
Как думать подобно SQL Server: повторяющиеся запуски запросов
Пересказ статьи Brent Ozar. How to Think Like the SQL Server Engine: Running a Query Repeatedly
Ранее в этой серии мы запускали запрос с ORDER BY, и обнаружили, что это интенсивно нагружает процессор, что утраивает стоимость запроса:
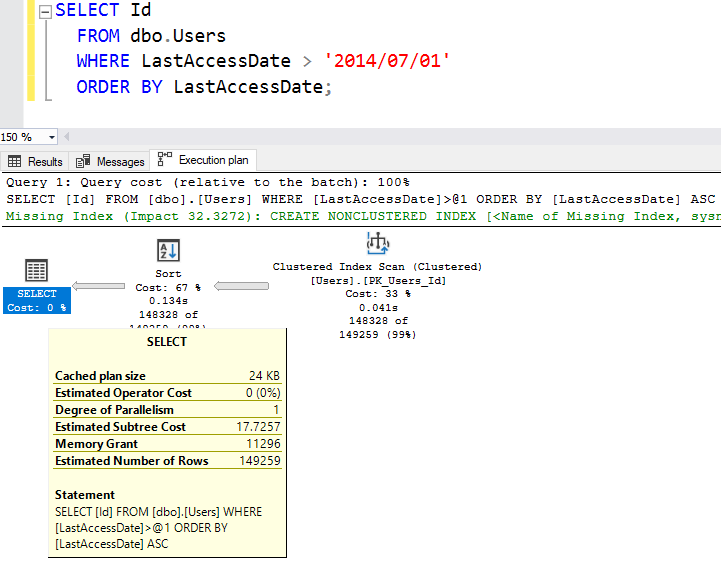
Теперь давайте запустим этот запрос многократно. В SSMS вы можете добавить число после GO, тогда SSMS выполнит ваш запрос указанное число раз. Я выполню его 50 раз:
SET STATISTICS IO, TIME ON;
GO
SELECT Id
FROM dbo.Users
WHERE LastAccessDate > '2014/07/01'
ORDER BY LastAccessDate;
GO 50В первой статье я объяснял инструкцию SET STATISTICS IO ON. Теперь я добавлю новую опцию: TIME. Это добавит больше сообщений, которые покажут, сколько времени процессора и всего потрачено на выполнение запроса:
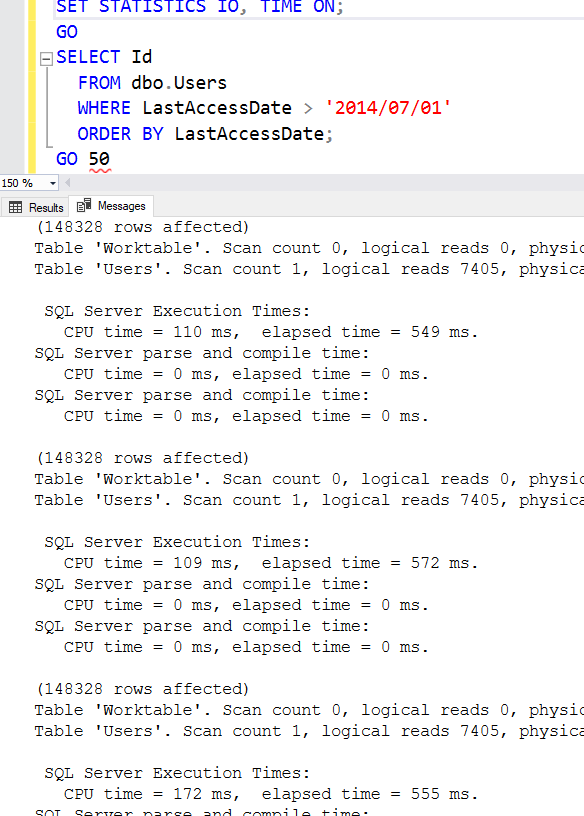
SQL Server выполняет запрос снова и снова, читая всякий раз 7405 страниц и выполняя сортировку.
Когда я был разработчиком, то у меня никогда не было проблем с получением данных с SQL Server. В конце концов, я бы просто запустил такой запрос раньше, верно? Данные в кэше, так? Конечно, SQL Server кэширует отсортированные данные, чтобы не пришлось повторять всю работу, особенно когда мои запросы выполняют множество соединений, группировку, фильтрацию и сортировку.
SQL Serwer кэширует страницы необработанных данных, а не результат запроса.
Не важно, что данные не изменились. Это не имеет значения, даже если вы единственный пользователь базы данных, и даже если база данных установлена в режим "только чтение".
SQL Server повторно выполняется запрос с нуля.
Аналогично, если 500 человек запускают в точности один и тот же запрос в одно и то же время, SQL Server не выполняет его один раз, распределяя результаты по всем сессиям. Каждый запрос получает свою собственную выделенную память и собственную долю работы процессора.
Это одна из тех областей, где Oracle побеждает. Иногда меня спрашивают о том, какая моя любимая СУБД; и я должен признаться, что если бы деньги не имели значения, я, вероятно, действительно увлекся бы Oracle. Посмотрите их функцию Result Cache: вы можете сконфигурировать процент памяти для кэширования результатов запроса на случай, когда приложения продолжают повторять один и тот же запрос. Однако $47500 на одно ядро процессора для лицензирования Enterprise Edition, боюсь, что в ближайшее время я не сподоблюсь попробовать эту икру.
Один из способов решить данную проблему - это кэширование результатов в слое приложения:
- Самый быстрый запрос - это тот, который вы никогда не напишете
- Какие запросы следует кэшировать в приложении?
- Как кэшировать результаты хранимой процедуры
Другой способ, который я использую наиболее часто, это предварительно подготовить данные таким образом, чтобы запросы выполнялись быстрее. Это некластеризованный индекс, о котором я буду говорить в следующей статье.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой