
Как сделать запросы SELECT COUNT(*) очень быстрыми
Пересказ статьи Brent Ozar. How to Make SELECT COUNT(*) Queries Crazy Fast
Когда вы выполняете SELECT COUNT(*), скорость результатов во многом зависит от структуры и настроек базы данных. Давайте проведем исследование на таблице Votes в базе данных Stack Overflow - 300-гигабайтной версии 2018-06, в которой таблица Votes содержит 150784380 строк и занимает пространство около 5,3Гб.
Я собираюсь проводить 3 измерения для каждого метода:
Не зацикливайтесь на небольших различиях в операциях - я пишу этот пост, чтобы показать вам различия в общих чертах и то, как работает моя мысль при сравнении различных операций. В вашем окружении при различиях в железе, версии системы и т.д. вы можете получить другие результаты, и это хорошо. Существуют также другие измерения этих методов, в зависимости от ваших собственных требований к производительности: выделение памяти, способность выполняться без блокировок и даже точность результатов при конкурентных запросах. В целях наших тестов, я не буду говорить об уровнях изоляции или блокировках.
Я выполняю эти тесты на SQL Server 2019 (15.0.2070.41) на 8-ядерной виртуальной машине с 64Гб RAM.
Таблица Votes имеет размер всего около 5,3Гб, поэтому я могу всю её поместить в кэш на моем SQL Server. Даже после первого выполнения запроса и кэширования данных в RAM, это все равно не быстро:
В SQL Server 2019 появились операции пакетного режима на построчных индексах, изначально доступные только на поколоночных индексах. Выгода здесь довольно велика, хотя мы все еще имеем дело только с построчным индексом:
Резкое сокращение времени процессора обусловлено пакетным режимом. Это не очевидно в плане выполнения пока вы не наведете мышку на отдельные операторы:
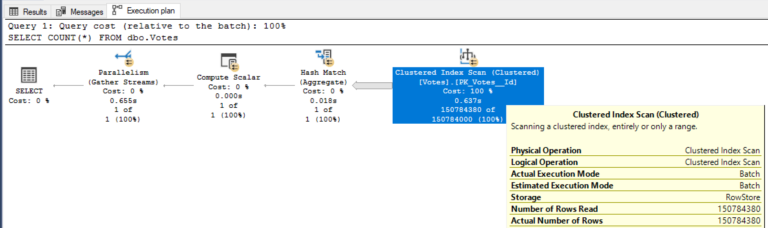
Пакетный режим отлично подходит к множеству запросов, создающих отчеты, агрегируя большие объемы данных.
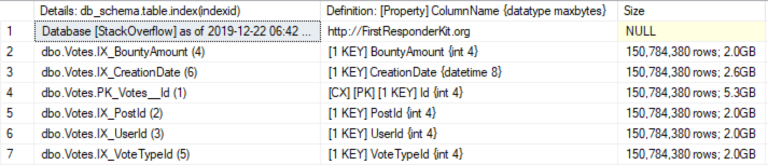
Я собираюсь создать индекс на каждом из 5 столбцов таблицы dbo.Votes, а затем сравнить их размеры при помощи sp_BlitzIndex:
Проверьте число строк в каждом индексе сравнительно с его размером. Когда SQL Server необходимо подсчитать число строк в таблице, он достаточно умен, чтобы посмотреть на то, какой из объектов является наименьшим, а затем использовать его для подсчета. Индексы могут иметь различные размеры в зависимости от типов данных индексируемого содержимого, размера содержимого каждой строки, числа NULL-значений и т.п.
Я вернусь к уровню совместимости 2017 (убирая операции пакетного режима), после чего выполню подсчет:
SQL Server останавливает выбор на индексе BountyAmount, одном из меньших 2Гб:
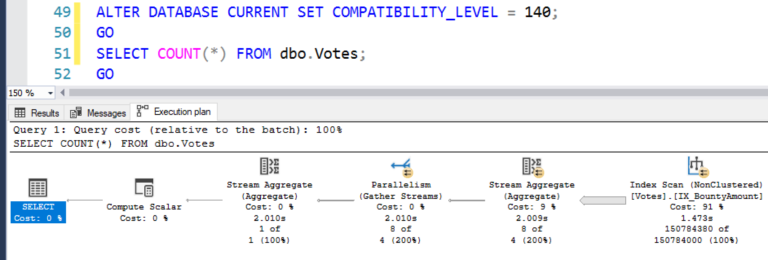
Мы экономим на чтении меньшего числа страниц, но по-прежнему читаем то же самое число строк - 150М, поэтому время процессора и продолжительность фактически не меняется:
Если вы хотите понизить время процессора и продолжительность, вам действительно потребуется другой подход к подсчету - и тут поможет операция пакетного режима.
Итак, давайте теперь испытаем операцию пакетного режима с имеющимися индексами:
Тут все еще используется индекс BountyAmount и производится то же число чтений, что и в варианте №3, но мы получаем меньшее время процессора и продолжительность шага №2:
Пока это победитель. Но вспомним, что пакетный режим изначально был реализован в связи с поколоночными индексами, которые являются отличными инструментами для запросов генерации отчетов….
Я намеренно работаю здесь в режиме совместимости 2017, чтобы выяснить, где зарыта собака:
План выполнения содержит оператор сканирования нашего нового поколоночного индекса, и все операторы в плане относятся к пакетному режиму:
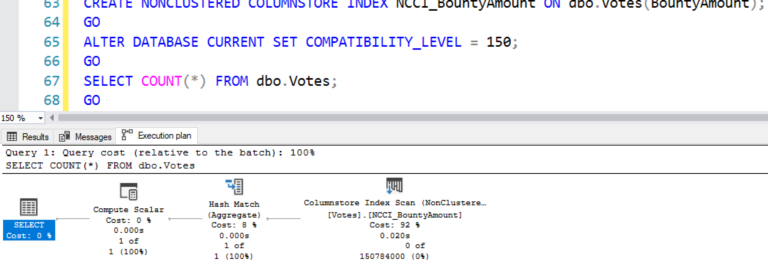 Тут я должен поменять единицы измерения:
Тут я должен поменять единицы измерения:
Перспективы: Я знаю некоторых разработчиков, кто пытается использовать системные таблицы для быстрого подсчета числа строк, но даже они не могут достичь таких результатов по скорости.
В убывающем порядке предпочтения и скорости, сначала лучшие результаты:
- Как много страниц он читает (с установкой SET STATISTICS IO ON).
- Как много времени процессора он использует (с установкой SET STATISTICS TIME ON).
- Как быстро выполняется.
Не зацикливайтесь на небольших различиях в операциях - я пишу этот пост, чтобы показать вам различия в общих чертах и то, как работает моя мысль при сравнении различных операций. В вашем окружении при различиях в железе, версии системы и т.д. вы можете получить другие результаты, и это хорошо. Существуют также другие измерения этих методов, в зависимости от ваших собственных требований к производительности: выделение памяти, способность выполняться без блокировок и даже точность результатов при конкурентных запросах. В целях наших тестов, я не буду говорить об уровнях изоляции или блокировках.
Я выполняю эти тесты на SQL Server 2019 (15.0.2070.41) на 8-ядерной виртуальной машине с 64Гб RAM.
1: Обычный COUNT (*) только с кластеризованным индексом построчного хранения и уровнем совместимости 2017 и ранее
ALTER DATABASE CURRENT SET COMPATIBILITY_LEVEL = 140;
GO
SELECT COUNT(*) FROM dbo.Votes;
GO
Таблица Votes имеет размер всего около 5,3Гб, поэтому я могу всю её поместить в кэш на моем SQL Server. Даже после первого выполнения запроса и кэширования данных в RAM, это все равно не быстро:
- Чтение страниц: 694389
- CPU: 14,5 секунд времени процессора
- Продолжительность: 2 секунды
2: Уровень совместимости 2019 (пакетный режим на построчных индексах)
ALTER DATABASE CURRENT SET COMPATIBILITY_LEVEL = 150;
GO
SELECT COUNT(*) FROM dbo.Votes;
GO
В SQL Server 2019 появились операции пакетного режима на построчных индексах, изначально доступные только на поколоночных индексах. Выгода здесь довольно велика, хотя мы все еще имеем дело только с построчным индексом:
- Чтение страниц: 694379
- CPU: 5,2 секунд времени процессора
- Продолжительность: 0,7 секунды
Резкое сокращение времени процессора обусловлено пакетным режимом. Это не очевидно в плане выполнения пока вы не наведете мышку на отдельные операторы:
Пакетный режим отлично подходит к множеству запросов, создающих отчеты, агрегируя большие объемы данных.
3: Добавление некластеризованных построчных индексов, но при использовании режима 2017 и ранее
Я собираюсь создать индекс на каждом из 5 столбцов таблицы dbo.Votes, а затем сравнить их размеры при помощи sp_BlitzIndex:
CREATE INDEX IX_PostId ON dbo.Votes(PostId);
GO
CREATE INDEX IX_UserId ON dbo.Votes(UserId);
GO
CREATE INDEX IX_BountyAmount ON dbo.Votes(BountyAmount);
GO
CREATE INDEX IX_VoteTypeId ON dbo.Votes(VoteTypeId);
GO
CREATE INDEX IX_CreationDate ON dbo.Votes(CreationDate);
GO
/ Каковы размеры каждого индекса?
Выключите фактические планы для выполнения этого: /
sp_BlitzIndex @TableName = 'Votes';
GO
Проверьте число строк в каждом индексе сравнительно с его размером. Когда SQL Server необходимо подсчитать число строк в таблице, он достаточно умен, чтобы посмотреть на то, какой из объектов является наименьшим, а затем использовать его для подсчета. Индексы могут иметь различные размеры в зависимости от типов данных индексируемого содержимого, размера содержимого каждой строки, числа NULL-значений и т.п.
Я вернусь к уровню совместимости 2017 (убирая операции пакетного режима), после чего выполню подсчет:
ALTER DATABASE CURRENT SET COMPATIBILITY_LEVEL = 140;
GO
SELECT COUNT(*) FROM dbo.Votes;
GO
SQL Server останавливает выбор на индексе BountyAmount, одном из меньших 2Гб:
Мы экономим на чтении меньшего числа страниц, но по-прежнему читаем то же самое число строк - 150М, поэтому время процессора и продолжительность фактически не меняется:
- Чтение страниц: 263322
- CPU: 14,8 секунд времени процессора
- Продолжительность: 2 секунды
Если вы хотите понизить время процессора и продолжительность, вам действительно потребуется другой подход к подсчету - и тут поможет операция пакетного режима.
4: Пакетный режим 2019 с некластеризованными построчными индексами
Итак, давайте теперь испытаем операцию пакетного режима с имеющимися индексами:
ALTER DATABASE CURRENT SET COMPATIBILITY_LEVEL = 150;
GO
SELECT COUNT(*) FROM dbo.Votes;
GO
Тут все еще используется индекс BountyAmount и производится то же число чтений, что и в варианте №3, но мы получаем меньшее время процессора и продолжительность шага №2:
- Чтение страниц: 694379
- CPU: 4,3 секунд времени процессора
- Продолжительность: 0,6 секунды
Пока это победитель. Но вспомним, что пакетный режим изначально был реализован в связи с поколоночными индексами, которые являются отличными инструментами для запросов генерации отчетов….
5: Некластеризованный поколоночный индекс с пакетным режимом
Я намеренно работаю здесь в режиме совместимости 2017, чтобы выяснить, где зарыта собака:
CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_BountyAmount ON dbo.Votes(BountyAmount);
GO
ALTER DATABASE CURRENT SET COMPATIBILITY_LEVEL = 140;
GO
SELECT COUNT(*) FROM dbo.Votes;
GO
План выполнения содержит оператор сканирования нашего нового поколоночного индекса, и все операторы в плане относятся к пакетному режиму:
Тут я должен поменять единицы измерения:- Чтение страниц: 73922
- CPU: 15 миллисекунд
- Продолжительность: 21 миллисекунда
Перспективы: Я знаю некоторых разработчиков, кто пытается использовать системные таблицы для быстрого подсчета числа строк, но даже они не могут достичь таких результатов по скорости.
Вот что необходимо сделать, чтобы запросы SELECT COUNT(*) выполнялись быстро
В убывающем порядке предпочтения и скорости, сначала лучшие результаты:
- Иметь SQL server 2017 или новее, и построить поколоночный индекс на таблице.
- Иметь любую версию, которая поддерживает пакетный режим на поколоночных индексах, и построить поколоночный индекс на таблице - хотя ваш опыт будет сильно различаться в зависимости от типа вашего запроса. Чтобы познакомиться со спецификой, почитайте о поколоночных индексах, особенно те статьи Niko, где в заголовке упоминается слово "пакетный" (batch).
- Иметь SQL SERVER 2019 или новее, и установить уровень совместимости 150 (2019), даже с построчными индексами. Вы сможете по-прежнему значительно сократить использование процессора, благодаря пакетному режиму на построчном хранении. Это действительно легко сделать - вероятно, вам потребуются минимальные изменения вашего приложения и схемы базы данных - хотя у вас и не будет удивительно быстрых ответов в миллисекундах, которые может обеспечить поколоночный индекс.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой