
Анатомия плана запроса в PostgreSQL
Пересказ статьи Everett Berry. Anatomy of a PostgreSQL Query Plan
Начинать оптимизацию запроса следует с планировщика запросов (Query Planner). В этой статье объясняется, как выполняется запрос, и как понимать команду EXPLAIN.
Введение
Понимание плана запроса в PostgreSQL является критичным навыком для разработчиков и администраторов баз данных. Это, вероятно, первое, на что мы должны обратить внимание в начале оптимизации запроса, а также первая вещь для проверки того, действительно ли ваш оптимизированный запрос оптимизирован так, как вы ожидали.
Жизненный цикл запроса в базе данных PostgreSQL
Прежде чем пытаться прочитать план запроса, важно задать несколько основных вопросов:
- Зачем нам вообще нужен план запроса?
- Что точно представлено в плане?
- PostgreSQL недостаточно умен, чтобы оптимизировать мои запросы автоматически? Почему я должен беспокоиться о планировщике?
- Планировщик - это единственное, куда я должен смотреть?
Каждый запрос проходит несколько различных стадий, и важно понимать, что каждая стадия означает для базы данных.
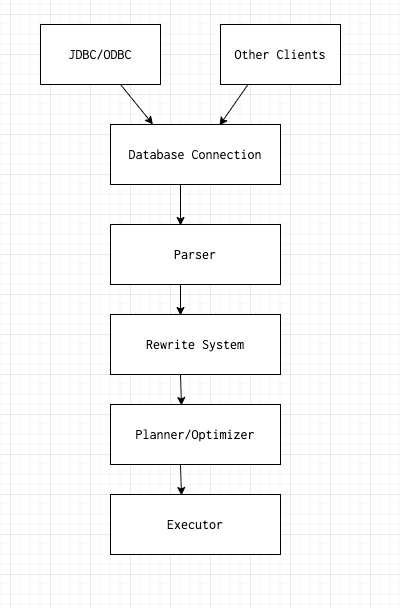
Диаграмма жизненного цикла запроса в PostgreSQL
Первая фаза - это подключение к базе данных либо через ODBC/JDBC (API, созданный Microsoft и Oracle, соответственно, для взаимодействия с базами данных), либо другими средствами типа PSQL (интерфейс терминала для Postgres).
Вторая фаза предназначена для трансляции запроса в промежуточный формат, известный как дерево разбора. Обсуждение внутреннего устройства дерева разбора выходит за рамки настоящей статьи, но вы можете представить себе это как скомпилированную форму запроса SQL.
Третья фаза это то, что мы называем системой перезаписи системы/правил. Она берет дерево разбора, сгенерированное на втором этапе, и переписывает его в виде, с которым может начать работать планировщик/оптимизатор.
Четвертая фаза является наиболее важной, это сердце базы данных. Без планировщика исполнительный механизм будет решать вслепую, как выполнить запрос, какие индексы использовать, стоит ли сканировать небольшие таблицы для исключения уже ненужных строк и т.д. Это стадия как раз будет обсуждаться в этой статье.
Пятая и последняя фаза - это исполнитель, который фактически выполняет план и возвращает результат. Почти все системы баз данных следуют процессу, который более или менее соответствует изложенному выше.
Установка данных
Давайте установим некую фиктивную таблицу с тестовыми данными для выполнения экспериментов.

Затем наполним эту таблицу данными. Я использовал скрипт Python, приведенный ниже, для генерации случайных строк.
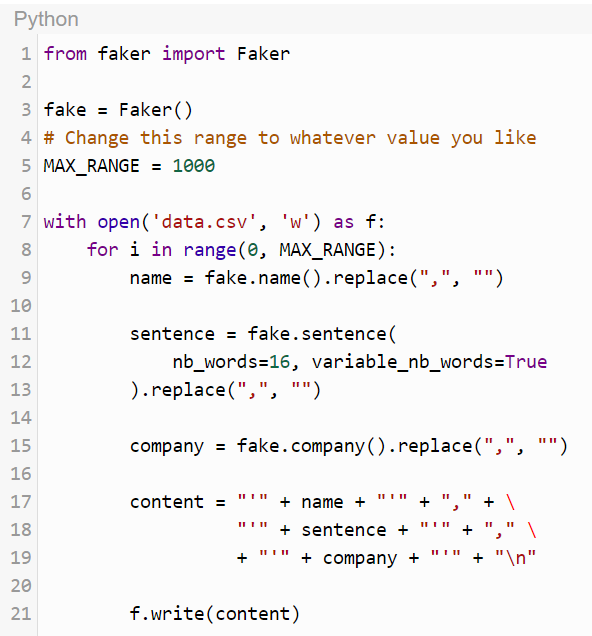
Скрипт использует библиотеку Faker для генерации тестовых данных. Он генерирует csv файл на корневом уровне, который может быть импортирован как обычный csv в PostgreSQL при помощи следующей команды.

Поскольку id есть serial, он будет автоматически заполняться самим PostgreSQL.

Теперь таблица содержит 1119284 записей.
Большинство последующих примеров будут основаны на этой таблице. Она намеренно сделана простой, чтобы сфокусироваться на процессе, а не на сложности таблицы/данных.
Переходим к этапу планирования
PostgreSQL и многие другие системы баз данных позволяют пользователям видеть то, что фактически происходит под капотом на этапе планирования. Мы можем сделать это, выполняя то, что называется командой EXPLAIN (объяснить).
ОБЪЯСНЕНИЕ запроса в PostgreSQL
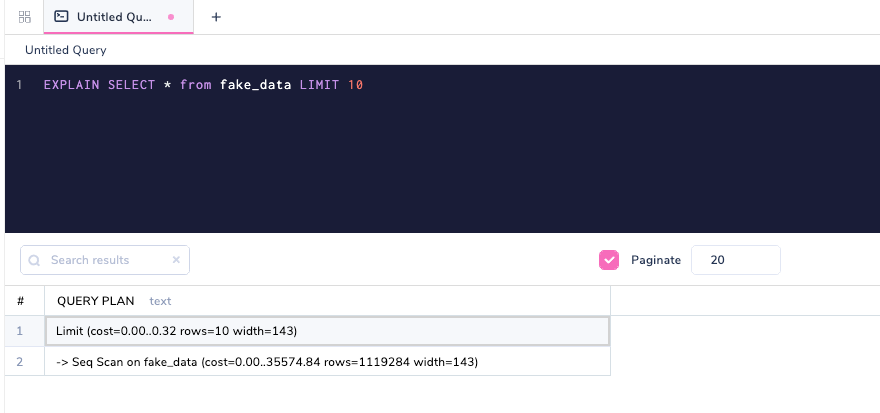
При использовании EXPLAIN вы можете посмотреть планы запросов до их фактического выполнения базой данных. Мы перейдем к пониманию каждого из них ниже, но давайте сначала взглянем на другую расширенную версию EXPLAIN, которая называется EXPLAIN ANALYSE.
Объяснение и анализ вместе
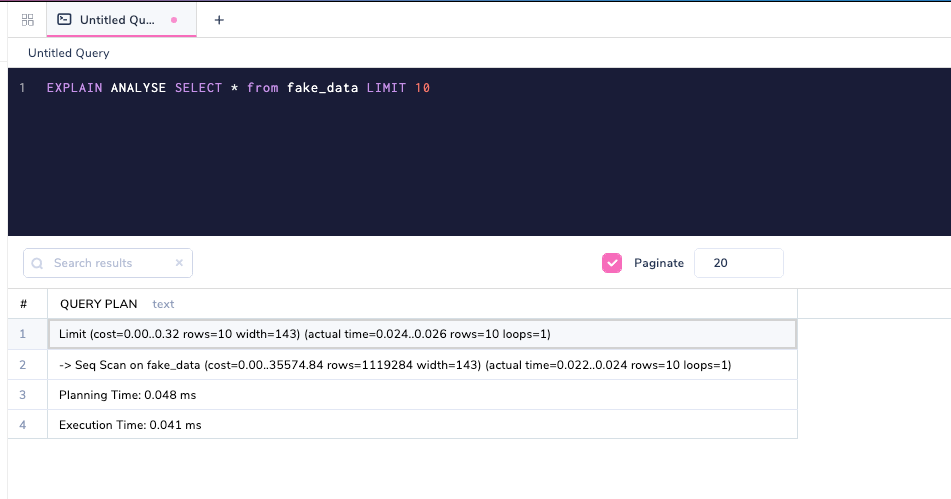
Добавление аргумента ANALYZE к запросам выводит информацию о времени.
В отличие от EXPLAIN, EXPLAIN ANALYSE фактически выполняет запрос в базе данных. Этот вариант весьма полезен для понимания ситуации, когда планировщик играет свою партию неверно; т.е. имеется ли огромное различие в генерируемом плане между EXPLAIN и EXPLAIN ANALYSE.
Что такое буферы и кэши в базах данных?
Давайте перейдем к более интересной метрике, которая называется BUFFERS. Она объясняет как много данных приходит из кэша PostgreSQL и как много считывается с диска.
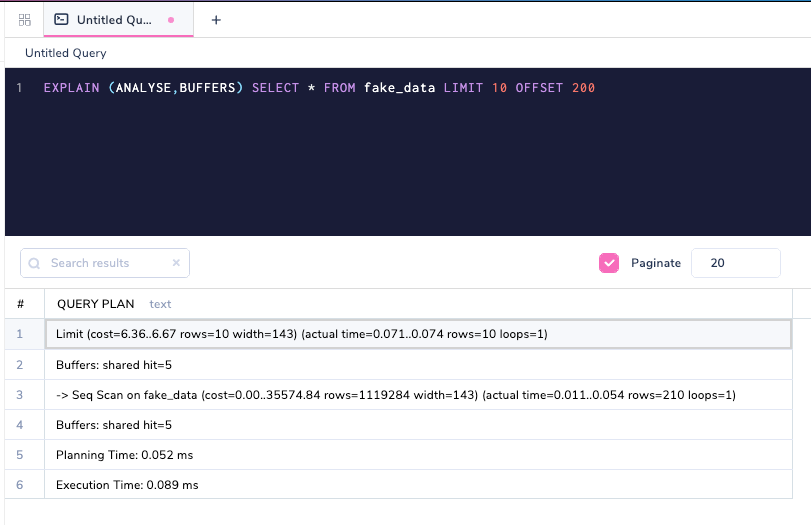
Включение BUFFERS в качестве аргумента показывает, сколько страниц попадает в запрос.
Buffers : shared hit=5 означает, что пять страниц было извлечено из кэша самого PostgreSQL. Давайте настроим смещение в запросе для получения отличных строк.
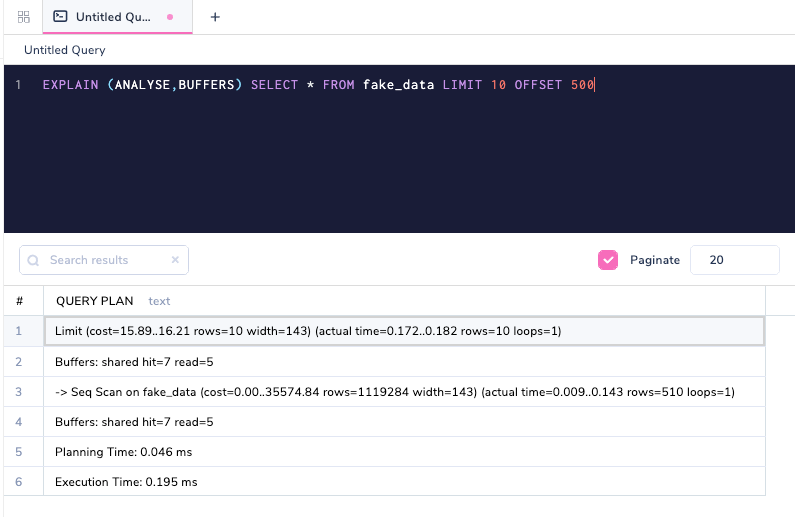
Изменение OFFSET приводит к отличающемуся числу запросов страниц.
Buffers: shared hit=7 read=5 показывает, что 5 страниц бралось с диска. Часть read - это переменная, которая показывает как много страниц читались с диска, а hit, как уже объяснялось, берутся из кэша. Если мы выполним тот же запрос опять (помним, что ANALYSE выполняет запрос), то теперь все данные будут находиться в кэше.
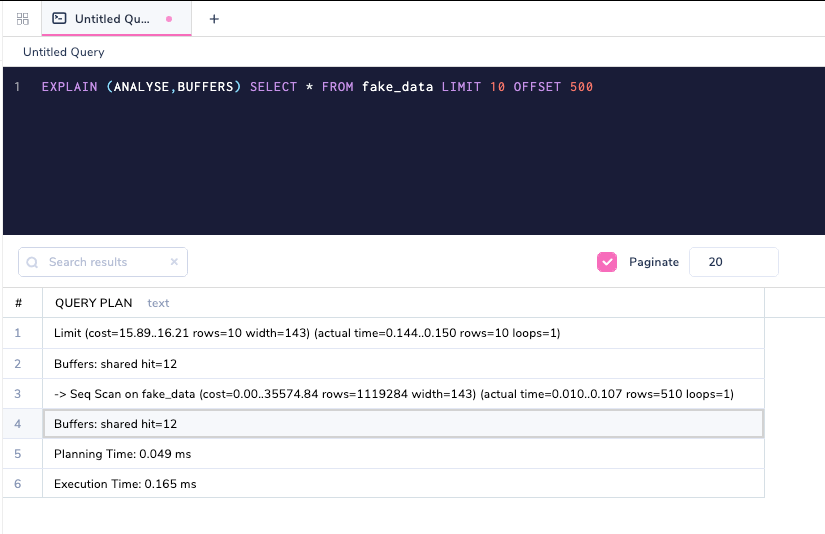
Повторное выполнение запроса показывает, что кэш теперь предоставляет все результаты.
PostgreSQL использует механизм кэша, называемый LRU (Least Recently Used - реже всего используемые за последнее время), для хранения в памяти часто используемых данных. Понимание того, как работает кэш, и его важность, это материал для другой статьи, но сейчас мы должны осознать, что PostgreSQL имеет надежный механизм кэширования, и мы можем увидеть его работу, используя команду EXPLAIN (ANALYSE, BUFFERS).
Аргумент команды VERBOSE
Verbose - еще один аргумент команды, который дает дополнительную информацию.
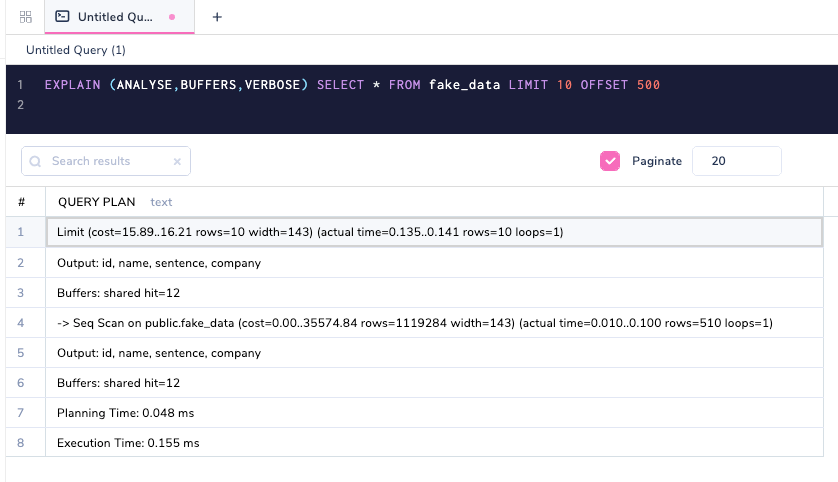
Аргумент команды VERBOSE даст еще больше информации для сложного запроса.
Заметим, что Output: id, name, sentence, company является дополнительным. В плане сложного запроса будет много другой информации, которая будет напечатана. По умолчанию опции COSTS и TIMING установлены в TRUE, и нет необходимости указывать их явно, если вы не захотите их отключить (FALSE).
FORMAT в объяснении PostgreSQL
PostgreSQL имеет возможность представлять план в замечательном формате, таком как JSON, поэтому эти планы могут интерпретироваться независимым от языка способом.

Этот запрос напечатает план запроса в формате JSON. Вы можете просмотреть этот формат в Arctype, скопировав его вывод и вставив его в другую таблицу, как показано ниже в GIF.
Вставка вывода EXPLAIN JSON в таблицу, и использование просмотра JSON для проверки.
Имеются другие форматы:
- Text (по умолчанию)
- JSON (в примере выше)
- XML
- YAML
Имеется две других опции, именуемые SETTINGS и WAL, которые могут быть включены в план запроса, но они выходят за рамки этой конкретной статьи.
Итак:
- EXPLAIN - тип плана, с которого вы обычно начинаете, и используемый, главным образом, в промышленных системах.
- EXPLAIN ANALYSE используется для выполнения запроса, наряду с получением плана запроса. Так вы получаете разбивку в плане времени планирования и времени выполнения, и сравнение по стоимости и фактическое время выполненного запроса.
- EXPLAIN (ANALYSE, BUFFERS) используется поверх анализа для получения числа строк, читаемых из кэша и диска, и того, как ведет себя кэш.
- EXPLAIN (ANALYSE, BUFFERS, VERBOSE) для получения подробной и дополнительной информации, относящейся к запросу.
- EXPLAIN(ANALYSE,BUFFERS,VERBOSE,FORMAT JSON) - какой формат вывода вы хотите получить; в данной случае JSON.
В следующем разделе мы будем использовать эти инструменты для выяснения работы плана запроса в PostgreSQL. Для простоты бы будем рассматривать только текстовый формат (Text) плана запроса.
Элементы плана запроса
Любой план запроса вне зависимости от сложности обладает некоторой фундаментальной структурой. В этом разделе мы сфокусируем внимание на этих структурах, которые помогут нам понять план запроса в абстрактной манере.
Узлы запроса
План запроса состоит из узлов:
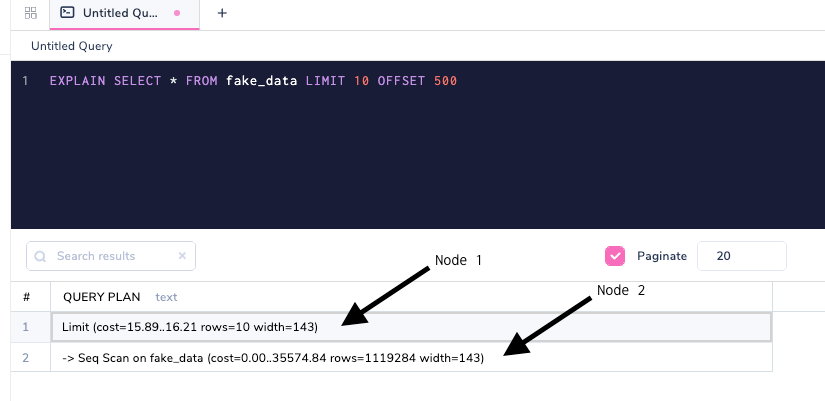
Узлы - ключевая часть выполнения запроса
Узел можно представлять себе как этап выполнения запроса базой данных. Узлы зачастую являются вложенными, как показано выше; Seq Scan выполняется раньше, после чего применяется предложение Limit. Давайте добавим предложение Where, чтобы понять дальнейшее вложение.


Выполнения следует порядку изнутри наружу.
- Фильтрация строк по имени Sandra Smith.
- Выполнение последовательного сканирования при применении вышеприведенного фильтра.
- Применение предложения limit наверху.
Как можно видеть, база данных понимает, что необходимы только 10 строк, и сканирование не будет продолжено, как только будут получены требуемые 10 строк. Пожалуйста, отметьте, что я отключил SET max_parallel_workers_per_gather =0; поэтому этот план получился проще. Мы исследуем параллелизм в последующей статье.
Стоимость в планировщике запросов
Стоимости являются решающей частью плана запроса к базе данных, и они легко могут быть неправильно поняты из-за того, в каком виде они представлены. Давайте посмотрим снова на простой план со стоимостью.
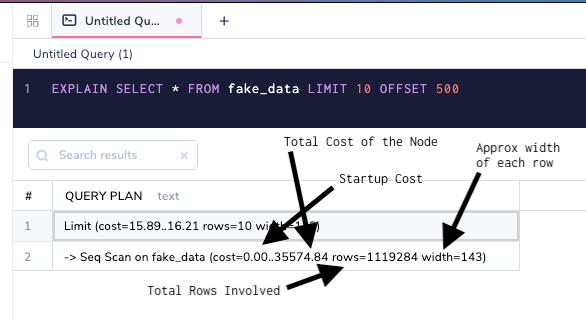
Стоимость представлена внутри вывода EXPLAIN.
Важно отметить следующие вещи:
- Начальная стоимость предложения LIMIT не равна нулю. Это потому, что стоимости выполнения суммируются снизу вверх, и то, что вы видите, есть стоимость узлов, расположенных ниже.
- Полная стоимость является произвольной мерой, и более актуальна для планировщика, чем для пользователя. В любом случае вы никогда не получите на практике данные всей таблицы одновременно.
- Последовательное сканирование имеет заведомо плохие оценки, поскольку база данных не имеет вариантов оптимизировать его. Индексы могут резко увеличить скорость запросов с предложением WHERE.
- Width (ширина) важна, поскольку, чем шире строка, тем больше данных приходится читать с диска. Вот почему очень важно придерживаться правил нормализации таблиц базы данных.
Если мы действительно выполним запрос, то стоимости будут иметь больше смысла.
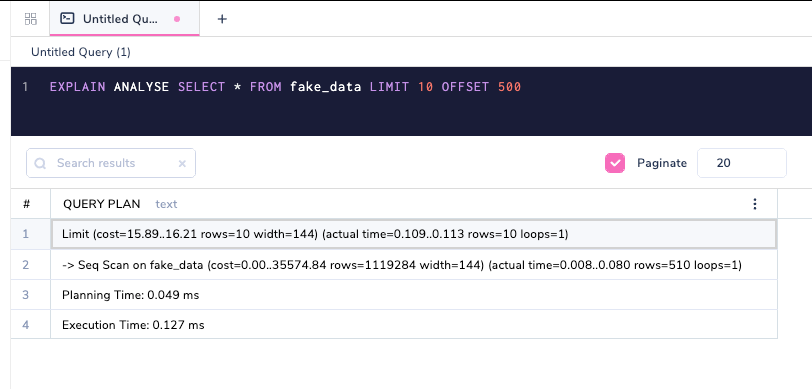
Планирование и выполнение базой данных
Время планирования и выполнения - это метрики, которые выводятся только с опцией EXPLAIN ANALYSE.
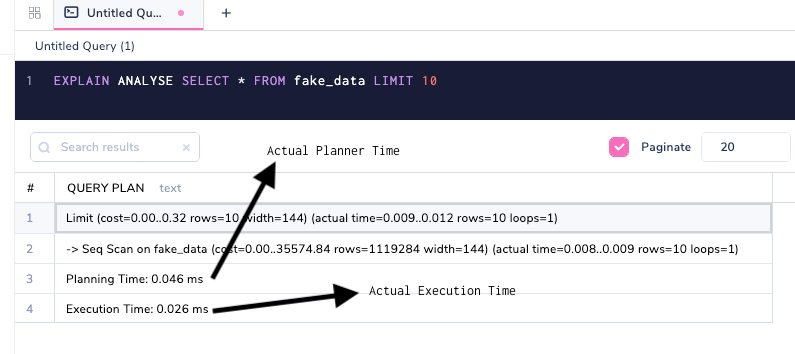
Планирование и выполнение - это две разные фазы выполнения запроса.
Планировщик (Planning Time - время планирования) решает, как запрос должен выполняться на основе различных параметров, а исполнитель (Execution Time) выполняет запрос. Эти указанные выше параметры являются абстрактными и применяются к любому типу запросов. Время выполнения представлено в миллисекундах. Во многих случаях время планирования и время выполнения могут различаться и, как в примере выше, планировщику может потребоваться больше времени для планирования запроса, а исполнителю требуется меньше времени, что обычно не так. Им не обязательно необходимо соответствовать друг другу, но если они сильно расходятся, тогда пора задуматься о том, почему это произошло.
В типичных OLTP системах, к которым относится и PostgreSQL, любая комбинация планирования и выполнения должна быть менее 50мс, если это не аналитический запрос/огромные записи/известные исключения. Напомним, что OLTP - это оперативная обработка транзакций. В типичном бизнесе выполняется от сотен до миллионов транзакций. Всегда следует очень внимательно следить за временем выполнения, поскольку запросы с невысокой стоимостью могут в сумме добавить высокие накладные расходы.
Куда двигаться дальше
Мы прошли путь от рассмотрения жизненного цикла запроса до того, как планировщик принимает свои решения. Я намеренно не касался таких вопросов, как типы узлов (сканирование, сортировка, соединения), поскольку каждый из них требует отдельной статьи. Целью настоящей статьи является дать общее понимание того, как работает планировщик, что влияет на его решения и какие инструменты предоставляет PostgreSQL для лучшего понимания планировщика.
Давайте вернемся к вопросам, которые мы задавали выше.
Q: Зачем нам вообще нужен план?
A: "Дурак с планом лучше, чем гений без плана!" - старая поговорка. План абсолютно необходим, чтобы решить, какой путь избрать, особенно когда решение принимается на основе статистики.
Q: Что точно находится в плане?
A: План состоит из узлов, стоимостей, времени планирования и времени выполнения. Узлы - это фундаментные блоки построения запроса. Стоимость - это основной атрибут узла. Время планирования и выполнения показывает фактическое время.
Q: Разве PostgreSQL недостаточно умен, чтобы оптимизировать мои запросы автоматически? Почему я должен беспокоиться о планировщике?
A: PostgreSQL действительно умен настолько, насколько это возможно. Планировщик становится лучше и лучше с каждым релизом, но не существует такого полностью автоматизированного/совершенного планировщика. В действительности это непрактично, т.к. оптимизация может быть хорошей для одного запроса, но плохой для другого. Планировщик должен где-то прочертить линию и обеспечить согласованное поведение и производительность. Большая ответственность лежит на разработчиках/администраторах баз данных, чтобы писать оптимизированные запросы и лучше понимать поведение базы данных.
Q: Достаточно ли мне смотреть только на планировщика?
A: Конечно, нет. Имеется много других вещей, таких как предметная экспертиза приложения, проектирование таблиц, архитектура базы данных и т.д., которые очень важны. Но вам, как разработчику/администратору баз данных, понимание и улучшение этих абстрактных навыков чрезвычайно важно для карьерного роста.
С этими фундаментальными знаниями мы теперь можем уверенно читать любой план и понимать, что происходит на высоком уровне. Оптимизация запросов очень обширная тема, которая требует знания множества вещей, происходящих внутри базы данных. В последующих статьях мы увидим, как планируются и выполняются запросы и их узлы, какие факторы влияют на поведение планировщика, и как мы можем оптимизировать их.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой