
Оконные функции T-SQL и производительность
Пересказ статьи Kathi Kellenberger. T-SQL Window Functions and Performance
Оконные функции упрощают написание многих запросов и зачастую обеспечивают лучшую производительность по сравнению со старыми методами. Например, использование функции LAG существенно лучше, чем применение самосоединения. Однако чтобы добиться лучшей производительности в целом, необходимо понимать концепции оконных функций, и то как они используют сортировку для получения результата.
Предложение OVER и сортировка
Имеется две конструкции в предложении OVER, которые могут привести к сортировке: ORDER BY и PARTITION BY. PARTITION BY поддерживается всеми оконными функциями, но не является обязательной. ORDER BY является обязательной для большинства функций. В зависимости от того, что вы пытаетесь выполнить, данные будут сортироваться в соответствии с предложением OVER, и это может являться узким местом производительности вашего запроса.
Например, вы хотите применить функцию ROW_NUMBER в порядке SalesOrderID. Результат будет отличаться от, скажем, применения функции в порядке убывания TotalDue:
USE AdventureWorks2017; --или другая версия, которая у вас установлена
GO
SELECT SalesOrderID,
TotalDue,
ROW_NUMBER() OVER(ORDER BY SalesOrderID) AS RowNum
FROM Sales.SalesOrderHeader;
SELECT SalesOrderID,
TotalDue,
ROW_NUMBER() OVER(ORDER BY TotalDue DESC) AS RowNum
FROM Sales.SalesOrderHeader;
Поскольку первый запрос использует кластерный ключ в опции ORDER BY, никакой сортировки не требуется.

План выполнения второго запроса содержит дорогую операцию сортировки.

ORDER BY в предложении OVER никак не связан с предложением ORDER BY для всего запроса. Следующий пример показывает, что происходит, если они отличаются:
SELECT SalesOrderID,
TotalDue,
ROW_NUMBER() OVER(ORDER BY TotalDue DESC) AS RowNum
FROM Sales.SalesOrderHeader
ORDER BY SalesOrderID;
Ключом кластерного индекса является SalesOrderID, однако строки сначала должны быть отсортированы по TotalDue в убывающем порядке, а затем снова по SalesOrderID. Взгляните на план:

Предложение PARTITION BY тоже может вызывать сортировку. Это подобно, хотя и не вполне точно, предложению GROUP BY в агрегирующих запросах. Следующий запрос нумерует строки для каждого клиента.
SELECT CustomerID,
SalesOrderID,
TotalDue,
ROW_NUMBER() OVER(PARTITION BY CustomerID ORDER BY SalesOrderID) AS RowNum
FROM Sales.SalesOrderHeader;
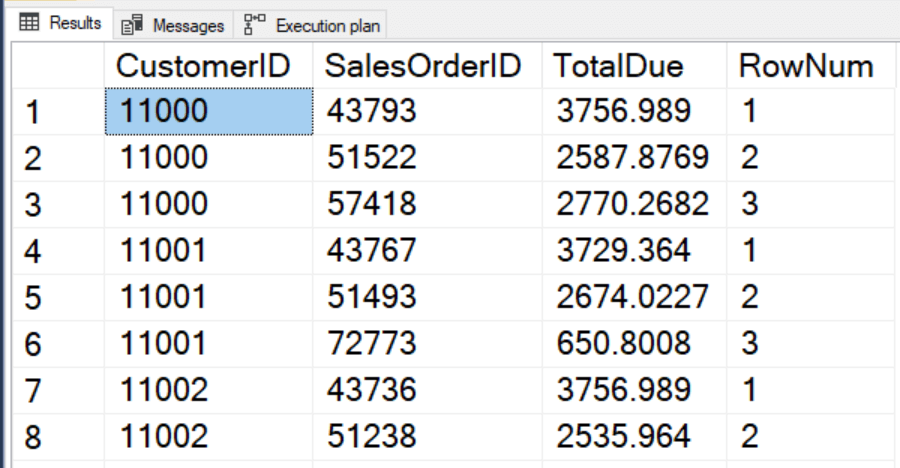
План выполнения показывает только одну сортировку по комбинации столбцов – CustomerID и SalesOrderID.

Одним из способов избежать падения производительности является создание индекса специально под предложение OVER. В своей книге Microsoft SQL Server 2012 High-Performance T-SQL Using Window Functions, Ицик Бен-Ган предлагает POC-индекс (POC – (P)ARTITION BY, (O)RDER BY, and (C)overing). Он рекомендует добавлять любые столбцы, используемые для фильтрации, перед столбцами PARTITION BY и ORDER BY в ключ индекса. Затем добавлять любые дополнительные столбцы, необходимые для создания покрывающего индекса, в качестве включенных столбцов. Как и всегда, следует выполнить тестирование, как такой индекс повлияет на ваш запрос и общую нагрузку. Разумеется, вы не можете добавлять индексы для каждого запроса, который пишете. Но если проблемы производительности вызывает конкретный запрос, который использует оконную функцию, важно принять во внимание этот совет.
Вот индекс, который улучшает предыдущий запрос:
CREATE NONCLUSTERED INDEX test ON Sales.SalesOrderHeader
(CustomerID, SalesOrderID)
INCLUDE (TotalDue);
Если вы опять запустите этот запрос, то увидите, что операция сортировки исчезла из плана выполнения:
 Рамки (FRAME)
Рамки (FRAME)
На мой взгляд, рамки представляются наиболее сложной для понимания концепцией при изучении оконных функций. Рамки требуются в случаях:
- Оконные агрегаты с ORDER BY, используемые для вычисления накопительных итогов, перемещающихся средних и т.д.
- FIRST_VALUE
- LAST_VALUE
К счастью, рамки требуются не всегда, однако, к сожалению, легко упустить их из виду, используя поведение по умолчанию. Рамка по умолчанию всегда RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW (диапазон от начала до текущей строки). Хотя вы будете получать правильные результаты, если предложение ORDER BY содержит уникальный столбец или комбинацию столбцов, вы увидите скачок производительности.
Вот пример, сравнивающий окно по умолчанию и правильное окно:
SET STATISTICS IO ON;
GO
SELECT CustomerID,
SalesOrderID,
TotalDue,
SUM(TotalDue) OVER(PARTITION BY CustomerID ORDER BY SalesOrderID) AS RunningTotal
FROM Sales.SalesOrderHeader;
SELECT CustomerID,
SalesOrderID,
TotalDue,
SUM(TotalDue) OVER(PARTITION BY CustomerID ORDER BY SalesOrderID
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS RunningTotal
FROM Sales.SalesOrderHeader;
Результаты одинаковы, но производительность сильно разнится. К сожалению, план выполнения не скажет вам правды в этом случае. Он отводит каждому запросу по 50% ресурсов:
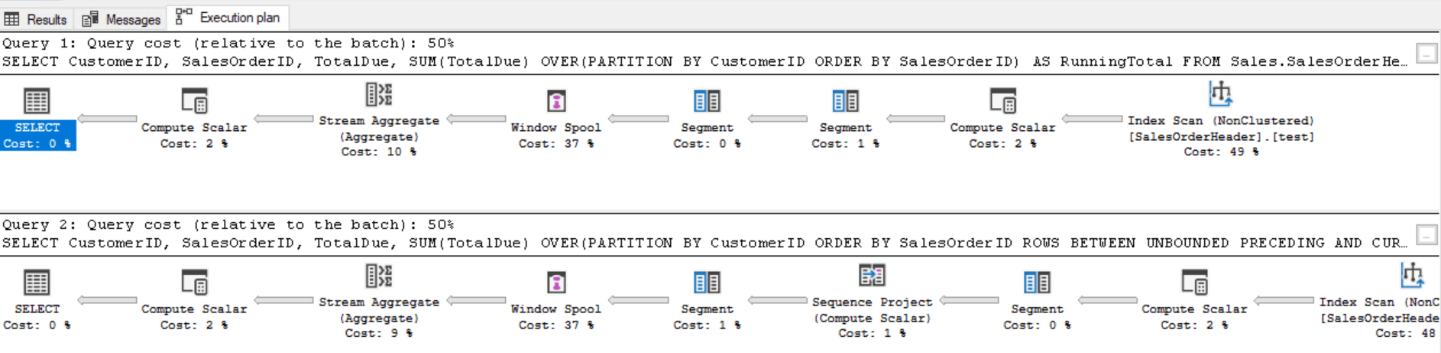
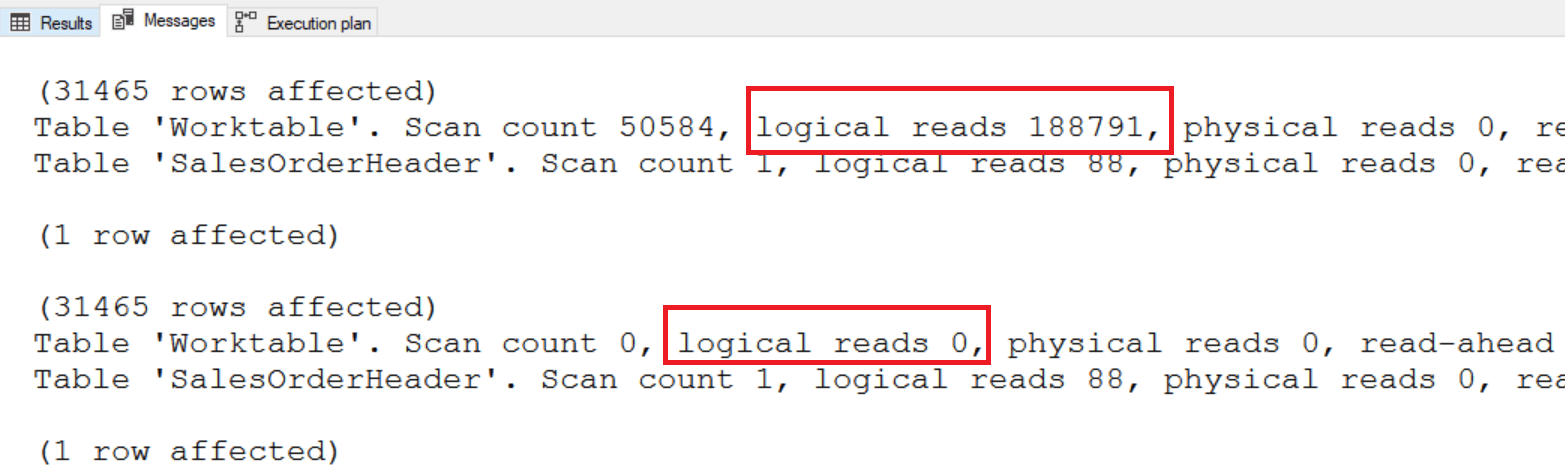
Если вы посмотрите статистику по вводу/выводу, то увидите разницу:
Использование правильной рамки окна даже более важно, если опция ORDER BY не уникальна или если вы используете LAST_VALUE. В данном примере в ORDER BY используется столбец OrderDate, а некоторые покупатели размещают более одного заказа в день. Если не задать рамки окна, или использовать RANGE, функция рассматривает совпадающие даты как часть одного и того же окна.
SELECT CustomerID,
SalesOrderID,
TotalDue,
OrderDate,
SUM(TotalDue) OVER(PARTITION BY CustomerID ORDER BY OrderDate) AS RunningTotal,
SUM(TotalDue) OVER(PARTITION BY CustomerID ORDER BY OrderDate
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS CorrectRunningTotal
FROM Sales.SalesOrderHeader
WHERE CustomerID IN ('11433','11078','18758');
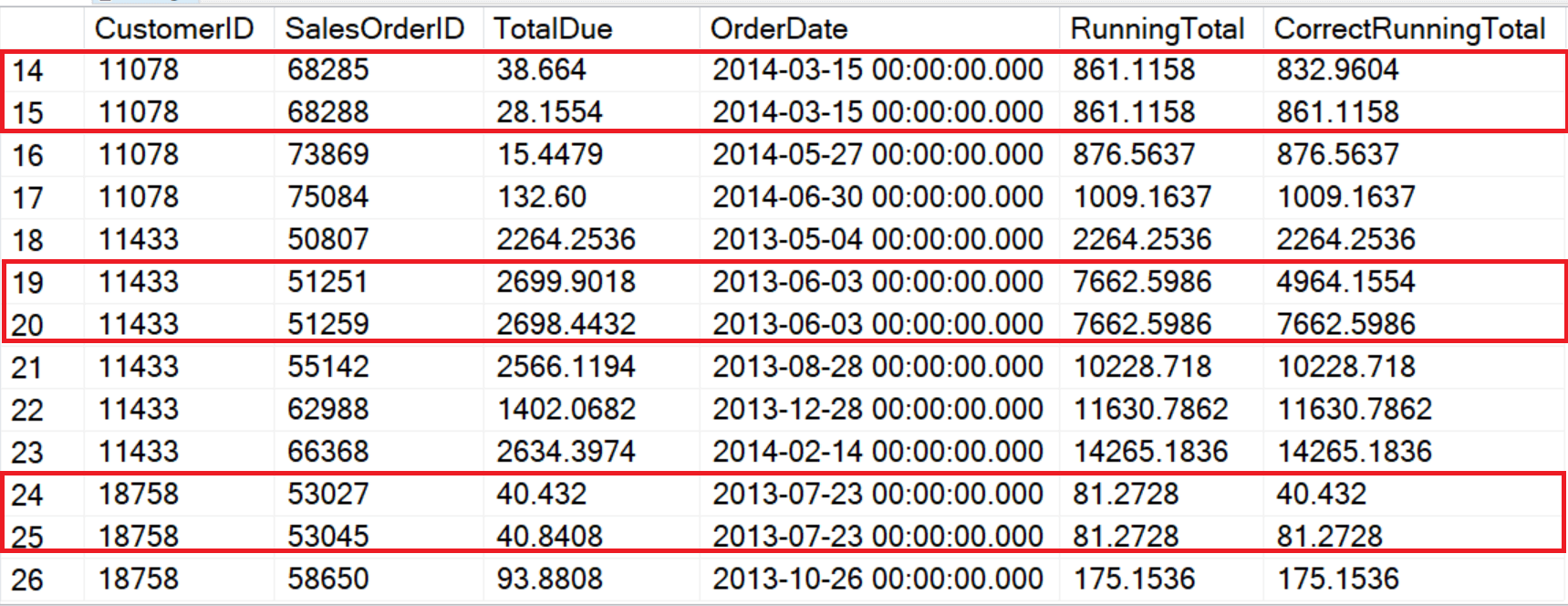
Причина несоответствия состоит в том, что RANGE видит данные логически, в то время как ROWS видит их позиционно. Существует 2 решения этой проблемы. Первое – это сделать опцию ORDER BY уникальной. Второй и более важный способ – всегда задавать рамку там, где она поддерживается.
Другая область, где рамки вызывают логические проблемы, связана с LAST_VALUE. LAST_VALUE возвращает выражение из последней строки рамки. Поскольку значение по умолчанию рамки (RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) простирается только до текущей строки, последняя строка рамки и есть строка, для которой выполняются вычисления. Вот пример:
SELECT CustomerID,
SalesOrderID,
TotalDue,
LAST_VALUE(SalesOrderID) OVER(PARTITION BY CustomerID ORDER BY SalesOrderID) AS LastOrderID,
LAST_VALUE(SalesOrderID) OVER(PARTITION BY CustomerID ORDER BY SalesOrderID
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS CorrectLastOrderID
FROM Sales.SalesOrderHeader
ORDER BY CustomerID, SalesOrderID;
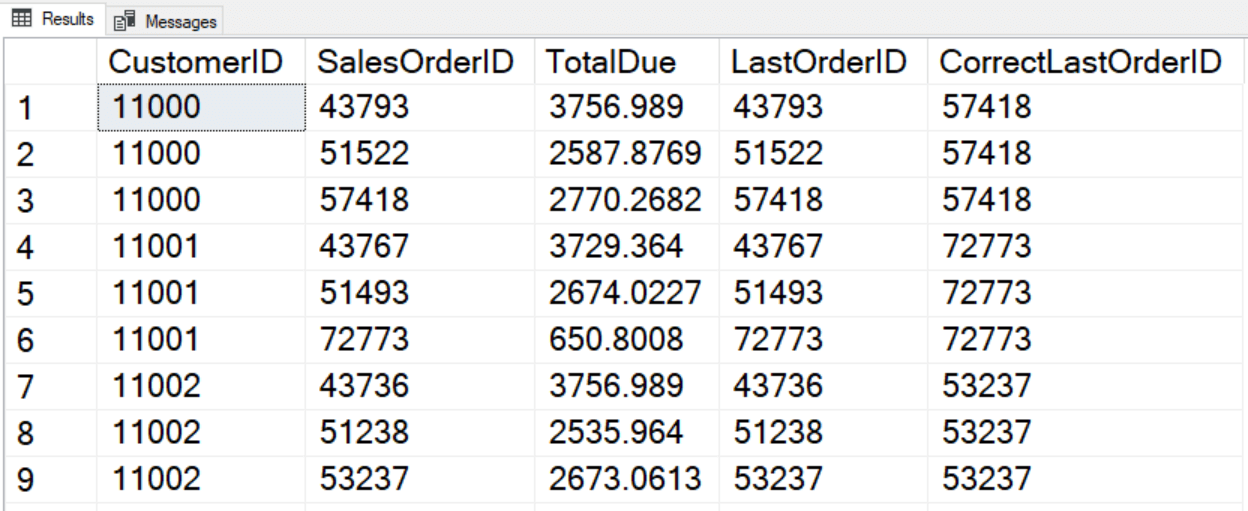
Агрегаты окна
Одной их полезнейших особенностей оконных функций является возможность добавлять агрегатные выражения в неагрегатные запросы. К сожалению, это часто плохо сказывается на производительности. Чтобы понять проблему, нужно посмотреть статистику ввода/вывода, где вы увидите большое число логических чтений. Если вам требуется вернуть значения с разной детализацией в одном запросе для большого числа строк, я советую использовать один из старых методов, например, общие табличные выражения (CTE), временные таблицы или даже переменные. Если возможно заранее вычислить агрегаты до использования оконных агрегатов, - это еще один способ. Вот пример, который демонстрирует разницу между оконным агрегатом и другим методом:
SELECT SalesOrderID,
TotalDue,
SUM(TotalDue) OVER() AS OverallTotal
FROM Sales.SalesOrderHeader
WHERE YEAR(OrderDate) =2013;
DECLARE @OverallTotal MONEY;
SELECT @OverallTotal = SUM(TotalDue)
FROM Sales.SalesOrderHeader
WHERE YEAR(OrderDate) = 2013;
SELECT SalesOrderID,
TotalDue,
@OverallTotal AS OverallTotal
FROM Sales.SalesOrderHeader AS SOH
WHERE YEAR(OrderDate) = 2013;
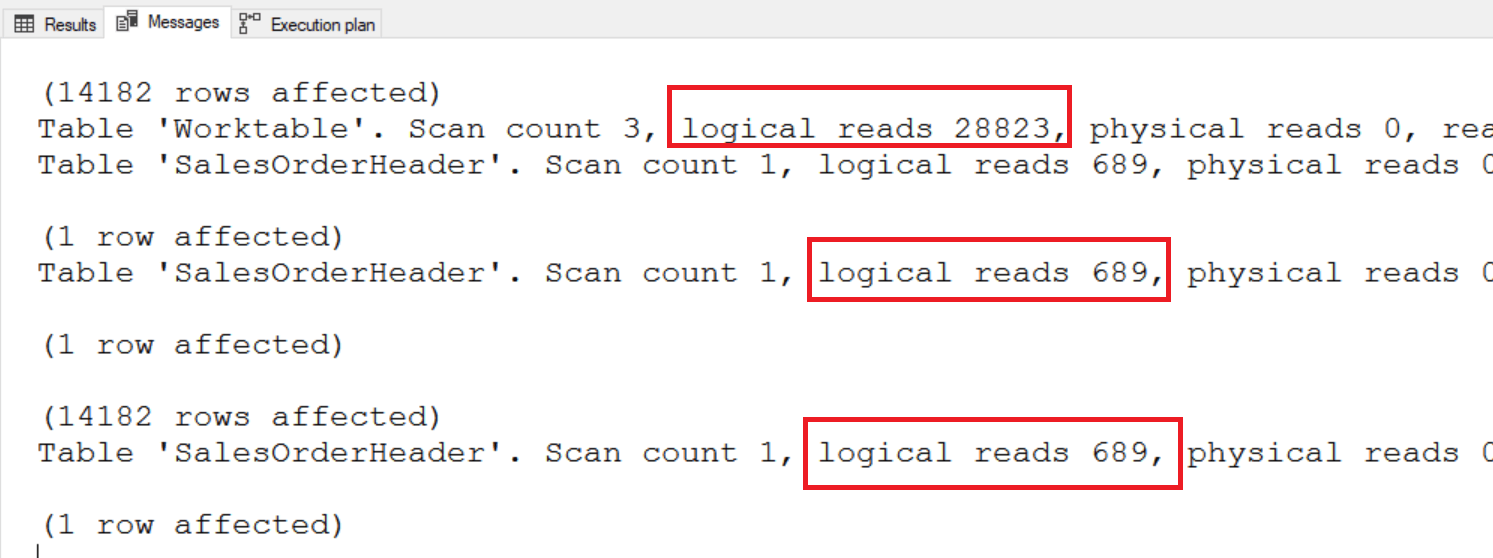
Первый запрос сканирует таблицу лишь один раз, однако он имеет 28823 логических чтений в рабочей таблице. Второй метод сканирует таблицу дважды, но ему не требуется рабочая таблица.
Следующий пример использует оконный агрегат, применяемый к агрегатному выражению:
SELECT YEAR(OrderDate) AS OrderYear,
SUM(TotalDue) AS YearTotal,
SUM(TotalDue)/
SUM(SUM(TotalDue)) OVER() * 100 AS PercentOfSales
FROM Sales.SalesOrderHeader
GROUP BY YEAR(OrderDate)
ORDER BY OrderYear;
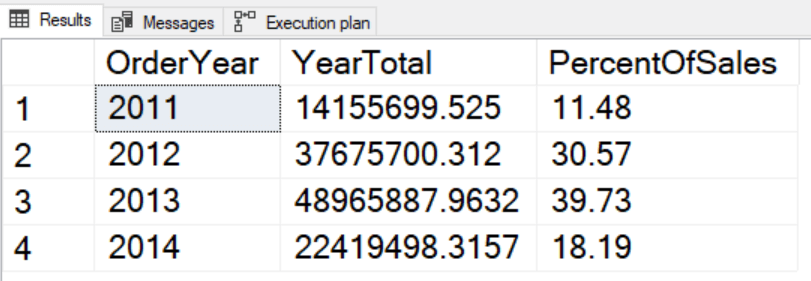
При использовании оконных функций в агрегирующем запросе, выражение должно следовать тем же правилам, что и предложения SELECT и ORDER BY. В данном случае оконная функция применяется к SUM(TotalDue). Это выглядит как вложенный агрегат, однако на самом деле оконная функция применяется к агрегатному выражению.
Поскольку данные были агрегированы до применения оконной функции, запрос демонстрирует хорошую производительность:

Существует более интересная вещь, знать о которой нужно, используя агрегатные функции. Если вы используете множественные выражения, у которых совпадает определение предложения OVER, вы не увидите дополнительного падения производительности.
Я советую использовать эту функциональность с осторожностью. Это весьма удобно, но не так хорошо масштабируется.
Сравнение производительности
До сих пор в примерах использовалась небольшая таблица Sales.SalesOrderHeader из базы данных AdventureWorks, и внимание уделялось плану выполнения и логическим чтениям. В реальной жизни ваших клиентов не беспокоит ни план выполнения, ни логические чтения; им важно насколько быстро выполняется запрос. Чтобы увидеть разницу во времени исполнения, я использую скрипт Адама Мачаника (Adam Machanic) с некоторыми изменениями.
Скрипт создает таблицу с именем bigTransactionHistory, содержащую свыше 30 миллионов строк. После выполнения скрипта Адама я создала еще две копии этой таблицы с 15 и 7,5 миллионами строк соответственно. Кроме того, я включила опцию Discard results after execution (Отбросить результаты после выполнения) в параметрах результатов запроса с тем, чтобы заполнение сетки не отражалось на времени выполнения. Я запускала тест три раза и чистила кэш буфера перед каждым запуском.
Ниже приводится скрипт для создания дополнительных тестовых таблиц:
SELECT TOP(50) Percent *
INTO mediumTransactionHistory
FROM bigTransactionHistory;
SELECT TOP(25) PERCENT *
INTO smallTransactionHistory
FROM bigTransactionHistory;
GO
ALTER TABLE mediumTransactionHistory
ALTER COLUMN TransactionID INT NOT NULL;
GO
ALTER TABLE mediumTransactionHistory
ADD CONSTRAINT pk_mediumTransactionHistory PRIMARY KEY (TransactionID);
GO
ALTER TABLE smallTransactionHistory
ALTER COLUMN TransactionID INT NOT NULL;
GO
ALTER TABLE smallTransactionHistory
ADD CONSTRAINT pk_smallTransactionHistory PRIMARY KEY (TransactionID);
GO
CREATE NONCLUSTERED INDEX IX_ProductId_TransactionDate
ON mediumTransactionHistory
(
ProductId,
TransactionDate
)
INCLUDE
(
Quantity,
ActualCost
);
CREATE NONCLUSTERED INDEX IX_ProductId_TransactionDate
ON smallTransactionHistory
(
ProductId,
TransactionDate
)
INCLUDE
(
Quantity,
ActualCost
);
Я не могу привести все аргументы, насколько важно использовать рамку в случае её поддержки. Чтобы увидеть разницу, я выполняла тест, вычисляющий накопительные итоги, используя четыре метода:
- Решение на базе курсора
- Коррелирующий подзапрос
- Оконная функция с рамкой по умолчанию
- Оконная функция с ROWS
Я запускала тест на трех новых таблицах. Ниже приводятся результаты в виде графиков:
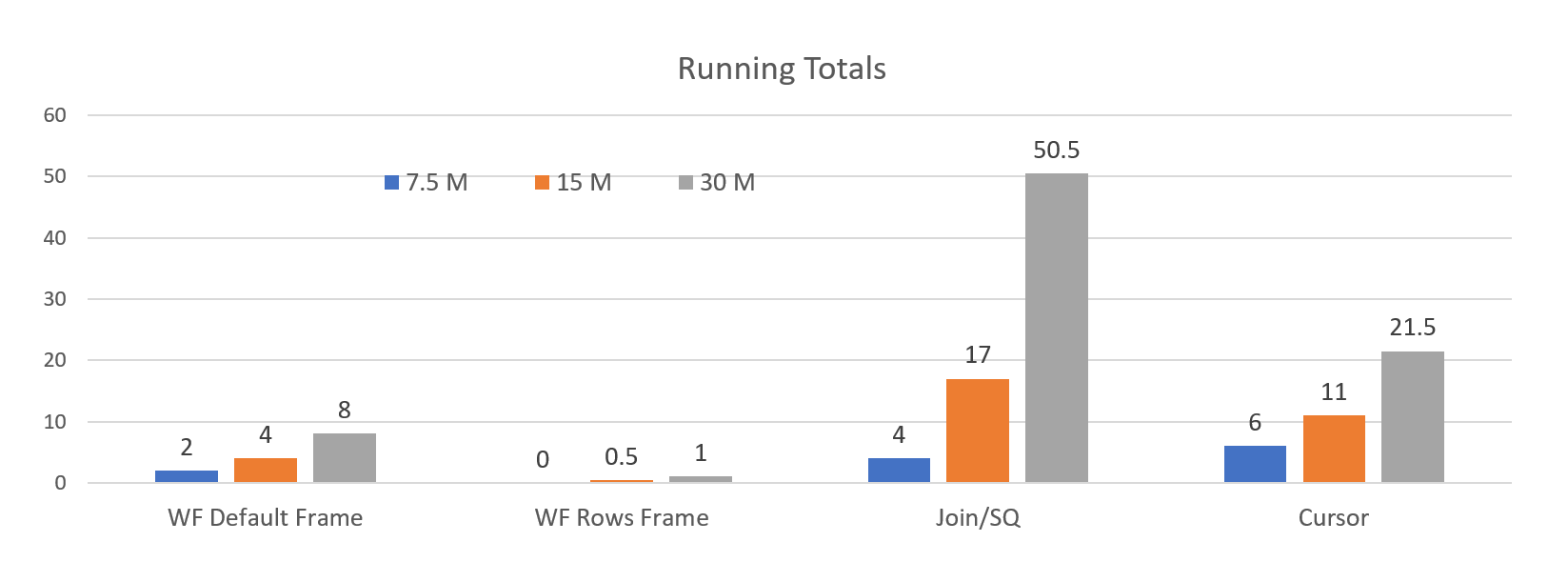
В случае с рамкой ROWS на таблице с 7,5 миллионом строк запросу на выполнение потребовалось меньше секунды. На таблице в 30 миллионов строк время запуска составило около минуты.
Вот запрос, использующий рамку ROWS, который выполнялся на таблице в 30 миллионов строк:
SELECT ProductID, SUM(ActualCost) OVER(PARTITION BY ProductID ORDER BY TransactionDate
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS RunningTotal
FROM bigTransactionHistory;
Я также проводила тесты, чтобы посмотреть, как оконные агрегаты ведут себя по сравнению с традиционными методами. В этом случае я просто использовала таблицу в 30 миллионов строк, но выполняла одно, два или три вычисления, используя одну и ту же степень детализации и, следовательно, одно и то же предложение OVER. Сравнивалась производительность оконных агрегатов с CTE и коррелирующим подзапросом.
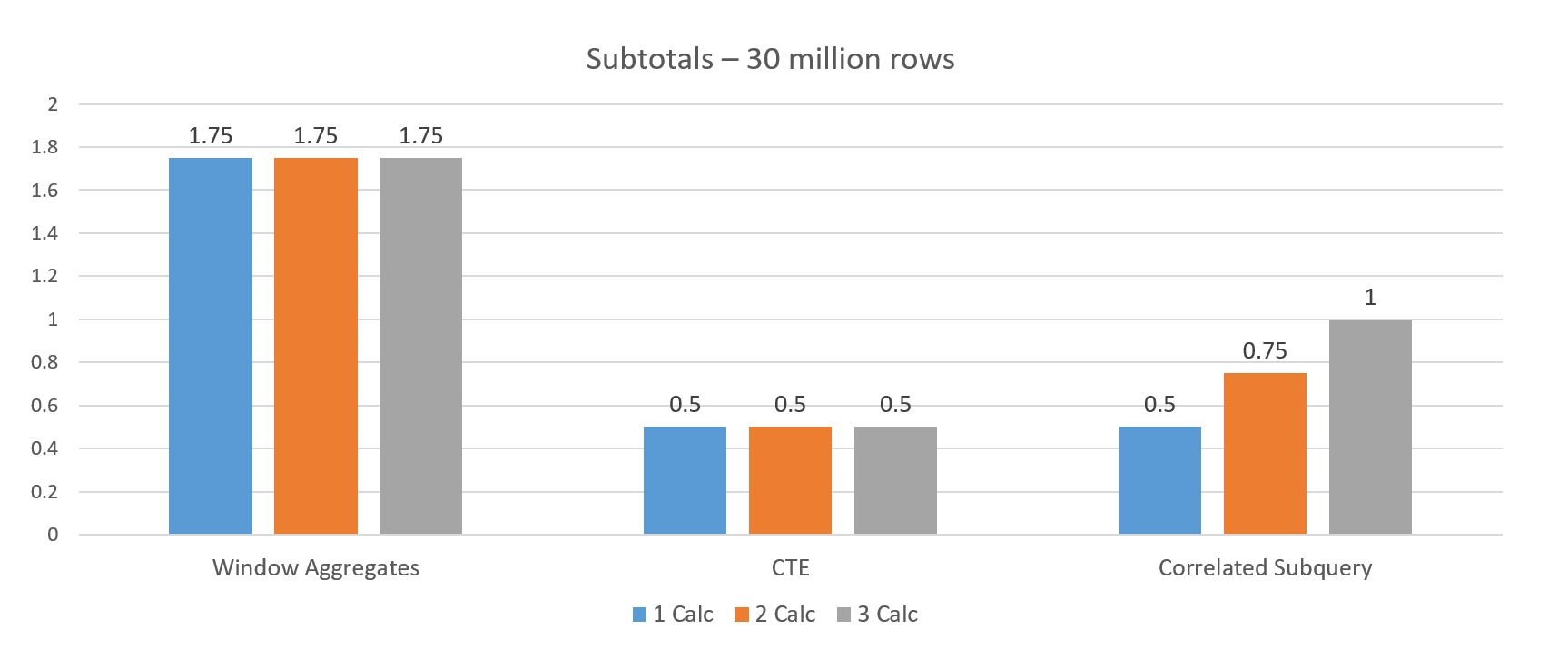
Производительность оконных агрегатов оказалась худшей – около 1,75 минут в каждом случае. CTE показал лучший результат при увеличении числа вычислений, поскольку таблица читалась только один раз для всех трех вычислений. Производительность коррелирующего подзапроса ухудшалась с увеличением числа вычислений, поскольку каждое вычисление должно было выполняться отдельно, что приводило к четырем обращениям к таблице.
Вот запрос-победитель:
WITH Calcs AS (
SELECT ProductID,
AVG(ActualCost) AS AvgCost,
MIN(ActualCost) AS MinCost,
MAX(ActualCost) AS MaxCost
FROM bigTransactionHistory
GROUP BY ProductID)
SELECT O.ProductID,
ActualCost,
AvgCost,
MinCost,
MaxCost
FROM bigTransactionHistory AS O
JOIN Calcs ON O.ProductID = Calcs.ProductID;
Заключение
Оконные функции T-SQL продвигались как средство значительного повышения производительности. На мой взгляд, они позволяют проще писать запросы. И вам следует их понимать, чтобы получить хорошую производительность. Индексирование имеет значение, но вы не можете создавать индекс для каждого запроса. Рамки сложнее понять, но это становится очень важным для больших таблиц.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой