
Планирование планов. Часть 26 - окна с диапазонной рамкой
Пересказ статьи Hugo Kornelis. Plansplaining part 26 – Windows with a ranged frame
Это двадцать шестая часть данной серии (plansplaining). И уже четвертый эпизод об оконных функциях. Первая из этих статей была посвящена базовым оконным функциям; вторая была посвящена быстрой оптимизации накопительных агрегатов, а в третьей публикации объяснялось, как оптимизатор работает при отсутствии поддержки плана выполнения для UNBOUNDED FOLLOWING.
Но все это было для спецификации OVER, которая использует ключевое слово ROWS. Теперь давайте рассмотрим альтернативу, ключевое слово RANGE.
RANGE вместо ROWS
При использовании спецификации RANGE не допускаются число PRECEDING и число FOLLOWING . Поэтому нам остаются только несколько возможных спецификаций RANGE. И даже для этого ограниченного списка не все требует обсуждения.
Например, RANGE BETWEEN UNBOUDED PRECEDING AND UNBOUNDED FOLLOWING означает ровно то же, что и ROWS BETWEEN UNBOUDED PRECEDING AND UNBOUNDED FOLLOWING, т.е. что видимым является все окно. Здесь нет рамки, и оптимизатор просто притворится, что оно не было указано.
Также RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING обрабатывается тем же способом, как и любой ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING: оптимизатор обратит указанный порядок сортировки, а затем также должен перевернуть рамку окна на RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW.
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
Использование RANGE вместо ROWS для спецификации рамки окна означает, что конечная точка CURRENT ROW не обязательно заканчивается на текущей строке. Если имеются дубликаты в столбце (или столбцах) ORDER BY, то конечной точкой рамки окна является последняя строка с теми же самыми значениями в столбцах ORDER BY , что и в текущей строке. Поэтому для ORDER BY по уникальным значениям RANGE или ROWS делают одно и то же. Но если имеются дубликаты, то спецификация RANGE включает несколько лишних строк. Вы можете увидеть этот эффект, раскомментировав столбец RunningSum в коде ниже, а затем сравнив данные в этих двух столбцах.
SELECT p.ProductID,
p.Name,
p.ListPrice,
p.ProductLine,
--SUM (p.ListPrice) OVER (PARTITION BY p.ProductLine
-- ORDER BY p.ListPrice
-- ROWS BETWEEN UNBOUNDED PRECEDING
-- AND CURRENT ROW) AS RunningSum,
SUM (p.ListPrice) OVER (PARTITION BY p.ProductLine
ORDER BY p.ListPrice
RANGE BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW) AS SumWithRange
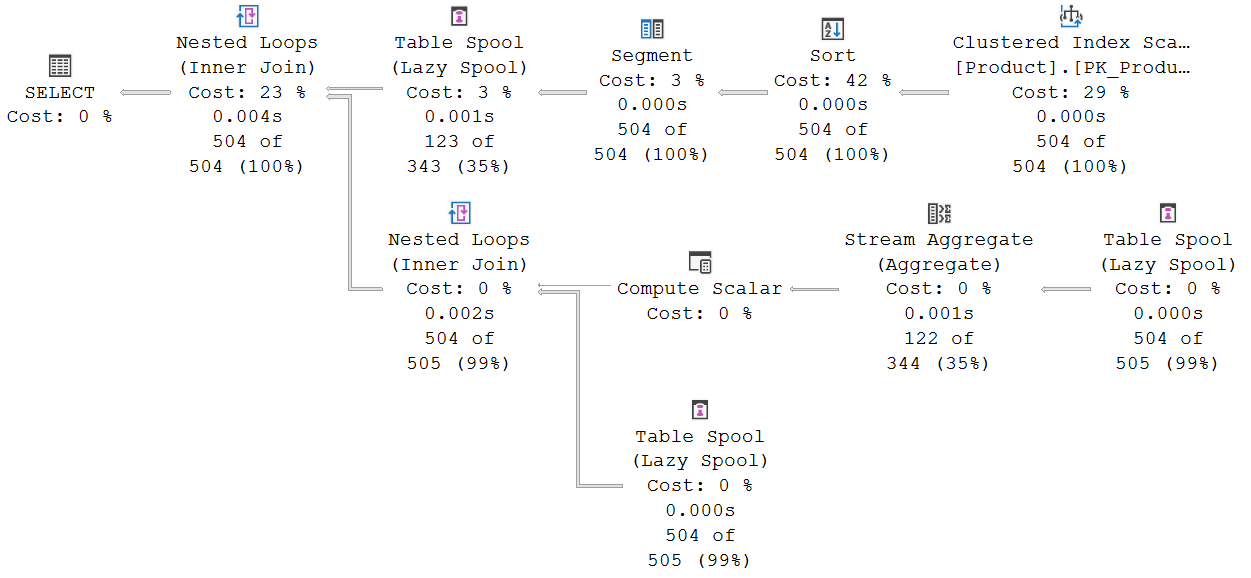
FROM Production.Product AS p;Но пока я оставлю этот столбец закомментированным, поскольку хочу показать план выполнения, который вычисляет агрегат для рамки окна с RANGE. Поэтому я выполняю запрос выше, и план выполнения со статистикой в реальном времени выглядит следующим образом:

Некоторые вещи те же, что и в предыдущих примерах. Слева по-прежнему находится сканирование кластеризованного индекса, чтобы получить все строки, а затем сортировка (Sort), чтобы упорядочить их по ProductLine и ListPrice. Слева так же находится Window Spool, чтобы воспроизвести видимую рамку окна для каждой строки, а Stream Aggregate - для агрегации строк из этой воспроизводимой рамки в единственную строку; и Compute Scalar - для обработки (теоретической, но в данном конкретном случае невозможной) случая рамки окна без строк.
Но середина выглядит иначе. Здесь нет Sequence Project для вычисления номера строки в пределах разбиения для каждой строки. Ни Compute Scalar для вычисления максимального и/или минимального номера строки текущей рамки. Зато теперь есть два оператора Segment вместо одного, который мы обычно видим. Segment #4 нам знаком. Так же, как и в других планах выполнения, которые мы видели до сих пор, этот оператор устанавливает Segment1004 для указания того, где начинается новое разбиение (окно), поскольку изменяется столбец ProductLine.
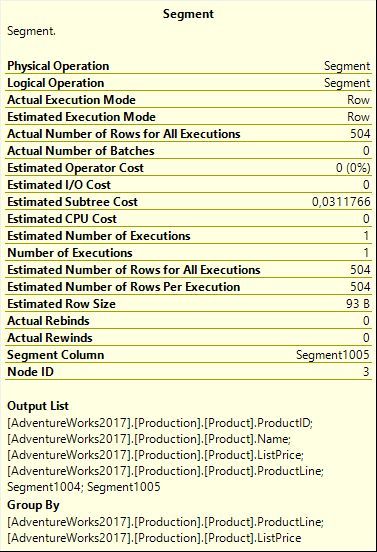
Segment #3 уникален для этого плана выполнения. Он добавляет столбец второго сегмента, Segment1005. И этот столбец сегмента основывается на изменении в любом из ProductLine и ListPrice. Поэтому этот столбец второго сегмента отмечает новый сегмент всякий раз когда первый отмечает новый сегмент, но он также отмечает новый сегмент, когда ProductLine не меняется, а меняется ListPrice. Другими словами, каждый сегмент, отмечаемый этим оператором, является множеством строк, которые все имеют одинаковое значение PARTITION BY, а также одинаковое значение ORDER BY. Поэтому для спецификации RANGE все строки в текущем сегменте следует включить в агрегацию для получения правильного значения.
Оператор Window Spool может затем использовать эти столбцы сегмента для выявления корректных строк для оператора Stream Aggregate. Скажем, одно из разбиений имеет четыре строки, и значениями в столбце ORDER BY являются 1,1,2 и 2. Segment1004 будет установлен только на первую их этих строк, и заставит Window Spool очистить рабочую таблицу. Затем он читает вперед, чтобы найти все остальные строки в том же сегменте, как указывается в столбце второго сегмента, Segment1005, который установлен как на первой, так и на третьей строке. Затем он возвращает первую строку в качестве текущей, за которой следуют строки в его рамке, первая и вторая строки. После этого он возвращает вторую строку, за которой опять следует та же рамка. В третьей строке установлен Segent1005, поэтому теперь еще раз выполняется чтение вперед, а затем возвращается эта третья строка как текущая, за которой следует вся рамка (строки с 1 по 4). И, наконец, возвращается четвертая строка и еще раз та же самая рамка.
Но… на самом деле это не так. Поскольку мы стартуем с UNBOUNDED PRECEDING, быстрая оптимизация, которую мы видели раньше, здесь также может быть применена. Так что при этой оптимизации, фактически возвращаемыми строками для этого примера являются: первая строка в качестве текущей, плюс первая и вторая строки, которые нужно добавить в (на тот момент пустую) рамку. Вторая строка в качестве текущей со следующими за ней третьей и четвертой добавляются в рамку. А затем четвертая строка как текущая, за которой опять ничего не добавляется. Как и в случае ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW, мы приходим к возвращению каждой строки дважды, один раз в качестве текущей и еще раз в качестве строки, которая добавляется к накопительному агрегату. Просто в несколько ином порядке.
Оператор Window Spool должен сохранить все строки в одном и том же (вторичном) сегменте в своей рабочей таблице. Хотя и маловероятно, всегда возможно, что найдется более 10000 строк с одними и теми же значениями в обоих столбцах PARTITION BY и ORDER BY. Следовательно, эта рабочая таблица всегда сохраняется на диске и никогда в памяти.
Крайне важно всегда указывать ROWS, а не RANGE, если вам не нужна функциональность RANGE. Если вам нужны нормальные накопительные агрегаты, и вы случайно указали RANGE, то вы, надеюсь, заметите свою ошибку, когда выполните тесты и увидите неверные результаты, возвращаемые для строк, которые имеют одинаковые значения в столбце (столбцах) ORDER BY. Но есть одно неприятное исключение. Когда имеет место случай, что столбец ORDER BY содержит только уникальные значения, то ROWS и RANGE по определению возвращают одинаковые результаты. Поэтому никакие тесты не обнаружат, если вы случайно использовали RANGE вместо ROWS. Но все же ЕСТЬ разница в производительности. Для двух запросов ниже первый будет сохранять рабочую таблицу в памяти, в то время как второй - на диске. Это вызывает почти 190000 логических чтений, и на моем ноутбуке второй запрос выполняется примерно вдвое дольше первого, и потребляет в четыре раза больше времени ЦП.
SELECT soh.SalesOrderID,
SUM(soh.TotalDue) OVER (ORDER BY soh.SalesOrderID
ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW) AS RunTotal
FROM Sales.SalesOrderHeader AS soh;
SELECT soh.SalesOrderID,
SUM(soh.TotalDue) OVER (ORDER BY soh.SalesOrderID
RANGE BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW) AS RunTotal
FROM Sales.SalesOrderHeader AS soh;К сожалению, предложение OVER предоставляет, что может на первый взгляд показаться очень удобным, значение по умолчанию, которое экономит массу печатного набора. Если вы указываете ORDER BY, но при этом не задаете рамку, то по умолчанию это даст накопительный агрегат, такой, как в примере ниже:
SELECT soh.SalesOrderID,
SUM(soh.TotalDue) OVER (ORDER BY soh.SalesOrderID) AS RunTotal
FROM Sales.SalesOrderHeader AS soh;А плохая новость заключается в том, что это поведение по умолчанию фактически определяется как RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. Которое в случае примера выше возвращает те же самые результаты, но со значительно худшей производительностью. И если в действительности имеются дубликаты в столбце ORDER BY, то результат по умолчанию весьма вероятно будет не тот, который вы хотели получить!
Отсюда вывод: всегда явно указывайте выражение ROWS или RANGE!
RANGE BETWEEN CURRENT ROW AND CURRENT ROW
Спецификация BETWEEN CURRENT ROW AND CURRENT ROW может сначала показаться странной. И, прежде всего, полностью избыточной. И это на самом деле правильно...если говорить о спецификации ROWS. ROWS BETWEEN CURRENT ROW AND CURRENT ROW буквально означает только текущую строку, и агрегация только текущей строки будет именно ее и возвращать. (На заметку. Оптимизатор не распознает безумие такого запроса и будет радостно нести все накладные расходы, чтобы это повторить и агрегировать рамку окна из одной строки. Поэтому, пожалуйста, не делайте так.)
Однако RANGE BETWEEN CURRENT ROW AND CURRENT ROW на самом деле имеет больше смысла. Как объяснялось ранее, при использовании RANGE верхняя граница CURRENT ROW не всегда заканчивается текущей строкой, а на последней строке при том же значении ORDER BY. Подобным образом нижняя граница CURRENT ROW означает, что она начинается на первой строке с тем же самым значением ORDER BY. Фактически это означает, что для каждой строки в разбиении с конкретным значением в столбце (столбцах) ORDER BY рамка окна включает все строки с тем же самым значением (значениями) ORDER BY.
Это все же не значит, что RANGE BETWEEN CURRENT ROW AND CURRENT ROW действительно полезен. Вы можете просто перенести столбцы ORDER BY в предложение PARTITION BY и удалить рамку, чтобы получить в точности те же результаты. Поэтому два запроса ниже фактически одинаковы:
SELECT p.ProductID,
p.Name,
p.ListPrice,
p.ProductLine,
SUM (p.ListPrice) OVER (PARTITION BY p.ProductLine
ORDER BY p.ListPrice
RANGE BETWEEN CURRENT ROW
AND CURRENT ROW) AS SumWithRange
FROM Production.Product AS p;
SELECT p.ProductID,
p.Name,
p.ListPrice,
p.ProductLine,
SUM (p.ListPrice) OVER (PARTITION BY p.ProductLine,
p.ListPrice) AS SumWithRange
FROM Production.Product AS p;И действительно, план выполнения для первого является таким же, как план выполнения для второго, использующего шаблон, который мы уже видели ранее множество раз для агрегатов в окне без рамки. Помимо этого в данном случае границы окна определяются комбинацией двух столбцов, а не одного. (Только в этом вы можете увидеть действительное различие в свойстве Group By оператора Segment.)
Заключение
Количество возможных спецификаций RANGE само по себе уже ограничено. И большинство даже не требует поддержки в плане выполнения. Некоторые могут быть преобразованы в эквивалентный запрос, который использует окно без рамки. Только два не могут, и они являются противоположностями друг друга. Следовательно, планы выполнения имеют непосредственную поддержку только для RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. Он возвращает то же самое, чтобы и подобная спецификация ROWS в случаях, когда комбинация столбцов PARTITION BY и ORDER BY не может иметь дублирующих значений, но с огромной потерей производительности. Когда возможно наличие дублирующих значений, результаты не одинаковы, и вам требуется выбрать один подходящий вам вариант.
Когда вы используете предложение OVER с ORDER BY, но без задания рамки, применяется рамка по умолчанию RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW с его (возможно нежелательным) ударом по производительности.
На этом мы заканчиваем обсуждение предложения OVER с агрегацией. Но это не завершает данную мини-серию по оконным функциям. В следующем эпизоде, я сосредоточу внимание на функциях LAG и LEAD и объяснении, что они фактически являются просто специальным случаем агрегации с рамкой окна.
Ссылки по теме
1. Агрегатные функции
2. Оконные функции T-SQL и производительность
3. Пересмотр производительности оконных агрегатов в SQL Server 2019
4. Индексирование и оконные функции
5. Понимание предложения ROWS BETWEEN в SQL
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой