
Как думать подобно серверу SQL Server
Пересказ статьи Brent Ozar. How to Think Like the SQL Server Engine
Вы разработчик или администратор баз данных, и вы вполне уверенно пишите запросы для получения требуемых данных. Но вы значительно менее уверенно чувствуете себя, пытаясь спроектировать правильные индексы для вашего сервера баз данных.
В нескольких следующих постах мы изучим:
Эти базы доступны для скачивания. В этой серии статей я собираюсь использовать небольшую 10-гигабайтную базу StackOverflow2010 (zip-файл 1Гб). Используйте её, если вы хотите повторять мои действия и получать подобные результаты и планы запросов.
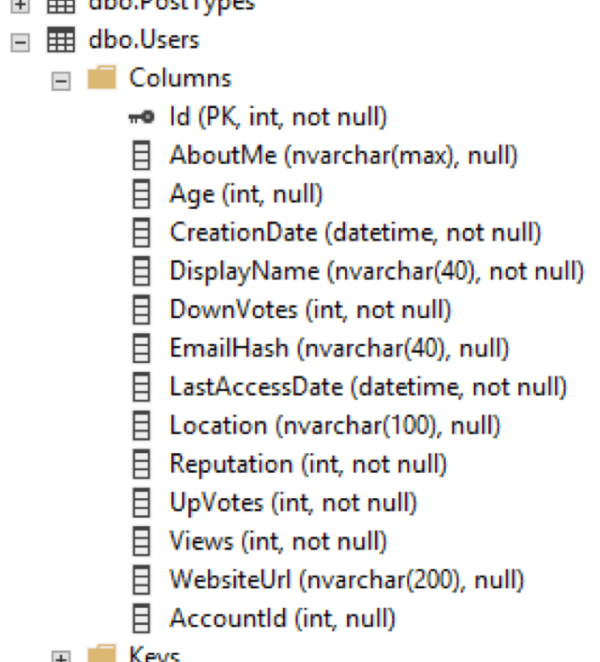
Таблица Users содержит именно то, что вы ожидаете: список тех, создал аккаунт на StackOverflow.com. Схема довольно проста:
В SQL Server большинство объектов сохраняется на 8-килобайтных страницах, каждая такая страница полностью выделена под один объект. (Мы оставим нюансы поколоночных индексов, Hekaton и другие второстепенные объекты для следующих публикаций.) Вы можете думать об этих 8-килобайтных страницах просто как о напечатанных страницах листа Excel, например:
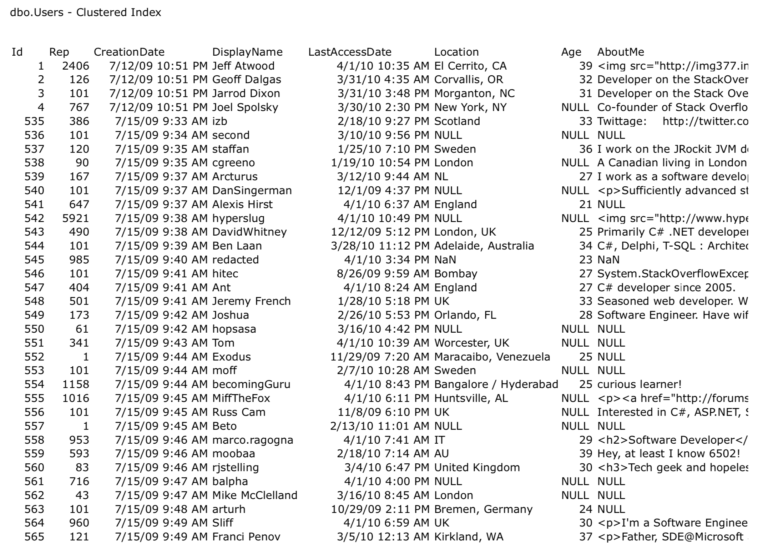
На рисунке выше представлен кластеризованный индекс таблицы dbo.Users. Столбец id является кластеризованным первичным ключом таблицы.
Посмотрите вниз в левой части листа: строки отсортированы по id, а лист содержит все столбцы в таблице. Кластеризованный индекс ЯВЛЯЕТСЯ таблицей, и эти 8-килобайтные страницы одинаковы, что на диске, что в памяти.
Каждый файл данных базы (MDF/NDF) есть просто строка 8-килобайтных страниц от начала до конца. Некоторые страницы используются SQL Server для хранения метаданных о базе данных, но большинство из их - это ваши индексы.
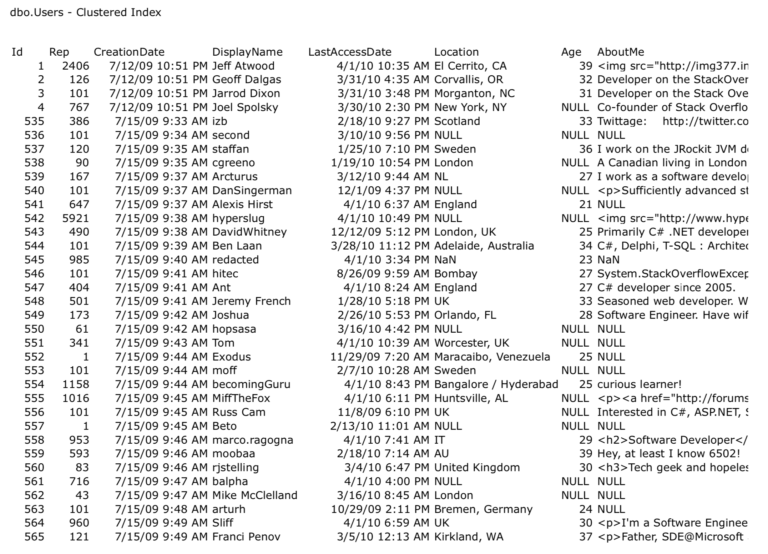
Вы можете увидеть, сколько страниц содержит таблица, выполнив к ней запрос типа:
Первая строка здесь - SET STATISTICS IO ON - добавляет информацию на вкладку "Сообщения" в SQL Server Management Studio, которая покажет вам число 8-килобайтных страниц, которое должен прочитать SQL Server, чтобы выполнить ваш запрос:
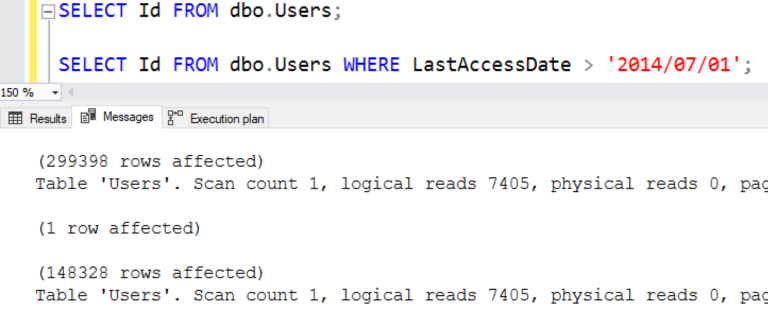
“logical reads 7405” означает, что SQL Server прочитал 7405 8-килобайтных страниц. Вообще говоря, чем меньше страниц должен прочитать SQL Server, чтобы выполнить ваш запрос, тем быстрей запрос выполнится.
Вы знаете эти 500-страничные упаковки бумаги, которые вы используете в копире или принтере? Таблица Users одна из самых маленьких таблиц в базе данных Stack Overflow, и, тем не менее, она занимает 15 таких упаковок.

Я хочу, чтобы вы представили себе стопу из 15 пачек бумаги в углу вашей комнаты. Когда я прошу выполнить запрос к таблице, я хочу, чтобы вы подумали о человеке, которому пришлось бы перебирать эту стопу из 15-ти пачек бумаги. Вы вряд ли бросились бы начинать эту работу. Вам, вероятно, захочется сначала придумать хороший план, прежде чем приступить к работе с этой стопой бумаги.
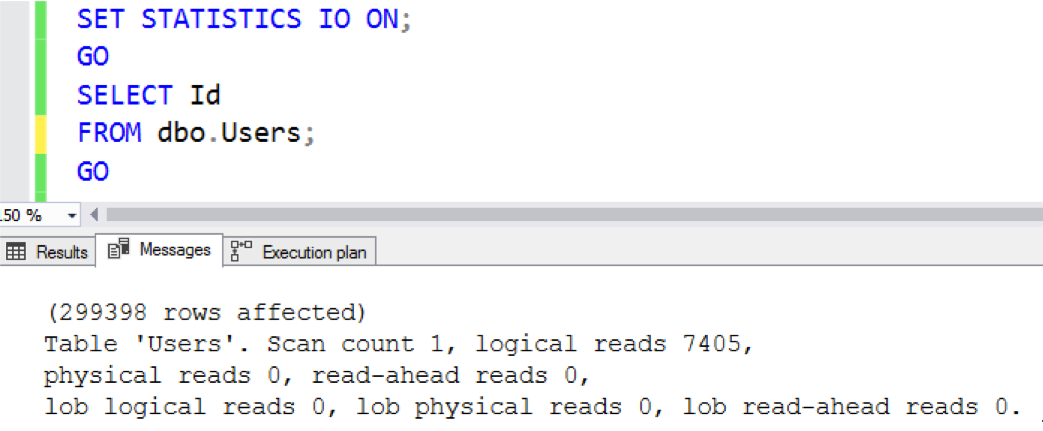
В SSMS щелкните Запрос, Включить Действительный План Выполнения (или нажмите Ctrl-M), выполните запрос еще раз, и вы получите вкладку "План выполнения":

Читайте план справа налево: SQL Server просканировал кластерный индекс (т.е. таблицу), вытолкнув 299398 вещей в оператор SELECT. Он должен был просканировать всю таблицу, поскольку мы запросили все - ну, мы просили только один столбец (Id), но идентификаторы разбросаны по всем страницам, поэтому приходится читать их все.
Т.к. обычно мы не должны писать запрос без предложения WHERE, поэтому добавим его.
Давайте получим только тех посетителей, которые заходили после 1 июля 2014:
Мой план выполнения выглядит так же:
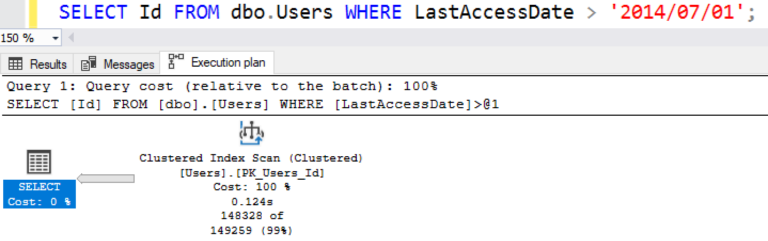
(Если вы повторяете это на своём компьютере, ваш запрос может выглядеть несколько иначе. Я объясню, почему так происходит, в следующей статье.)
Оба моих запроса - с предложением WHERE и без него - читают одинаковое число страниц. Здесь я запускаю оба запроса один за другим, показывая их статистику на вкладке Сообщения:
И если вы снова посмотрите на страницу размером 8КБ, то поймете, почему мы должны сканировать кластерный индекс, чтобы найти строки с LastAccessDate> 2014/07/01:
И хотя наш запрос возвращает меньше строк, мы по-прежнему должны выполнить столько же работы, поскольку данные просто не отсортированы в том порядке, который помог бы нашему запросу. Если вы собираетесь часто отбирать данные по LastAccessDate, и если вы хотите, чтобы запросы выполнялся быстрей, вам потребуется помочь SQL Server, спроектировав дополнительную копию нашей таблицы, отсортированную лучшим образом: некластеризованный индекс.
В этой серии статей я собираюсь быстро объяснить многие важные основополагающие вещи. Для этого я оставляю в стороне многие детали, которые вы, вероятно, сочли бы интересными - но поймите, это блог, а не книга. И это начальная точка в вашей траектории обучения.
Тем не менее, есть несколько заявлений, которые я должен сделать, иначе блоггеры в креслах будут жаловаться:
- Различие между кластеризованным и некластеризованным индексами.
- Как (и когда) создавать покрывающий индекс.
- Основы планов выполнения.
Я использую таблицу Users в базе данных Stack Overflow
Эти базы доступны для скачивания. В этой серии статей я собираюсь использовать небольшую 10-гигабайтную базу StackOverflow2010 (zip-файл 1Гб). Используйте её, если вы хотите повторять мои действия и получать подобные результаты и планы запросов.
Таблица Users содержит именно то, что вы ожидаете: список тех, создал аккаунт на StackOverflow.com. Схема довольно проста:
- id - идентификатор, от 1 до миллиарда.
- DisplayName - не уникально, просто имя, на которое вы отзываетесь, типа “Brent Ozar” или “Alex”.
- LastAccessDate - время, когда вы последний раз посещали StackOverflow.com.
В SQL Server большинство объектов сохраняется на 8-килобайтных страницах, каждая такая страница полностью выделена под один объект. (Мы оставим нюансы поколоночных индексов, Hekaton и другие второстепенные объекты для следующих публикаций.) Вы можете думать об этих 8-килобайтных страницах просто как о напечатанных страницах листа Excel, например:
На рисунке выше представлен кластеризованный индекс таблицы dbo.Users. Столбец id является кластеризованным первичным ключом таблицы.
Этот кластеризованный индекс на Id и есть таблица.
Посмотрите вниз в левой части листа: строки отсортированы по id, а лист содержит все столбцы в таблице. Кластеризованный индекс ЯВЛЯЕТСЯ таблицей, и эти 8-килобайтные страницы одинаковы, что на диске, что в памяти.
Каждый файл данных базы (MDF/NDF) есть просто строка 8-килобайтных страниц от начала до конца. Некоторые страницы используются SQL Server для хранения метаданных о базе данных, но большинство из их - это ваши индексы.
Вы можете увидеть, сколько страниц содержит таблица, выполнив к ней запрос типа:
SET STATISTICS IO ON;
GO
SELECT Id FROM dbo.Users;Первая строка здесь - SET STATISTICS IO ON - добавляет информацию на вкладку "Сообщения" в SQL Server Management Studio, которая покажет вам число 8-килобайтных страниц, которое должен прочитать SQL Server, чтобы выполнить ваш запрос:
“logical reads 7405” означает, что SQL Server прочитал 7405 8-килобайтных страниц. Вообще говоря, чем меньше страниц должен прочитать SQL Server, чтобы выполнить ваш запрос, тем быстрей запрос выполнится.
7405 страниц - это около 15 пачек бумаги.
Вы знаете эти 500-страничные упаковки бумаги, которые вы используете в копире или принтере? Таблица Users одна из самых маленьких таблиц в базе данных Stack Overflow, и, тем не менее, она занимает 15 таких упаковок.
Я хочу, чтобы вы представили себе стопу из 15 пачек бумаги в углу вашей комнаты. Когда я прошу выполнить запрос к таблице, я хочу, чтобы вы подумали о человеке, которому пришлось бы перебирать эту стопу из 15-ти пачек бумаги. Вы вряд ли бросились бы начинать эту работу. Вам, вероятно, захочется сначала придумать хороший план, прежде чем приступить к работе с этой стопой бумаги.
Вот почему SQL Server пытается строить хорошие планы выполнения.
В SSMS щелкните Запрос, Включить Действительный План Выполнения (или нажмите Ctrl-M), выполните запрос еще раз, и вы получите вкладку "План выполнения":
Читайте план справа налево: SQL Server просканировал кластерный индекс (т.е. таблицу), вытолкнув 299398 вещей в оператор SELECT. Он должен был просканировать всю таблицу, поскольку мы запросили все - ну, мы просили только один столбец (Id), но идентификаторы разбросаны по всем страницам, поэтому приходится читать их все.
Т.к. обычно мы не должны писать запрос без предложения WHERE, поэтому добавим его.
Давайте будем хорошими и добавим предложение WHERE
Давайте получим только тех посетителей, которые заходили после 1 июля 2014:
SELECT Id FROM dbo.Users WHERE LastAccessDate > '2014/07/01';Мой план выполнения выглядит так же:
(Если вы повторяете это на своём компьютере, ваш запрос может выглядеть несколько иначе. Я объясню, почему так происходит, в следующей статье.)
Оба моих запроса - с предложением WHERE и без него - читают одинаковое число страниц. Здесь я запускаю оба запроса один за другим, показывая их статистику на вкладке Сообщения:
И если вы снова посмотрите на страницу размером 8КБ, то поймете, почему мы должны сканировать кластерный индекс, чтобы найти строки с LastAccessDate> 2014/07/01:
И хотя наш запрос возвращает меньше строк, мы по-прежнему должны выполнить столько же работы, поскольку данные просто не отсортированы в том порядке, который помог бы нашему запросу. Если вы собираетесь часто отбирать данные по LastAccessDate, и если вы хотите, чтобы запросы выполнялся быстрей, вам потребуется помочь SQL Server, спроектировав дополнительную копию нашей таблицы, отсортированную лучшим образом: некластеризованный индекс.
Отказ от ответственности: я многое упрощаю здесь.
В этой серии статей я собираюсь быстро объяснить многие важные основополагающие вещи. Для этого я оставляю в стороне многие детали, которые вы, вероятно, сочли бы интересными - но поймите, это блог, а не книга. И это начальная точка в вашей траектории обучения.
Тем не менее, есть несколько заявлений, которые я должен сделать, иначе блоггеры в креслах будут жаловаться:
- Обратите внимание, что столбец AboutMe обрезан. Столбец AboutMe имеет тип NVARCHAR(MAX), поскольку Stack Overflow позволяет хранить огромное количество материала в вашем профиле. В SQL Server большие данные AboutMe могут быть вынесены из строки и сохраняться на отдельных 8-килобайтных страницах. Когда вы проектируете таблицы с большими столбцами типа VARCHAR(MAX), NVARCHAR(MAX), XML, JSON и т.д., вы можете, в конечном итоге, заплатить производительностью, поскольку SQL Server переключится на чтение всех этих данных. В идеале, размер столбцов должен быть достаточно широким, чтобы позволить хранить нужные вам данные, и не более того.
- 8-килобайтные страницы не используют сетку типа Excel. SQL Server нужно втиснуть как можно больше данных на страницу, поэтому нет, он не организует строки и столбцы на странице размером 8 КБ, как в электронной таблице. Также заголовки столбцов не хранятся в виде плоского текста на каждой странице, как и значения null не хранятся как текст в верхнем регистре - NULL. Я лишь использую электронную таблицу в качестве инструмента визуализации, поскольку это помогает вам понять, как все работает.
- 8-килобайтные страницы, которые я показал, называются листовыми страницами. Индексы имеют также страницы других типов, подобных структурам B-tree, которые помогают движку быстро находить нужную страницу при поиске конкретной строки. Однако, даже если вы просто сосредоточитесь на листовых страницах и не будете знать ничего другого, вы, тем не менее, сможете выполнить феноменальную работу по улучшению производительности базы данных - а это цель настоящей серии публикаций, позволяющей быстро познакомить вас с наиболее важными вещами.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой