
Ограничения в PostgreSQL: учим PostgreSQL вместе с Grant Fritchey
Пересказ статьи Grant Fritchey. PostgreSQL Constraints: Learning PostgreSQL with Grant
Одними из наиболее важных аспектов управления данными является способность гарантировать, что данные в вашей базе данных хорошо определены и согласованы. Некоторые из этих аспектов обеспечиваются реляционными структурами данных, которые вы проектируете. Другая часть управления заключается в использовании корректных типов данных. Затем мы переходим к ограничениям. Ограничение - это способ валидации данных перед их добавлением в вашу базу данных. Это еще один инструмент в вашем ящике, который помогает поддерживать хорошие данные.
PostgreSQL поддерживает ограничения во многом подобно любым другим системам управления базами данных. Когда вам нужно обеспечить определенное поведение данных, вы можете задействовать эти ограничения. Я уже использовал некоторые из них при создании моей тестовой базы данных (доступной на GitHub в файле CreateDatabase.sql). По мере продвижения я объясню их. В PostgreSQL поддерживаются следующие ограничения:
Один из способов убедиться, что наши данные верны, — это в первую очередь их наличие. Давайте создадим подобную таблицу:
Поскольку вы не указали, могут ли столбцы допускать NULL-значения, то они будут принимать значения NULL. Что касается NULL, то это реально полезная вещь. Иногда люди просто не имеют информации для предоставления, поэтому разрешение NULL является хорошим решением. Хотя иногда вам обязательно требуется, чтобы значение было добавлено в строки вашей таблицы.
Давайте в качестве примера возьмем таблицу radio.radios из базы данных hamshackradio:
Здесь я использовал предложение NOT NULL для нескольких столбцов для гарантии, что они должны иметь соответствующую информацию. Короче говоря, radio должно иметь производителя (через столбец manufacturer_id) и название (столбец radio_name). Определение их как NOT NULL обеспечивает обязательность их заполнения. Обратите внимание, что я использовал определение NULL для столбца picture. Я мог бы просто позволить отвечать за это значению по умолчанию. Для ясности и с целью демонстрации я вместо этого использую указание NULL.
Поэтому теперь, если я попытаюсь вставить в таблицу radio.radios подобные данные:
я получу очень конкретную ошибку:
Она говорит мне о том, что я должен предоставить значение для столбца radio_name. Следует отметить, что был пропущен другой столбец NOT NULL, connectortype_id. Он не был включен в сообщение об ошибке, поскольку дополнительные проверки не выполнялись после первого столбца, radio_name, для которого было нарушено ограничение NOT NULL. Если бы я просто добавил значение radio_name в оператор INSERT выше, я бы получил новую ошибку. Короче говоря, вы должны предоставить значения для всех столбцов, помеченных как NOT NULL, если для этих столбцов не определены значения по умолчанию (мы обсудим значения по умолчанию в другой статье).
Если бы я захотел перечислить все ограничения в таблице, то мог выполнить подобный запрос:
Выполнение этого запроса дает следующие результаты:

Ни одно из ограничений NOT NULL не присутствует в списке. Хотя они считаются ограничениями, но определены только на уровне столбца и не имеют никакого другого определения за его пределами. Если вы хотите увидеть, какие столбцы допускают значения NULL, то можете использовать следующий запрос:
Этот запрос возвращает столбцы picture и digitalmode_id, которые совпадают с определенными в DDL таблицы.
Иногда столбец или набор столбцов в таблице должен быть уникальным, т.е. не допускать дубликатов. PostgreSQL предоставляет целый набор механизмов для определения уникальности столбца или столбцов в пределах таблицы.
Во-первых, вы можете просто определить уникальный столбец так:
Теперь только уникальные значения могут присутствовать в столбце myuniquevalue. Однако случилась интересная вещь. Давайте посмотрим на индексы этой таблицы:
Вот результаты, которые возвращает этот запрос:

Способ, которым PostgreSQL реализует критерий уникальности столбца, является создание уникального индекса b-tree. Это знакомо мне как пользователю SQL Server. Но возникает вопрос, зачем вообще создавать ограничение уникальности? Почему просто не создать уникальный индекс? Да, вы действительно можете поступить так или иначе. Однако важна документация, которую подразумевает использование ограничения уникальности для базы данных.
Мое правило большого пальца гласит, что ограничение UNIQUE предназначено для обеспечения того, чтобы значения в столбце таблицы отличались друг от друга. Уникальный индекс отвечает за производительность. Это помогает сообщить людям, которые настраивают свои запросы к базе данных, что индекс может быть безопасно удален, в то время как ограничение является частью ключевых бизнес-правил базы данных.
Преимущество в плане выполнения запросов будет одинаковым в любом случае. Однако это будет отмечено и перечислено и как ограничение, и как индекс:
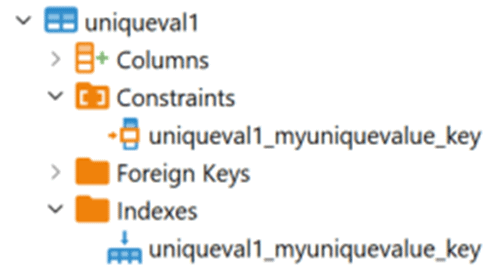
Вы можете выполнить то же самое, используя несколько отличный синтаксис:
Есть проблемы с обоими этими подходами по умолчанию. Дело в имени ограничения по умолчанию, которое я не могу контролировать. Это влияет на возможность работы с базой данных в системе управления ресурсами, поэтому я бы изменил синтаксис на следующий:
или
В этом случае я получаю контроль над именами ограничений. Если больше одного столбца имеют ограничение, вам следует использовать этот второй синтаксис с определением ограничения столбца.
Вы можете также добавить ограничение уникальности в таблицу, используя ALTER:
Здесь очень важно понимать, как значения NULL обрабатываются в PostgreSQL, что может отличаться от других РСУБД, с которыми вы работали. NULL-значение является по определению неизвестным значением. Поскольку два неизвестных значения не равны одно другому, вы можете получить по умолчанию множество NULL-значений в вашем "уникальном" наборе строк. Давайте посмотрим на это в действии:
Это выполнится без ошибок, поскольку NULL-значения не являются дубликатами в соответствии с определением. Вы можете изменить это поведение, если используете PostgreSQL 15 или более позднюю версию, используя уникальные неразличающиеся NULL (unique nulls not distinct):
Теперь при выполнении запроса вы сразу получите ошибку:
При измененном определении таблицы с использованием NULLS NOT DISTINCT теперь вы получаете одну строку с NULL, а любые последующие значения NULL считаются дубликатами. Вы можете задать такое поведение по умолчанию с помощью NULLS DISTINCT.
Для более ранних версий вам могло потребоваться применять другие менее простые решения. Напрмер, в версии сервера 14.5, которую я используя для тестирования, я мог бы добавить вычисляемый столбец, который принимает NULL-значения и делает их не-NULL.
Затем добавить фильтрованный индекс на вычисляемом столбце:
Конечно, это приведет к затратам пространства на дублирующий столбец и лишний индекс, плюс необходимость искать "impossible value" для uniqueval (и вероятно добавления ограничения, чтобы убедиться, что это действительно невозможно). Однако почти всегда стоимость реализации и сложность представляется менее важной, чем качество данных.
Ограничение первичного ключа подобно ограничению уникальности за небольшими, но важными, отличиями. Оно будет поддерживаться так же с помощью уникального индекса, и на него можно ссылаться с помощью ограничения внешнего ключа (которое будет рассмотрено позже в этой статье). Однако ограничение первичного ключа обычно представляет столбцы, используемые в связи по внешнему ключу, и столбцы первичного ключа не могут допускать значения NULL. (Даже если вы определите столбец первичного ключа как NULL, оно будет изменено на NOT NULL, пока в столбце нет данных.)
Хотя вы могли бы обойтись без первичного ключа и просто определить ваш ключ как ограничение уникальности или уникальный индекс, ясность так же важна, когда дело доходит до кода. Определяйте ваши структуры в соответствии с тем, как как ваша база спроектирована и как она будет использоваться. Более подробно об этом читайте в разделе внешних ключей.
Синтаксис для создания первичного ключа очень похож на создание ограничения уникальности:
Хотя, как и ранее, это приведет к созданию имени ограничения по умолчанию, так что лучше сделать это так:
Будет создан первчный ключ с именем pkradios. Обратите также внимание на то, что я здесь использовал значение IDENTITY, чтобы обеспечить автоматическую генерацию значений при добавлении данных в таблицу.
Как и в случае ограничения уникальности, примеры которого приведены выше, вы можете определить первичный ключ в форме определения столбца. Вы должны использовать этот синтаксис, если ключ состоит из более чем одного столбца. Вы можете также изменить таблицу (ALTER), чтобы добавить ограничение первичного ключа. Кроме этого, поведение первчного ключа в основном идентично ограничению уникальности. Я все же всегда использовал бы определение первичного ключа, если нет других причин, как средство документирования.
Интересно, что если при создании ограничений первичного ключа значения, которые вы определяете как PRIMARY KEY, допускают значения NULL, ядро PostgreSQL попытается исправить это за вас. Например, рассмотрим следующую таблицу:
Проверим результаты следующего запроса к метаданным:
Будет возвращено YES. Это значит, что столбец допускает значения NULL. После добавления следующего ограничения:
запрос к метаданным теперь вернет NO. Т.е. произошло изменение определения столбца, который больше не допускает значений NULL. Если данные в столбце id уже содержат значения NULL, вы получите следующее сообщение об ошибке:
Одной из ключевых концепций, лежащих в основе реляционных баз данных, является смысловая связь между таблицами. Внешние ключи определяют и управляют ссылочной целостностью одной таблицы с другой. В моей тестовой базе данных есть одна таблица для радио, а другая для производителей радио. Определение внешнего ключа между этими двумя таблицами выглядит так:
Первичный ключ в radio.manufacturers состоит из столбца manufacturer_id. Имеется такой же столбец с совпадающим типом данных в radio.radios. Это позволяет мне создать внешний ключ между этими двумя таблицами. Обратите внимание, что хотя участвуют обе таблицы, мы изменяем только одну, чтобы добавить ограничение.
С установленным внешним ключом я смогу добавить только такие значения manufacturer_id в таблицу radio.radios, которые содержатся в первичном ключе таблицы radios.manufacturers. Кроме того, при наличии этого ограничения я не могу удалить строку с этим значением в таблице radio.manufacturers (подробности ниже). Так ограничение внешнего ключа помогает обеспечивать целостность данных.
Способ, с помощью которого я определил внешний ключ, будет генерировать имя по умолчанию. Я смогу контролировать имя, изменив код.
Я могу также добавить внешний ключ как часть определения таблицы:
Поведением по умолчанию внешнего ключа является проверка удаления строки в таблице, на которую ключ ссылается. Если значение существует, удаление останавливается. Вы можете непосредственно влиять на это поведение и менять его. Например, вы можете поменять его, когда внутри процесса транзакции выполняется проверка. Обычно это делается позже в процессе, но вы можете установить так, чтобы это происходило сначала с помощью опции ON DELETE RESTRICT:
Это изменит поведение по умолчанию. Вы можете также установить значение по умолчанию с помощью синтаксиса ON DELETE NO ACTION, но мне представляется, что это многословно и непонятно. Лучше просто использовать синтаксис по умолчанию. Позвольте мне уделить немного времени, чтобы показать вам диаграмму, описывающую это поведение DELETE:
Итак, поведение по умолчанию находит строки, которые должны быть удалены, удаляет их, затем проверяет, чтобы не было совпадающих строк в любых связанных таблицах. Так работает и SQL Server. Однако вы можете поменять, когда выполняется эта проверка, при помощи DELETE RESTRICT в определении внешнего ключа. В этом случае проверка нарушения огранчений внешнего ключа будет выполняться перед началом обработки транзакции.
Все это может показаться семантикой, но есть дополнительное поведение, которое вы можете добавить в свои транзакции в PostgreSQL. В этом поведении немного нюансов, и я кратко изложу их здесь. Вы можете непосредственно влиять, когда некоторые ограничения, в частности, UNIQUE, PRIMARY KEY, внешний ключ (REFERENCES) и EXCLUDE проверяются в отдельной транзакциию Поведение по умолчанию для этих ограничений описывается в соответствующем разделе. Но вы можете отсрочить их все на более позднее время в транзакции. Однако некоторые ограничения внешнего ключа могут быть нарушены с большей вероятностью. Их вы можете контролировать посредством этих установок, принуждая выполнять проверки раньше в транзакции, экономя на необязательной обработке и откатах транзакции. И наоборот, вы можете выполнять все проверки ограничений немедленно. К слову, ограничения NULL и CHECK всегда выполняются немедленно.
Вы также можете сделать так, чтобы при удалении строки в таблице radio.manufacturers все связанные строки в таблице radios также удалялись:
Это то, что делает опция CASCADE. Однако здесь есть важные следствия. Таблица radio.radios также ссылается по внешнему ключу. Если мы попытаемся удалить строки из таблицы radio.radios, то потерпим неудачу, из-за этих других ограничений внешнего ключа. Пока мы не сделаем их также каскадными. Однако тут вы можете получить довольно неприятную проблему поведения вашей базы данных, т.к. будут удерживаться блокировки пока все различные таблицы не пройдут через каскадное удаление. Обычно это не считается хорошим способом поведения.
По большей части базы данных, которые я создавал, использовали значения идентификатора, которые не могли изменяться, поэтому я редко использовал следующие настройки, но PostgreSQL имеет некоторые дополнительные опции для ON DELETE, которые могут оказаться полезными в некоторых случаях.
Вы можете определить ON DELETE SET NULL. Это изменит значение, каким бы оно ни было, на значение NULL. Естественно, столбец должен допускать NULL-значения. Также можно определить ON DELETE SET DEFAULT. Тогда, каким бы ни было значение по умолчанию для столбца (мы уже обсуждали значения по умолчанию), оно будет подставляться вместо удаленных значений. Хотя опять таки, это значение по умолчанию должно удовлетворять фундаментальным требованиям ссылочной целостности, что подразумевает наличие этого значения в первичном ключе (в нашем примере в таблице radio.manufacturers).
Замечание. Вы можете определить ограничение внешнего ключа, которое ссылается на ограничение UNIQUE, но важно предупредить, что NULL-значения в столбце будут гарантровать выполнение соответствия. Как я продемонстрирую в разделе ограничений Check, ограничения нарушаются при условии false, но не для NULL (при сравнении любого значения с NULL).
Ограничение CHECK позволяет вам оределить свои собственные правила целостности данных для значений в строке. Это может быть что угодно - от значений в столбце, которые могут содержать только числа больше 100, до вычислений между столбцами. Смысл в том, что все проверки выполняются при вставке строки или при любом последующем обновлении, и могут получать доступ только к столбцам и значениям в той же строке.
Для примера в США самая низкая возможная частота, которую я могу использовать как радиолюбитель, составляет 135,7 кГц, а самая высокая — 1300 МГц или 1300000 кГц. Поэтому в моей таблице radio.bands, в которой отслеживаются частоты, я мог бы определить ограничение для столбца frequency_start_khz:
Теперь я не смогу случайно добавить значение, которое находится ниже моего возможного рабочего диапазона.
Для примера взамодействия столбцов, я мог бы обеспечить условие, чтобы frequency_start_khz всегда была меньше frequency_end_khz, которые определяют диапазон полосы частот:
И при желании я мог бы сделать это в одной проверке:
Это действительно вопрос - как использовать ограничения. Я бы, вероятно, держал их отдельно, поскольку это облегчает понимание того, что делает каждое ограничение.
Как и с другими примерами ограничений в главе, вы можете также сделать ограничение частью определения столбца:
Как и ранее, если я не включаю имя ограничения, оно будет автоматически сгенерировано.
Следует сделать еще одно замечание относительно NULL-значений и ограничений. Ограничения работают несколько отлично от предложений WHERE. В предложении WHERE строка возвращается, когда результат равен TRUE. 1=1 возвращает TRUE, 1=2 возвращает FALSE, но 1=NULL есть UNKNOWN. Только значение TRUE будет возвращать результаты. В ограничениях данные их нарушают, только если сравнение дает FALSE.
Для примера рассмотрим следующую таблицу:
Затем я добавлю ограничение CHECK, требующее, чтобы значение столбца равнялось 1.
Представляется довольно ясным, какой из этих двух операторов INSERT отработает, а какой завершится неудачно:
Второй оператор завершится с ошибкой:
Заметим, что если выполнить оба оператора в одном пакете, никаких строк не будет добавлено в таблицу. Однако следующий оператор выполнится успешно, поскольку NULL = 1 есть UNKNOWN, а не FALSE.
Если вам необходимо ограничение для учета NULL-значений в критерии, то следует явно включить выражение IS NULL или нечто подобное. Если вы хотите исключить NULL значения в некоторых условиях, то необходимо явно установить IS NOT NULL. Например, я изменю ограничение, допускающее NULL-значения, когда значения id меньше 5, но не допускающее NULL-значения при 5 и выше.
Теперь при выполнении следующих операторов:
первый оператор будет успешен, а второй - нет.
Я настоятельно советую вам тщательно тестировать ограничения, особенно когда ссылочный столбец допускает NULL-значения.
Ограничение исключения несколько похоже на ограничение уникальности, но есть отличие. В основном ограничение исключения гарантирует, что если сравниваются любые две строки, используя выражения, определенные в ограничении, и не все сравнения вернут TRUE, по крайней мере, одно должно вернуть FALSE или NULL. Идея состоит в том, чтобы иметь возможность определить более сложные ограничения для нескольких столбцов в таблице.
Сразу отметим, что если при сравнении столбцов используются только операторы равенства, то ограничение исключения в точности соответствует ограничению уникальности. Поэтому главное состоит в том, что когда вы имеете более сложное сравнение, чем простое равенство, но все же хотите иметь уникальные данные на основе этого сравнения, что бы это ни было, вы могли бы использовать ограчение исключения.
Прежде чем попытаться создать ограничения исключения, следует знать, что есть ограничения на типы данных, которые могут использоваться. Если вас интересуют даты, текст и тому подобные вещи, которые могут ограничивать строку и являются довольно стандартными, вам сначала нужно выполнить одну команду:
Это позволит вам накладывать ограничения на стандартные скалярные скалярные типы данных в противоположность массвам, геометрическим и другим более сложным типам. В этой серии статей я пытался строго придерживаться того, что «в коробке» с точки зрения функциональности PostgreSQL, то есть без расширений, но это воспрепятствует нашим намерениям. Видите ли, существуют просто тонны расширений. Некоторые, аналогично btree_gist, являются бесплатными и довольно фундаментальными для некоторых моделей поведения. За другие нужно заплатить, но они добавляют изумительное поведение. Сейчас я стараюсь изучить ядро PostgreSQL, а не все возможные расширения. Однако ограничения на стандартные типы данных весьма вероятны, поэтому я забегаю вперед и нарушаю свое собственное правило в этом отношении.
Имея это в виду, возьмем таблицу logging.logs:
Я пытаюсь определить ограничение, при котором log_date, log_callsign могут быть одинаковыми, в то время как log_location меняться. Это было бы полезно для такого конкурса, как парки в эфире, где вы можете говорить с некоторыми людьми, но ваше местонахождение может меняться, означая, что вы находитесь в другом парке. Это ограничение можно было бы определить так:
Затем я могу добавить некоторые данные в таблицу:
И это отработает отлично. Несмотря на то, что log_date и log_callsign одинаковы, log_location различается. Если теперь я попробую добавить это:
то получу следующую ошибку:
Хотя вы можете выполнить некоторые сложные вещи с помощью этого ограничения, стоит отметить, что ограничение исключения далеко не лучшее ограничение с точки зрения прозводительности. Где это возможно рекомендуется использовать ограничения уникальности, поскольку они лучше в этом отношении. Однако, когда имеются конкретные требования, ограничение исключения может решить проблему.
Это все типы ограничений в PostgreSQL. Они позволят вам обеспечить, насколько это возможно, чистоту данных. Если вы использовали другую РСУБД, подобную SQL Server, большнство из этих ограничений покажутся вам очень знакомыми, как и поведение ограничений. Некоторые вещи, как-то возможность управлять тем, как значения NULL разрешаются в ограничениях уникальности, или концепция ограничения исключения, будут для вас новыми. В целом, я впечатлен функциональностью, которая предоставляется ограничениями в PostgreSQL.
- Ограничения Not Null
- Ограничения Unique (уникальности)
- Primary Key (первичный ключ)
- Foreign Key (внешний ключ)
- Ограничения Check (проверочные)
- Ограничения Exclusion (исключения)
Ограничения Not Null
Один из способов убедиться, что наши данные верны, — это в первую очередь их наличие. Давайте создадим подобную таблицу:
create table public.example
(ID int,
SomeValue varchar(50)); Поскольку вы не указали, могут ли столбцы допускать NULL-значения, то они будут принимать значения NULL. Что касается NULL, то это реально полезная вещь. Иногда люди просто не имеют информации для предоставления, поэтому разрешение NULL является хорошим решением. Хотя иногда вам обязательно требуется, чтобы значение было добавлено в строки вашей таблицы.
Давайте в качестве примера возьмем таблицу radio.radios из базы данных hamshackradio:
CREATE TABLE IF NOT EXISTS radio.radios
(radio_id int CONSTRAINT pkradios
PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
radio_name varchar(100) NOT NULL,
manufacturer_id int NOT NULL,
picture BYTEA NULL,
connectortype_id int NOT NULL,
digitalmode_id int NULL
);Здесь я использовал предложение NOT NULL для нескольких столбцов для гарантии, что они должны иметь соответствующую информацию. Короче говоря, radio должно иметь производителя (через столбец manufacturer_id) и название (столбец radio_name). Определение их как NOT NULL обеспечивает обязательность их заполнения. Обратите внимание, что я использовал определение NULL для столбца picture. Я мог бы просто позволить отвечать за это значению по умолчанию. Для ясности и с целью демонстрации я вместо этого использую указание NULL.
Поэтому теперь, если я попытаюсь вставить в таблицу radio.radios подобные данные:
insert into radio.radios (manufacturer_id)
values (2);я получу очень конкретную ошибку:
SQL Error [23502]: ERROR: null value in column "radio_name" of relation "radios" violates not-null constraint
Detail: Failing row contains (4, null, 2, null, null, null).Она говорит мне о том, что я должен предоставить значение для столбца radio_name. Следует отметить, что был пропущен другой столбец NOT NULL, connectortype_id. Он не был включен в сообщение об ошибке, поскольку дополнительные проверки не выполнялись после первого столбца, radio_name, для которого было нарушено ограничение NOT NULL. Если бы я просто добавил значение radio_name в оператор INSERT выше, я бы получил новую ошибку. Короче говоря, вы должны предоставить значения для всех столбцов, помеченных как NOT NULL, если для этих столбцов не определены значения по умолчанию (мы обсудим значения по умолчанию в другой статье).
Если бы я захотел перечислить все ограничения в таблице, то мог выполнить подобный запрос:
select
c.conname,
ccu.table_schema,
ccu.table_name,
ccu.column_name,
c.contype,
pg_get_constraintdef(c.oid)
from
pg_constraint as c
join pg_namespace as ns on
ns.oid = c.connamespace
join pg_class as cl on
c.conrelid = cl.oid
left join information_schema.constraint_column_usage as ccu
on
c.conname = ccu.constraint_name
and ns.nspname = ccu.constraint_schema
where
ccu.table_name = 'radios';Выполнение этого запроса дает следующие результаты:
Ни одно из ограничений NOT NULL не присутствует в списке. Хотя они считаются ограничениями, но определены только на уровне столбца и не имеют никакого другого определения за его пределами. Если вы хотите увидеть, какие столбцы допускают значения NULL, то можете использовать следующий запрос:
select column_name
from information_schema.columns
where table_catalog = 'hamshackradio'
and table_schema = 'radio'
and table_name = 'radios'
and is_nullable = 'YES';
Этот запрос возвращает столбцы picture и digitalmode_id, которые совпадают с определенными в DDL таблицы.
Ограничения UNIQUE
Иногда столбец или набор столбцов в таблице должен быть уникальным, т.е. не допускать дубликатов. PostgreSQL предоставляет целый набор механизмов для определения уникальности столбца или столбцов в пределах таблицы.
Во-первых, вы можете просто определить уникальный столбец так:
CREATE TABLE IF NOT EXISTS public.uniqueval1
(id int not null,
myuniquevalue varchar(50) unique);Теперь только уникальные значения могут присутствовать в столбце myuniquevalue. Однако случилась интересная вещь. Давайте посмотрим на индексы этой таблицы:
select i.indexname,
i.indexdef
from
pg_indexes as i
where
i.tablename = 'uniqueval1';Вот результаты, которые возвращает этот запрос:
Способ, которым PostgreSQL реализует критерий уникальности столбца, является создание уникального индекса b-tree. Это знакомо мне как пользователю SQL Server. Но возникает вопрос, зачем вообще создавать ограничение уникальности? Почему просто не создать уникальный индекс? Да, вы действительно можете поступить так или иначе. Однако важна документация, которую подразумевает использование ограничения уникальности для базы данных.
Мое правило большого пальца гласит, что ограничение UNIQUE предназначено для обеспечения того, чтобы значения в столбце таблицы отличались друг от друга. Уникальный индекс отвечает за производительность. Это помогает сообщить людям, которые настраивают свои запросы к базе данных, что индекс может быть безопасно удален, в то время как ограничение является частью ключевых бизнес-правил базы данных.
Преимущество в плане выполнения запросов будет одинаковым в любом случае. Однако это будет отмечено и перечислено и как ограничение, и как индекс:
Вы можете выполнить то же самое, используя несколько отличный синтаксис:
create table if not exists public.uniqueval2
(id int not null,
myuniquevalue varchar(50) not null,
unique(myuniquevalue));Есть проблемы с обоими этими подходами по умолчанию. Дело в имени ограничения по умолчанию, которое я не могу контролировать. Это влияет на возможность работы с базой данных в системе управления ресурсами, поэтому я бы изменил синтаксис на следующий:
create table if not exists public.uniqueval3
(id int not null,
myuniquevalue varchar(50)
constraint uniqueval3_inameit unique not null);или
create table if not exists public.uniqueval4
(id int not null,
myuniquevalue varchar(50),
constraint inameit unique(myuniquevalue));В этом случае я получаю контроль над именами ограничений. Если больше одного столбца имеют ограничение, вам следует использовать этот второй синтаксис с определением ограничения столбца.
Вы можете также добавить ограничение уникальности в таблицу, используя ALTER:
--Создание таблицы без ограничения
create table if not exists public.uniqueval5
(id int not null,
myuniquevalue varchar(50) null);
--теперь добавим ограничение
alter table public.uniqueval5
add constraint mynewconstraint unique(id, myuniquevalue);Здесь очень важно понимать, как значения NULL обрабатываются в PostgreSQL, что может отличаться от других РСУБД, с которыми вы работали. NULL-значение является по определению неизвестным значением. Поскольку два неизвестных значения не равны одно другому, вы можете получить по умолчанию множество NULL-значений в вашем "уникальном" наборе строк. Давайте посмотрим на это в действии:
create table if not exists public.nullnotunique
(id int not null,
nonuniqueval varchar(50) constraint notunique unique null
);
insert into public.nullnotunique(id,nonuniqueval)
values (1, null), (2,null), (3, 'one');Это выполнится без ошибок, поскольку NULL-значения не являются дубликатами в соответствии с определением. Вы можете изменить это поведение, если используете PostgreSQL 15 или более позднюю версию, используя уникальные неразличающиеся NULL (unique nulls not distinct):
create table if not exists public.nullunique
(id int not null,
uniqueval varchar(50)
constraint nowunique unique nulls not distinct null);
insert into public.nullunique (id,uniqueval)
values (1, null), (2, null), (3, 'one');Теперь при выполнении запроса вы сразу получите ошибку:
SQL Error [23505]: ERROR: duplicate key value violates unique constraint "nowunique"
Detail: Key (uniqueval)=(null) already exists.При измененном определении таблицы с использованием NULLS NOT DISTINCT теперь вы получаете одну строку с NULL, а любые последующие значения NULL считаются дубликатами. Вы можете задать такое поведение по умолчанию с помощью NULLS DISTINCT.
Для более ранних версий вам могло потребоваться применять другие менее простые решения. Напрмер, в версии сервера 14.5, которую я используя для тестирования, я мог бы добавить вычисляемый столбец, который принимает NULL-значения и делает их не-NULL.
ComputedUniqueeval varchar(50) GENERATED ALWAYS AS
(case when uniqueval is null
then 'impossible value'
else uniqueval END) STORED
);Затем добавить фильтрованный индекс на вычисляемом столбце:
CREATE UNIQUE INDEX uniqueval_notnull_idx
ON public.nullunique (ComputedUniqueeval)
WHERE uniqueval IS NULL;Конечно, это приведет к затратам пространства на дублирующий столбец и лишний индекс, плюс необходимость искать "impossible value" для uniqueval (и вероятно добавления ограничения, чтобы убедиться, что это действительно невозможно). Однако почти всегда стоимость реализации и сложность представляется менее важной, чем качество данных.
Ограничения первичного ключа
Ограничение первичного ключа подобно ограничению уникальности за небольшими, но важными, отличиями. Оно будет поддерживаться так же с помощью уникального индекса, и на него можно ссылаться с помощью ограничения внешнего ключа (которое будет рассмотрено позже в этой статье). Однако ограничение первичного ключа обычно представляет столбцы, используемые в связи по внешнему ключу, и столбцы первичного ключа не могут допускать значения NULL. (Даже если вы определите столбец первичного ключа как NULL, оно будет изменено на NOT NULL, пока в столбце нет данных.)
Хотя вы могли бы обойтись без первичного ключа и просто определить ваш ключ как ограничение уникальности или уникальный индекс, ясность так же важна, когда дело доходит до кода. Определяйте ваши структуры в соответствии с тем, как как ваша база спроектирована и как она будет использоваться. Более подробно об этом читайте в разделе внешних ключей.
Синтаксис для создания первичного ключа очень похож на создание ограничения уникальности:
create table if not exists public.pkexample
(id int primary key not null,
somevalue varchar(50));Хотя, как и ранее, это приведет к созданию имени ограничения по умолчанию, так что лучше сделать это так:
CREATE TABLE IF NOT EXISTS radio.radios
(radio_id int CONSTRAINT pkradios PRIMARY KEY
GENERATED ALWAYS AS IDENTITY,
radio_name varchar(100) NOT NULL,
manufacturer_id int NOT NULL,
picture BYTEA NULL,
connectortype_id int NOT NULL,
digitalmode_id int NULL);Будет создан первчный ключ с именем pkradios. Обратите также внимание на то, что я здесь использовал значение IDENTITY, чтобы обеспечить автоматическую генерацию значений при добавлении данных в таблицу.
Как и в случае ограничения уникальности, примеры которого приведены выше, вы можете определить первичный ключ в форме определения столбца. Вы должны использовать этот синтаксис, если ключ состоит из более чем одного столбца. Вы можете также изменить таблицу (ALTER), чтобы добавить ограничение первичного ключа. Кроме этого, поведение первчного ключа в основном идентично ограничению уникальности. Я все же всегда использовал бы определение первичного ключа, если нет других причин, как средство документирования.
Интересно, что если при создании ограничений первичного ключа значения, которые вы определяете как PRIMARY KEY, допускают значения NULL, ядро PostgreSQL попытается исправить это за вас. Например, рассмотрим следующую таблицу:
create table if not exists public.badpkexample
(id int null,
somevalue varchar(50));Проверим результаты следующего запроса к метаданным:
select is_nullable
from information_schema.columns
where table_schema = 'public'
and table_name = 'badpkexample'
and column_name = 'id';Будет возвращено YES. Это значит, что столбец допускает значения NULL. После добавления следующего ограничения:
alter table public.badpkexample
add constraint PKbadpkexample
primary key (id);запрос к метаданным теперь вернет NO. Т.е. произошло изменение определения столбца, который больше не допускает значений NULL. Если данные в столбце id уже содержат значения NULL, вы получите следующее сообщение об ошибке:
ERROR: column "id" of relation "badpkexample" contains null values
SQL state: 23502Ограничения внешнего ключа
Одной из ключевых концепций, лежащих в основе реляционных баз данных, является смысловая связь между таблицами. Внешние ключи определяют и управляют ссылочной целостностью одной таблицы с другой. В моей тестовой базе данных есть одна таблица для радио, а другая для производителей радио. Определение внешнего ключа между этими двумя таблицами выглядит так:
ALTER TABLE radio.radios
ADD foreign key (manufacturer_id)
references radio.manufacturers;Первичный ключ в radio.manufacturers состоит из столбца manufacturer_id. Имеется такой же столбец с совпадающим типом данных в radio.radios. Это позволяет мне создать внешний ключ между этими двумя таблицами. Обратите внимание, что хотя участвуют обе таблицы, мы изменяем только одну, чтобы добавить ограничение.
С установленным внешним ключом я смогу добавить только такие значения manufacturer_id в таблицу radio.radios, которые содержатся в первичном ключе таблицы radios.manufacturers. Кроме того, при наличии этого ограничения я не могу удалить строку с этим значением в таблице radio.manufacturers (подробности ниже). Так ограничение внешнего ключа помогает обеспечивать целостность данных.
Способ, с помощью которого я определил внешний ключ, будет генерировать имя по умолчанию. Я смогу контролировать имя, изменив код.
alter table radio.radios drop constraint radios_manufacturer_id_fkey;
alter table radio.radios
add constraint radios_fk_manufacturer
foreign key (manufacturer_id)
references radio.manufacturers;Я могу также добавить внешний ключ как часть определения таблицы:
create table if not exists radio.radios
(radio_id int constraint pkradios primary key
generated always as identity,
radio_name varchar(100) not null,
manufacturer_id int not null,
picture BYTEA null,
connectortype_id int not null,
digitalmode_id int null,
constraint radios_fk_manufacturer3
foreign key (manufacturer_id)
references radio.manufacturers
);Поведением по умолчанию внешнего ключа является проверка удаления строки в таблице, на которую ключ ссылается. Если значение существует, удаление останавливается. Вы можете непосредственно влиять на это поведение и менять его. Например, вы можете поменять его, когда внутри процесса транзакции выполняется проверка. Обычно это делается позже в процессе, но вы можете установить так, чтобы это происходило сначала с помощью опции ON DELETE RESTRICT:
create table if not exists radio.radios
(
radio_id int constraint pkradios primary key
generated always as identity,
radio_name varchar(100) not null,
manufacturer_id int not null,
picture BYTEA null,
connectortype_id int not null,
digitalmode_id int null,
constraint radios_fk_manufacturer3 foreign key
(manufacturer_id)
references radio.manufacturers ON DELETE RESTRICT
);Это изменит поведение по умолчанию. Вы можете также установить значение по умолчанию с помощью синтаксиса ON DELETE NO ACTION, но мне представляется, что это многословно и непонятно. Лучше просто использовать синтаксис по умолчанию. Позвольте мне уделить немного времени, чтобы показать вам диаграмму, описывающую это поведение DELETE:
Итак, поведение по умолчанию находит строки, которые должны быть удалены, удаляет их, затем проверяет, чтобы не было совпадающих строк в любых связанных таблицах. Так работает и SQL Server. Однако вы можете поменять, когда выполняется эта проверка, при помощи DELETE RESTRICT в определении внешнего ключа. В этом случае проверка нарушения огранчений внешнего ключа будет выполняться перед началом обработки транзакции.
Все это может показаться семантикой, но есть дополнительное поведение, которое вы можете добавить в свои транзакции в PostgreSQL. В этом поведении немного нюансов, и я кратко изложу их здесь. Вы можете непосредственно влиять, когда некоторые ограничения, в частности, UNIQUE, PRIMARY KEY, внешний ключ (REFERENCES) и EXCLUDE проверяются в отдельной транзакциию Поведение по умолчанию для этих ограничений описывается в соответствующем разделе. Но вы можете отсрочить их все на более позднее время в транзакции. Однако некоторые ограничения внешнего ключа могут быть нарушены с большей вероятностью. Их вы можете контролировать посредством этих установок, принуждая выполнять проверки раньше в транзакции, экономя на необязательной обработке и откатах транзакции. И наоборот, вы можете выполнять все проверки ограничений немедленно. К слову, ограничения NULL и CHECK всегда выполняются немедленно.
Вы также можете сделать так, чтобы при удалении строки в таблице radio.manufacturers все связанные строки в таблице radios также удалялись:
create table if not exists radio.radios
(radio_id int constraint pkradios primary key
generated always as identity,
radio_name varchar(100) not null,
manufacturer_id int not null,
picture BYTEA null,
connectortype_id int not null,
digitalmode_id int null,
constraint radios_fk_manufacturer foreign key
(manufacturer_id)
references radio.manufacturers on delete cascade
);Это то, что делает опция CASCADE. Однако здесь есть важные следствия. Таблица radio.radios также ссылается по внешнему ключу. Если мы попытаемся удалить строки из таблицы radio.radios, то потерпим неудачу, из-за этих других ограничений внешнего ключа. Пока мы не сделаем их также каскадными. Однако тут вы можете получить довольно неприятную проблему поведения вашей базы данных, т.к. будут удерживаться блокировки пока все различные таблицы не пройдут через каскадное удаление. Обычно это не считается хорошим способом поведения.
По большей части базы данных, которые я создавал, использовали значения идентификатора, которые не могли изменяться, поэтому я редко использовал следующие настройки, но PostgreSQL имеет некоторые дополнительные опции для ON DELETE, которые могут оказаться полезными в некоторых случаях.
Вы можете определить ON DELETE SET NULL. Это изменит значение, каким бы оно ни было, на значение NULL. Естественно, столбец должен допускать NULL-значения. Также можно определить ON DELETE SET DEFAULT. Тогда, каким бы ни было значение по умолчанию для столбца (мы уже обсуждали значения по умолчанию), оно будет подставляться вместо удаленных значений. Хотя опять таки, это значение по умолчанию должно удовлетворять фундаментальным требованиям ссылочной целостности, что подразумевает наличие этого значения в первичном ключе (в нашем примере в таблице radio.manufacturers).
Замечание. Вы можете определить ограничение внешнего ключа, которое ссылается на ограничение UNIQUE, но важно предупредить, что NULL-значения в столбце будут гарантровать выполнение соответствия. Как я продемонстрирую в разделе ограничений Check, ограничения нарушаются при условии false, но не для NULL (при сравнении любого значения с NULL).
Ограничения Check
Ограничение CHECK позволяет вам оределить свои собственные правила целостности данных для значений в строке. Это может быть что угодно - от значений в столбце, которые могут содержать только числа больше 100, до вычислений между столбцами. Смысл в том, что все проверки выполняются при вставке строки или при любом последующем обновлении, и могут получать доступ только к столбцам и значениям в той же строке.
Для примера в США самая низкая возможная частота, которую я могу использовать как радиолюбитель, составляет 135,7 кГц, а самая высокая — 1300 МГц или 1300000 кГц. Поэтому в моей таблице radio.bands, в которой отслеживаются частоты, я мог бы определить ограничение для столбца frequency_start_khz:
alter table radio.bands
add constraint minfrequency
check (frequency_start_khz >= 135.7);Теперь я не смогу случайно добавить значение, которое находится ниже моего возможного рабочего диапазона.
Для примера взамодействия столбцов, я мог бы обеспечить условие, чтобы frequency_start_khz всегда была меньше frequency_end_khz, которые определяют диапазон полосы частот:
ALTER TABLE radio.bands
ADD CONSTRAINT startlessthanend
CHECK (frequency_start_khz < frequency_end_khz); И при желании я мог бы сделать это в одной проверке:
alter table radio.bands
add constraint allinone
check (frequency_start_khz < frequency_end_khz
and frequency_start_khz > 135.7);Это действительно вопрос - как использовать ограничения. Я бы, вероятно, держал их отдельно, поскольку это облегчает понимание того, что делает каждое ограничение.
Как и с другими примерами ограничений в главе, вы можете также сделать ограничение частью определения столбца:
CREATE TABLE IF NOT EXISTS radio.bands
(
band_id int CONSTRAINT pkbands PRIMARY KEY
GENERATED ALWAYS AS IDENTITY,
band_name varchar(100) NOT NULL,
frequency_start_khz numeric(9,2) NOT null
CONSTRAINT minfrequency check (frequency_start_khz >135.7),
frequency_end_khz numeric(9,2) NOT NULL,
country_id int NOT NULL
);Как и ранее, если я не включаю имя ограничения, оно будет автоматически сгенерировано.
Следует сделать еще одно замечание относительно NULL-значений и ограничений. Ограничения работают несколько отлично от предложений WHERE. В предложении WHERE строка возвращается, когда результат равен TRUE. 1=1 возвращает TRUE, 1=2 возвращает FALSE, но 1=NULL есть UNKNOWN. Только значение TRUE будет возвращать результаты. В ограничениях данные их нарушают, только если сравнение дает FALSE.
Для примера рассмотрим следующую таблицу:
create table public.nullconstraintcheck
(
id int not null,
value int NULL
); Затем я добавлю ограничение CHECK, требующее, чтобы значение столбца равнялось 1.
alter table public.nullconstraintcheck
add constraint valueEquals1
check (value = 1);Представляется довольно ясным, какой из этих двух операторов INSERT отработает, а какой завершится неудачно:
insert into public.nullconstraintcheck(id, value)
values (1,1);
insert into public.nullconstraintcheck(id, value)
values (2,2);Второй оператор завершится с ошибкой:
ERROR: new row for relation "nullconstraintcheck" violates check constraint "valueequals1"
DETAIL: Failing row contains (2,2).Заметим, что если выполнить оба оператора в одном пакете, никаких строк не будет добавлено в таблицу. Однако следующий оператор выполнится успешно, поскольку NULL = 1 есть UNKNOWN, а не FALSE.
insert into public.nullconstraintcheck(id, value)
values (3,NULL);Если вам необходимо ограничение для учета NULL-значений в критерии, то следует явно включить выражение IS NULL или нечто подобное. Если вы хотите исключить NULL значения в некоторых условиях, то необходимо явно установить IS NOT NULL. Например, я изменю ограничение, допускающее NULL-значения, когда значения id меньше 5, но не допускающее NULL-значения при 5 и выше.
alter table public.nullconstraintcheck
drop constraint valueEquals1;
alter table public.nullconstraintcheck
add constraint valueEquals1
check ((value is not null and value = 1)
OR (id < 5 and value = 1));Теперь при выполнении следующих операторов:
insert into public.nullconstraintcheck(id,value)
values (4,NULL);
insert into public.nullconstraintcheck(id,value)
values (5,NULL);первый оператор будет успешен, а второй - нет.
ERROR: new row for relation "nullconstraintcheck" violates check constraint "valueequals1"
DETAIL: Failing row contains (5, null).Я настоятельно советую вам тщательно тестировать ограничения, особенно когда ссылочный столбец допускает NULL-значения.
Ограничения исключения
Ограничение исключения несколько похоже на ограничение уникальности, но есть отличие. В основном ограничение исключения гарантирует, что если сравниваются любые две строки, используя выражения, определенные в ограничении, и не все сравнения вернут TRUE, по крайней мере, одно должно вернуть FALSE или NULL. Идея состоит в том, чтобы иметь возможность определить более сложные ограничения для нескольких столбцов в таблице.
Сразу отметим, что если при сравнении столбцов используются только операторы равенства, то ограничение исключения в точности соответствует ограничению уникальности. Поэтому главное состоит в том, что когда вы имеете более сложное сравнение, чем простое равенство, но все же хотите иметь уникальные данные на основе этого сравнения, что бы это ни было, вы могли бы использовать ограчение исключения.
Прежде чем попытаться создать ограничения исключения, следует знать, что есть ограничения на типы данных, которые могут использоваться. Если вас интересуют даты, текст и тому подобные вещи, которые могут ограничивать строку и являются довольно стандартными, вам сначала нужно выполнить одну команду:
CREATE EXTENSION btree_gist;Это позволит вам накладывать ограничения на стандартные скалярные скалярные типы данных в противоположность массвам, геометрическим и другим более сложным типам. В этой серии статей я пытался строго придерживаться того, что «в коробке» с точки зрения функциональности PostgreSQL, то есть без расширений, но это воспрепятствует нашим намерениям. Видите ли, существуют просто тонны расширений. Некоторые, аналогично btree_gist, являются бесплатными и довольно фундаментальными для некоторых моделей поведения. За другие нужно заплатить, но они добавляют изумительное поведение. Сейчас я стараюсь изучить ядро PostgreSQL, а не все возможные расширения. Однако ограничения на стандартные типы данных весьма вероятны, поэтому я забегаю вперед и нарушаю свое собственное правило в этом отношении.
Имея это в виду, возьмем таблицу logging.logs:
CREATE TABLE IF NOT EXISTS logging.logs
(log_id int CONSTRAINT pklogs PRIMARY KEY
GENERATED ALWAYS AS IDENTITY,
log_date timestamptz NOT NULL,
log_callsign text,
log_location point NOT NULL);Я пытаюсь определить ограничение, при котором log_date, log_callsign могут быть одинаковыми, в то время как log_location меняться. Это было бы полезно для такого конкурса, как парки в эфире, где вы можете говорить с некоторыми людьми, но ваше местонахождение может меняться, означая, что вы находитесь в другом парке. Это ограничение можно было бы определить так:
alter table logging.logs
add constraint uniquecontact exclude
using gist (log_date with =,
log_callsign with =,
log_location with ~=);Затем я могу добавить некоторые данные в таблицу:
INSERT INTO logging.logs
(log_date,log_callsign,log_location)
VALUES
('12/21/2022','KC1KCE','35.952, -96.152'),
('12/21/2022','KC1KCE','35.957, -96.127');И это отработает отлично. Несмотря на то, что log_date и log_callsign одинаковы, log_location различается. Если теперь я попробую добавить это:
INSERT INTO logging.logs
(log_date,log_callsign,log_location)
VALUES
('12/21/2022','KC1KCE','35.952, -96.152');то получу следующую ошибку:
SQL Error [23P01]: ERROR: conflicting key value violates exclusion constraint "uniquecontact"
Detail: Key (log_date, log_callsign, log_location)=(2022-12-21 00:00:00-06, KC1KCE, (35.952,-96.152)) conflicts with existing key (log_date, log_callsign, log_location)=(2022-12-21 00:00:00-06, KC1KCE, (35.952,-96.152)).Хотя вы можете выполнить некоторые сложные вещи с помощью этого ограничения, стоит отметить, что ограничение исключения далеко не лучшее ограничение с точки зрения прозводительности. Где это возможно рекомендуется использовать ограничения уникальности, поскольку они лучше в этом отношении. Однако, когда имеются конкретные требования, ограничение исключения может решить проблему.
Заключение
Это все типы ограничений в PostgreSQL. Они позволят вам обеспечить, насколько это возможно, чистоту данных. Если вы использовали другую РСУБД, подобную SQL Server, большнство из этих ограничений покажутся вам очень знакомыми, как и поведение ограничений. Некоторые вещи, как-то возможность управлять тем, как значения NULL разрешаются в ограничениях уникальности, или концепция ограничения исключения, будут для вас новыми. В целом, я впечатлен функциональностью, которая предоставляется ограничениями в PostgreSQL.
Стаьи по теме
- Типы данных в PostgreSQL: изучаем PostgreSQL с Grant Fritchey
- Создание резервных копий и восстановление в PostgreSQL: Изучение PostgreSQL с Grant Fritchey
- Создание базы данных и таблиц в PostgreSQL: Изучение PostgreSQL с Grant Fritchey
- Типы индексов в PostgreSQL: изучаем PostgreSQL вместе с Grant Fritchey
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой