
Какой-то индекс в моем индексе
Пересказ статьи Gavin Draper. Waiter Waiter There's an Index in my Index
Речь пойдет о том, как SQL Server обращается к одновременно к кластеризованному и некластерихованному индексам при поиске закладок.
В двух словах это работает примерно так:
- Если таблица не имеет кластеризованного индекса (куча), то каждая запись в некластеризованном индексе будет хранить идентификатор записи (RID), он используется как обратный указатель на кучу. Любое затребование данных, которых нет в некластеризованном индексе, будут использовать этот указатель для обращения к куче за получением дополнительных полей.
- Если таблица имеет кластеризованный индекс, то некластеризованные индексы не используют RID в качестве указателя. Вместо этого они используют в качестве указателя поля (ключи) кластеризованного индекса. Вначале это выглядит удивительным, т.к. подобное подразумевают, что каждый некластеризованный индекс также включает в себя поля кластеризованного индекса, чтобы иметь возможность выполнить поиск закладок в кластеризованном индексе.
Продемонстрируем сказанное небольшим примером...
CREATE TABLE NonClusteredOnly
(
Id INT IDENTITY,
Name NVARCHAR(100),
INDEX ndx_nonclusteredonly_name NONCLUSTERED(Name)
)
CREATE TABLE ClusteredOnly
(
Id INT IDENTITY PRIMARY KEY,
Name NVARCHAR(100)
)
CREATE TABLE ClusteredAndNonClustered
(
Id INT IDENTITY PRIMARY KEY,
Name NVARCHAR(100),
INDEX ndx_clusteredandnonclustered_name NONCLUSTERED(Name)
)
INSERT INTO NonClusteredOnly (Name)
SELECT specific_name
FROM msdb.information_schema.routines
WHERE routine_type = 'PROCEDURE'
INSERT INTO ClusteredOnly (Name)
SELECT specific_name
FROM msdb.information_schema.routines
WHERE routine_type = 'PROCEDURE'
INSERT INTO ClusteredAndNonClustered (Name)
SELECT specific_name
FROM msdb.information_schema.routines
WHERE routine_type = 'PROCEDURE'
После запуска этого кода вы получите 3 таблицы приблизительно по 500 записей в каждой (точное количество зависит от используемой вами версии SQL Server).
Посмотрим сначала что произойдет, если мы наложим фильтр на столбец name и вернем как ID, так и Name из таблицы ClusteredOnly...
SELECT id,[Name] FROM ClusteredOnly
WHERE [Name] LIKE 'sp_verify_job%'
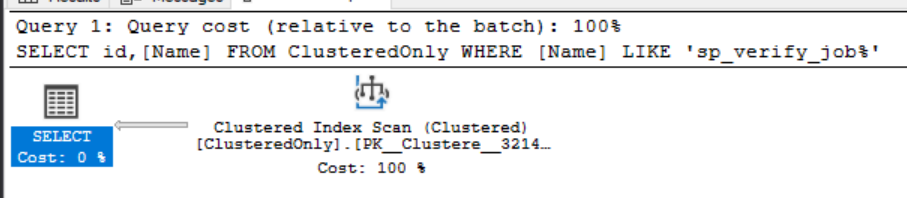 Как вы, вероятно, ожидали, у нас отсутствует индекс, который мог бы помочь с нашим предикатом, поэтому получаем полное сканирование кластеризованного индекса.
Как вы, вероятно, ожидали, у нас отсутствует индекс, который мог бы помочь с нашим предикатом, поэтому получаем полное сканирование кластеризованного индекса.Теперь запустим тот же запрос на нашей таблице с одним лишь некластеризованным индексом...
SELECT id,[Name] FROM NonClusteredOnly
WHERE [Name] LIKE 'sp_verify_job%'
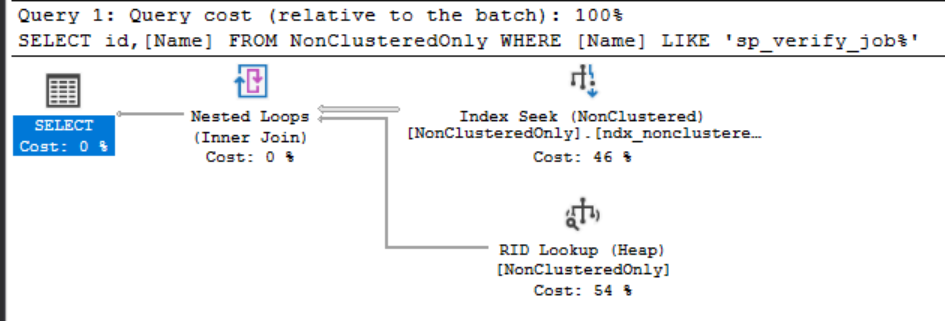 В этом случае мы используем некластеризованный индекс для поиска на нашем предикате, но из-за того, что индекс не содержит ID, который требуется в запросе, используется RID (идентификатор записи) для обратной ссылки на кучу для получения данных в этом поле.
В этом случае мы используем некластеризованный индекс для поиска на нашем предикате, но из-за того, что индекс не содержит ID, который требуется в запросе, используется RID (идентификатор записи) для обратной ссылки на кучу для получения данных в этом поле.Более интересную картину мы увидим, когда выполним тот же запрос на таблице, имеющей кластеризованный индекс на ID и некластеризованный на Name. Очевидно, что вы ожидаете увидеть поиск в некластеризованном индексе, а затем поиск закладки в кластеризованном индексе для получения поля ID. Однако...
SELECT id,[Name] FROM ClusteredAndNonClustered
WHERE [Name] LIKE 'sp_verify_job%'
 Как видно, мы получили оба поля, ID и Name, из некластеризованного индекса, хотя в нем содержится только Name. Как я упомянул вначале, это возможно из-за того, что некластеризованные индексы включают столбцы кластеризованного индекса в качестве обратного указателя на кластеризованный индекс. В результате нам не нужно обращаться куда-нибудь еще в кластеризованном или некластеризованном индексе, т.е. никакие закладки не потребовались.
Как видно, мы получили оба поля, ID и Name, из некластеризованного индекса, хотя в нем содержится только Name. Как я упомянул вначале, это возможно из-за того, что некластеризованные индексы включают столбцы кластеризованного индекса в качестве обратного указателя на кластеризованный индекс. В результате нам не нужно обращаться куда-нибудь еще в кластеризованном или некластеризованном индексе, т.е. никакие закладки не потребовались.Мы продемонстрировали, что каждая запись имеет указатель на кластеризованный индекс, и этот указатель представляет собой поля в кластеризованном индексе. Наверное, вас интересует как это работает, если кластеризованный индекс не является уникальным?
Давайте построим другой тест, чтобы выяснить это...
CREATE TABLE NonUniqueClusteredAndNonClustered
(
ID INT,
[Name] NVARCHAR(100),
[LookupText] NVARCHAR(100),
INDEX ndx_clustered CLUSTERED (Id),
INDEX ndx_nonclustered NONCLUSTERED(Name)
)
INSERT INTO NonUniqueClusteredAndNonClustered (Id,Name,LookupText)
SELECT 1,specific_name,'Test'
FROM msdb.information_schema.routines
WHERE routine_type = 'PROCEDURE'
Теперь мы имеем наш кластеризованный индекс на ID, в котором каждое значение равно 1. Также мы добавили новое поле LookupText, которое не включено ни в какой индекс. Мы уже знаем, что для того, чтобы получить LookupText из поиска по некластеризованному индексу, нам необходимо использовать ключи кластеризованного индекса для поиска закладок в кластеризованном индексе к требуемым записям. Но... это не может работать, когда указатель не является уникальным. Правильно?
SELECT id,[Name],LookupText FROM NonUniqueClusteredAndNonClustered
WHERE [Name] LIKE 'sp_verify_job%'
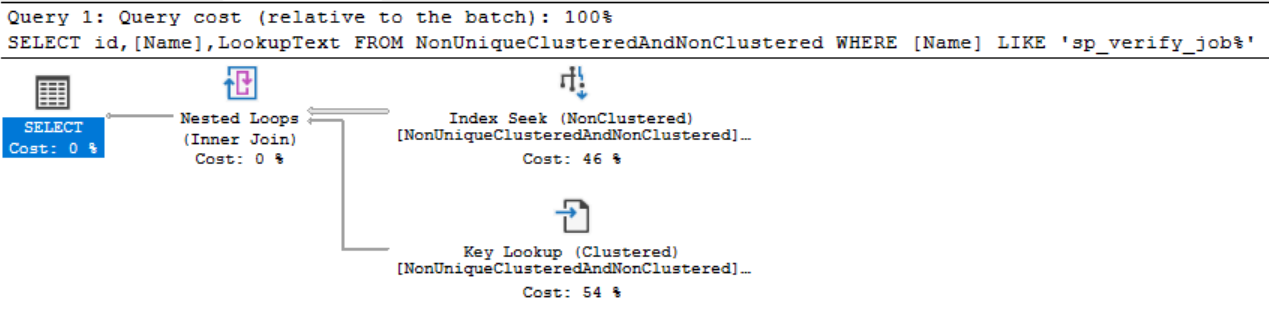
Как это возможно, чтобы выполнить поиск закладки из некластеризованного индекса к кластеризованному, если у нас нет уникального указателя? Ведь наш указатель равен 1 для каждой отдельной записи. Ну, в этом случае SQL Server видит, что ключ не является уникальным, и в то место, куда он вставляет данные, он добавляет уникальное 4-х байтовое значение, указывающее на кластеризованный индекс для каждой строки, позволяя указателю работать. Реально вы нигде не увидите этого уникального ключа, т.к. он используется SQL Server только за сценой, чтобы сделать возможным поиск закладок.
Выводы
Что не следует портить...
. Вам не нужно включать поля кластеризованного индекса в ваши некластеризованные индексы, поскольку они там уже находятся.
- Вам не нужно создавать дополнительные индексы, чтобы избежать поиска закладок из некластеризованного индекса в кластеризованном, когда поля закладок уже определены в кластеризованном индексе.
- Поиск закладок никогда не происходит из некластеризованного индекса к ключам, определенным в кластеризованном индексе.
- Это может также работать в обратную сторону, для каждой записи в кластеризованном индексе вы можете найти соответствующую запись в каждом некластеризованном индексе. Так работает DELETE и UPDATE, например, при обновлении кластеризованного индекса с последующим поиском закладок для каждой соответствующей записи в некластеризованном индексе для их обновления (каскадное обновление).
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой