
Как думать подобно SQL Server: добавить некластеризованный индекс
Пересказ статьи Brent Ozar. How to Think Like the SQL Server Engine: Adding a Nonclustered Index
Прочитав последнюю статью, наши пользователи продолжали выполнять этот запрос и хотели бы его ускорить:
SELECT Id
FROM dbo.Users
WHERE LastAccessDate > '2014/07/01'
ORDER BY LastAccessDate;Давайте подготовим данные, создав копию таблицы, отсортированную так, чтобы мы могли быстро найти требуемые строки:
CREATE INDEX IX_LastAccessDate_Id
ON dbo.Users(LastAccessDate, Id);Этим мы создадим отдельную копию нашей таблицы (также сохраняемой на 8-килобайтных страницах), которая выглядит следующим образом:

Этот индекс замедляет вставку и удаление.
Первое, что следует иметь в виду, это то, что теперь вы имеете две физических копии таблицы. Всякий раз, когда вы вставляете новую строку, вы должны добавить её в два места. Всякий раз, когда вы удаляете строку, вы должны убрать её из двух мест. Вы фактически удвоили число записей, которое должно обслуживать ваше хранилище. (Обновление несколько хитрее, о чем пойдет речь в следующей статье.)
Во-вторых, некластеризованный индекс (черная страница) является более плотным: на 8-килобайтную страницу может поместиться больше пользователей, поскольку мы сохраняем в индексе меньше полей. Вы можете увидеть это выполнив sp_BlitzIndex, если посмотрите на верх результирующего набора, где показано, насколько велик каждый индекс:

Кластеризованный индекс (CX PK) имеет около 300К строк и занимает 58,1Мб на диске, поскольку он содержит все столбцы таблицы.
Некластеризованный индекс содержит то же число строк, но занимает только 5,3Мб места на диске, поскольку хранит только LastAccessDate и Id. Чем больше столбцов вы добавляете в индекс - в ключ или же во включенные столбцы - тем больше места он занимает на диске. (Я расскажу еще о проектировании индексов по ходу этой серии.)
Но этот индекс с лихвой окупается при выборке.
Снова испытайте наш запрос на выборку. Здесь я выполняю подряд два запроса: первый с хинтом INDEX=1, чтобы показать стоимость сканирования кластерного индекса. (Index #1 - это ваш кластеризованный индекс.)
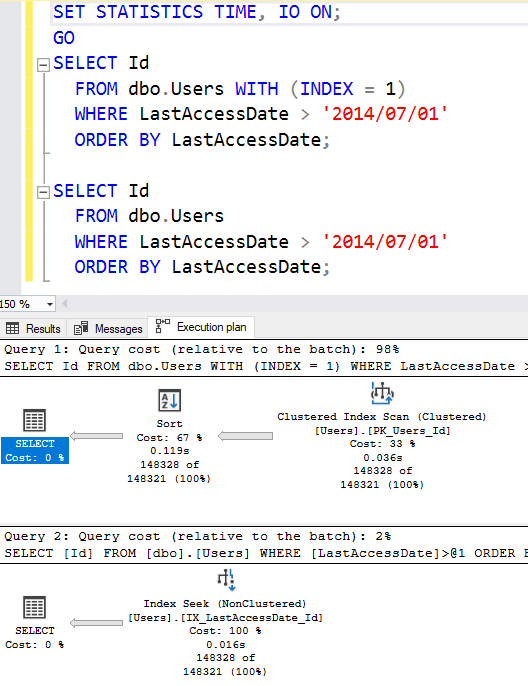
Наш новый план внизу значительно проще:
- Мы получаем поиск (seek), а не сканирование (scan), поскольку SQL Server имеет возможность перейти непосредственно к строкам, у которых LastAccessDate > 2014/07/01. Это не требует сканирования всего объекта.
- Нам не требуется сортировка, поскольку мы считываем данные, которые уже отсортированы по LastAccessDate.
Стоимость поиска по индексу ниже по двум причинам: ему не нужна сортировка, и он читает меньше 8-килобайтных страниц. Чтобы увидеть насколько меньше, перейдите на вкладку сообщений:

Сканирование кластеризованного индекса читает 7405 страниц и занимает 100мс времени процессора, чтобы выполнить ORDER BY.
Новый некластеризованный индекс читает только 335 страниц - примерно в 20 раз меньше - и не требует времени процессора на ORDER BY. Действительно хорошее проектирование индексов, подобное данному, это то, что позволит вам быстро получить улучшение в 20 или много более раз без переписывания ваших запросов. Хотел бы я, чтобы каждый запрос был идеально настроен? Конечно, но даже если бы это было так, вам все равно нужно будет помочь движку, организовав данные более удобным для поиска способом.
Этот индекс называется покрывающим.
Индекс идеально покрывает данный запрос, удовлетворяя его потребностям быстрым, эффективным способом. Термин "покрывающий" не является обозначением индексов особого вида, который создаете с использованием специального синтаксиса. "Покрывающий" просто относится к комбинации индекса И данного запроса. Если вы измените запрос - как мы собираемся сделать здесь в ближайшее время - то индекс может перестать быть покрывающим, и нам предстоит опять проделать больше работы.
Итак, наш план имеет поиск по индексу - это лучший план, который можно получить, верно? Нет, как мы увидим в следующем эпизоде.
Обратные ссылки
Автор не разрешил комментировать эту запись
Комментарии
Показывать комментарии Как список | Древовидной структурой