
Внутри оптимизатора: оценка стоимости плана
Пересказ статьи Paul White. Inside the Optimizer: Plan Costing
Оптимизатор SQL Server генерирует множество физических альтернатив плана на основе логических требований, выраженных на T-SQL. Если требуется полная оптимизация на основе стоимости, стоимость назначается каждому итератору в каждом альтернативном плане, и, в конечном счете, план с наименьшей общей стоимостью выбирается для исполнения.
Подробно об оценке стоимости
Графический план выполнения показывает общую оценку стоимости итератора, а также стоимость его составляющих - I/O (ввод/вывод) и CPU (процессор):
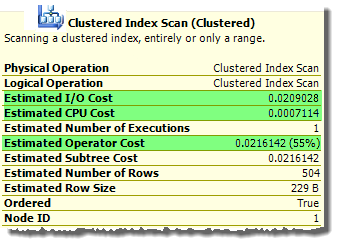
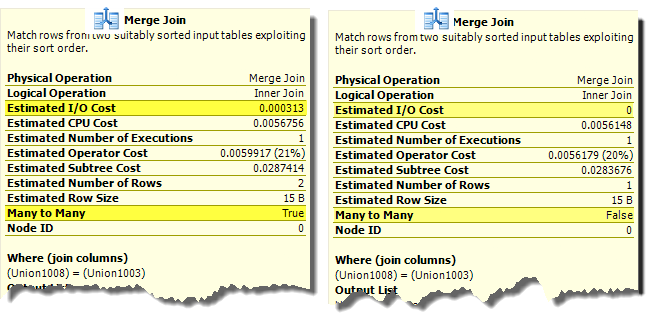
В простейших случаях (как показанный выше) общая оценка стоимости итератора есть простая сумма компонент I/O и CPU. В других обстоятельствах окончательная стоимость может быть модифицирована другими соображениями - например, как результат row goal. Стоимость I/O и CPU вычисляются на основе оценки числа строк, размера данных, статистической информации и типа итератора. Итераторы могут также оцениваться по-разному в зависимости от контекста. Например, итератор Merge Join имеет нулевую оценку стоимости I/O при выполнении соединения "один к многим". При выполнении режима "многие-ко-многим" требуется рабочая таблица в базе tempdb, и появляется соответствующая стоимость I/O:
Значения стоимости представляют ожидаемые времена выполнения (в секундах) на специфической конфигурации аппаратных средств. Заинтересованный читатель может найти углубленное рассмотрение некоторых "волшебных чисел", используемых элементами оценки стоимости в блестящей статье Джо Чанга (Joe Chang), у которого тоже есть блог на сайте sqlblog.com. Важно не относиться к числам стоимости буквально. Они возникают из математической модели, используемой для последовательного сравнения альтернативных планов. На практике, естественно, ваш сервер имеет совершенно отличные характеристики от принятых в модели. К счастью, они не имеют особого значения, поскольку представляют собой относительную стоимость плана, которая приводит к выбору окончательного плана. Если углубиться в детали, то модель оценки стоимости делает ряд упрощающих предположений, отдающих приоритет скорости и последовательности по сравнению с более точным отражением реальности. Хорошим примером сказанного является то, что вычисление стоимости предполагает запуск выполнения всех запросов с непрогретым кэшем.
Зачем использовать модель на основе стоимости?
Рассмотрим задачу выбора между возможными физическими реализациями операции join. Большинство людей знает, что Nested Loops является хорошим выбором, когда оба входных потока относительно невелики, Merge хорошо работает в соответствующим образом упорядоченных средах с большими входами, а Hash особенно подходит для очень больших соединений с параллельным планом выполнения. Одним из оптимизационных приемов является кодирование подробного набора правил на основе подобных рассуждений. Он известен как оптимизация на основе правил, которая применялась в большом числе продуктов баз данных в течение многих лет. Однако опыт показал, что схемам на основе правил не хватает гибкости и расширяемости: ввод нового итератора или возникновение новой характеристики базы данных, например, может потребовать большого числа новых правил, а также пересмотра существующих.
Альтернативным подходом является оптимизация на основе стоимости, опирающаяся на общую, относительно абстрактную модель. Добавление нового итератора просто сводится к встраиванию требуемых интерфейсов в существующую модель, повторно используя функциональность, которая обеспечивает информацию на базе стоимости (например, стоимость чтения страницы с диска), и контекстные данные (подобных оценке числа строк и среднего размера строки). Использование такого более объектно-ориентированного подхода и относительно простых правил оценки стоимости позволяет смоделировать сложное поведение. Например, Nested Loops может быть смоделировано без стоимости запуска и относительно высокой стоимостью на каждую строку. Hash Join может быть дана значительная стоимость запуска (на построение своей хэш-таблицы), но с низкой последующей стоимостью на строку. В каждом случае на точную стоимость может в дальнейшем оказать влияние размер строки и информация о распределении значений - ключевым моментом является контекстная зависимость и динамичность стоимости.
Пример расчета оценки стоимости
Давайте рассмотрим запрос, который возвращает количество продуктов на складе AdventureWorks, названия которых начинаются с пяти первых букв алфавита:
SELECT
p.Name,
total_qty = SUM(inv.Quantity)
FROM Production.Product AS p WITH (INDEX(AK_Product_Name))
JOIN Production.ProductInventory AS inv ON
inv.ProductID = p.ProductID
WHERE
p.Name LIKE '[A-E]%'
GROUP BY
p.Name;
Мы получим следующий план, в котором SQL Server вычисляет SUM(Quantity) для всех продуктов и соединяет (merge-join) эти результаты с продуктами, чьи названия начинаются на A-E (я использовал индексный хинт, чтобы гарантировать, что вы получите точно такой же план у себя):
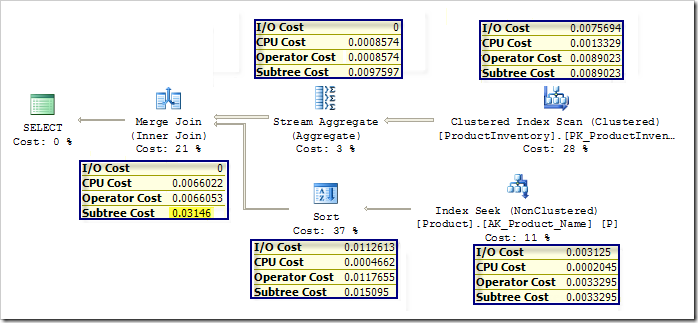
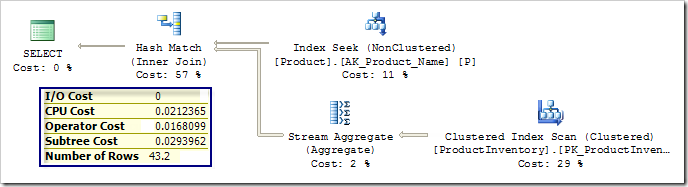
Я намеренно хотел показать план, в котором общая стоимость почти каждого итератора (Operator Cost) оказывается равной сумме стоимости I/O и CPU. Лишь итераторы Sort и Merge Join имеют небольшие дополнительные накладные расходы: Sort добавляет 0.000038, а Merge Join - 0.0000031. Осталось отметить, что каждый итератор знает суммарную стоимость всех нижеследующих итераторов (стоимость его поддерева). Давайте теперь навяжем план с соединением вложенными циклами этому же запросу и сравним стоимость:
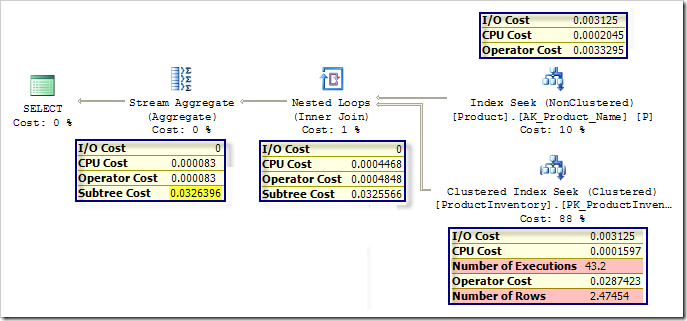
Посмотрев на выделенную цветом стоимость поддерева верхнего уровня, мы можем заметить, что этот план лишь немного дороже в целом эквивалентного плана с Merge, что объясняет выбор оптимизатора. Мы также можем увидеть, что Stream Aggregate и Nonclustered Index Seek имеют стоимость оператора равную сумме стоимости I/O и CPU. Итератор Nested Loops добавляет небольшие накладные расходы 0.000038 к стартовой стоимости CPU. Расчеты стоимости Clustered Index Seek (поиск в кластеризованном индексе) несколько сложней.
Расчет стоимости Clustered Index Seek
Стоимость CPU
Рассчитанная стоимость CPU равна 0.0001581 для первой строки и 0.000011 для последующих строк. В этом случае SQL Server ожидает, что каждое выполнение Clustered Index Seek даст 2.47454 строк, отсюда стоимость CPU составляет 0.0001581 (для первой строки) плюс 1.47454*0.000011 (для остальных). Эти вычисления делают CPU cost равной 0.0001597, что видно на плане.
Последний вклад в стоимость CPU получен умножением стоимости одного выполнения на предполагаемое число вычислений. В данном случае SQL Server ожидает, что поиск по индексу на таблице Product даст 43.2 строки, поэтому окончательная стоимость Clustered Index Seek равна 43.2*0.0001597, что составляет 0.00689904.
Стоимость I/O
Стоимость I/O 0.003125 или, если точно, 1/320 отражает предположение модели, что дисковая подсистема может производить 320 случайных операций ввода/вывода в секунду (каждое извлечение 8-килобайтной страницы). Эта оценка снова должна модифицироваться с учетом ожидаемых 43.2 выполнений. Однако компонента расчета стоимости достаточно интеллектуальна, чтобы определить, что общее число страниц, которые требует извлечь с диска, никогда не превышает числа страниц, требуемых для хранения таблицы целиком. Таблица Product Inventory использует только 7 страниц, моделируемая общая стоимость ввода-вывода приблизительно равна 7 * 0.003125, что дает 0.021875.
Общая стоимость оператора
Сложив стоимости CPU и I/O, мы получим полную стоимость оператора 0.02877404. Это не вполне соответствует стоимости 0.02877404, показанной на плане, поскольку я немного упростил вычисления ради простоты описания процесса.
Недокументированные возможности
До сих пор мы видели, как стоимость CPU и I/O влияла на выбор плана. Я хочу вам показать пару недокументированных возможностей, которые позволяют изменить вычисления стоимости I/O и CPU. Как обычно, это предлагается только с целью обучения и развлечения - никогда не используйте эти инструменты кроме как для персональной тестовой системы.
Имеется две недокументированные DBCC команды, SETCPUWEIGHT и SETIOWEIGHT, которые применяют множитель к значениям стоимости, обычно производимым компонентами расчета стоимости. По умолчанию оба множителя установлены в 1, что дает немодифицированную стоимость для CPU и I/O, которую вы обычно видите. Каждая команда имеет единственный параметр типа вещественного чиста с плавающей точкой. Простейший способ задать литеральную константу числа с плавающей точкой - это выразить её в научной нотации. Третью недокументированную команду DBCC, SHOWWEIGHTS, можно использовать для вывода эффективных настроек для текущей сессии. Как правило, нам потребуется установить флажок трассировки 3604, чтобы увидеть вывод этих DBCC команд (который появляется в окне сообщений SSMS). Скажем, мы хотим увидеть эффект удешевления I/O. Мы можем установить базовую стоимость I/O в 60% от её значения по умолчанию, выполнив такую команду:
DBCC TRACEON (3604); -- Показать вывод DBCC
DBCC SETCPUWEIGHT(1E0); -- Вес CPU по умолчанию
DBCC SETIOWEIGHT(0.6E0); -- множитель I/O = 0.6
DBCC SHOWWEIGHTS; -- Показать установки
Если теперь мы выполним запрос, используемый в примере расчета стоимости, то обнаружим, что оптимизатор выбрал план с nested loops, поскольку теперь он имеет более низкую общую стоимость, чем план с Merge join. Мы можем достичь того же эффекта увеличением веса CPU в 1.7 раза, восстановив множитель стоимости I/O в 1. Мы можем получить план на основе Hash join понижением коэффициента стоимости CPU ниже 0.8 или повышением множителя стоимости I/O до 1.3:
Отличный способ понять, как работает компонент расчета стоимости и оптимизатор в целом, поиграть с этими настройками. Особо интересна комбинация, когда оба множителя стоимости установлены в нуль. Это может заставить оптимизатор показать его внутреннюю работу, как в следующем примере:
SELECT
ps.Name,
cnt = COUNT_BIG(*)
FROM Production.ProductSubcategory AS ps
JOIN Production.Product AS p ON
p.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE
EXISTS
(
SELECT SQRT(PI())
FROM Production.ProductInventory AS inv
WHERE
inv.ProductID = p.ProductID
AND inv.Shelf = N'A'
)
GROUP BY
ps.Name;
С установленными в нуль обоими множителями оптимизатор строит план, содержащий три последовательных сортировки:
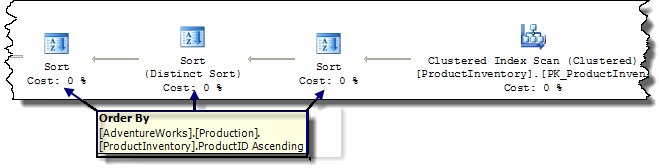
Обратите внимание, что все три сортировки выполняются одинаково, и стоимость каждой равна 0. Лишние сортировки - это результат применения правил движка, которые обычно удаляются из окончательного плана другими правилами. Установка множителей стоимости в нуль лишает нас этого преимущества. Поиграйтесь с этим, но не забудьте восстановить все к значениям по умолчанию, когда вы закончите свои эксперименты.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой