод, поскольку вы можете потерять множество полезных данных!
Допустим вы хотите узнать, какой тип имеет самый высокий средний показатель HP. Для этого мы можем использовать команду groupby. Эта команда используется для выполнения операций над группами данных.
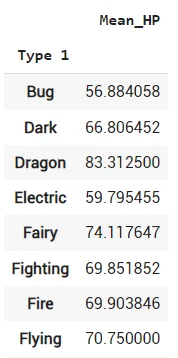
Эта команда создает новый фрейм данных с именем ‘df_groupby’. Во-первых, нам нужно указать, по какому столбцу вы хотите группировать данные. В нашем случае мы используем столбец ‘Type 1’. Затем нам нужно указать, какой столбец будет обрабатываться. Мы хотим найти среднее (mean) значение столбца HP. После этого мы можем задать имя столбцу, который мы только что создали с помощью функции groupby, у нас это имя ‘Mean_HP’.
Зачем останавливаться на среднем? Эта функция дает возможность вычислять любые виды статистики на вашем фрейме данных:
Код выше вычисляет среднее, медиану, максимум, минимум, сумму и количество значений в столбце HP для каждого типа покемонов. Посмотрите, как много информации вы получаете с помощью такого простого кода!
Более того, вы можете группировать данные по нескольким столбцам.
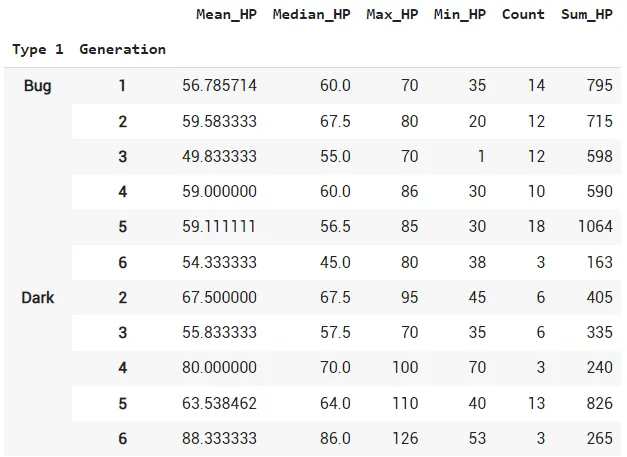
Обратите внимание, что функция groupby подобна повороту (pivot) вашего фрейма данных. Теперь вопрос: можно ли повернуть фрейм обратно (unpivot)? Ответ - да, мы можем это сделать с помощью функции melt.
Эта функция переводит фрейм данных с широкого представления (много столбцов) на длинный (много строк).
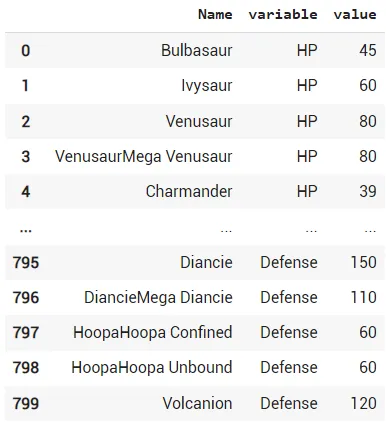
Результат выполнения команды melt
Эта команда создает новый фрейм данных с именем ‘df_melt’. Затем мы указываем переменную идентификатора (‘id_vars’). В данном случае наша переменная идентификатора носит имя покемона. Затем мы указываем столбцы для разворота. Мы используем столбцы ‘HP’, ‘Attack’ and ‘Defense’. Столбцы, которые мы хотим развернуть, попадут в новый столбец, названный ‘variable’. Значение каждого повернутого столбца находится в столбце ‘value’.
При анализе часто полезна фильтрация данных на базе заданного условия. Pandas предоставляет нам команду loc для фильтрации данных. Скажем, вы хотите отфильтровать покемонов по fire в первом типе.
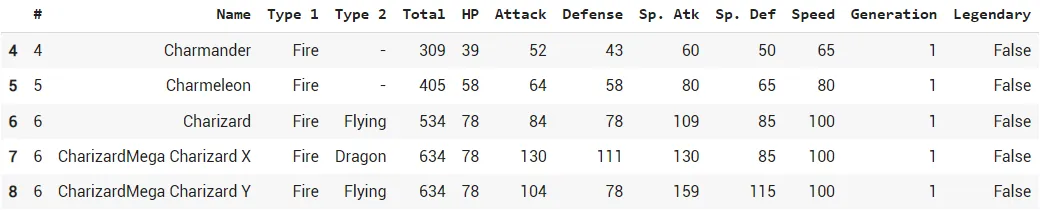
Результат
Что если вы хотите выполнить фильтрацию покемона по fire, water и grass из первого поколения? Мы также можем использовать функцию loc!
Вам, возможно интересно, что это за ":" после последней запятой в коде. Этот знак ":" используется для указания, что мы хотим увидеть все столбцы после фильтра. Если, скажем, нам нужны только names, HP, attack и defense из фильтра, мы можем использовать код:
Помимо loc, мы можете также использовать похожую команду с именем iloc. Она имеет подобную функциональность, но я предпочитаю использовать loc.
Другой информацией, которую вы можете захотеть узнать, это кто из покемонов имеет наилучший (или наихудший) показатель. Скажем, вы хотите узнать, кто из покемонов имеет наивысший показатель HP.
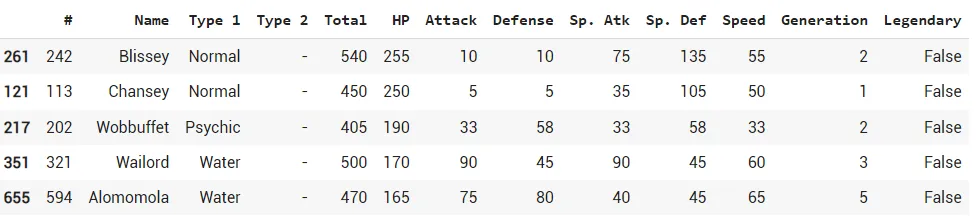
Результат выполнения sort_values
Как видно, эта функция сортирует фрейм данных по столбцу HP в порядке убывания. Если вам потребуется выполнить сортировку по возрастанию, просто измените код на:
Это все команды, которые я часто использую. Я стараюсь не выкладывать слишком много команд, так как их будет на все 20 страниц.
df=pd.read_csv('your path/Pokemon.csv')Теперь давайте посмотрим на этот набор данных!
Первые 5 строк набора
Данные содержат 13 столбцов (за исключением индексного столбца) - 4 текстовых столбца и 7 числовых.
Теперь давайте пройдемся по некоторым командам Pandas, которые я часто использую.
1. fillna/dropna
Никому не нравятся отсутствующие данные. Есть много различных способов их обработки, но эти 2 наbболее простые. Но сначала давайте посмотрим, есть ли в нашем фрейме данных отсутствующие данные, с помощью следующей функции:
df.info()Из результатов видно, что в столбце ‘Type 2’ множество пропущенных данных! Чтобы разобраться с этой проблемой вы можете использовать либо fillna, либо dropna.
Команда fillna заполняет отсутствующие данные тем, что вы укажете.
df.fillna('-')Эта команда заполняет отсутствующие данные символом '-'. Посмотрим теперь на набор данных:
Результат выполнения fillna
Можно увидеть, что некоторые строки в столбце ‘Type 2’ теперь содержат ‘-’, потому что ранее они не содержали значения.
Другим способом обработки отсутствующих данных является команда dropna. Команда dropna удаляет все строки, которые включают отсутствующие значения.
df.dropna()Результат выполнения этой команды выглядит так:
Результат выполнения команды dropna
Как видно, эта команда удаляет все строки с отсутствующими данными в столбце ‘Type 2’. Обратите внимание, что фрейм данных теперь содержит только 414 строк, а не исходные 800. Хотя эту команду легко использовать, я не рекомендую этот метод, поскольку вы можете потерять множество полезных данных!
2. Group by
Допустим вы хотите узнать, какой тип имеет самый высокий средний показатель HP. Для этого мы можем использовать команду groupby. Эта команда используется для выполнения операций над группами данных.
df_groupby=df.groupby(['Type 1']).agg(Mean_HP=('HP','mean'))
df_groupbyЭта команда создает новый фрейм данных с именем ‘df_groupby’. Во-первых, нам нужно указать, по какому столбцу вы хотите группировать данные. В нашем случае мы используем столбец ‘Type 1’. Затем нам нужно указать, какой столбец будет обрабатываться. Мы хотим найти среднее (mean) значение столбца HP. После этого мы можем задать имя столбцу, который мы только что создали с помощью функции groupby, у нас это имя ‘Mean_HP’.
Зачем останавливаться на среднем? Эта функция дает возможность вычислять любые виды статистики на вашем фрейме данных:
df_groupby=df.groupby(['Type 1']).agg(Mean_HP=('HP','mean'),Median_HP=('HP','median'),Max_HP=('HP','max'),Min_HP=('HP','min'),Count=('HP','count'),Sum_HP=('HP','sum'))Код выше вычисляет среднее, медиану, максимум, минимум, сумму и количество значений в столбце HP для каждого типа покемонов. Посмотрите, как много информации вы получаете с помощью такого простого кода!
Более того, вы можете группировать данные по нескольким столбцам.
df_groupby=df.groupby(['Type 1','Generation']).agg(Mean_HP=('HP','mean'),Median_HP=('HP','median'),Max_HP=('HP','max'),Min_HP=('HP','min'),Count=('HP','count'),Sum_HP=('HP','sum'))3. Melt
Обратите внимание, что функция groupby подобна повороту (pivot) вашего фрейма данных. Теперь вопрос: можно ли повернуть фрейм обратно (unpivot)? Ответ - да, мы можем это сделать с помощью функции melt.
Эта функция переводит фрейм данных с широкого представления (много столбцов) на длинный (много строк).
df_melt=pd.melt(df,id_vars=['Name'],value_vars=['HP','Attack','Defense'],ignore_index=False)Результат выполнения команды melt
Эта команда создает новый фрейм данных с именем ‘df_melt’. Затем мы указываем переменную идентификатора (‘id_vars’). В данном случае наша переменная идентификатора носит имя покемона. Затем мы указываем столбцы для разворота. Мы используем столбцы ‘HP’, ‘Attack’ and ‘Defense’. Столбцы, которые мы хотим развернуть, попадут в новый столбец, названный ‘variable’. Значение каждого повернутого столбца находится в столбце ‘value’.
4. Loc
При анализе часто полезна фильтрация данных на базе заданного условия. Pandas предоставляет нам команду loc для фильтрации данных. Скажем, вы хотите отфильтровать покемонов по fire в первом типе.
df.loc[(df['Type 1']=='Fire'),:]Результат
Что если вы хотите выполнить фильтрацию покемона по fire, water и grass из первого поколения? Мы также можем использовать функцию loc!
df.loc[(df['Type 1'].isin(['Fire','Water','Grass'])) & (df['Generation']==1),:]Вам, возможно интересно, что это за ":" после последней запятой в коде. Этот знак ":" используется для указания, что мы хотим увидеть все столбцы после фильтра. Если, скажем, нам нужны только names, HP, attack и defense из фильтра, мы можем использовать код:
Помимо loc, мы можете также использовать похожую команду с именем iloc. Она имеет подобную функциональность, но я предпочитаю использовать loc.
5. sort_values
Другой информацией, которую вы можете захотеть узнать, это кто из покемонов имеет наилучший (или наихудший) показатель. Скажем, вы хотите узнать, кто из покемонов имеет наивысший показатель HP.
df.sort_values(by=['HP'],ascending=False)Результат выполнения sort_values
Как видно, эта функция сортирует фрейм данных по столбцу HP в порядке убывания. Если вам потребуется выполнить сортировку по возрастанию, просто измените код на:
df.sort_values(by=['HP'],ascending=True)Это все команды, которые я часто использую. Я стараюсь не выкладывать слишком много команд, так как их будет на все 20 страниц.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой