
Обзор соединений в PostgreSQL
Пересказ статьи Everett Berry. Inspecting Joins in PostgreSQL
PostgreSQL использует различные алгоритмы для реализации JOIN в зависимости от запроса. Мы можем исследовать план запроса, чтобы выяснить, какой тип был использован.
Введение
Реляционные базы данных распределяют свои данные по многим таблицам в соответствии с правилами нормализации или бизнес-сущностями. Это упрощает поддержку растущей схемы базы данных. Реальные запросы зачастую обращаются к нескольким таблицам, что неизбежно приводит к соединению этих таблиц.
PostgreSQL использует много алгоритмов соединения таблиц. В этой статье мы рассмотрим, как соединения работают за сценой с точки зрения планировщика, и поймем, как их оптимизировать.
Вкратце о планировании запросов
Прежде чем погрузиться в тему, немного предварительного чтения. Эта публикация является третьей в серии статей, предназначенной для понимания различных частей плана запроса. Перечисленные ниже статьи могут оказаться полезными для вас. Данная статья относится к узлу JOIN и различным алгоритмам, которые PostgreSQL использует для выполнения соединений.
Установка данных
Чтобы понять, как PostgreSQL готовит планы для запросов с соединением, нам потребуется установить данные для экспериментов.
Схема
Пусть у нас имеется две таблицы, которые имеют следующую структуру:
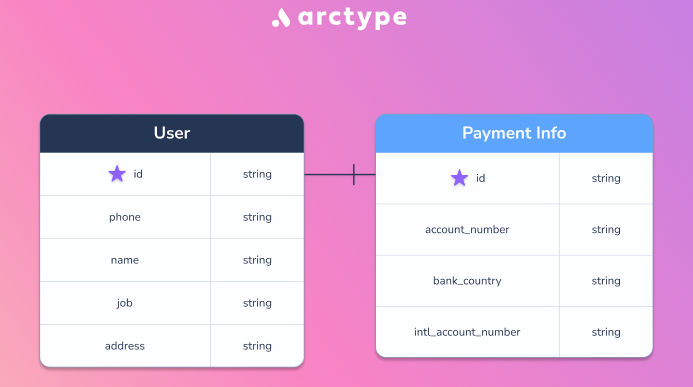
Эти таблицы предназначены, главным образом, для тестирования и сами объясняют, что в них хранится. Они соединяются по столбцу id, и имеют связь один-к-одному. Запросы создания таблиц приведены ниже:
CREATE TABLE IF NOT EXISTS user_info(
id text,
phone text,
name text,
job text,
address text
);
CREATE TABLE IF NOT EXISTS payment_info(
id text,
account_number text,
intl_account_number text,
bank_country text
);Генерация данных
Мы собираемся использовать библиотеку faker в Питоне для генерации некоторого количества фейковых пользовательских данных. Ниже код, используемый для генерации CSV файлов для данных:
from faker import Faker
import uuid
faker = Faker()
# Измените этот диапазон на требуемый
ROW_COUNT = 1000000
u_info = open('user_info.csv', 'w')
acc_info = open('account_info.csv', 'w')
for i in range(0, ROW_COUNT):
user_id = uuid.uuid4()
phone_number = faker.phone_number()
name = faker.name()
job = faker.job().replace(',', '')
address = faker.address().replace(',', '').replace('\n', '')
bank_country = faker.bank_country()
account_number = faker.bban()
intl_account_number = faker.iban()
user_info = f"'{user_id}','{phone_number}','{name}','{job}','{address}' \n"
account_info = f"'{user_id}','{account_number}','{bank_country}','{intl_account_number}' \n"
u_info.write(user_info)
acc_info.write(account_info)
u_info.close()
acc_info.close()Загрузка данных
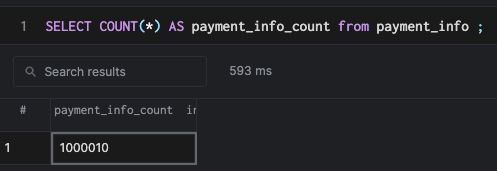
Я создал миллион строк с помощью скрипта выше, и загрузил данные в PostgreSQL, используя следующие команды:
COPY user_info(id, phone, name, job, address) FROM '/path/to/csv' DELIMITER ',';
COPY payment_info(id, account_number, bank_country, intl_account_number) FROM '/path/to/csv' DELIMITER ','; 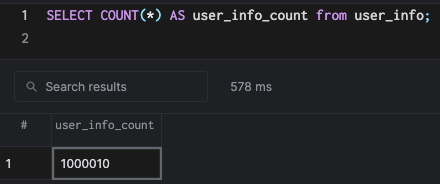
Алгоритмы JOIN
Давайте начнем с запросов к таблицам, которые мы создали и наполнили данным. Мы выполним несколько запросов и будем использовать EXPLAIN для анализа плана запроса. Как и в статье по узлам сканирования, мы установим максимальное число рабочих в нуль, чтобы наши планы выглядели проще.
SET max_parallel_workers_per_gather = 0;Наконец, мы посмотрим на параллелизацию в соединениях в образовательных целях.
Hash Join (хэш-соединение)
Давайте выполним простой запрос, который соединяет данные из двух таблиц.
SELECT
*
from
user_info
JOIN payment_info on user_info.id = payment_info.id
LIMIT
10Выполнение explain для этого запроса сгенерирует hash join.
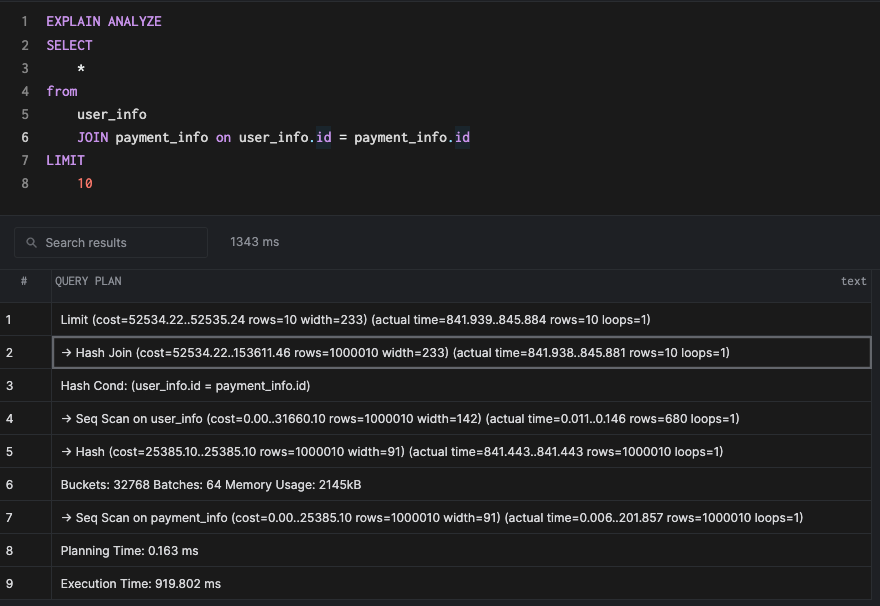
Как и предполагает имя, хэш-соединение строит хэш-таблицу на основе ключа соединения. В нашем примере мы создадим хэш-таблицу на столбце id таблицы user_info. Затем мы будем использовать эту таблицу для сканирования внешней таблицы payment_info. Построение хэш-таблицы добавляет стоимость, но помните, что поиск (построенный на хорошей хэш-функции) имеет эффективность O(1) в терминах асимптотической сложности. Планировщик обычно решает выполнить хэш-соединение, когда таблицы имеют более или менее одинаковый размер, и хэш-таблица может разместиться целиком в памяти. Индекс мало чем может помочь в этом случае, поскольку построение хэш-таблицы реализуется последовательным сканированием (сканированием всех строк, имеющихся в таблице).
Nested Loop (вложенные циклы)
Теперь построим запрос, в котором мы хотим выбрать все данные из обеих таблиц при условии, что ID таблицы user_info меньше, чем ID таблицы payment_info. Этот запрос может не иметь смысла в реальном мире, но вы сможете провести параллели, где может потребоваться соединение на базе такого условия. Это обычно называют "декартовым произведением".
SELECT
*
from
user_info, payment_info
WHERE user_info.id < payment_info.id
LIMIT
10
OFFSET 200Это приводит к соединению вложенными циклами.
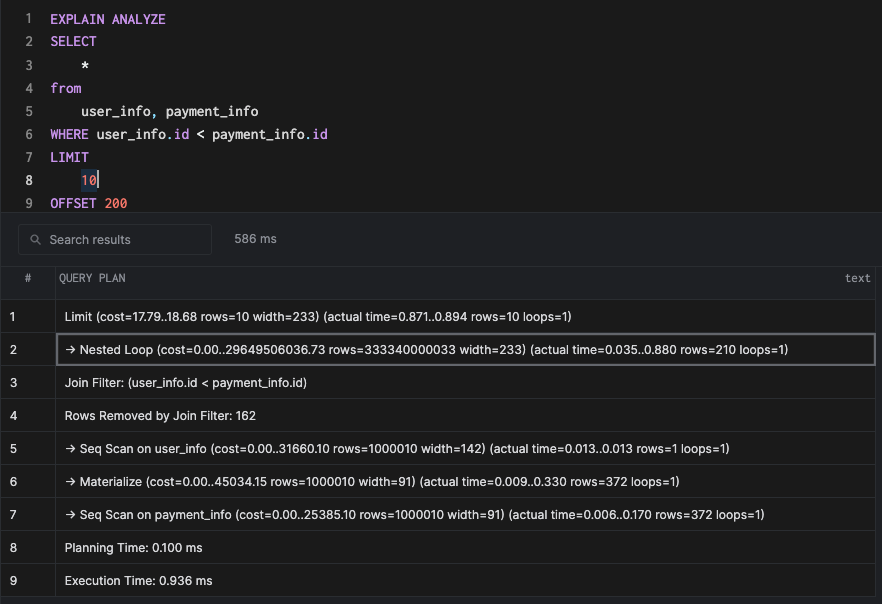
Вложенные циклы - один из простейших и, следовательно, наиболее наивный из возможных соединений. Он просто берет ключ соединения из одной таблицы и проходит через все ключи соединения во второй таблице во вложенном цикле. Другими словами, цикл внутри цикла:
for id as id_outer in user_info:
for id as id_inner in payment_info:
if id_outer == id_inner:
return true
else
return falseВложенные циклы выбираются планировщиком при следующих условиях:
- Условие соединения не использует оператор = .
- Внешняя таблица соединения меньше, чем внутренняя таблица.
Эти сценарии обычно имеют место при отношении многие-к-одному и итерации внутреннего цикла небольшие.
Merge Join (соединение слиянием)
Давайте создадим индексы на обеих таблицах на ключе соединения.
CREATE index id_idx_usr on user_info using btree(id);
CREATE index id_idx_payment on payment_info using btree(id);Если выполнить тот же запрос, который мы использовали в примере хэш-соединения, то получим следующее:
SELECT
*
from
user_info
JOIN payment_info on user_info.id = payment_info.id
LIMIT
10
План может показаться знакомым, если вы прочитали блог о сканировании ранее, поскольку он использует то, что называется index scan (сканирование индекса), но давайте сфокусируемся на алгоритме соединения. Поскольку мы имеем индексы на обеих таблицах, и индекс BTree сортирован по умолчанию, планировщик может выбирать строки из индекса в отсортированном порядке и выполнять слияние, как показано в узле плана Merge Cond. Это значительно быстрей, чем любой другой метод соединения из-за индекса.
Параллельные соединения
Давайте прервем сессию базы данных (чтобы отменить настройку max_parallel_workers_per_gather), а затем удалим все индексы для запуска исходного запроса. Это приведет к параллельному хэш-соединению, которое является параллельной версией первоначального хэш-соединения.
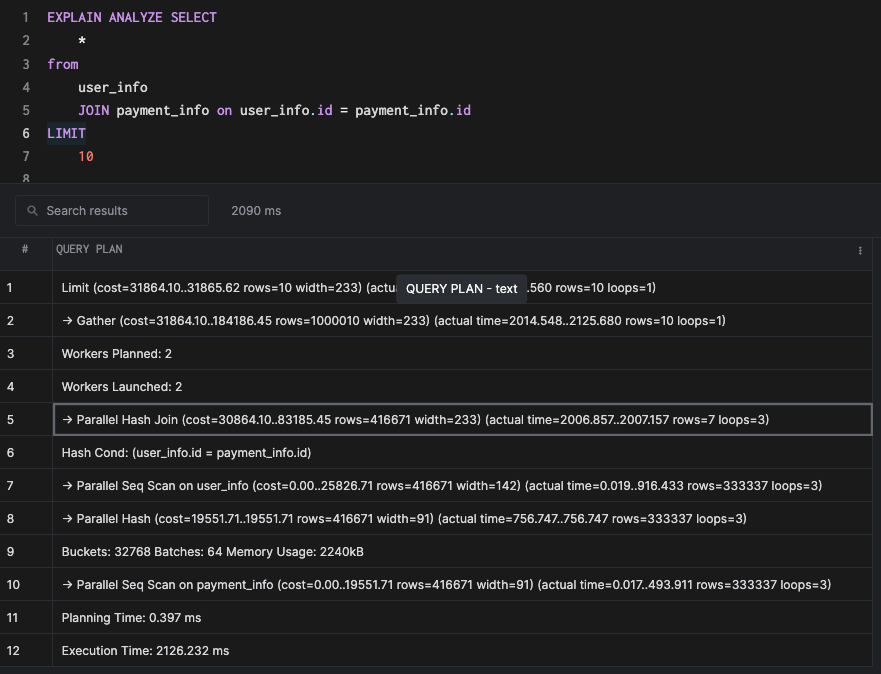
Подобно параллельному сканированию, параллельные соединения задействуют несколько ядер для ускорения выполнения. В реальных условиях параллельные соединения/сканирования могут как ускорить, так даже и замедлить выполнение в зависимости от различных факторов. Параллельные запросы требуют отдельной статьи для того, чтобы разобраться в них досконально.
Понимание настройки рабочей памяти
Это пространство памяти, которое используется PostgreSQL для выполнения соединений, сортировки и других агрегатных операций. По умолчанию используется 4 Мб памяти, и каждая операция соединения может использовать до 4 Мб. Мы должны быть осторожны с этой настройкой, поскольку возможны конкурирующие соединения, и каждое из них может использовать установленный объем в производственной базе данных. Если эта настройка выше требуемой, это может вызвать проблемы производительности, и даже вырубить саму базу данных. Как обычно, рекомендуется перед изменением значения настройки выполнять тестирование производительности.
Имеются друге настройки, например, hash_mem_multiplier и logical_decoding_work_mem, которые могут оказать влияние на производительность соединения, но в типичных производственных настройках все ключи/столбцы соединения должны быть проиндексированы, а настройка work_mem должна быть установлена в подходящее значение для обслуживания рабочих нагрузок приложений.
Заключение
Мы выполнили масштабную настройку данных, поэтому я настоятельно рекомендую читателям найти время для понимания узлов соединения, упомянутых в настоящей статье. Вы можете свободно экспериментировать с различными шаблонами запросов, наблюдая как планировщик ведет себя при комбинации таких запросов. Соединения являются критической частью функциональности для любой реляционной базы данных, и важно понимать работу планировщика. Итак:
- Следует создавать индексы BTree на ключах соединений для ускорения операций соединения.
- Если индексирование недоступно, то попытайтесь оптимизировать установку work_mem с тем, чтобы хэш-соединения могли полностью выполняться в памяти, а не сбрасывали данные на диск.
- Соединения вложенными циклами должны быть последним из вариантов, и они обычно содержат сравнения типа < , > для ключей соединения.
- Планировщик может комбинировать индексы для других операций типа сканирования (Scans), и существенно ускоряет запросы. Индексы BTree - очень мощное средство, имеющее широкий диапазон применения.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой