
Некоторые преобразования агрегата ANY нарушаются
Пересказ статьи Paul White. Some ANY Aggregate Transformations are Broken
Агрегат ANY - это не то, что мы можем непосредственно написать на Transact SQL. Это только внутренняя функция, используемая оптимизатором запросов и движком.
Я сам очень люблю агрегат ANY, поэтому был несколько огорчен, узнав, что он нарушается довольно фундаментальным образом. Говоря «нарушается», я имею в виду получение неправильных результатов.
Здесь я рассмотрю два конкретных случая, где обычно присутствует агрегат ANY, для демонстрации проблемы неправильных результатов и предложу при необходимости обходные пути.
Для введения в курс дела, посмотрите мою предыдущую статью на тему агрегата ANY .
Это должно быть одним из наиболее общих требований к ежедневным запросам при очень хорошо известном решении. Вы, вероятно, пишете такого типа запросы каждый день, автоматически следуя шаблону, не задумываясь об этом.
Идея состоит в нумерации входного набора строк с помощью оконной функции ROW_NUMBER, разбитого по столбцу или столбцам группировки. Это заворачивается в общее табличное выражение или производную таблицу и отфильтровывается по условию равенства единице вычисляемого столбца с номером строки. Поскольку ROW_NUMBER стартует с единицы для каждой группы, это дает нам одну требуемую строку на группу.
С этим общим шаблоном нет проблем. Тип запроса с одной строкой на группу, который связан с проблемой агрегата ANY, имеет место, когда мы не заботимся о том, какая конкретная строка выбирается для каждой группы.
В этом случае неясно, какой столбец следует использовать в обязательном предложении ORDER BY оконной функции ROW_NUMBER. В конце концов, нас совершенно не заботит, какая строка выбирается. Обычным приемом является еще раз использовать столбцы, указанные в PARTITION BY, в предложении ORDER BY. Здесь и может возникнуть проблема.
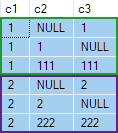
Давайте рассмотрим пример, использующий игрушечный набор данных:
Требуется вернуть одну любую полную строку данных из каждой группы, членство в которой определяется значением в столбце c1.
Следуя шаблону ROW_NUMBER, мы можем написать подобный следующему запрос (обратите внимание на то, что предложение ORDER BY соответствует предложению PARTITION BY):
Как показано, этот запрос выполняется успешно, давая корректные результаты. Эти результаты технически недетерминированы, поскольку SQL Server может на самом деле вернуть любую из строк в каждой группе. Тем не менее, если вы сами выполните этот запрос, то вполне вероятно увидите те же результаты, что и я:

План выполнения зависит от используемой версии SQL Server и не зависит от уровня совместимости базы данных.
На SQL Server 2014 и более ранних версиях план имеет вид:

Для SQL Server 2016 и более поздних версий вы можете увидеть:

Оба плана безопасны, но по разным причинам. План с Distinct Sort содержит агрегат ANY, но реализация оператора Distinct Sort не выявляет бага.
Более сложный план в SQL Server 2016+ вообще не использует агрегата ANY. Sort располагает строки в порядке, требуемом для операции нумерации строк. Оператор Segment устанавливает флаг в начале каждой новой группы. Sequence Project вычисляет номер строки. Наконец, оператор Filter проходит только те строки, которые имеют вычисленный номер строки равный единице.
Чтобы получить неверные результаты на этом наборе данных, нам потребуется использовать SQL Server 2014 или ранее, а агрегаты ANY должны быть реализованы в операторе Stream Aggregate или Eager Hash Aggregate (Flow Distinct Hash Match Aggregate не воспроизводит этот баг).
Одним способом заставить оптимизатор выбрать Stream Aggregate вместо Distinct Sort - это добавить кластеризованный индекс, обеспечивающий упорядочение по столбцу c1:
После этого изменения, план выполнения становится таким:

Агрегаты ANY видны в окне свойств при выборе оператора Stream Aggregate:

Вот результат запроса:
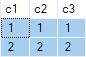
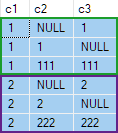
Это неверно. SQL Server вернул строки, которых не существует в источнике данных. Например, нет исходных строк с c2 = 1 и c3 = 1. Вот в качестве напоминания источник данных:
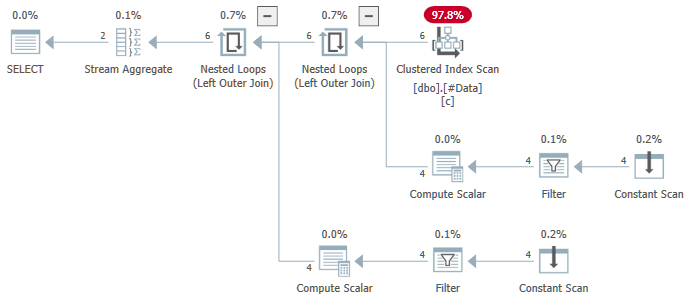
План выполнения ошибочно по отдельности вычисляет агрегаты ANY для столбцов c2 и с3, игнорируя null-значения. Каждый агрегат независимо возвращает первое не-NULL значение, которое встречает, что приводит к результату, когда значения для c2 и с3 берутся из разных строк источника. Это не то, что запрашивал исходный SQL-запрос.
Тот же неправильный результат можно воспроизвести с и без кластеризованного индекса, добавив хинт OPTION (HASH GROUP) для получения плана с Eager Hash Aggregate вместо Stream Aggregate.
Эта проблема имеет место только тогда, когда присутствует несколько агрегатов ANY, а агрегированные данные содержат NULL. Как отмечалось, проблема затрагивает только операторы Stream Aggregate и Eager Hash Aggregate; Distinct Sort и Flow Distinct не затрагиваются.
SQL Server 2016 и выше прикладывает усилия, чтобы избежать ввода множества агрегатов ANY для шаблона запроса с нумерацией и получения любой строки на группу, когда столбцы источника допускают NULL-значения. Когда это происходит, план выполнения будет содержать операторы Segment, Sequence Project и Filter вместо агрегата. Такая форма плана всегда безопасна, поскольку агрегаты ANY не используются вообще.
Оптимизатор SQL Server не совершенен в ситуации, когда столбец, изначально имеющий ограничение NOT NULL, все же может дать промежуточные значения NULL в процессе манипуляции данными.
Для демонстрации этого, начнем с таблицы, в которой все столбцы объявлены как NOT NULL:
Мы может сделать NULL из этого набора данных множеством способов, большинство из которых оптимизатор успешно обнаружит и, тем самым, избежит введения агрегатов ANY в процессе оптимизации.
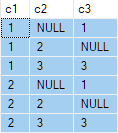
Один способ добавить NULL-значения, которые скроются от радаров, показан ниже:
Этот запрос производит следующий вывод:
Следующий шаг - использовать этот запрос в качестве источника данных для стандартного запроса "одна строка на группу":
На любой версии SQL Server получается следующий план:
Stream Aggregate содержит множество агрегатов ANY; получаем неверный результат. Ни одной из возвращаемых строк не содержится в источнике данных:
Единственный совершенно надежный обход до исправления бага - это избежать шаблона, в котором ROW_NUMBER имеет одни и те же столбцы, как в предложении ORDER BY, так и в предложении PARTITION BY.
Когда нам не важно, какая одна строка выбирается в каждой группе, неприятно, что все равно требуется предложение ORDER BY. Один способ обойти проблему - это использовать константу времени исполнения, подобную ORDER BY @@SPID в оконной функции.
Проблема с множеством агрегатов ANY на допускающем NULL входе не ограничивается шаблоном запроса с одной строкой на группу. Оптимизатор запросов может вводить внутренний агрегат ANY в разнообразных случаях. Одним из таких случаев является недетерминированное обновление.
Недетерминированное обновление имеет место, когда оператор не гарантирует, что каждая целевая строка будет обновляться максимум один раз. Другими словами, существует множество строк источника для хотя бы одной целевой строки. Документация явно предупреждает об этом:
Чтобы обработать недетерминированное обновление, оптимизатор группирует строки по ключу (индекса или RID) и применяет агрегаты ANY к остальным столбцам. Основная идея тут - выбрать одну строку для множества кандидатов, и использовать значения из этой строки для выполнения обновления. Имеются очевидные параллели с предыдущей проблемой ROW_NUMBER, поэтому не удивительно, что оказалось довольно просто продемонстрировать некорректное обновление.
В отличие от предыдущей проблемы, SQL Server теперь не предпринимает специальных шагов, чтобы избежать множества агрегатов ANY на допускающих NULL столбцах при выполнении недерминированного обновления. Поэтому следующее относится ко всем версиям, включая SQL Server 2019 CTP 3.0.
Логически это обновление должно всегда вызывать ошибку: Целевая таблица не допускает NULL ни в каком столбце. Какая бы совпадающая строка ни была выбрана из исходной таблицы, должна иметь место попытка обновить столбец c2 или c3 в NULL.
К сожалению, обновление проходит успешно, и конечное состояние целевой таблицы не согласуется с предоставленными данными:

Я написал отчет о баге. Решение состоит в том, чтобы избежать написания недетерминированных операторов UPDATE, поэтому агрегаты ANY не нужны для разрешения неоднозначности.
Как говорилось выше, SQL Server может производить агрегаты ANY в большем числе случаев, чем два представленных здесь примера. Если получается, что агрегируемые столбцы содержат NULL, имеется потенциальная возможность получения неверных результатов.
1. Запросы, выводящие одну строку на группу
Это должно быть одним из наиболее общих требований к ежедневным запросам при очень хорошо известном решении. Вы, вероятно, пишете такого типа запросы каждый день, автоматически следуя шаблону, не задумываясь об этом.
Идея состоит в нумерации входного набора строк с помощью оконной функции ROW_NUMBER, разбитого по столбцу или столбцам группировки. Это заворачивается в общее табличное выражение или производную таблицу и отфильтровывается по условию равенства единице вычисляемого столбца с номером строки. Поскольку ROW_NUMBER стартует с единицы для каждой группы, это дает нам одну требуемую строку на группу.
С этим общим шаблоном нет проблем. Тип запроса с одной строкой на группу, который связан с проблемой агрегата ANY, имеет место, когда мы не заботимся о том, какая конкретная строка выбирается для каждой группы.
В этом случае неясно, какой столбец следует использовать в обязательном предложении ORDER BY оконной функции ROW_NUMBER. В конце концов, нас совершенно не заботит, какая строка выбирается. Обычным приемом является еще раз использовать столбцы, указанные в PARTITION BY, в предложении ORDER BY. Здесь и может возникнуть проблема.
Пример
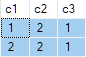
Давайте рассмотрим пример, использующий игрушечный набор данных:
CREATE TABLE #Data
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL
);
INSERT #Data
(c1, c2, c3)
VALUES
-- Группа 1
(1, NULL, 1),
(1, 1, NULL),
(1, 111, 111),
-- Группа 2
(2, NULL, 2),
(2, 2, NULL),
(2, 222, 222);Требуется вернуть одну любую полную строку данных из каждой группы, членство в которой определяется значением в столбце c1.
Следуя шаблону ROW_NUMBER, мы можем написать подобный следующему запрос (обратите внимание на то, что предложение ORDER BY соответствует предложению PARTITION BY):
WITH
Numbered AS
(
SELECT
D.*,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM #Data AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1;Как показано, этот запрос выполняется успешно, давая корректные результаты. Эти результаты технически недетерминированы, поскольку SQL Server может на самом деле вернуть любую из строк в каждой группе. Тем не менее, если вы сами выполните этот запрос, то вполне вероятно увидите те же результаты, что и я:
План выполнения зависит от используемой версии SQL Server и не зависит от уровня совместимости базы данных.
На SQL Server 2014 и более ранних версиях план имеет вид:
Для SQL Server 2016 и более поздних версий вы можете увидеть:
Оба плана безопасны, но по разным причинам. План с Distinct Sort содержит агрегат ANY, но реализация оператора Distinct Sort не выявляет бага.
Более сложный план в SQL Server 2016+ вообще не использует агрегата ANY. Sort располагает строки в порядке, требуемом для операции нумерации строк. Оператор Segment устанавливает флаг в начале каждой новой группы. Sequence Project вычисляет номер строки. Наконец, оператор Filter проходит только те строки, которые имеют вычисленный номер строки равный единице.
Баг
Чтобы получить неверные результаты на этом наборе данных, нам потребуется использовать SQL Server 2014 или ранее, а агрегаты ANY должны быть реализованы в операторе Stream Aggregate или Eager Hash Aggregate (Flow Distinct Hash Match Aggregate не воспроизводит этот баг).
Одним способом заставить оптимизатор выбрать Stream Aggregate вместо Distinct Sort - это добавить кластеризованный индекс, обеспечивающий упорядочение по столбцу c1:
CREATE CLUSTERED INDEX c ON #Data (c1);После этого изменения, план выполнения становится таким:
Агрегаты ANY видны в окне свойств при выборе оператора Stream Aggregate:
Вот результат запроса:
Это неверно. SQL Server вернул строки, которых не существует в источнике данных. Например, нет исходных строк с c2 = 1 и c3 = 1. Вот в качестве напоминания источник данных:
План выполнения ошибочно по отдельности вычисляет агрегаты ANY для столбцов c2 и с3, игнорируя null-значения. Каждый агрегат независимо возвращает первое не-NULL значение, которое встречает, что приводит к результату, когда значения для c2 и с3 берутся из разных строк источника. Это не то, что запрашивал исходный SQL-запрос.
Тот же неправильный результат можно воспроизвести с и без кластеризованного индекса, добавив хинт OPTION (HASH GROUP) для получения плана с Eager Hash Aggregate вместо Stream Aggregate.
Условия
Эта проблема имеет место только тогда, когда присутствует несколько агрегатов ANY, а агрегированные данные содержат NULL. Как отмечалось, проблема затрагивает только операторы Stream Aggregate и Eager Hash Aggregate; Distinct Sort и Flow Distinct не затрагиваются.
SQL Server 2016 и выше прикладывает усилия, чтобы избежать ввода множества агрегатов ANY для шаблона запроса с нумерацией и получения любой строки на группу, когда столбцы источника допускают NULL-значения. Когда это происходит, план выполнения будет содержать операторы Segment, Sequence Project и Filter вместо агрегата. Такая форма плана всегда безопасна, поскольку агрегаты ANY не используются вообще.
Воспроизведение бага в SQL Server 2016+
Оптимизатор SQL Server не совершенен в ситуации, когда столбец, изначально имеющий ограничение NOT NULL, все же может дать промежуточные значения NULL в процессе манипуляции данными.
Для демонстрации этого, начнем с таблицы, в которой все столбцы объявлены как NOT NULL:
IF OBJECT_ID(N'tempdb..#Data', N'U') IS NOT NULL
BEGIN
DROP TABLE #Data;
END;
CREATE TABLE #Data
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL
);
CREATE CLUSTERED INDEX c ON #Data (c1);
INSERT #Data
(c1, c2, c3)
VALUES
-- Группа 1
(1, 1, 1),
(1, 2, 2),
(1, 3, 3),
-- Группа 2
(2, 1, 1),
(2, 2, 2),
(2, 3, 3);Мы может сделать NULL из этого набора данных множеством способов, большинство из которых оптимизатор успешно обнаружит и, тем самым, избежит введения агрегатов ANY в процессе оптимизации.
Один способ добавить NULL-значения, которые скроются от радаров, показан ниже:
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2;Этот запрос производит следующий вывод:
Следующий шаг - использовать этот запрос в качестве источника данных для стандартного запроса "одна строка на группу":
WITH
SneakyNulls AS
(
-- Вводим nullы, которые не может увидеть оптимизатор
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2
),
Numbered AS
(
SELECT
D.c1,
D.c2,
D.c3,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM SneakyNulls AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1;На любой версии SQL Server получается следующий план:
Stream Aggregate содержит множество агрегатов ANY; получаем неверный результат. Ни одной из возвращаемых строк не содержится в источнике данных:
Обход
Единственный совершенно надежный обход до исправления бага - это избежать шаблона, в котором ROW_NUMBER имеет одни и те же столбцы, как в предложении ORDER BY, так и в предложении PARTITION BY.
Когда нам не важно, какая одна строка выбирается в каждой группе, неприятно, что все равно требуется предложение ORDER BY. Один способ обойти проблему - это использовать константу времени исполнения, подобную ORDER BY @@SPID в оконной функции.
2. Недетерминированное обновление
Проблема с множеством агрегатов ANY на допускающем NULL входе не ограничивается шаблоном запроса с одной строкой на группу. Оптимизатор запросов может вводить внутренний агрегат ANY в разнообразных случаях. Одним из таких случаев является недетерминированное обновление.
Недетерминированное обновление имеет место, когда оператор не гарантирует, что каждая целевая строка будет обновляться максимум один раз. Другими словами, существует множество строк источника для хотя бы одной целевой строки. Документация явно предупреждает об этом:
Будьте осторожны при указании критериев для операции обновления в предложении FROM.
Результаты оператора UPDATE не определены, если оператор включает предложение FROM, которое не специфицировано таким образом, чтобы для каждого обновляемого вхождения столбца было доступно только одно значение, то есть, если оператор UPDATE не является детерминированным.
Чтобы обработать недетерминированное обновление, оптимизатор группирует строки по ключу (индекса или RID) и применяет агрегаты ANY к остальным столбцам. Основная идея тут - выбрать одну строку для множества кандидатов, и использовать значения из этой строки для выполнения обновления. Имеются очевидные параллели с предыдущей проблемой ROW_NUMBER, поэтому не удивительно, что оказалось довольно просто продемонстрировать некорректное обновление.
В отличие от предыдущей проблемы, SQL Server теперь не предпринимает специальных шагов, чтобы избежать множества агрегатов ANY на допускающих NULL столбцах при выполнении недерминированного обновления. Поэтому следующее относится ко всем версиям, включая SQL Server 2019 CTP 3.0.
Пример
DECLARE @Target table
(
c1 integer PRIMARY KEY,
c2 integer NOT NULL,
c3 integer NOT NULL
);
DECLARE @Source table
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL,
INDEX c CLUSTERED (c1)
);
INSERT @Target
(c1, c2, c3)
VALUES
(1, 0, 0);
INSERT @Source
(c1, c2, c3)
VALUES
(1, 2, NULL),
(1, NULL, 3);
UPDATE T
SET T.c2 = S.c2,
T.c3 = S.c3
FROM @Target AS T
JOIN @Source AS S
ON S.c1 = T.c1;
SELECT * FROM @Target AS T;Логически это обновление должно всегда вызывать ошибку: Целевая таблица не допускает NULL ни в каком столбце. Какая бы совпадающая строка ни была выбрана из исходной таблицы, должна иметь место попытка обновить столбец c2 или c3 в NULL.
К сожалению, обновление проходит успешно, и конечное состояние целевой таблицы не согласуется с предоставленными данными:
Я написал отчет о баге. Решение состоит в том, чтобы избежать написания недетерминированных операторов UPDATE, поэтому агрегаты ANY не нужны для разрешения неоднозначности.
Как говорилось выше, SQL Server может производить агрегаты ANY в большем числе случаев, чем два представленных здесь примера. Если получается, что агрегируемые столбцы содержат NULL, имеется потенциальная возможность получения неверных результатов.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой