
Пересмотр производительности оконных агрегатов в SQL Server 2019
Пересказ статьи Kathi Kellenberger. The Performance of Window Aggregates Revisited with SQL Server 2019
В 2005 и 2012 Майкрософт ввела в SQL Server большое число оконных функций, например, мою любимую функцию LAG. Эти функции отличает хорошая производительность, но главное преимущество их, на мой взгляд, состоит в простом написании сложных запросов. Я многие годы с удовольствием пользовалась этими функциями, однако одна вещь все же беспокоила меня - это производительность агрегатных оконных функций. К счастью, ситуация изменилась с приходом SQL Server 2019.
Что такое агрегатные оконные функции?
Агрегатные оконные функции позволяют вам добавлять ваши любимые агрегатные функции, типа SUM, AVG и MIN, в неагрегатные запросы. Это дает вам возможность возвращать детализированные данные наряду с общими или промежуточными итогами, или любые другие агрегаты, которые вам требуются. Вот пример:
USE AdventureWorks2017;
GO
SET STATISTICS IO ON;
GO
SELECT CustomerID, SalesOrderID, OrderDate, TotalDue
FROM Sales.SalesOrderHeader
ORDER BY CustomerID;
SELECT CustomerID, SalesOrderID, OrderDate, TotalDue,
SUM(TotalDue) OVER(PARTITION BY CustomerID) AS SubTotal
FROM Sales.SalesOrderHeader
ORDER BY CustomerID;
Я использую базу данных в режиме совместимости 2016 на запущенном SQL Server 2019 CTP 2.2. Первый запрос выводит список заказов продаж, а второй содержит также промежуточные итоги для каждого покупателя. Результаты представлены на рис.1.
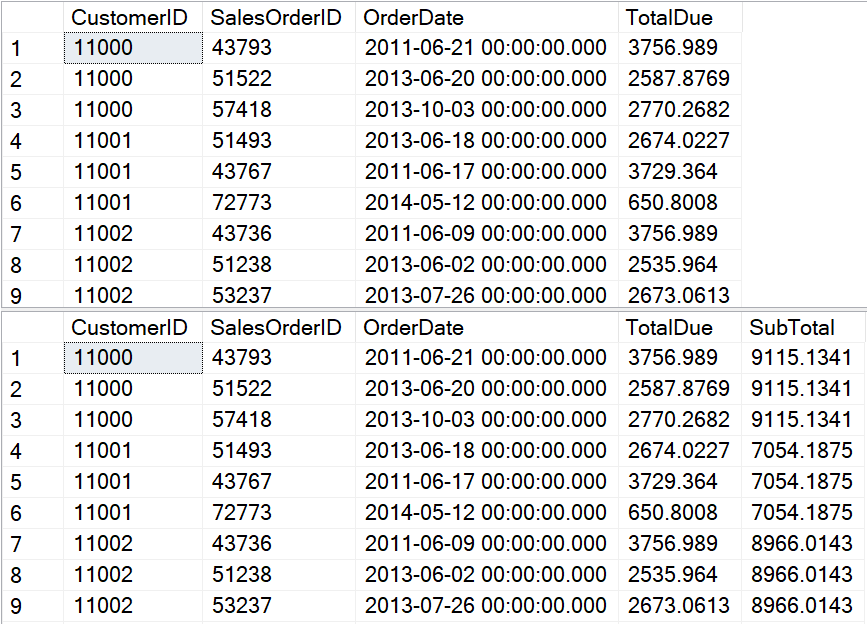 Рис.1 Фрагмент результатов запросов с отчетами о продажах
Рис.1 Фрагмент результатов запросов с отчетами о продажах
Я полагаю, что вы согласитесь насчет легкости вычисления промежуточных итогов. Вы просто должны добавить предложение OVER. В том случае, когда промежуточные итоги требуются для каждого покупателя, я включаю PARTITION BY CustomerID. Недостатком этого метода является неутешительная производительность. Действительно, я рекомендовала избегать оконных агрегатов при обработке большого числа строк. Чтобы показать то, что я имею в виду, взглянем на результаты STATISTICS IO на рис.2.
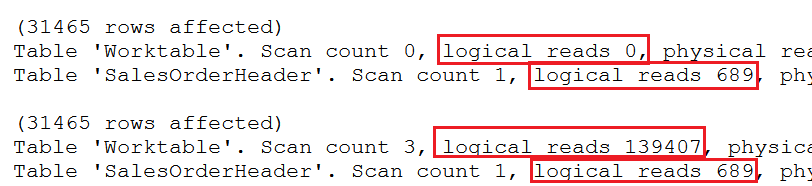 Рис.2 Логические чтения для запросов отчетов по продажам
Рис.2 Логические чтения для запросов отчетов по продажам
Первый запрос имеет 0 логических чтений для рабочей таблицы и 689 логических чтений для сканирования всей таблицы, поскольку предложение WHERE отсутствует. Второй запрос также имеет 689 логических чтений на сканирование таблицы и 139407 логических чтений из рабочей таблицы. Это огромная разница, но оказывают ли логические чтения из рабочей таблицы эффект на время выполнения запроса? Эти таблицы AdventureWorks слишком малы, чтобы увидеть влияние на производительность, но различие возникает, как вы увидите в следующей разделе.
Действительно ли производительность так плоха?
Чтобы показать, насколько оконные агрегаты ухудшают производительность, следующие запросы используют таблицы, созданные скриптом Адама Мечаника Thinking Big Adventure. Чтобы исключить влияние загрузки в SSMS (SQL Server Management Studio) на время выполнения, результаты сохраняются во временных таблицах. Вот два запроса, вычисляющих промежуточные итоги для каждого продукта в таблице, содержащей 31 миллион строк.
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
CREATE TABLE #Products(ProductID INT, TransactionDate DATETIME,
Total MONEY, SubTotal MONEY);
WITH SubTotalByProduct AS (
SELECT ProductID, SUM(Quantity * ActualCost) AS SubTotal
FROM bigTransactionHistory
GROUP BY ProductID)
INSERT INTO #Products (ProductID, TransactionDate, Total, SubTotal)
SELECT STP.ProductID, TransactionDate, Quantity * ActualCost AS Total,
SubTotal
FROM bigTransactionHistory AS BT
JOIN SubTotalByProduct AS STP ON BT.ProductID = STP.ProductID;
TRUNCATE TABLE #Products;
INSERT INTO #Products (ProductID, TransactionDate, Total, SubTotal)
SELECT ProductID, TransactionDate, Quantity * ActualCost AS Total,
SUM(Quantity * ActualCost)
OVER(PARTITION BY ProductID) AS SubTotal
FROM dbo.bigTransactionHistory;
DROP TABLE #Products;
Поскольку результаты сохраняются во временной таблице, выводится только STATISTICS IO и STATISTICS TIME. Первый запрос в этом примере демонстрирует один из традиционных методов получения промежуточных итогов при использовании CTE (общие табличные выражения), которое соединяется с исходной таблицей. Второй запрос производит те же результаты, но теперь с помощью оконной агрегатной функции.
Чтобы исключить эффект кэширования, я запускала запросы дважды. Статистику второго запуска вы можете увидеть на Рис.3.
 Рис.3 Результаты выполнения теста на таблице bigTransactionHistory
Рис.3 Результаты выполнения теста на таблице bigTransactionHistory
В первую очередь следует отметить, что традиционный метод отрабатывает за 35 секунд. Метод с оконной агрегатной функцией исполняется за 156 секунд или 2,2 минуты. Вы также можете видеть большую разницу в логических чтениях. Традиционный метод имеет в два раза больше логических чтений при сканировании таблицы. Это связано с тем, что доступ к таблице осуществляется один раз в СТЕ, а затем во внешнем запросе. Таблица сканировалась только один раз при использовании оконных агрегатов, но опять таки потребовалось значительно больше логических чтений из рабочей таблицы по сравнению с чтением просто из таблицы. Как видно, имеется большое падение производительности при использовании оконных агрегатов по сравнению с традиционными методами.
Пакетный режим к спасению
В 2016 Майкрософт анонсировал продвижение в характеристике индекса со столбцовым хранением, известной как обработка пакетного режима. Эта особенность также улучшает производительность запросов с оконными агрегатами, поскольку таблица с индексом столбцового хранения является частью запроса. Если это произошло естественным путем, замечательно! В противном случае, искусственное добавление индекса со столбцовым хранением кажется большей неприятностью, чем простое использование традиционного запроса.
Чтобы показать разницу в производительности, данный пример создает пустую временную таблицу со столбцовым индексом и добавляет его в запрос.
USE master;
GO
ALTER DATABASE AdventureWorks2017
--Гарантируем уровень совместимости 2016
SET COMPATIBILITY_LEVEL = 130 WITH NO_WAIT
GO
USE AdventureWorks2017;
GO
CREATE TABLE #Products(ProductID INT, TransactionDate DATETIME,
Total MONEY, SubTotal MONEY);
CREATE TABLE #CS(KeyCol INT NOT NULL PRIMARY KEY,
Col1 NVARCHAR(25));
CREATE COLUMNSTORE INDEX CSI_CS ON #CS(KeyCol, Col1);
INSERT INTO #Products (ProductID, TransactionDate, Total, SubTotal)
SELECT ProductID, TransactionDate, Quantity * ActualCost AS Total,
SUM(Quantity * ActualCost)
OVER(PARTITION BY ProductID) AS SubTotal
FROM dbo.bigTransactionHistory
OUTER APPLY #CS;
DROP TABLE #Products;
DROP TABLE #CS;
Чтобы увидеть преимущества изменений, сделанных в 2016, уровень совместимости базы данных был изменен на 2016. Наряду с упомянутым индексом была создана пустая таблица #CS. Она добавляется к запросу с помощью OUTER APPLY и не вляет на результаты.
Результаты производительности показаны на Рис.4:
 Рис.4 Включение индекса столбцового хранения для улучшения производительности
Рис.4 Включение индекса столбцового хранения для улучшения производительности
В этом тесте производительность была соизмерима с традиционным СТЕ-запросом. Это замечательно, но, на мой взгляд, главная причина использования оконных агрегатов это сделать запрос более простым для написания. Я не хочу вносить усложнение добавлением искусственного столбцового индекса. К счастью, в 2019 пакетная обработка строк применяется к некоторым запросам с оконными агрегатами, которые могут извлечь выгоду из этого без столбцового индекса! Эта возможность называется пакетный режим при построчном хранении (Batch Mode on Rowstore). Вот еще один тест, на этот раз для уровня совместимости 2019.
USE master;
GO
ALTER DATABASE AdventureWorks2017
--Установка совместимости с 2019
SET COMPATIBILITY_LEVEL = 150 WITH NO_WAIT
GO
USE AdventureWorks2017;
GO
CREATE TABLE #Products(ProductID INT, TransactionDate DATETIME,
Total MONEY, SubTotal MONEY);
INSERT INTO #Products (ProductID, TransactionDate, Total, SubTotal)
SELECT ProductID, TransactionDate, Quantity * ActualCost AS Total,
SUM(Quantity * ActualCost)
OVER(PARTITION BY ProductID) AS SubTotal
FROM dbo.bigTransactionHistory;
DROP TABLE #Products;
Теперь запрос выполняется за 15 секунд! Результаты производительности показаны на рис.5.
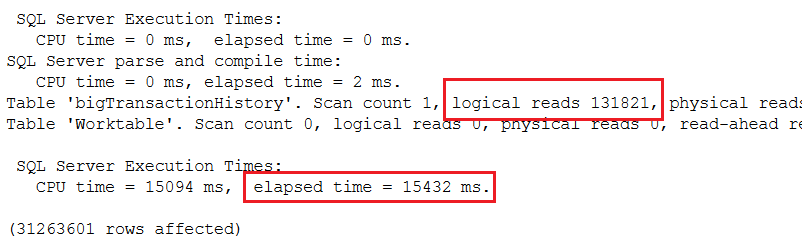 Рис.5 Использование возможности пакетного режима в 2019
Рис.5 Использование возможности пакетного режима в 2019
Аккумуляция агрегатов
Чтобы получить накопительные итоги, все, что нужно сделать - это добавить ORDER BY в предложение OVER в оконном агрегате. Это легко и даст вам ожидаемые результаты, если столбцы в спецификации ORDER BY предложения OVER уникальны. Для существенного роста производительности вам необходимо добавить фрейм (ROWS BETWEEN UNBOUND PROCEEDING AND CURRENT ROW) в предложение OVER. Это интуитивно понятно, но, вероятно, чаще не учитывается, чем включается. Для демонстрации разницы этот тест сравнивает использование фрейма и неиспользование его в режиме совместимости 2016.
USE master;
GO
ALTER DATABASE AdventureWorks2017
SET COMPATIBILITY_LEVEL = 130 WITH NO_WAIT
GO
USE AdventureWorks2017;
GO
CREATE TABLE #Products(TransactionID INT, ProductID INT,
TransactionDate DATETIME,
Total MONEY, RunningTotal MONEY);
INSERT INTO #Products (TransactionID, ProductID, TransactionDate,
Total, RunningTotal)
SELECT TransactionID, ProductID, TransactionDate,
Quantity * ActualCost,
SUM(Quantity * ActualCost)
OVER(PARTITION BY ProductID ORDER BY TransactionID)
FROM bigTransactionHistory;
TRUNCATE TABLE #Products;
INSERT INTO #Products (TransactionID, ProductID, TransactionDate,
Total, RunningTotal)
SELECT TransactionID, ProductID, TransactionDate,
Quantity * ActualCost,
SUM(Quantity * ActualCost)
OVER(PARTITION BY ProductID ORDER BY TransactionID
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
FROM bigTransactionHistory;
DROP TABLE #PRODUCTS
Результаты при использовании режима совместимости 2016 можно увидеть на рис.6.
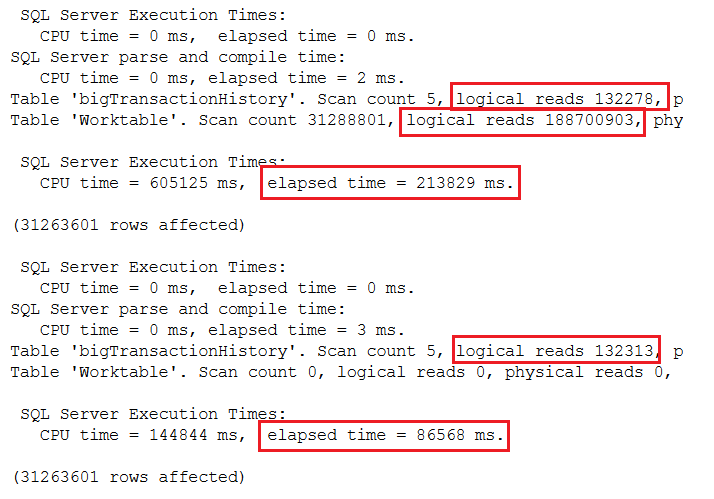 Рис.6 Сравнение результатов, использующих фрейм при режиме совместимости 2016
Рис.6 Сравнение результатов, использующих фрейм при режиме совместимости 2016
При использовании фрейма выполнение запроса снизилось с почти 4 минут до 1.4 минут. Ниже тот же самый тест только для уровня совместимости 2019, чтобы оценить преимущество обработки в пакетном режиме.
USE master;
GO
ALTER DATABASE AdventureWorks2017
SET COMPATIBILITY_LEVEL = 150 WITH NO_WAIT
GO
USE AdventureWorks2017;
GO
CREATE TABLE #Products(TransactionID INT, ProductID INT,
TransactionDate DATETIME,
Total MONEY, RunningTotal MONEY);
INSERT INTO #Products (TransactionID, ProductID, TransactionDate,
Total, RunningTotal)
SELECT TransactionID, ProductID, TransactionDate,
Quantity * ActualCost,
SUM(Quantity * ActualCost)
OVER(PARTITION BY ProductID ORDER BY TransactionID)
FROM bigTransactionHistory;
TRUNCATE TABLE #Products;
INSERT INTO #Products (TransactionID, ProductID, TransactionDate,
Total, RunningTotal)
SELECT TransactionID, ProductID, TransactionDate,
Quantity * ActualCost,
SUM(Quantity * ActualCost)
OVER(PARTITION BY ProductID ORDER BY TransactionID
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
FROM bigTransactionHistory;
DROP TABLE #Products;
В пакетном режиме нет падения производительности при отсутствии фрейма. В каждом случае запрос выполняется менее чем за 30 секунд, даже быстрей, чем при использовании фрейма в 2016. Конечно, вам придется включать фрейм в вариантах, отличных от принимаемых по умолчанию. (Смотрите мою статью Introduction to T-SQL Window Functions, чтобы узнать больше.) На рис.7 показаны результаты производительности.
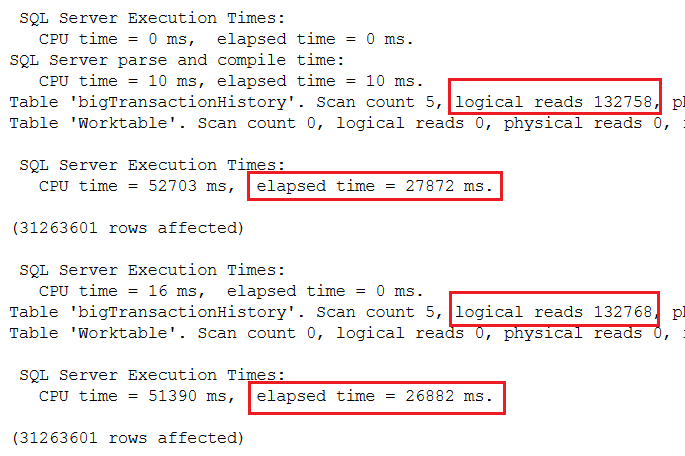 Рис.7 Результаты использования режима совместимости 2019 для вычисления накопительных итогов
Рис.7 Результаты использования режима совместимости 2019 для вычисления накопительных итогов
Пакетный режим для обработки построчного хранения
Как вы можете видеть, этот новый пакетный режим с использованием построчного хранения резко улучшает производительность этих двух запросов с оконными функциями. Мои запросы выполнялись примерно в 7 раз быстрей, но ваши результаты могут отличаться. Как работает пакетный режим? Он разбивает обработку на 900 кусков. SQL Server применяет этот режим для запросов с агрегацией и сортировками при сканировании большого числа строк. Это одно из ряда улучшений в обработке запросов, доступных в 2019 и названных "интеллектуальная обработка запросов".
Возможно, вам интересно узнать, используется ли пакетная обработка для вашего запроса. Если вы посмотрите на план выполнения, то сможете увидеть разницу. На рис.8 показан план выполнения для запроса с промежуточными итогами, выполненного в режиме совместимости 2016. Чтобы было легче увидеть, я разбила изображение на 2 фрагмента. На верхнем показана левая часть плана, а на нижнем - правая сторона.
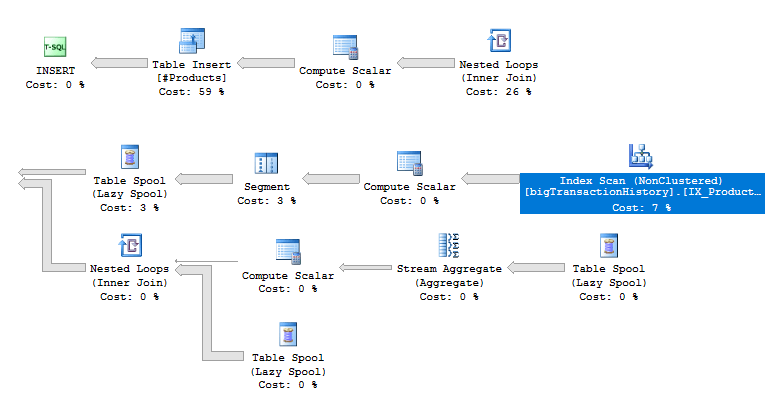 Рис.8 План выполнения для промежуточных итогов в режиме совместимости 2016
Рис.8 План выполнения для промежуточных итогов в режиме совместимости 2016
Первое, что интересно отметить, это то, что параллелизм не используется, хотя кажется, что он мог бы быть полезным в запросе 31 миллиона строк. Было бы возможным переписать запрос в такой форме, чтобы заставить оптимизатор распараллелить запрос, но это тема для будущей статьи.
Также отметим операторы Table Spool. Это рабочие таблицы, которые вы видели в выводе STATISTICS IO. Они соединяются с результатами с помощью Nested Loops (вложенных циклов).
Если открыть свойства оператора Index Scan (сканирование индекса - рис.9), то увидите, что хранением является Rowstore (построчное), и Actual Execution Mode (фактический режим выполнения) есть Row (строка).
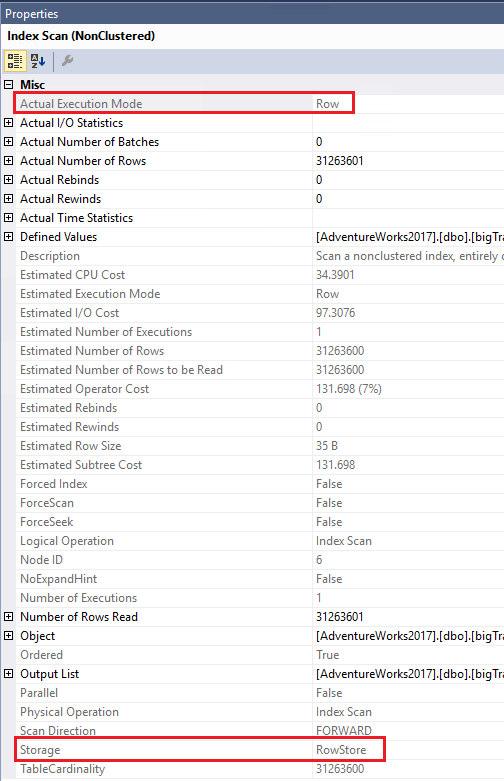 Рис.9 Свойства, показывающие режим Row
Рис.9 Свойства, показывающие режим Row
Теперь посмотрим на план выполнения на рис.10 для того же запроса, но в режиме совместимости 2019. Я снова разбила его для облегчения чтения.
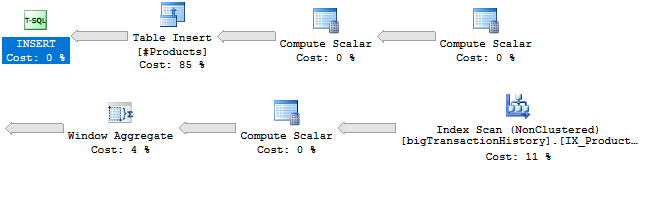 Рис.10 План, используемый в режиме совместимости 2019
Рис.10 План, используемый в режиме совместимости 2019
Во-первых, вы, вероятно, заметили, что этот план выглядит много проще. Здесь больше нет рабочих таблиц (Table Spool) и нет необходимости в Nested Loops. Появился также новый оператор Window Aggregate. Поместив курсор над этим оператором, получим информацию, показанную на рис.11.
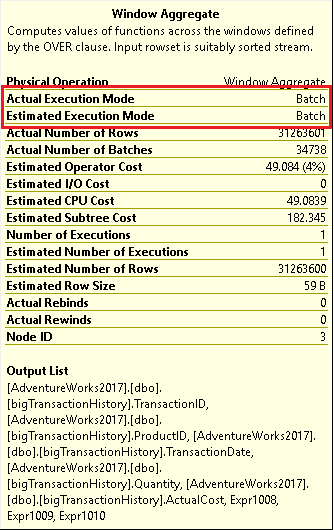
Рис.11 Окно оператора Window Aggregate
Вы можете увидеть, что использовался пакетный режим. В свойствах Index Scan на рис.12 можно увидеть, что пакетный режим использовался, хотя индекс хранится построчно (rowstore), а не поколоночно (columnstore).
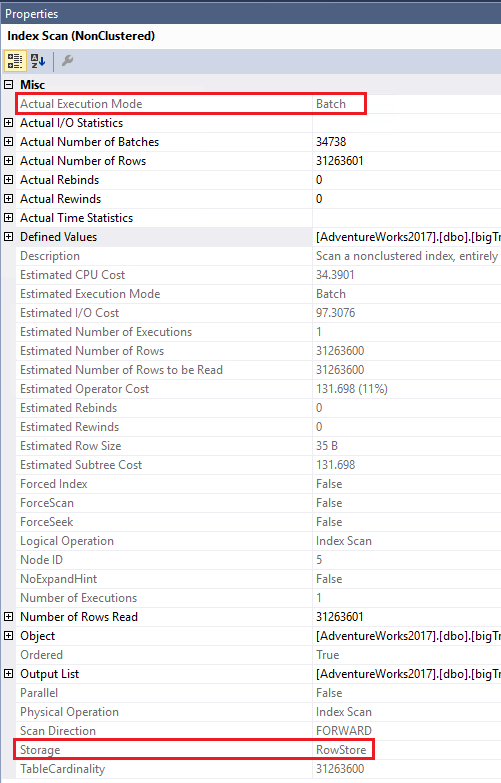
Рис.12 Свойства оператора Index Scan
Как упоминалось ранее, пакетный режим при построчном хранении применяется для запросов на больших объемах, которые включают такие действия, как сортировка или агрегация. Мне было интересно, где находится точка перехода для этого запроса, поэтому я решила создать копию bigTransactionHistory с теми же идексами, но просто меньшим числом случайных строк. Выяснилось, что точкой перехода было 131072 строк для этого запроса на экземпляре, запущенном на Azure VM. Это значение может вполне отличаться в другой ситуации.
Заключение
Многие организации не выполняют апгрейд сразу, как только появляется новая версия SQL Server. Они делают апгрейд через несколько версий. Я думаю, что каждый может оценить новую оптимизацию запросов. Пакетный режим при построчном хранении - только одна из многих больших возможностей, которые улучшат производительность только при переходе на 2019.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой