
Недокументированные планы запросов: агрегат ANY
Пересказ статьи Paul White. Undocumented Query Plans: The ANY Aggregate
Как обычно, начнем с тестовой таблицы:
CREATE TABLE #Example
(
pk numeric IDENTITY PRIMARY KEY NONCLUSTERED,
col1 sql_variant NULL,
col2 sql_variant NULL,
thing sql_variant NOT NULL,
);
Пример данных:
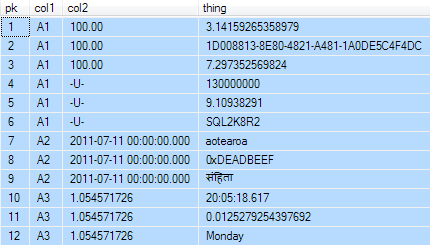
И индекс, который вскоре будет использован:
Весь скрипт, создающий таблицу с данными, находится в конце статьи. В таблице и данных нет ничего необычного (за исключением того, что я хотел немного позабавиться со значениями и типами данных).
Требуется вернуть уникальные комбинации col1 и col2, плюс любое значение любое значение из третьего столбца (не важно какое) из группы одинаковых col1, col2.
Один из возможных результирующих наборов показан ниже:
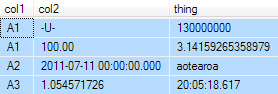
Существует много способов написать на SQL запрос, который бы выполнил это. Действительно существует удивительное число альтернатив, и я могу вернуться к ним в дальнейшем.
Пока давайте посмотрим на одно естественное решение:
План выполнения имеет вид:

Здесь все абсолютно правильно, как с запросом, так и с планом выполнения. Запрос краткий, возвращает правильный результат и выполняется быстро.
Тогда почему я говорю о нем? Дело в агрегатной функции. Меня беспокоит то, что я должен использовать здесь MAX (или MIN), в то время, когда я на самом деле хочу написать что-то подобное:
Жаль, что это неправильный синтаксис; в T-SQL нет агрегатной функции ANY. Однако только потому, что мы не можем использовать агрегат ANY, не означает, что процессор запросов SQL Server не может это сделать...
Вот альтернативный ход мыслей по поводу запроса, который мы хотим написать: Если сделать разбиение входного набора по столбцам группировки и пронумеровать (произвольным образом) строки в каждом разбиении, то мы могли бы просто взять строку с номером #1 в каждом разбиении.
На языке T-SQL мы можем использовать оконную функцию ROW_NUMBER, чтобы это реализовать:
Если вы знакомы с планами выполнения, то можете ожидать, что этот запрос произведет план, который выглядит примерно так:

В вышеприведенном воображаемом плане:
На самом деле мы вообще не получаем ничего подобного, вместо этого мы имеем:
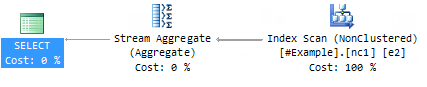
Это тот же план, который был получен для запроса с агрегатом MAX!
Ну, фактически это не совсем то же самое. Если вы кликните на Stream Aggregate и посмотрите его свойства, вы увидите, что он не выполняет агрегата MAX.
Вот значения, определенные агрегатом в новом запросе:
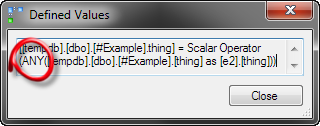
Для сравнения значения, определяемые запросом с MAX:
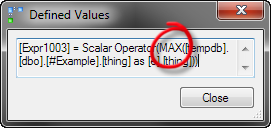
Наш запрос в новом виде использует агрегат ANY!
SQL Server заметил, что реально нам вообще не нужен номер строки. Мы просто выразили пожелание получить одну строку на группу и нам все равно, какая это будет строка.
Правило упрощения, используемое для выполнения этого, называется SelSeqPrjToAnyAgg. Как предполагает имя, оно согласуется с выделением (Filter) и Sequence Project (в частности, с тем, которое использует ROW_NUMBER) и заменяет его на агрегат ANY.
Это - правило упрощения, поэтому оно выполняется до полной оптимизации на основе стоимости, делая это преобразование доступным даже в тривиальных планах.
Эта конкретная оптимизация соответствует только очень специфичным видам плана, поэтому тут следует быть осторожным:
Указание константы в предложении ORDER BY оконной функции (для сообщения, что вы не заботитесь о сортировке) не работает:
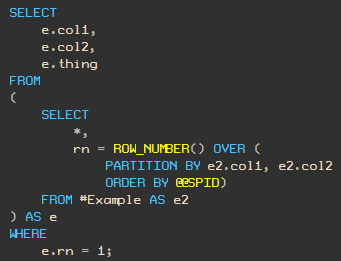
Этот запрос (и другие подобные ему, которые используют (ORDER BY ... (SELECT 0), NULL, Или NEWID() и т.д.) не соответствуют правилу, приводя к плану с Segment, Sequence Project и Filter. (Если вы используете SELECT <константа>, то увидите в плане дополнительно Compute Scalar):

Если вы хотите получить преимущество от переписывания на агрегат ANY, то должны точно удовлетворять описанным условиям.
Давайте удалим созданный ранее индекс:
Теперь, если мы выполним соответствующий правилам запрос в форме ROW_NUMBER, то получим другой план:
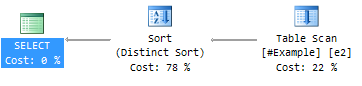
Как упоминалось в моей предыдущей статье Row Goals and Grouping, Sort с последующим Stream Aggregate может трансформироваться в Sort, выполняемой в режиме Distinct Sort.
Stream Aggregate (со своим агрегатом ANY) относится к Sort, и в этом процессе агрегирование ANY теряется для нас.
Логически он все еще там, но не отображается в плане запроса, даже в виде XML:
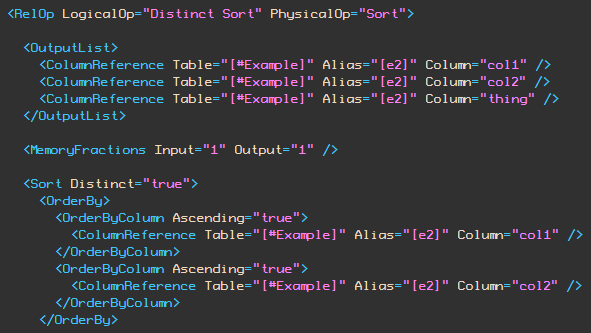
Оператор Sort производит три необходимых столбца (col1, col2 и thing) и выполняет Distinct, упорядоченный по col1 и col2, но не имеет больше явной ссылки на агрегат ANY, производимым на столбце thing.
Чтобы он снова появился, нам необходимо временно запретить правило оптимизатора, ответственное за трансформацию в Distinct Sort:
Теперь мы видим план с отдельными операторами Sort и Stream Aggregate, содержащем агрегат ANY:

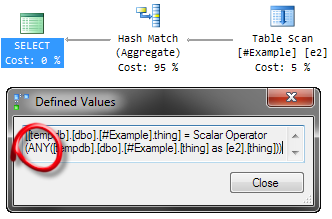
Последнее, что я хочу показать, - это агрегат ANY, работающий в Hash Match Aggregate.
Если мы воспользуемся хинтом запроса OPTION (HASH GROUP), то получим такой план:
Обещанный скрипт:
И индекс, который вскоре будет использован:
CREATE INDEX nc1
ON #Example
(col1, col2, thing);Весь скрипт, создающий таблицу с данными, находится в конце статьи. В таблице и данных нет ничего необычного (за исключением того, что я хотел немного позабавиться со значениями и типами данных).
Задача
Требуется вернуть уникальные комбинации col1 и col2, плюс любое значение любое значение из третьего столбца (не важно какое) из группы одинаковых col1, col2.
Один из возможных результирующих наборов показан ниже:
Существует много способов написать на SQL запрос, который бы выполнил это. Действительно существует удивительное число альтернатив, и я могу вернуться к ним в дальнейшем.
Использование агрегатной функции MAX
Пока давайте посмотрим на одно естественное решение:
SELECT
e.col1,
e.col2,
MAX(e.thing)
FROM #Example AS e
GROUP BY
e.col1,
e.col2;План выполнения имеет вид:
Здесь все абсолютно правильно, как с запросом, так и с планом выполнения. Запрос краткий, возвращает правильный результат и выполняется быстро.
Тогда почему я говорю о нем? Дело в агрегатной функции. Меня беспокоит то, что я должен использовать здесь MAX (или MIN), в то время, когда я на самом деле хочу написать что-то подобное:
SELECT
e.col1,
e.col2,
ANY (e.thing)
FROM #Example AS e
GROUP BY
e.col1,
e.col2;Агрегат ANY
Жаль, что это неправильный синтаксис; в T-SQL нет агрегатной функции ANY. Однако только потому, что мы не можем использовать агрегат ANY, не означает, что процессор запросов SQL Server не может это сделать...
Вот альтернативный ход мыслей по поводу запроса, который мы хотим написать: Если сделать разбиение входного набора по столбцам группировки и пронумеровать (произвольным образом) строки в каждом разбиении, то мы могли бы просто взять строку с номером #1 в каждом разбиении.
На языке T-SQL мы можем использовать оконную функцию ROW_NUMBER, чтобы это реализовать:
SELECT
e.col1,
e.col2,
e.thing
FROM
(
SELECT
*,
rn = ROW_NUMBER() OVER (
PARTITION BY e2.col1, e2.col2
ORDER BY e2.col1, e2.col2)
FROM #Example AS e2
) AS e
WHERE
e.rn = 1;Если вы знакомы с планами выполнения, то можете ожидать, что этот запрос произведет план, который выглядит примерно так:
В вышеприведенном воображаемом плане:
- Index Scan производит строки, упорядоченные по col1 и col2
- Segment определяет начало каждой новой группы и устанавливает флаг в потоке
- Sequence Project использует этот флаг для рестарта нумерации строк для каждой группы
- Filter ограничивает вывод только строками, для которых номер равен 1
На самом деле мы вообще не получаем ничего подобного, вместо этого мы имеем:
Это тот же план, который был получен для запроса с агрегатом MAX!
Ну, фактически это не совсем то же самое. Если вы кликните на Stream Aggregate и посмотрите его свойства, вы увидите, что он не выполняет агрегата MAX.
Вот значения, определенные агрегатом в новом запросе:
Для сравнения значения, определяемые запросом с MAX:
Наш запрос в новом виде использует агрегат ANY!
Что за волшебство?
SQL Server заметил, что реально нам вообще не нужен номер строки. Мы просто выразили пожелание получить одну строку на группу и нам все равно, какая это будет строка.
Правило упрощения, используемое для выполнения этого, называется SelSeqPrjToAnyAgg. Как предполагает имя, оно согласуется с выделением (Filter) и Sequence Project (в частности, с тем, которое использует ROW_NUMBER) и заменяет его на агрегат ANY.
Это - правило упрощения, поэтому оно выполняется до полной оптимизации на основе стоимости, делая это преобразование доступным даже в тривиальных планах.
Эта конкретная оптимизация соответствует только очень специфичным видам плана, поэтому тут следует быть осторожным:
- Filter должен ограничить выражение, произведенное Sequence Project единицей. В нашем запросе это соответствует выражению
WHERE rn = 1. - Выражение, добавляемое Sequence Project не должно формировать часть результата запроса.
- Вы должны разбивать (PARTITION BY) и сортировать (ORDER BY) по столбцам группировки (хотя порядок не имеет значения).
- Столбцы, по которым не выполняется группировка, должны иметь ограничение NOT NULL.
Указание константы в предложении ORDER BY оконной функции (для сообщения, что вы не заботитесь о сортировке) не работает:
Этот запрос (и другие подобные ему, которые используют (ORDER BY ... (SELECT 0), NULL, Или NEWID() и т.д.) не соответствуют правилу, приводя к плану с Segment, Sequence Project и Filter. (Если вы используете SELECT <константа>, то увидите в плане дополнительно Compute Scalar):
Если вы хотите получить преимущество от переписывания на агрегат ANY, то должны точно удовлетворять описанным условиям.
Невидимый ANY
Давайте удалим созданный ранее индекс:
DROP INDEX nc1 ON #Example;Теперь, если мы выполним соответствующий правилам запрос в форме ROW_NUMBER, то получим другой план:
Как упоминалось в моей предыдущей статье Row Goals and Grouping, Sort с последующим Stream Aggregate может трансформироваться в Sort, выполняемой в режиме Distinct Sort.
Stream Aggregate (со своим агрегатом ANY) относится к Sort, и в этом процессе агрегирование ANY теряется для нас.
Логически он все еще там, но не отображается в плане запроса, даже в виде XML:
Оператор Sort производит три необходимых столбца (col1, col2 и thing) и выполняет Distinct, упорядоченный по col1 и col2, но не имеет больше явной ссылки на агрегат ANY, производимым на столбце thing.
Чтобы он снова появился, нам необходимо временно запретить правило оптимизатора, ответственное за трансформацию в Distinct Sort:
Теперь мы видим план с отдельными операторами Sort и Stream Aggregate, содержащем агрегат ANY:
Хеш агрегат ANY
Последнее, что я хочу показать, - это агрегат ANY, работающий в Hash Match Aggregate.
Если мы воспользуемся хинтом запроса OPTION (HASH GROUP), то получим такой план:
Обещанный скрипт:
USE Sandpit;
DBCC FREEPROCCACHE;
IF OBJECT_ID(N'tempdb.bdpmet.#Example', N'U') IS NOT NULL
BEGIN
DROP TABLE tempdb.penguin.#Example;
END;
GO
CREATE TABLE #Example
(
pk numeric IDENTITY PRIMARY KEY NONCLUSTERED,
col1 sql_variant NULL,
col2 sql_variant NULL,
thing sql_variant NOT NULL,
);
GO
INSERT #Example
(col1, col2, thing)
VALUES
('A1', CONVERT(sql_variant, $100), CONVERT(sql_variant, PI())),
('A1', $100, {guid '1D008813-8E80-4821-A481-1A0DE5C4F4DC'}),
('A1', $100, 7.297352569824),
('A1', N'-U-', 1.3E8),
('A1', N'-U-', 9.10938291),
('A1', N'-U-', @@SERVICENAME),
('A2', {d '2011-07-11'}, 'aotearoa'),
('A2', {d '2011-07-11'}, 0xDEADBEEF),
('A2', {d '2011-07-11'}, N'संहिता'),
('A3', 1.054571726, {fn CURRENT_TIME}),
('A3', 1.054571726, RADIANS(RAND())),
('A3', 1.054571726, {fn DAYNAME (0)});
GO
CREATE INDEX nc1
ON #Example
(col1, col2, thing);
GO
-- A natural query:
SELECT
e.col1,
e.col2,
MAX(e.thing)
FROM #Example AS e
GROUP BY
e.col1,
e.col2;
GO
-- Would prefer:
SELECT
e.col1,
e.col2,
ANY (e.thing)
FROM #Example AS e
GROUP BY
e.col1,
e.col2;
GO
-- Transformed to use ANY
SELECT
e.col1,
e.col2,
e.thing
FROM
(
SELECT
*,
rn = ROW_NUMBER() OVER (
PARTITION BY e2.col1, e2.col2
ORDER BY e2.col1, e2.col2)
FROM #Example AS e2
) AS e
WHERE
e.rn = 1;
GO
-- Нет соответствия, нет агрегата ANY
SELECT
e.col1,
e.col2,
e.thing
FROM
(
SELECT
*,
rn = ROW_NUMBER() OVER (
PARTITION BY e2.col1, e2.col2
ORDER BY (SELECT 0))
FROM #Example AS e2
) AS e
WHERE
e.rn = 1;
GO
-- Нет соответствия -мы используем столбец rn
SELECT
e.col1,
e.col2,
e.thing,
e.rn
FROM
(
SELECT
*,
rn = ROW_NUMBER() OVER (
PARTITION BY e2.col1, e2.col2
ORDER BY e2.col1, e2.col2)
FROM #Example AS e2
) AS e
WHERE
e.rn = 1;
GO
DROP INDEX nc1 ON #Example;
GO
-- Distinct Sort с невидимым ANY
SELECT
e.col1,
e.col2,
e.thing
FROM
(
SELECT
*,
rn = ROW_NUMBER() OVER (
PARTITION BY e2.col1, e2.col2
ORDER BY e2.col1, e2.col2)
FROM #Example AS e2
) AS e
WHERE
e.rn = 1;
GO
-- Отключить правило
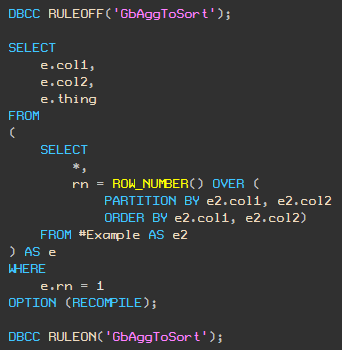
DBCC RULEOFF('GbAggToSort');
-- Тот же запрос, перекомпиляция для повторной оптимизации
SELECT
e.col1,
e.col2,
e.thing
FROM
(
SELECT
*,
rn = ROW_NUMBER() OVER (
PARTITION BY e2.col1, e2.col2
ORDER BY e2.col1, e2.col2)
FROM #Example AS e2
) AS e
WHERE
e.rn = 1
OPTION (RECOMPILE);
-- Снова включаем правило (*** ВАЖНО! ***)
DBCC RULEON('GbAggToSort');
GO
-- агрегат ANY с Hash Match
SELECT
e.col1,
e.col2,
e.thing
FROM
(
SELECT
*,
rn = ROW_NUMBER() OVER (
PARTITION BY e2.col1, e2.col2
ORDER BY e2.col1, e2.col2)
FROM #Example AS e2
) AS e
WHERE
e.rn = 1
OPTION (HASH GROUP);
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой