
Почему не следует использовать SELECT * в рабочих системах (никогда!)
Пересказ статьи Gavin Draper. Why You Shouldn't Use SELECT * In Production Systems (EVER!)
Это не значит, что я никогда не использую операторы SELECT *; обычно я использую их для прямых запросов на стадии разработки. Моё предупреждение относится к их использованию в рабочих системах.
Здесь я хочу рассмотреть несколько потенциально возможных неожиданных проблем, к которым может привести подобный оператор. Как обычно, в примерах я использую базу данных Stack Overflow Database.
Все демонстрационные запросы выполнялись на SQL Server 2017; результаты могут различаться при использовании других версий из-за различий в статистике и выборе оптимизатора.
Теперь предположим, что мы должны получить id, DisplayName и Location для всех пользователей, которые последний раз заходили во временном интервале между 2008-01-01 и 2008-01-31...
Создадим еще одну процедуру, которая делает то же самое, но использует SELECT *.
Давайте немного поможем себе и создадим индекс для нашего отчета...
Этот индекс полностью покрывает наш первый запрос (тот, который не SELECT *). При этом уже имеется кластеризованный индекс на ID, поэтому нам не нужно помещать идентификатор в наш индекс (смотрите статью Waiter Waiter. Какой-то индекс в моем индексе).
Перейдем теперь к проблемным сценариям...
Очевидно, что чем больше данных возвращают наши запросы, тем больше операций ввода/вывода выполняется. Можно попробовать списать это на пару дополнительных полей, однако давайте проверим это. Если мы включим статистику IO и выполним наш запрос, который НЕ SELECT *...

Практически мгновенный ответ с очень небольшим числом чтений страниц. Теперь давайте посмотрим на нашу версию SELECT *
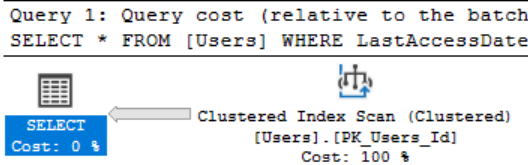
4 чтения по сравнению с 44530; при условии, что извлекаются 8-килобайтный страницы, мы пришли от чтения 32Кб к 347Мб! Сравнив планы, можно увидеть, что это связано с тем, что SQL Server не использовал наш индекс, а выполнял полное сканирование кластеризованного индекса. Это произошло потому, что поиски закладок всех полей, отсутствующих в индексе, стало бы более дорогой операцией, чем просто считать всю таблицу.
В вышеупомянутом примере я преднамеренно создал индекс под версию НЕ SELECT *, поэтому давайте сейчас создадим другой индекс для SELECT *...
Теперь мы имеем другую полную копию нашей таблицы, чтобы покрыть весь запрос SELECT *. Для сравнения, этот индекс имеет размер 347Мб против 115Мб нашего прежнего индекса. Если мы опять выполним нашу процедуру SELECT * ...
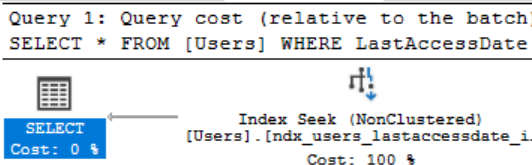
Мы видим, что сейчас получили использование поиска по нашему новому индексу, а не полное сканирование кластеризованного индекса, что дало в результате то же самое число чтений, как и для версии НЕ SELECT * (SQL Server читает за раз 8Кб, поэтому другая версия возвращает некоторое пустое пространство на этих страницах, следовательно, обеим версиям требуется только 4 чтения, чтобы вернуть разное количество данных). Однако это приводит к росту стоимости за счет намного более дорогой поддержки и хранения индекса.
Предположим теперь, что кто-то добавил в таблицу флаг для отключения пользователя. Сколько вреда может принести единственное поле типа BIT?
Давайте теперь снова запустим каждый из наших запросов, и посмотрим, к чему это приведет...
Тут все еще хорошо, 4 чтения и мы по-прежнему используем наш индекс. Теперь для версии SELECT *...
Ох, наш точно настроенный под SELECT * индекс больше не используется! Все, что было сделано - это добавление единственного битового поля, а нас отбросило назад к чтению 44530 страниц! Вместо 32Кб получили 347Мб только из-за добавления битового поля! Вывод: не важно, как вы спроектировали ваш индекс для запроса SELECT *, он не будет использоваться при любом незначительном добавлении в схеме таблицы и, помимо этого, мы будем еще платить за поддержку неиспользуемого индекса.
Давайте теперь рассмотрим сценарий, когда добавление поля все же допустит использование нашего индекса, но с другим побочным эффектом. Внесем небольшое изменение в нашу процедуру, чтобы результат возвращался отсортированным по LastAccessDate. Этого изменения достаточно, чтобы оптимизатор захотел использовать наш индекс, даже если он не содержит нового битового столбца, который мы добавили на предыдущем шаге...
Запрос НЕ SELECT * по-прежнему дает прежнее число чтений. Однако версия SELECT * несколько отличается...
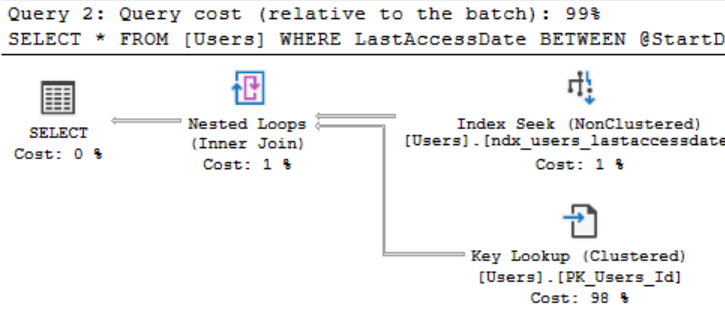
Теперь мы возвращаемся к использованию нашего индекса, и число чтений сильно сократилось, но оно все еще весьма превышает те 4 чтения, которые мы имели прежде, поскольку для каждой строки, которую мы получаем, выполняется поиск закладки в кластеризованном индексе, чтобы извлечь наше новое поле. Нынешняя 141 строка не так много, и это, вероятно, не скажется на времени выполнения, но увеличит его, если будет возвращаться больше строк и, скорее всего, существенно больше полей, которые нам не нужны, и это может обойтись в итоге очень дорого.
Сортировка является для SQL Server одной из наиболее расточительных операций по отношению к памяти. Одна из вещей, о которой забывают, заключается в том, что когда вы сортируете набор данных, вы перемещаете все поля в строке, и чем больше полей в строке, тем больше памяти требует сортировка. Давайте немного изменим наши запросы, добавив сортировку по неиндексированному полю, чтобы вызвать операцию сортировки...
Ни один из этих запросов не является сейчас специально оптимизированным, т.к. оба они сортируются по полю, которое не является индексированным. Однако давайте просто посмотрим, насколько один хуже другого...
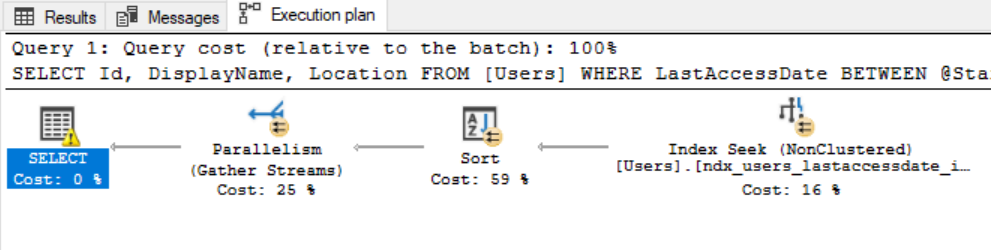
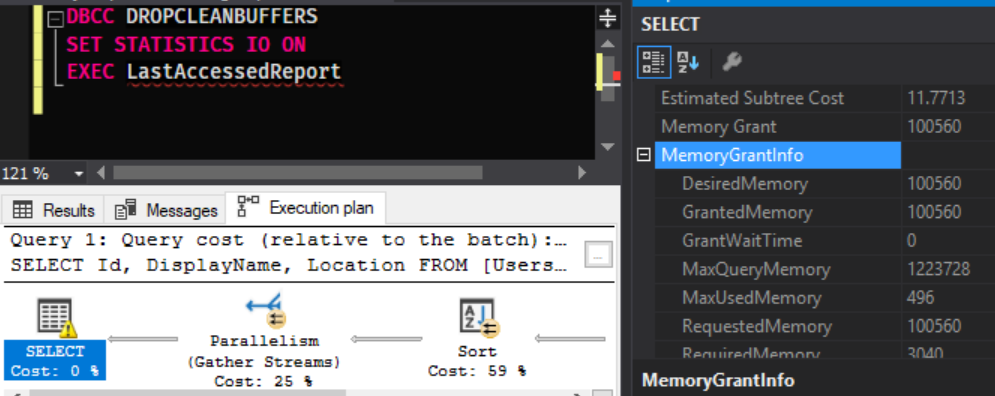
Наш запрос НЕ SELECT * потребляет 100Мб памяти для выполнения сортировки. Теперь сравним с версией SELECT *...
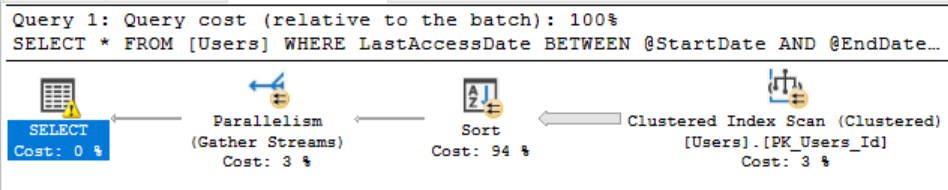
Мы вернулись к полному сканированию кластеризованного индекса, т.к. теперь это считается более дешевым вариантом по сравнению с поиском закладок, поскольку мы теперь не получаем преимущества от порядка, в котором выполнена сортировка индекса. Однако если мы взглянем на память...
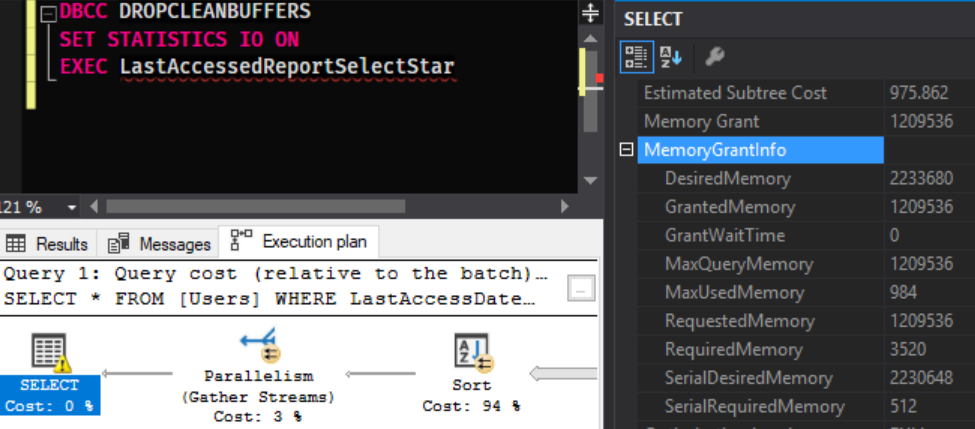
Наш запрос запросил 2.1Гб памяти, из которых предоставляется только 1.2Гб. Нам теперь требуется много больше пространства для сортировки данных за счет всех этих лишних полей, которые нам даже не нужны. Ситуация будет становиться только хуже с каждым добавленным в таблицу столбцом, и стать невероятной при добавлении больших полей. Я видел запросы на более 60Гб в некоторых довольно экстремальных случаях, когда более точно написанная версия того же запроса требовала менее 200Мб.
Та же логика справедлива и для соединений типа Hash Match, когда в запросе используется несколько таблиц.
Когда вы используете в запросе SELECT * с соединением нескольких таблиц, становится весьма сложно различать, какие поля из каких таблиц берутся. Когда я начал соединять таблицы, я указывал имя таблицы для каждого поля, чтобы упростить отладку и работу с кодом в дальнейшем, например:
Уяснив проблему, довольно просто перестать использовать такие запросы в будущем, однако устранение SELECT * из существующего проекта много сложнее, т.к. к этому времени вы, вероятно, уже не помните, какие поля используются в вызывающем приложении.
Только единственный аргумент я слышал в пользу применения SELECT * - это сокращение набора/поддержки в коде. Учитывая тот негатив, который это дает, я предпочту лишнюю работу. Нельзя сказать, что это всегда безопасно, что ваша таблица никогда не будет изменяться. Все подвержено изменениям, только я думаю, что эти ситуации являются исключениями, и мы никогда не можем предсказать то, что случится потом.
Поскольку всегда имеются исключения, правда? Я всегда пытаюсь избегать этого, но если вы настаиваете на использовании SELECT *, то ниже приводятся несколько ситуаций, которые вряд ли удовлетворят вас:
Все демонстрационные запросы выполнялись на SQL Server 2017; результаты могут различаться при использовании других версий из-за различий в статистике и выборе оптимизатора.
Установка
Теперь предположим, что мы должны получить id, DisplayName и Location для всех пользователей, которые последний раз заходили во временном интервале между 2008-01-01 и 2008-01-31...
CREATE PROCEDURE LastAccessedReport
AS
DECLARE @StartDate DATETIME = '20080801'
DECLARE @EndDate DATETIME = '20080831'
SELECT
Id,
DisplayName,
Location
FROM
[Users]
WHERE
LastAccessDate BETWEEN @StartDate AND @EndDate
ORDER BY LastAccessDate
Создадим еще одну процедуру, которая делает то же самое, но использует SELECT *.
CREATE PROCEDURE LastAccessedReportSelectStar
AS
DECLARE @StartDate DATETIME = '20080801'
DECLARE @EndDate DATETIME = '20080831'
SELECT
*
FROM
[Users]
WHERE
LastAccessDate BETWEEN @StartDate AND @EndDate
ORDER BY LastAccessDate
Давайте немного поможем себе и создадим индекс для нашего отчета...
CREATE INDEX ndx_users_lastaccessdate_include_display_location
ON dbo.Users(LastAccessDate)
INCLUDE(DisplayName,Location)
Этот индекс полностью покрывает наш первый запрос (тот, который не SELECT *). При этом уже имеется кластеризованный индекс на ID, поэтому нам не нужно помещать идентификатор в наш индекс (смотрите статью Waiter Waiter. Какой-то индекс в моем индексе).
Перейдем теперь к проблемным сценариям...
Рост IO
Очевидно, что чем больше данных возвращают наши запросы, тем больше операций ввода/вывода выполняется. Можно попробовать списать это на пару дополнительных полей, однако давайте проверим это. Если мы включим статистику IO и выполним наш запрос, который НЕ SELECT *...
DBCC DROPCLEANBUFFERS
SET STATISTICS IO ON
EXEC LastAccessedReport
(42 rows affected) Table ‘Users’. Scan count 1, logical reads 4
Практически мгновенный ответ с очень небольшим числом чтений страниц. Теперь давайте посмотрим на нашу версию SELECT *
DBCC DROPCLEANBUFFERS
SET STATISTICS IO ON
EXEC LastAccessedReportSelectStar
(42 rows affected) Table ‘Users’. Scan count 1, logical reads 44530
4 чтения по сравнению с 44530; при условии, что извлекаются 8-килобайтный страницы, мы пришли от чтения 32Кб к 347Мб! Сравнив планы, можно увидеть, что это связано с тем, что SQL Server не использовал наш индекс, а выполнял полное сканирование кластеризованного индекса. Это произошло потому, что поиски закладок всех полей, отсутствующих в индексе, стало бы более дорогой операцией, чем просто считать всю таблицу.
Индексы, которые не используются
В вышеупомянутом примере я преднамеренно создал индекс под версию НЕ SELECT *, поэтому давайте сейчас создадим другой индекс для SELECT *...
CREATE INDEX ndx_users_lastaccessdate_include_everything
ON dbo.Users(LastAccessDate)
INCLUDE(
AboutMe, Age, CreationDate, DisplayName,
DownVotes, EmailHash, Location, Reputation,
UpVotes, Views, WebsiteUrl, AccountId)
Теперь мы имеем другую полную копию нашей таблицы, чтобы покрыть весь запрос SELECT *. Для сравнения, этот индекс имеет размер 347Мб против 115Мб нашего прежнего индекса. Если мы опять выполним нашу процедуру SELECT * ...
DBCC DROPCLEANBUFFERS
SET STATISTICS IO ON
EXEC LastAccessedReportSelectStar
(42 rows affected) Table ‘Users’. Scan count 1, logical reads 4
Мы видим, что сейчас получили использование поиска по нашему новому индексу, а не полное сканирование кластеризованного индекса, что дало в результате то же самое число чтений, как и для версии НЕ SELECT * (SQL Server читает за раз 8Кб, поэтому другая версия возвращает некоторое пустое пространство на этих страницах, следовательно, обеим версиям требуется только 4 чтения, чтобы вернуть разное количество данных). Однако это приводит к росту стоимости за счет намного более дорогой поддержки и хранения индекса.
Предположим теперь, что кто-то добавил в таблицу флаг для отключения пользователя. Сколько вреда может принести единственное поле типа BIT?
ALTER TABLE [Users] ADD [Enabled] BIT
Давайте теперь снова запустим каждый из наших запросов, и посмотрим, к чему это приведет...
DBCC DROPCLEANBUFFERS
SET STATISTICS IO ON
EXEC LastAccessedReport
(42 rows affected) Table ‘Users’. Scan count 1, logical reads 4
Тут все еще хорошо, 4 чтения и мы по-прежнему используем наш индекс. Теперь для версии SELECT *...
DBCC DROPCLEANBUFFERS
SET STATISTICS IO ON
EXEC LastAccessedReportSelectStar
(42 rows affected) Table ‘Users’. Scan count 1, logical reads 44530
Ох, наш точно настроенный под SELECT * индекс больше не используется! Все, что было сделано - это добавление единственного битового поля, а нас отбросило назад к чтению 44530 страниц! Вместо 32Кб получили 347Мб только из-за добавления битового поля! Вывод: не важно, как вы спроектировали ваш индекс для запроса SELECT *, он не будет использоваться при любом незначительном добавлении в схеме таблицы и, помимо этого, мы будем еще платить за поддержку неиспользуемого индекса.
Дорогой поиск закладок
Давайте теперь рассмотрим сценарий, когда добавление поля все же допустит использование нашего индекса, но с другим побочным эффектом. Внесем небольшое изменение в нашу процедуру, чтобы результат возвращался отсортированным по LastAccessDate. Этого изменения достаточно, чтобы оптимизатор захотел использовать наш индекс, даже если он не содержит нового битового столбца, который мы добавили на предыдущем шаге...
ALTER PROCEDURE LastAccessedReport
AS
DECLARE @StartDate DATETIME = '20080801'
DECLARE @EndDate DATETIME = '20080831'
SELECT
Id,
DisplayName,
Location
FROM
[Users]
WHERE
LastAccessDate BETWEEN @StartDate AND @EndDate
ORDER BY LastAccessDate
GO
ALTER PROCEDURE LastAccessedReportSelectStar
AS
DECLARE @StartDate DATETIME = '20080801'
DECLARE @EndDate DATETIME = '20080831'
SELECT
*
FROM
[Users]
WHERE
LastAccessDate BETWEEN @StartDate AND @EndDate
ORDER BY LastAccessDate
Запрос НЕ SELECT * по-прежнему дает прежнее число чтений. Однако версия SELECT * несколько отличается...
DBCC DROPCLEANBUFFERS
SET STATISTICS IO ON
EXEC LastAccessedReportSelectStar
Table ‘Users’. Scan count 1, logical reads 141
Теперь мы возвращаемся к использованию нашего индекса, и число чтений сильно сократилось, но оно все еще весьма превышает те 4 чтения, которые мы имели прежде, поскольку для каждой строки, которую мы получаем, выполняется поиск закладки в кластеризованном индексе, чтобы извлечь наше новое поле. Нынешняя 141 строка не так много, и это, вероятно, не скажется на времени выполнения, но увеличит его, если будет возвращаться больше строк и, скорее всего, существенно больше полей, которые нам не нужны, и это может обойтись в итоге очень дорого.
Сортировка и выделение памяти
Сортировка является для SQL Server одной из наиболее расточительных операций по отношению к памяти. Одна из вещей, о которой забывают, заключается в том, что когда вы сортируете набор данных, вы перемещаете все поля в строке, и чем больше полей в строке, тем больше памяти требует сортировка. Давайте немного изменим наши запросы, добавив сортировку по неиндексированному полю, чтобы вызвать операцию сортировки...
ALTER PROCEDURE LastAccessedReport
AS
DECLARE @StartDate DATETIME = '20080801'
DECLARE @EndDate DATETIME = '20080831'
SELECT
Id,
DisplayName,
Location
FROM
[Users]
WHERE
LastAccessDate BETWEEN @StartDate AND @EndDate
ORDER BY Location
GO
ALTER PROCEDURE LastAccessedReportSelectStar
AS
DECLARE @StartDate DATETIME = '20080801'
DECLARE @EndDate DATETIME = '20080831'
SELECT
*
FROM
[Users]
WHERE
LastAccessDate BETWEEN @StartDate AND @EndDate
ORDER BY Location
Ни один из этих запросов не является сейчас специально оптимизированным, т.к. оба они сортируются по полю, которое не является индексированным. Однако давайте просто посмотрим, насколько один хуже другого...
BCC DROPCLEANBUFFERS
SET STATISTICS IO ON
EXEC LastAccessedReport
Наш запрос НЕ SELECT * потребляет 100Мб памяти для выполнения сортировки. Теперь сравним с версией SELECT *...
DBCC DROPCLEANBUFFERS
SET STATISTICS IO ON
EXEC LastAccessedReportSelectStar
Мы вернулись к полному сканированию кластеризованного индекса, т.к. теперь это считается более дешевым вариантом по сравнению с поиском закладок, поскольку мы теперь не получаем преимущества от порядка, в котором выполнена сортировка индекса. Однако если мы взглянем на память...
Наш запрос запросил 2.1Гб памяти, из которых предоставляется только 1.2Гб. Нам теперь требуется много больше пространства для сортировки данных за счет всех этих лишних полей, которые нам даже не нужны. Ситуация будет становиться только хуже с каждым добавленным в таблицу столбцом, и стать невероятной при добавлении больших полей. Я видел запросы на более 60Гб в некоторых довольно экстремальных случаях, когда более точно написанная версия того же запроса требовала менее 200Мб.
Та же логика справедлива и для соединений типа Hash Match, когда в запросе используется несколько таблиц.
Запросы может стать сложнее читать/отлаживать
Когда вы используете в запросе SELECT * с соединением нескольких таблиц, становится весьма сложно различать, какие поля из каких таблиц берутся. Когда я начал соединять таблицы, я указывал имя таблицы для каждого поля, чтобы упростить отладку и работу с кодом в дальнейшем, например:
SELECT
Table1.FieldA,
Table1.FieldB,
Table2.FieldA
FROM
Table1
INNER JOIN Table2 ON Table1.Id = Table2.Table1Id
WHERE
Table1.FieldA = 'Test'
Тяжело удалить
Уяснив проблему, довольно просто перестать использовать такие запросы в будущем, однако устранение SELECT * из существующего проекта много сложнее, т.к. к этому времени вы, вероятно, уже не помните, какие поля используются в вызывающем приложении.
Выгоды
Только единственный аргумент я слышал в пользу применения SELECT * - это сокращение набора/поддержки в коде. Учитывая тот негатив, который это дает, я предпочту лишнюю работу. Нельзя сказать, что это всегда безопасно, что ваша таблица никогда не будет изменяться. Все подвержено изменениям, только я думаю, что эти ситуации являются исключениями, и мы никогда не можем предсказать то, что случится потом.
Исключения
Поскольку всегда имеются исключения, правда? Я всегда пытаюсь избегать этого, но если вы настаиваете на использовании SELECT *, то ниже приводятся несколько ситуаций, которые вряд ли удовлетворят вас:
- Когда запрос адресуется к CTE, в котором уже ограничено число полей.
- Из табличной переменной или временной таблицы, в которых данные уже ограничены.
- Как часть ETL-процесса в хранилищах данных, когда вы всегда хотите получить все данные.
- Что-либо еще подобное вышесказанному, когда ограничение уже либо было применено, либо вы знаете, что вам всегда нужны все данные.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой